






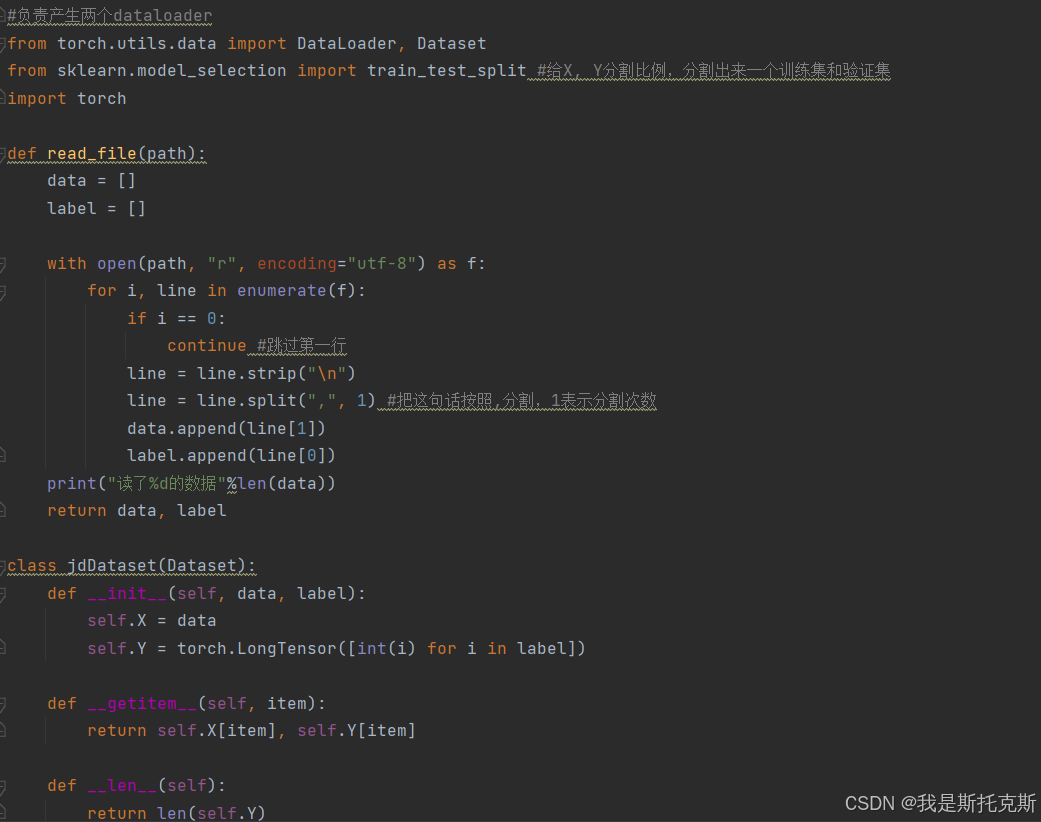
一、data.py
这些函数主要用于处理和加载数据集,以便在机器学习或深度学习任务中使用。具体来说,它们的职责如下:
-
read_file函数:- 读取指定路径的文件,通常是一个以逗号分隔的CSV文件。
- 跳过文件的第一行(通常是标题行)。
- 将每一行按照逗号分割,提取出数据和标签。
- 将数据和标签分别存储在两个列表中。
- 打印读取的数据条数。
- 返回数据和标签列表。
-
jdDataset类:- 这是一个自定义的数据集类,继承自
Dataset类,用于在PyTorch中处理数据。 - 在初始化时,接收数据和标签,并将标签转换为PyTorch的
LongTensor类型。 - 实现
__getitem__方法,用于通过索引获取数据和标签。 - 实现
__len__方法,返回数据集的大小。
- 这是一个自定义的数据集类,继承自
-
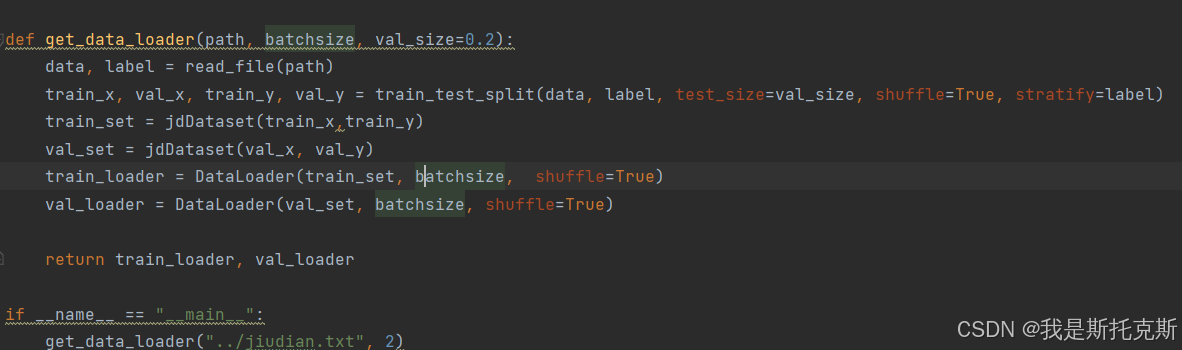
get_data_loader函数:- 接收文件路径、批量大小以及验证集比例(默认为0.2)。
- 调用
read_file函数读取数据。 - 使用
train_test_split函数将数据分为训练集和验证集,同时保持标签的分布。 - 创建
