






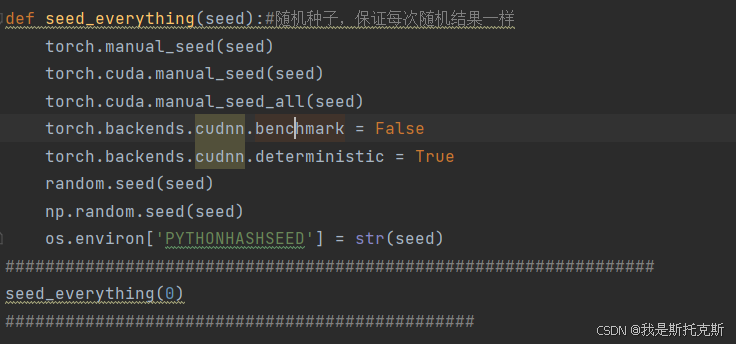
总的来说,通过设置这些种子,seed_everything函数确保了在深度学习训练过程中,所有随机操作(如初始化权重、打乱数据集等)都是可复现的。这对于调试和科学研究特别重要,因为可复现的结果是验证研究有效性的关键。
当调用seed_everything(0)时,函数会将所有上述提到的随机数生成器的种子设置为0,从而确保在接下来的代码执行中,任何随机操作都将按照固定的模式进行,使得实验结果可以复现
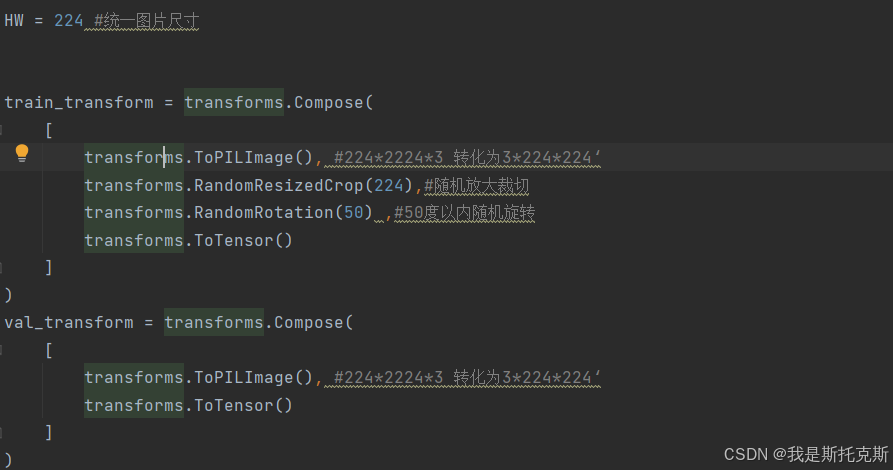
这段代码定义了两个图像变换序列,一个用于训练数据(train_transform),另一个用于验证数据(val_transform)。这些变换是使用PyTorch的torchvision.transforms模块来完成的,它们通常用于预处理图像数据,特别是在深度学习模型的训练过程中。
具体来说,以下是每个变换的作用:
-
HW = 224:- 设置一个变量
HW为224,这代表图片的宽度和高度都将被调整到224像素。
- 设置一个变量
-
train_transform:transforms.ToPILImage(): 将输入的图像数据(假设是一个NumPy数组或PIL图像)转换为PIL图像格式。如果输入图像的形状是224x224x3,则转换后的图像形状是3x224x224,这代表3个颜色通道,宽度和高度分别为224像素。transforms.RandomResizedCrop(224): 随机裁剪图像,然后将其缩放到指定的尺寸(224x224像素)。这是数据增强的一种方式,可以提高模型对图像尺寸变化的鲁棒性。transforms.RandomRotation(50): 随机旋转图像,旋转角度在0到50度之间。这也是一种数据增强技术,有助于模型学习到旋转不变性。transforms.ToTensor(): 将PIL图像或NumPy数组转换为浮点张量,并标准化其值到[0, 1]范围内,同时将其形状从HxWxC转换为CxHxW,这是PyTorch模型期望的输入格式。
