







一、引言
机器翻译作为自然语言处理(NLP)领域的一项重要技术,其发展日新月异。本文将深入探讨基于门控循环单元(GRU)和Transformer模型的机器翻译原理及其应用,本文将详细介绍这两种模型在机器翻译中的应用,从数据预处理到模型训练,再到评估与优化。我们将展示如何通过编码器将源语言文本转换为上下文向量,并通过解码器逐步生成目标语言的翻译结果。同时,我们还将探讨注意力机制如何集成到这两种模型中,以进一步提升翻译的准确性和流畅性。
二、实验原理
1.数据读取与预处理
在机器翻译任务中,数据的读取与预处理是至关重要的步骤,构成了整个实验流程的基础。我们定义了一些自然语言处理中常用的特殊标记,例如<pad>用于填充,<bos>表示句子的开始,<eos>表示句子的结束。各个序列后添加必要的<pad>标记,直到达到预设的最大序列长度max_seq_len。同时,我们在序列末尾添加<eos>标记,以明确句子的边界。处理后的序列随后被保存到全局序列列表中。
预处理的下一步是构建词典。build_data函数使用collections.Counter统计all_tokens中所有单词的频率,并利用torchtext.vocab.Vocab创建词汇表。该函数将特殊标记作为词典的一部分,并为all_seqs中的每个序列生成词索引列表,最终将这些索引转换为PyTorch Tensor,为模型训练准备数据。最后初始化存放词汇、序列和数据的列表,遍历文件中的每一行,对源语言和目标语言序列分别进行处理,包括分割、填充、添加特殊标记,并跳过长度不符合要求的样本。最终,该函数利用所有输入序列和输出序列的词汇构建词典,并转换为词索引的张量,创建PyTorch的Data.TensorDataset数据集,为模型训练提供输入输出对。
通过这些连贯的步骤,原始的文本数据被转换成了适合深度学习模型处理的格式,为训练阶段提供了必要的数据基础。这一过程不仅涉及技术实现,也体现了对自然语言处理任务中数据重要性的深刻理解。
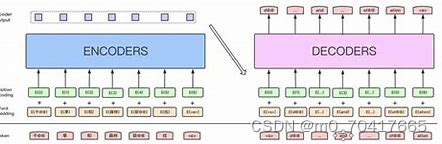
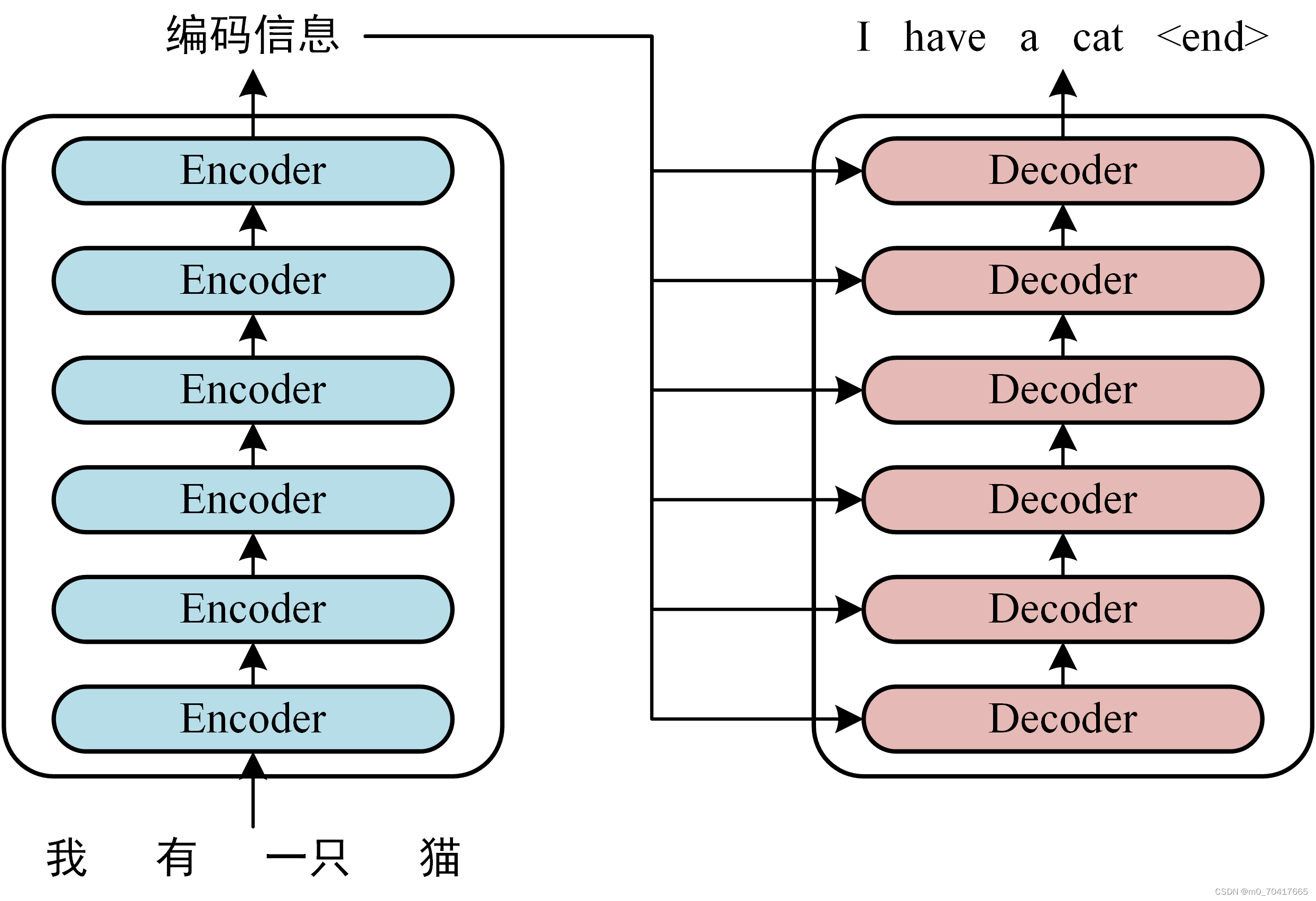
2.含注意力机制的编码器—解码器
2.1编码器
编码器的目的是将输入的源语言文本转换成一个固定大小的向量,这个向量包含了整个输入序列的信息。在传统的Seq2Seq模型中,编码器通常是一个循环神经网络(RNN),如长短期记忆网络(LSTM)或门控循环单元(GRU)。编码器逐个处理输入序列中的每个词,更新其内部状态,最终将最后一个时间步的隐藏状态作为上下文向量输出。
2.2注意力机制
注意力机制是Seq2Seq模型的一个关键改进,它允许解码器在生成每个目标词时,动态地聚焦于源序列中与当前目标词最相关的部分。这种机制通过一个可学习的函数来计算源序列中每个词对于当前解码步骤的重要性或“注意力得分”。然后,这些注意力得分用于加权源序列的表示,生成一个加权的上下文向量,这个向量随后被解码器用作条件信息。
2.3含有注意力机制的解码器