jdDataset类的实例,分别用于训练集和验证集。 - 使用
DataLoader类创建训练集和验证集的数据加载器,这些加载器会在训练过程中批量提供数据,并且可以指定是否打乱数据顺序。
总的来说,这些函数和类的组合使得从文件中读取数据、划分数据集、创建数据加载器的过程变得更加方便,便于后续在PyTorch中进行模型的训练和验证。
二、model.py
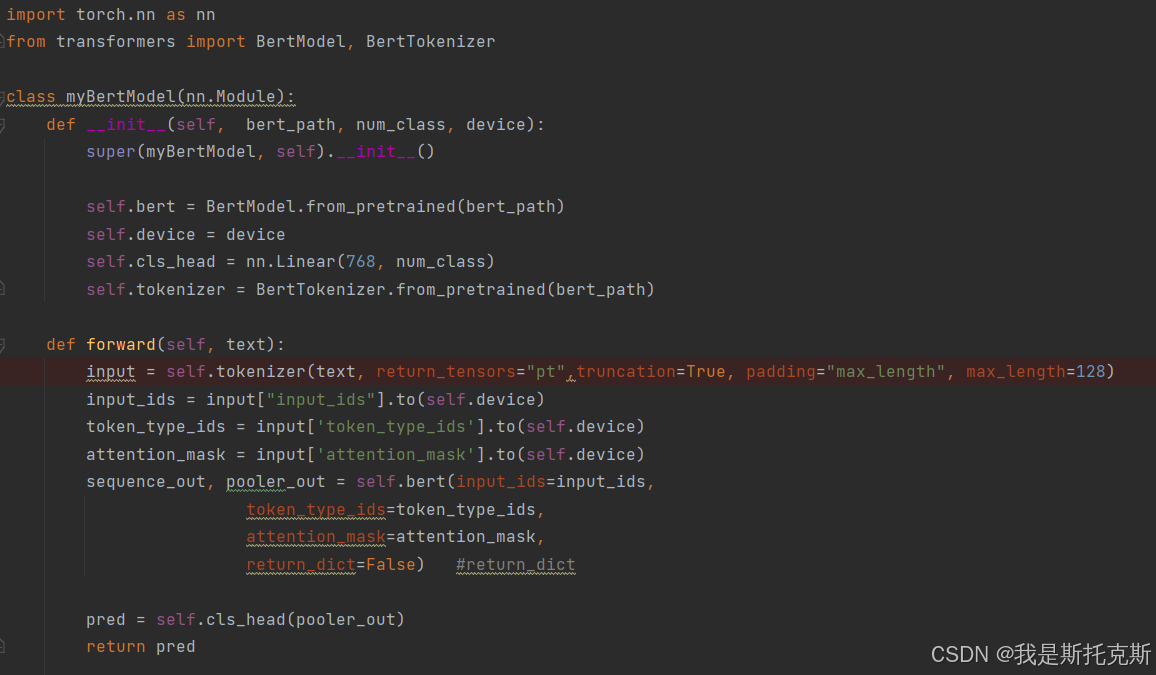
这段代码定义了一个名为myBertModel的PyTorch模块,它是一个基于BERT(Bidirectional Encoder Representations from Transformers)的模型,用于文本分类任务。以下是该类的功能和各个部分的作用:
-
__init__方法:- 初始化父类
nn.Module。 - 加载预训练的BERT模型,指定模型路径
bert_path。 - 保存设备信息(如CPU或GPU),用于将模型和数据移动到指定设备上。
- 定义一个线性层
cls_head,用于将BERT模型的输出转换为所需的类别数num_class。 - 初始化BERT的tokenizer,用于将文本转换为模型所需的输入格式。
- 初始化父类
-
forward方法:- 接收原始文本数据