-
val_transform:transforms.ToPILImage(): 与训练变换中的相同,将图像转换为PIL图像格式。transforms.ToTensor(): 与训练变换中的相同,将PIL图像转换为张量。
总结来说,train_transform用于对训练数据进行一系列的数据增强操作,以增加模型训练时的数据多样性,帮助模型泛化得更好。而val_transform则简单地将验证数据转换为模型所需的格式,没有应用数据增强,因为验证数据是用来评估模型性能的,需要保持原始数据的特点。
一、Dataset
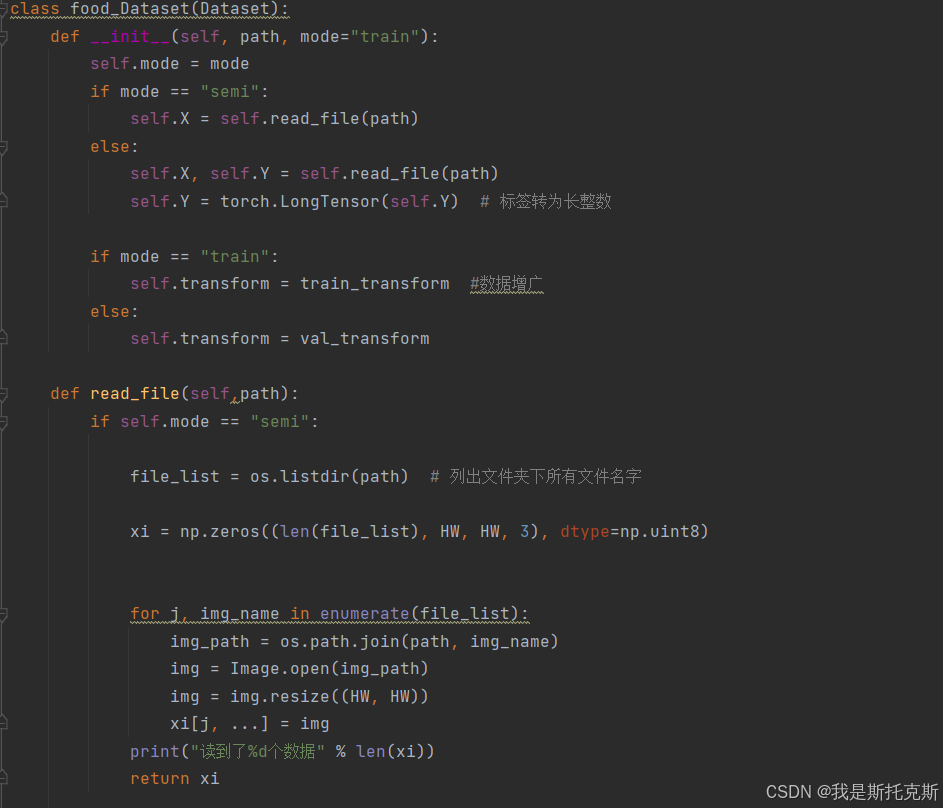
这段代码定义了一个名为food_Dataset的类,它继承自PyTorch的Dataset类。这个类用于创建一个自定义的数据集,专门用于处理和加载与食物相关的图像数据。以下是该类的详细功能和操作:
-
__init__(self, path, mode="train"):- 初始化方法接收两个参数:
path(数据集的路径)和mode(指定数据集的模式,默认为"train")。 - 根据
mode的不同,food_Dataset类会以不同的方式读取和处理数据。 - 如果
mode是"semi",表示半监督学习模式,只读取图像数据,不读取标签。 - 如果
mode不是"semi",表示全监督学习模式,同时读取图像数据和对应的标签,并将标签转换为长整数张量。 - 根据
mode是"train"还是其他(如"val"),选择不同的图像变换序列(train_transform或val_transform)。
- 初始化方法接收两个参数:
-
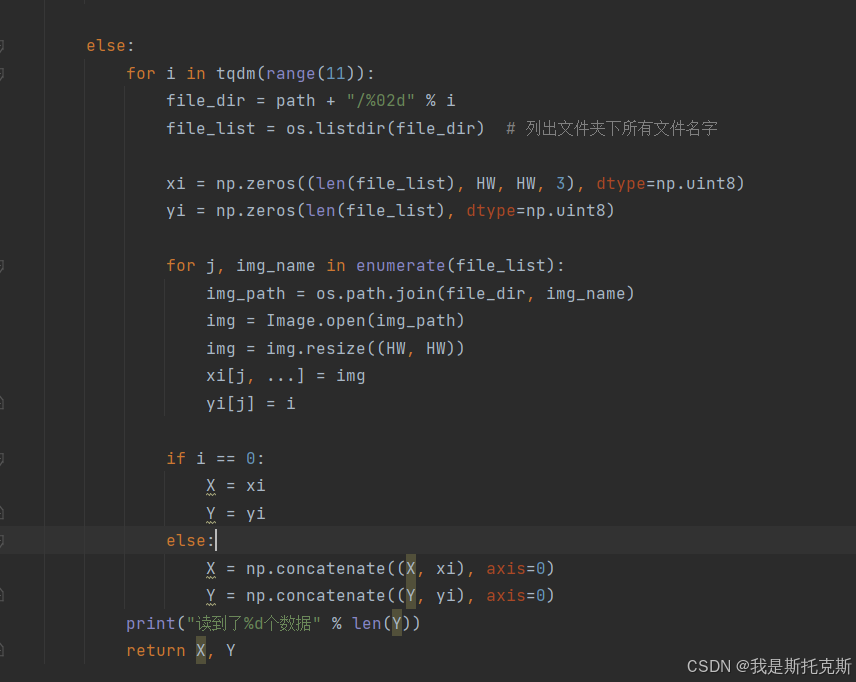
