







利用无约束与约束帕累托前沿关系的约束多目标优化算法
引言
约束多目标优化问题(CMOPs)在工程和科学领域广泛存在,其核心挑战在于如何平衡目标优化与约束满足。传统方法如基于惩罚函数、约束支配原则等,在处理复杂约束时往往效率不足。本文介绍了一种新型算法URCMO,通过分析无约束帕累托前沿(UPF)与约束帕累托前沿(CPF)的关系,显著提升了算法在复杂约束下的搜索效率。
核心方法
问题定义
CMOP的数学模型可表示为:
{
min
f
(
x
)
=
(
f
1
(
x
)
,
f
2
(
x
)
,
…
,
f
M
(
x
)
)
s.t.
g
n
(
x
)
≤
0
(
n
=
1
,
…
,
l
)
,
h
n
(
x
)
=
0
(
n
=
l
+
1
,
…
,
q
)
\begin{cases} \min f(x) = (f_1(x), f_2(x), \dots, f_M(x)) \\ \text{s.t.} \quad g_n(x) \leq 0 \ (n=1,\dots,l), \quad h_n(x) = 0 \ (n=l+1,\dots,q) \end{cases}
{minf(x)=(f1(x),f2(x),…,fM(x))s.t.gn(x)≤0 (n=1,…,l),hn(x)=0 (n=l+1,…,q)
其中,
x
x
x为决策变量,
f
f
f为目标函数,
g
g
g和
h
h
h分别为不等式和等式约束。
URCMO算法框架
URCMO将进化过程分为学习阶段和进化阶段,通过两个种群分别逼近CPF和UPF。算法流程如下:
初始化种群P1(CPF)和P2(UPF)
while 未达最大评估次数:
if 处于学习阶段:
使用GA和DE生成子群
合并种群并选择最优个体
else:
分类CPF与UPF关系
根据关系调整P2的进化策略

学习阶段策略
-
双种群进化:
- GA操作:使用模拟二进制交叉(SBX)和多项式变异(PM):
u j = { ( 2 α − α 2 ) 1 / η ⋅ ( x j , a − x j , b ) + x j , b if α ≤ 1 ( 2 − 2 α + α 2 ) − 1 / η ⋅ ( x j , a − x j , b ) + x j , b otherwise u_j = \begin{cases} \left(2\alpha - \alpha^2\right)^{1/\eta} \cdot (x_{j,a} - x_{j,b}) + x_{j,b} & \text{if } \alpha \leq 1 \\ \left(2 - 2\alpha + \alpha^2\right)^{-1/\eta} \cdot (x_{j,a} - x_{j,b}) + x_{j,b} & \text{otherwise} \end{cases} uj={(2α−α2)1/η⋅(xj,a−xj,b)+xj,b(2−2α+α2)−1/η⋅(xj,a−xj,b)+xj,bif α≤1otherwise - DE操作:采用DE/current-to-rand/1变异策略:
v i = x i + F ⋅ ( x r − x r ′ ) v_i = x_i + F \cdot (x_r - x_{r'}) vi=xi+F⋅(xr−xr′)