text。 - 使用tokenizer对文本进行编码,包括转换为token IDs、添加分段token IDs和注意力掩码,并且将文本截断或填充到最大长度128。
- 将编码后的数据移动到指定设备上(CPU或GPU)。
- 将编码后的数据(
input_ids、token_type_ids、attention_mask)输入到BERT模型中,获取序列输出和池化层输出。 - 将池化层输出
pooler_out通过定义的线性层cls_head进行分类预测。 - 返回预测结果
pred。
- 接收原始文本数据
这个模型的工作流程大致如下:
- 输入文本数据。
- 使用BERT tokenizer将文本数据转换为模型可接受的格式。
- 将这些格式化的数据传递给BERT模型。
- BERT模型输出文本的编码表示。
- 通过一个线性层将BERT的编码表示转换为类别预测。
- 输出最终的分类预测结果。
这个模型可以用于各种文本分类任务,例如情感分析、主题分类等。在训练过程中,你需要提供一个包含文本和对应标签的数据集,并使用适当的损失函数和优化器来调整模型参数。
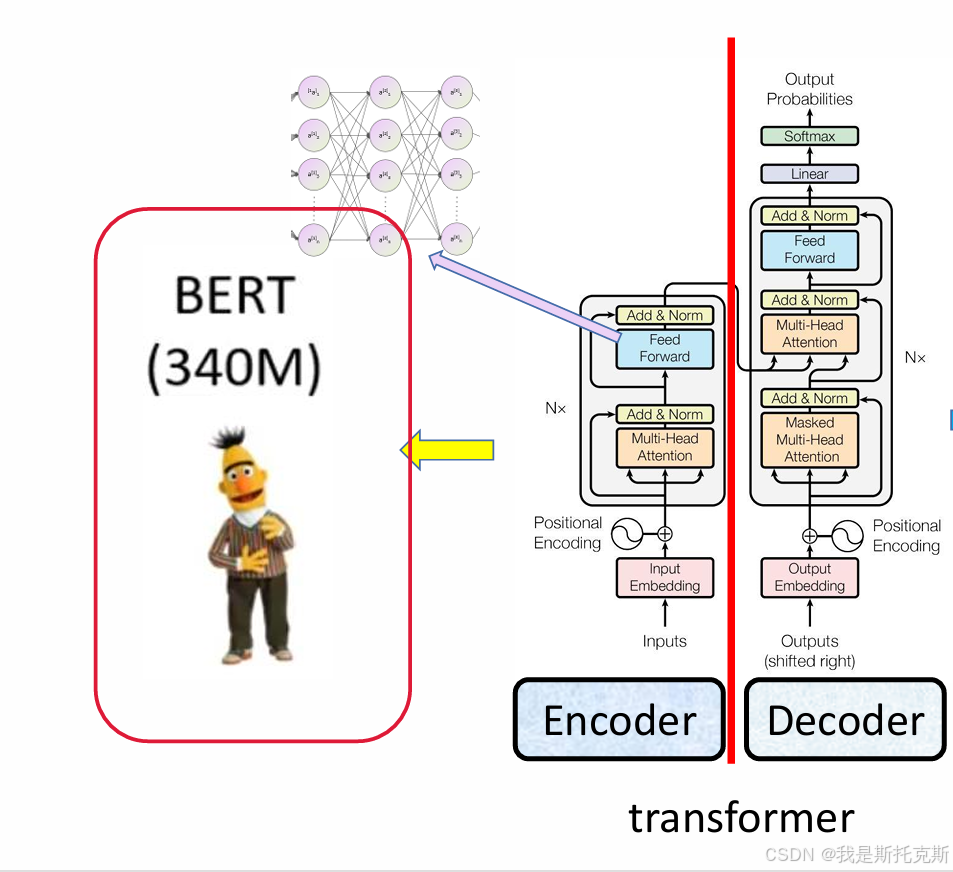
BERT(Bidirectional Encoder Representations from Transformers)模型架构是基于Transformer的编码器结构。以下是BERT模型的主要组成部分和其架构的特点:
主要组成部分:
-
Embedding Layer:
- Token Embeddings: 为每个词分配一个向量。
- Segment Embeddings: 为不同句子片段(例如,句子A和句子B)分配不同的向量。
- Positional Embeddings: 为句子中的每个词分配一个位置向量,以保留词序信息。
- 这些嵌入会被相加,形成最终的输入表示。
-
Transformer Encoder:
- 由多个相同的层堆叠而成,通常BERT使用的是Transformer的“Encoder”部分。
- 每个层包含两个子层:多头自注意力(Multi-Head Self-Attention)和位置全连接前馈网络(Position-wise Feed-Forward Networks)。
- 每个子层周围都有残差连接,后接层归一化(Layer Normalization)。
-
输出层:
- 对于预训练任务(如掩码语言建模和下一句预测),BERT模型的输出层会有特定的结构。
- 在微调任务中,通常会添加一个或多个线性层来生成最终的输出(例如,分类任务的类别预测)。
架构特点:
-
双向性 (Bidirectional): BERT是双向的,这意味着它同时考虑了输入序列中每个词的左右上下文。
-
多层堆叠 (Multi-layer): BERT通常有多个Transformer编码器层堆叠在一起(例如,BERT-Base有12层,BERT-Large有24层)。
-
多头注意力 (Multi-Head Attention): 在Transformer编码器层中,多头注意力机制允许模型在不同的表示子空间中并行地学习信息。
-
预训练任务:
- 掩码语言模型 (Masked Language Model, MLM): 随机掩盖输入序列中的一些词,并要求模型预测这些词。
- 下一句预测 (Next Sentence Prediction, NSP): 给定两个句子A和B,模型需要预测B是否是A的下一句。
模型变种:
- BERT-Base: 12层,768个隐藏单元,12个注意力头。
- BERT-Large: 24层,1024个隐藏单元,16个注意力头。
BERT模型因其强大的表示能力和在多种NLP任务中的优异表现而广受欢迎。在微调阶段,可以根据具体任务的需要对BERT模型进行微调,例如通过添加额外的输出层来实现分类、命名实体识别等任务。
三、train.py
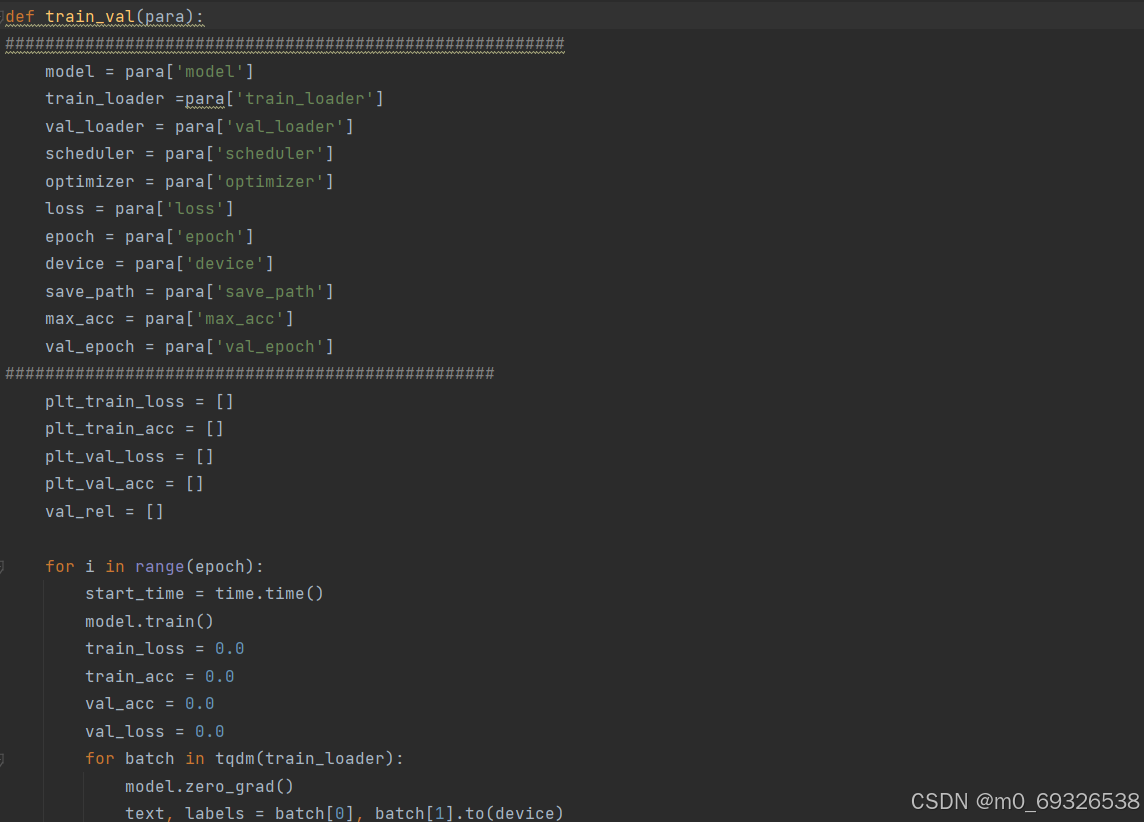
这个函数train_val用于训练和验证一个深度学习模型,具体来说,它执行以下步骤:
-
初始化参数:函数接收一个包含多个训练和验证所需参数的字典
para。 -
模型训练和验证循环:
- 对于每个epoch(指定的训练轮数):