含有注意力机制的解码器结合了传统的RNN结构和注意力机制。在每个解码步骤中,解码器不仅接收来自前一个步骤的隐藏状态,还接收一个从编码器的输出序列中计算得到的上下文向量。这个上下文向量是通过注意力机制得到的,它反映了当前目标词与源序列中各个词的关联程度。
具体来说,解码器的每个时间步都会进行以下操作:
- 使用前一个时间步的输出作为当前时间步的输入。
- 计算当前时间步的注意力得分,这些得分基于解码器的当前隐藏状态和编码器的所有隐藏状态。
- 使用注意力得分对编码器的隐藏状态进行加权求和,得到一个加权的上下文向量。
- 将这个上下文向量与解码器的当前输入合并,形成解码器的当前输入表示。
- 将合并后的输入表示输入到解码器的RNN单元中,生成下一个隐藏状态。
- 最后,解码器的输出层(通常是一个全连接层)将隐藏状态映射到目标词汇表的概率分布上,从而预测下一个词。
通过这种方式,含有注意力机制的解码器能够在生成翻译时,更加灵活和准确地利用源文本中的信息,从而提高翻译的质量和流畅性。这种模型结构特别适合处理长序列,因为它允许解码器在每个步骤中都重新关注源文本的不同部分。
3.训练模型
我们利用了batch_loss函数来计算损失,下面是该函数的原理。
我们可以将batch_loss函数的作用和原理概括如下:
-
损失函数计算:
batch_loss函数的核心目的是计算模型在一个小批量数据上的损失。损失函数衡量了模型预测输出与真实标签之间的差异,是训练过程中需要最小化的关键指标。 -
编码器-解码器架构:在序列到序列的机器翻译任务中,编码器首先处理输入序列(源语言文本),将其转换成一个固定大小的向量或一组向量。解码器随后基于这些向量生成输出序列(目标语言文本)。
-
初始化状态:在每个小批量数据处理之前,编码器和解码器的状态需要被适当初始化。对于循环神经网络(RNN)来说,这通常意味着设置隐藏状态和/或细胞状态。
-
前向传播:编码器对输入序列进行前向传播,产生输出和最终状态。解码器使用这些信息,结合自己的初始状态,开始生成输出序列。
-
强制教学:为了加速模型学习过程,解码器在每个时间步使用实际的目标词作为下一个时间步的输入,而不是使用自己生成的预测词。这种方法称为强制教学,有助于模型更快地收敛。
-
掩码处理:在序列生成任务中,通常会有填充(padding)的存在,即序列中某些位置实际上不包含有效信息。掩码变量用于在损失计算时忽略这些填充位置,确保只计算有效词项的损失。
-
动态调整:在解码器生成每个词的过程中,一旦生成了序列结束的标记,后续的掩码将被设置为零,这样在计算损失时就不会考虑这些位置。
-
平均损失:最终,计算得到的总损失会被有效词项的数量所归一化,得到平均损失,这是每个词项损失的平均值,用于更公平地评估模型性能。
-
反向传播:在损失计算之后,通过反向传播算法来计算损失相对于模型参数的梯度,这些梯度指导了模型参数的更新。
-
迭代优化:在训练过程中,通过不断迭代,模型学习如何减少预测误差,最终达到提高翻译质量的目的。
batch_loss函数的实现和使用是深度学习中监督学习的一个典型例子,它体现了通过梯度下降和反向传播来优化模型参数的过程。
4.预测不定长的序列