read_file(self, path):- 这个方法用于读取图像文件和标签。
- 如果
mode是"semi",它会列出指定路径下的所有文件,创建一个numpy数组来存储图像数据,并将每个图像调整为固定大小(HW x HW),然后存储在数组中。 - 如果
mode不是"semi",它会遍历不同的类别文件夹(假设有0到10共11个类别),读取每个文件夹下的图像和对应的标签,将图像调整为固定大小,并将图像数据和标签分别存储在numpy数组中。最后,将这些数组沿着第一个轴(axis=0)连接起来,形成一个大的图像数组和标签数组。
-
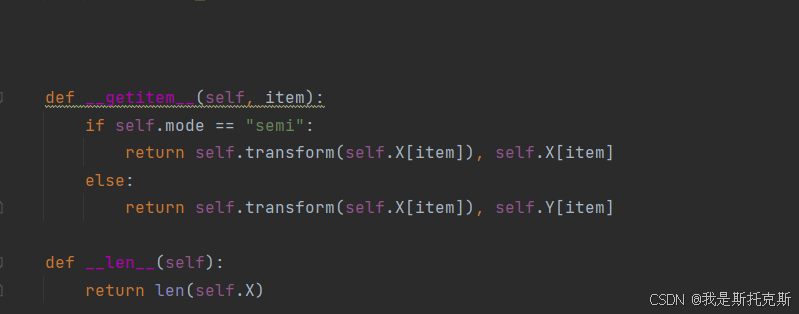
__getitem__(self, item):- 这个方法允许通过索引
item来获取数据集中的单个样本。 - 如果
mode是"semi",返回经过变换的图像和原始图像。 - 如果
mode不是"semi",返回经过变换的图像和对应的标签。
- 这个方法允许通过索引
-
__len__(self):- 这个方法返回数据集中样本的总数。
总的来说,food_Dataset类的作用是:
- 从指定的路径加载数据集的图像和标签。
- 将图像调整为统一的大小。
- 根据不同的模式(训练、验证或半监督学习),应用不同的图像变换。
- 提供一个接口,允许通过索引访问数据集中的单个样本,以及获取数据集的总长度。
这个semiDataset类是用于半监督学习的自定义PyTorch Dataset。以下是该类的详细功能和操作:
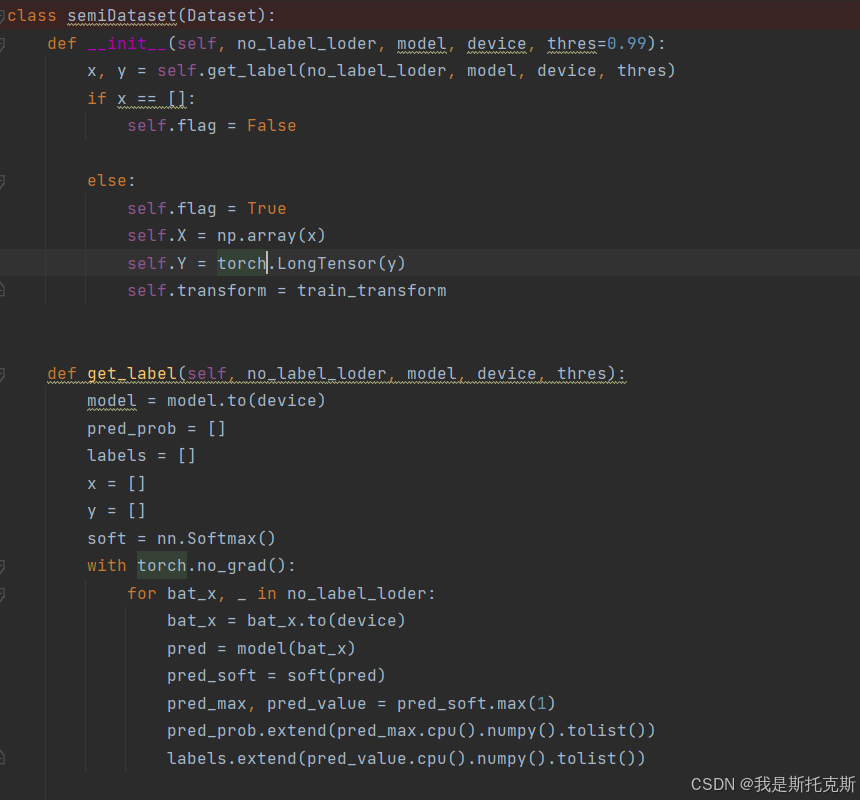
-
__init__(self, no_label_loader, model, device, thres=0.99):- 初始化方法接收四个参数:
no_label_loader(一个没有标签的数据加载器),model(一个预训练的模型,用于预测标签),device(用于运行模型的设备,如CPU或GPU),以及一个可选参数thres(一个阈值,用于确定预测的置信度是否足够高以被视为可靠标签)。 - 在初始化过程中,它调用