- 训练阶段:
- 将模型设置为训练模式。
- 初始化训练损失和准确率为0。
- 对于训练数据加载器中的每个批次:
- 将梯度清零。
- 获取数据和标签,确保标签在正确的设备上。
- 通过模型进行前向传播以获得预测结果。
- 计算损失。
- 执行反向传播以计算梯度。
- 更新模型参数。
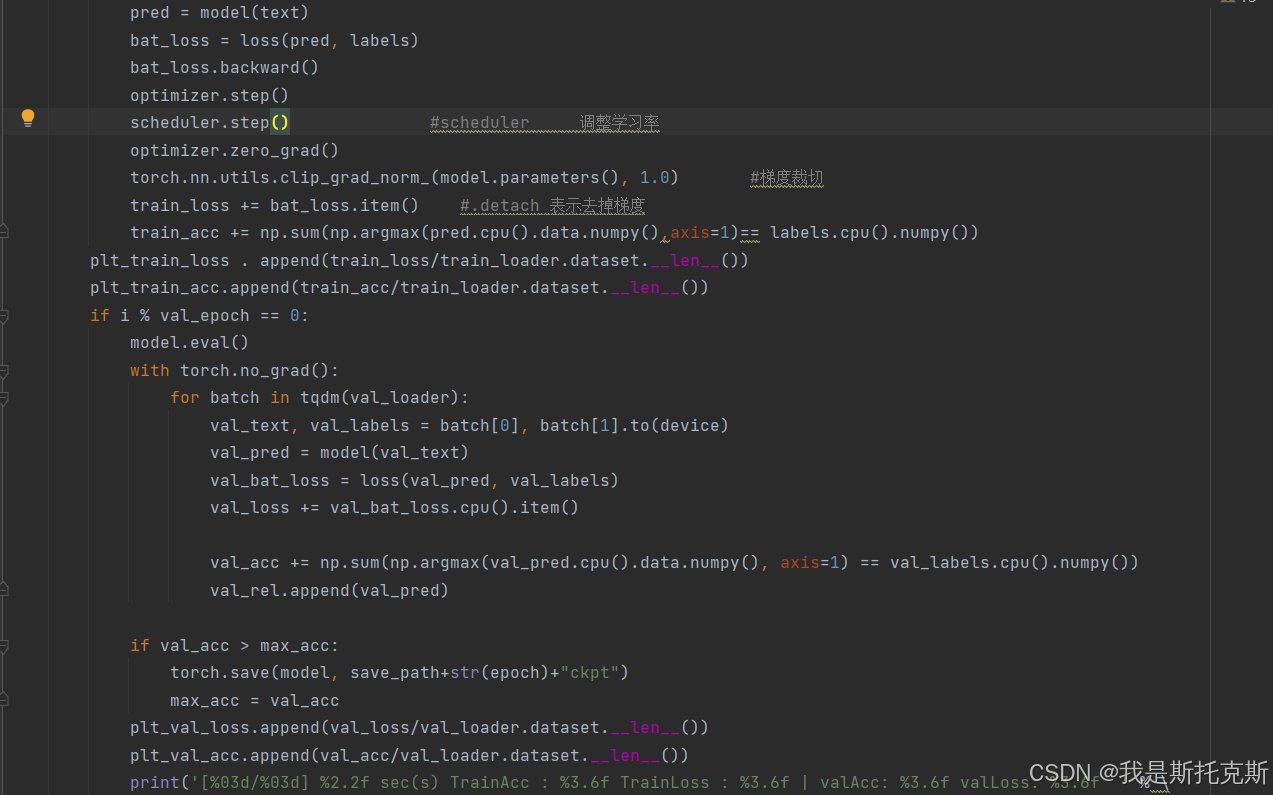
- 使用调度器调整学习率。
- 执行梯度裁剪以避免梯度爆炸。
- 累加批次损失和准确率。
- 记录训练损失和准确率。
- 验证阶段(每
val_epoch个epoch执行一次):- 将模型设置为评估模式。
- 初始化验证损失和准确率为0。
- 对于验证数据加载器中的每个批次:
- 获取数据和标签。
- 进行前向传播以获得预测结果,不计算梯度。
- 计算并累加批次损失和准确率。
- 如果当前验证准确率高于之前记录的最高准确率,则保存模型。
- 记录验证损失和准确率。
- 打印当前epoch的训练和验证统计信息。
- 训练阶段:
- 对于每个epoch(指定的训练轮数):
-
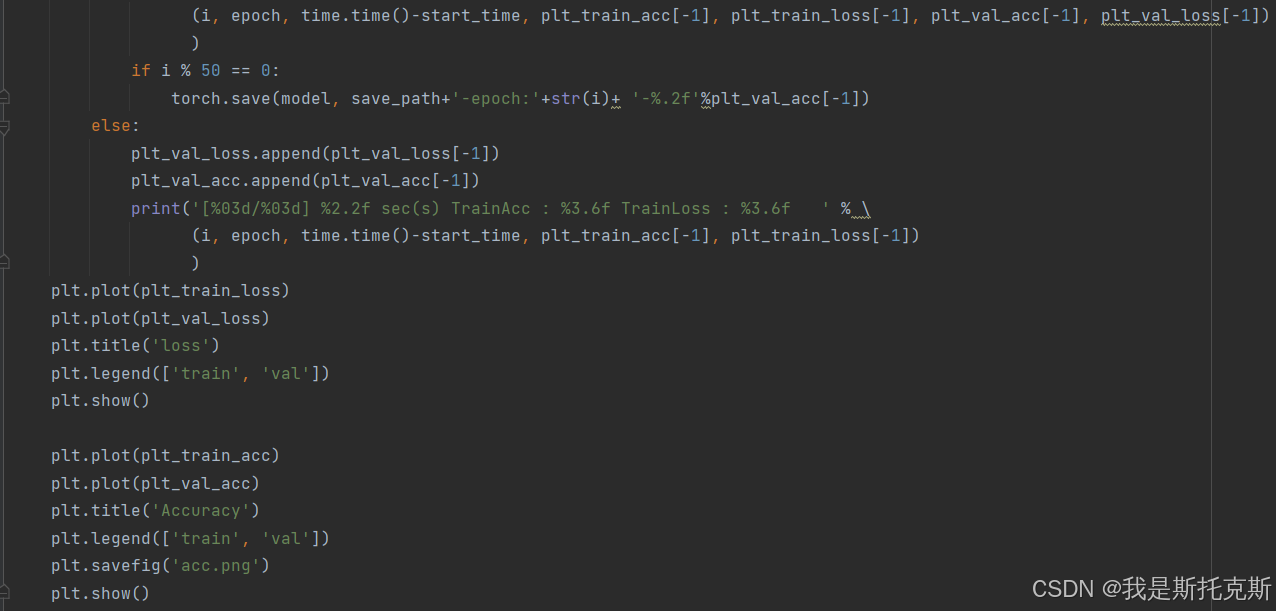
绘图:
- 绘制训练和验证损失曲线。
- 显示并保存训练和验证准确率曲线。
-
保存模型:
- 每隔50个epoch,保存当前模型。