在机器翻译或序列生成任务中,预测不定长的序列是一个挑战,因为输出序列可能具有不同的长度。一般有贪婪搜索、穷举搜索、束搜索。贪婪搜索是一种简单而直观的解码策略,用于生成解码器的输出序列。以下是贪婪搜索的作用与原理:
贪婪搜索的主要作用是在给定输入序列的情况下,生成一个输出序列。在机器翻译中,这意味着将源语言的文本转换成目标语言的文本。
在贪婪搜索中,解码器在每个时间步都会选择概率最高的单个词作为输出。这是一种贪心策略,因为每一步都只考虑当前最优的选择,而不考虑未来可能带来的整体最优结果。这就导致虽然贪婪搜索实现简单,计算效率高,因为它不需要考虑所有可能的序列组合,只关注每一步的最优解。但是它并不总是能够找到整体最优的序列。在某些情况下,它可能会因为局部最优选择而错过更好的全局解决方案。


5.Transferormer
Transformer模型是一种基于自注意力机制的序列到序列(Seq2Seq)模型,它在2017年由Vaswani等人在论文《Attention is all you need》中提出,并在自然语言处理领域引起了革命性的变化。以下是Transformer模型的核心原理:
1. 自注意力机制(Self-Attention):
- 允许模型在编码每个单词时考虑到序列中的所有单词,而不是像传统RNN那样按顺序处理。
- 通过计算单词之间的注意力分数,模型可以捕捉长距离依赖关系。
2. 多头注意力(Multi-Head Attention):
- Transformer模型使用多个注意力头并行处理信息,每个头学习到序列的不同方面。
- 多头注意力的输出被合并,为模型提供更丰富的表示。
3. 位置编码(Positional Encoding):
- 由于Transformer模型本身不具备捕捉序列顺序的能力,因此需要位置编码来提供单词在序列中的位置信息。
- 通常使用正弦和余弦函数的组合来编码位置信息。
4. 编码器-解码器架构(Encoder-Decoder Architecture):
- 编码器由多个相同的层(Transformer Encoder Layer)堆叠而成,每层包含自注意力和前馈网络。
- 解码器同样由多个相同的层(Transformer Decoder Layer)组成,每层包含自注意力、编码器-解码器注意力(用于关注编码器的输出)和前馈网络。
5. 前馈网络(Feed-Forward Networks):
- 在每个编码器和解码器层中,自注意力或多头注意力的输出会传递给一个前馈网络,用于进一步处理和提炼特征。
6. 残差连接和层归一化(Residual Connections and Layer Normalization)**:
- 每个子层(自注意力和前馈网络)的输出通过残差连接和层归一化来减少训练深度网络时的梯度消失问题。
7. 并行处理能力:
- 由于自注意力机制的特性,Transformer模型可以并行处理整个序列,这与循环神经网络的顺序处理方式形成对比。
8. 输出层:
- 解码器的最后一层输出通过一个线性层和Softmax层来预测下一个词的概率分布。
9. 训练技术:
- 使用交叉熵损失函数来衡量预测输出和真实标签之间的差异,并采用优化算法(如Adam)进行参数更新。
10. 教师强制(Teacher Forcing):