- GA操作:使用模拟二进制交叉(SBX)和多项式变异(PM):
-
环境选择:基于SPEA2的适应度分配和截断策略。
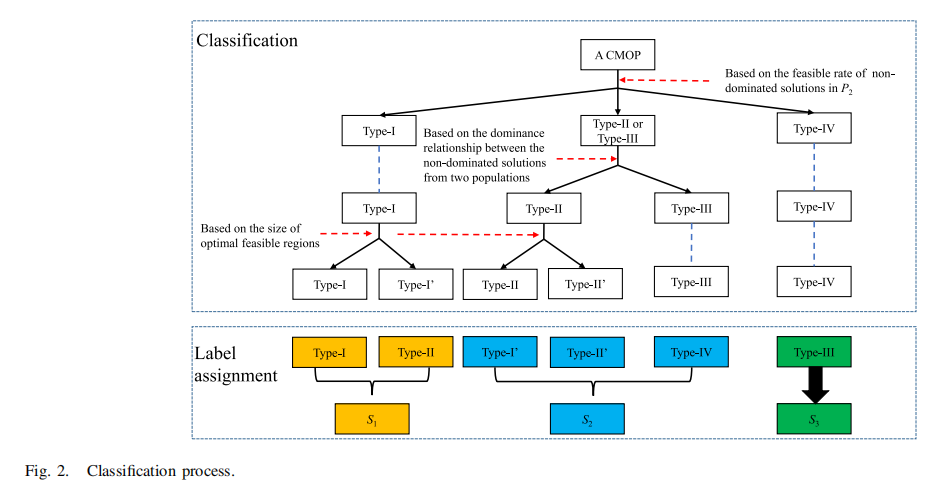
关系分类方法
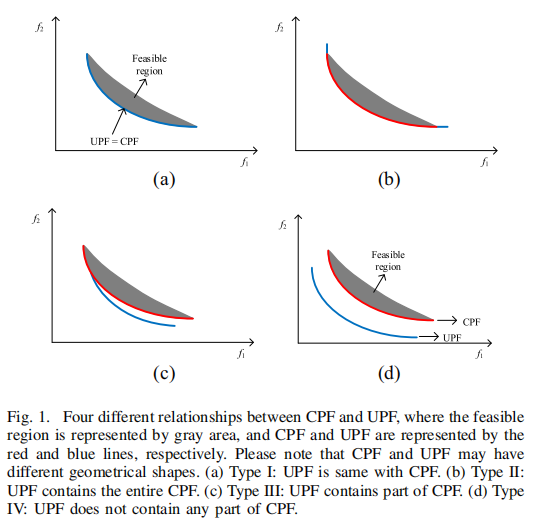
通过可行性信息和支配关系将问题分为四类(图1):
- 类型I:UPF与CPF完全重合
- 类型II:UPF包含完整CPF
- 类型III:UPF包含部分CPF
- 类型IV:UPF与CPF无交集
分类公式为:
Type
=
{
I
若
P
2
1
全可行
IV
若
P
2
1
全不可行
II/III
否则,通过支配比例判断
\text{Type} = \begin{cases} \text{I} & \text{若} \ P_2^1 \text{全可行} \\ \text{IV} & \text{若} \ P_2^1 \text{全不可行} \\ \text{II/III} & \text{否则,通过支配比例判断} \end{cases}
Type=⎩
⎨
⎧IIVII/III若 P21全可行若 P21全不可行否则,通过支配比例判断
进化阶段策略
根据分类结果调整P2的进化策略:
- 类型I/II:使用GA和DE/transfer/1(交叉概率CR=0.1~1.0)
- 类型I’/II’/IV:采用DE/current-to-opbest/1:
v i = x i + F ⋅ ( x opbest − x i ) + F ⋅ ( x r 2 − x r 3 ) v_i = x_i + F \cdot (x_{\text{opbest}} - x_i) + F \cdot (x_{r2} - x_{r3}) vi=xi+F⋅(xopbest−xi)+F⋅(xr2−xr3) - 类型III:混合使用三种策略(GA、DE/transfer/1、DE/current-to-opbest/1)
实验与结果
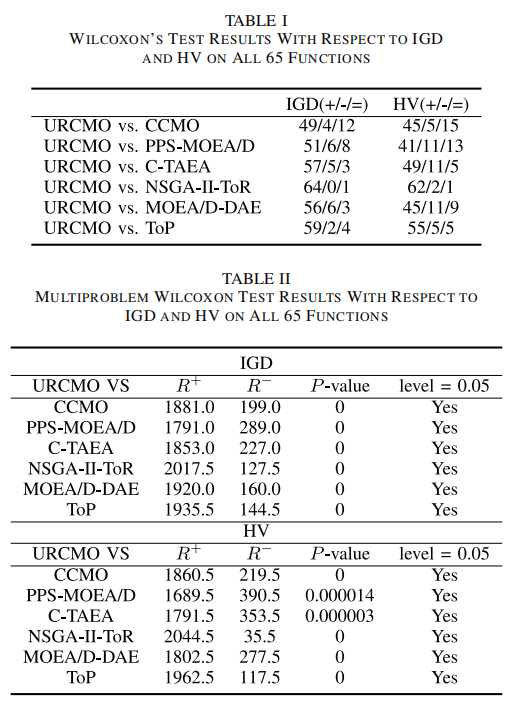
在65个基准函数和10个实际问题上的实验表明,URCMO在收敛性(IGD指标)和多样性(HV指标)上均优于现有算法(表1)。例如:
- 在LIR-CMOP2(类型IV)上,URCMO的IGD值比CCMO降低42%
- 在复杂约束的DOC问题中,URCMO的可行解获取率达96.7%
结论与展望
URCMO通过动态利用UPF与CPF的关系,显著提升了约束多目标优化的性能。未来研究可探索:
- 复杂约束下的自适应性策略
- 多目标优化中的高维问题扩展
- 结合机器学习的关系预测模型
引用:
Liang J, Qiao K, Yu K, et al. Utilizing the Relationship Between Unconstrained and Constrained Pareto Fronts for Constrained Multiobjective Optimization[J]. IEEE Transactions on Cybernetics, 2023, 53(6): 3873-3886.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