以下是该函数的关键点:
- 使用
tqdm库来显示进度条。 - 使用
clip_grad_norm_来限制梯度的大小,防止梯度爆炸。 - 使用
torch.no_grad()在验证阶段禁用梯度计算,节省内存和计算资源。 - 保存准确率最高的模型和定期保存模型,以便于后续的模型评估和恢复。
整体上,这个函数提供了训练深度学习模型的一个标准流程,包括数据加载、模型训练、验证、学习率调整、梯度裁剪、模型保存和结果可视化。
四、main.py
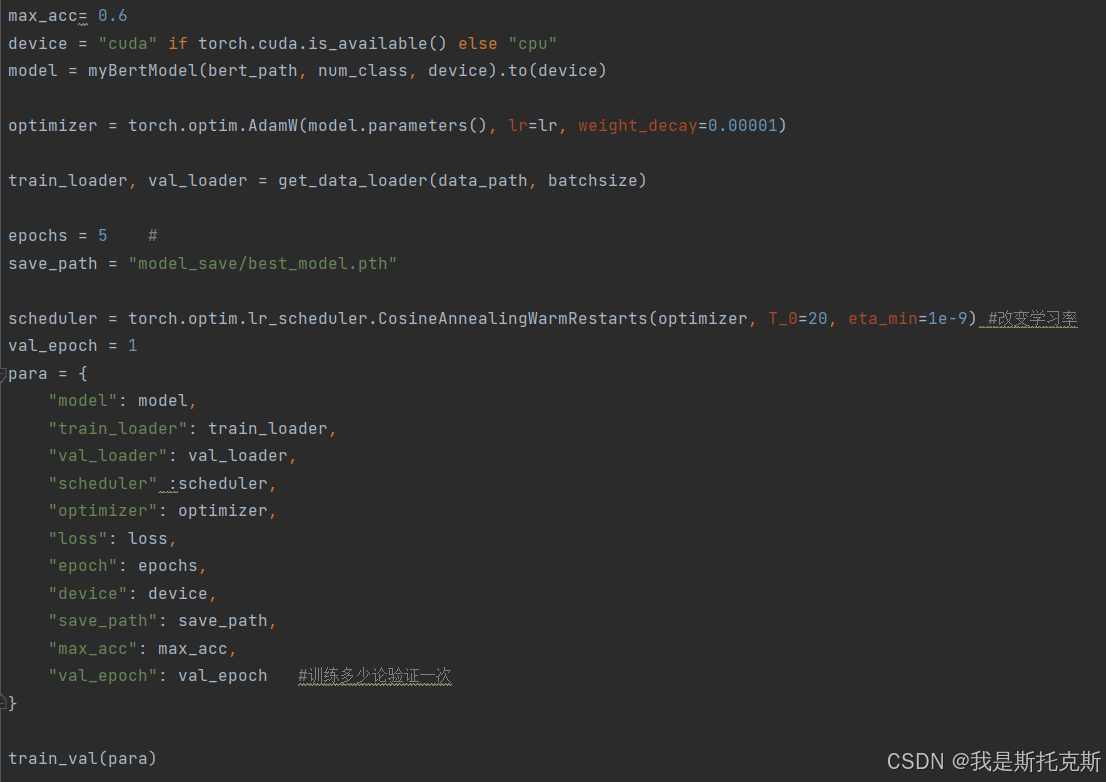
这段代码是一个使用PyTorch框架进行BERT模型训练的完整流程。以下是代码的主要功能和步骤:
-
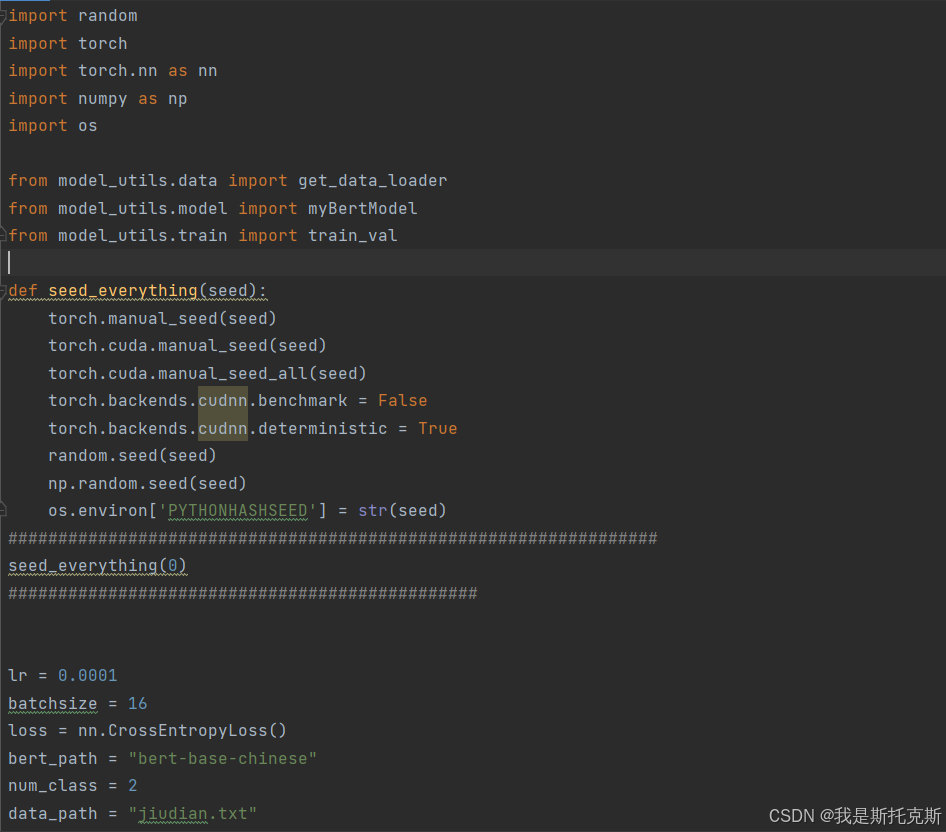
导入必要的库:导入random、torch、torch.nn、numpy、os等库,以及自定义的数据加载、模型和训练函数。
-
设置随机种子:
seed_everything函数用于设置各种库的随机种子,以确保实验的可重复性。 -
初始化训练参数:
- 设置学习率
lr。 - 设置批量大小
batchsize。 - 定义损失函数为交叉熵损失
nn.CrossEntropyLoss()。 - 设置BERT模型的路径
bert_path。 - 设置分类任务的类别数
num_class。 - 设置数据集路径
data_path。 - 设置模型保存的路径
save_path。 - 设置最大准确率阈值
max_acc,用于确定是否保存模型。 - 确定使用的设备是GPU(如果可用)还是CPU。
- 实例化模型、优化器和调度器:
- 实例化
myBertModel并移动到指定设备。 - 使用AdamW优化器初始化模型参数。
- 使用余弦退火预热重启调度器(
CosineAnnealingWarmRestarts)调整学习率。
-
获取数据加载器:调用
get_data_loader函数来获取训练集和验证集的数据加载器。 -
定义训练参数字典
para:将模型、数据加载器、优化器、调度器、损失函数、训练轮数、设备、保存路径、最大准确率和验证间隔等参数封装到一个字典中。 -
调用
train_val函数:使用定义的参数开始模型的训练和验证过程。
总的来说,这段代码执行以下操作:
- 初始化实验环境,确保结果的可重复性。
- 配置模型训练的超参数。
- 实例化BERT模型、优化器和调度器。
- 加载训练和验证数据。
- 开始训练和验证过程,期间会定期保存准确率最高的模型。
这个流程是训练BERT模型进行文本分类任务的标准步骤。

















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