- 在训练过程中,使用教师强制技术,即用真实的输出作为下一时间步的输入,以提高学习效率。
Transformer模型的这些原理使其在机器翻译、文本摘要、问答系统等多个NLP任务中表现出色,特别是在处理长序列和捕捉长距离依赖关系方面。
三、实验介绍
3.1实验目的
- 使用编码器—解码器和注意力机制来实现机器翻译模型
- 使用Transformer架构和PyTorch深度学习库来实现的日中机器翻译模型
3.2实验环境
- Python 3.6.7
- 需要有GPU来进行训练模型,若有GPU可以下载对应版本的cuda驱动程序和能够匹配的Pytorch(GPU),若无GPU可参考下面这个博客自然语言处理:机器翻译的原理以及应用编码器—解码器和注意力机制实现基于GRU和Transformer的机器翻译(GPU实现版)-优快云博客
 https://blog.youkuaiyun.com/Cherry_chen2003/article/details/139882765?spm=1001.2014.3001.5502
https://blog.youkuaiyun.com/Cherry_chen2003/article/details/139882765?spm=1001.2014.3001.5502
四、实验运行
4.1使用编码器—解码器和注意力机制来实现机器翻译模型
4.1.1读取和预处理数据
我们先定义一些特殊符号。其中“<pad>”(padding)符号用来添加在较短序列后,直到每个序列等长,而“<bos>”和“<eos>”符号分别表示序列的开始和结束。
!tar -xf d2lzh_pytorch.tar
# 导入Python标准库,用于数据集合、操作系统接口、I/O操作和数学计算
import collections
import os
import io
import math
# 导入PyTorch深度学习库及其子模块
import torch
from torch import nn # 包含神经网络层的模块
import torch.nn.functional as F # 包含函数式接口的神经网络操作模块
# 导入torchtext库中的词汇表模块,用于文本处理
import torchtext.vocab as Vocab
# 导入PyTorch的数据加载和处理工具模块
import torch.utils.data as Data
# 导入系统库sys,用于添加额外的模块搜索路径
import sys
# sys.path.append("..") # 注释掉的代码,用于将上级目录添加到模块搜索路径
# 导入自定义模块d2lzh_pytorch,可能包含深度学习辅助函数或类
import d2lzh_pytorch as d2l
# 定义自然语言处理中常用的特殊标记
PAD, BOS, EOS = '<pad>', '<bos>', '<eos>'
# 设置环境变量,指定GPU设备编号,如果GPU不可用 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