get_label方法来获取没有标签数据的预测标签。 - 如果没有可靠的预测标签(即
x为空列表),则设置flag为False。 - 如果有可靠的预测标签,则将
flag设置为True,并将预测数据的图像和标签转换为numpy数组和torch张量,并设置图像变换为train_transform。
- 初始化方法接收四个参数:
-
get_label(self, no_label_loader, model, device, thres):- 这个方法使用预训练的模型
model来预测没有标签的数据加载器no_label_loader中的数据的标签。 - 它将模型移动到指定的
device上,并设置为评估模式(通过torch.no_grad())。 - 对于数据加载器中的每个批次,它预测标签,应用softmax函数,并获取最大概率及其对应的标签。
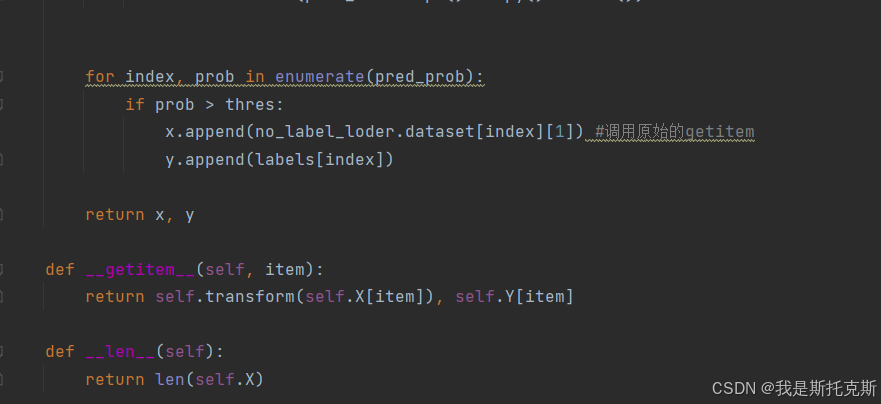
- 然后,它根据阈值
thres筛选出高置信度的预测,并将这些预测的图像和标签存储在列表中。 - 最后,返回筛选后的图像和标签列表。
- 这个方法使用预训练的模型
-
__getitem__(self, item):- 这个方法允许通过索引
item来获取数据集中的单个样本。 - 它返回经过变换的图像和对应的预测标签。
- 这个方法允许通过索引
-
__len__(self):- 这个方法返回数据集中样本的总数。
总的来说,semiDataset类的作用是:
- 使用预训练的模型为没有标签的数据生成伪标签。
- 保留那些模型预测置信度高于特定阈值的数据。
- 提供一个接口,允许通过索引访问数据集中的单个样本,以及获取数据集的总长度,以便于后续的模型训练。
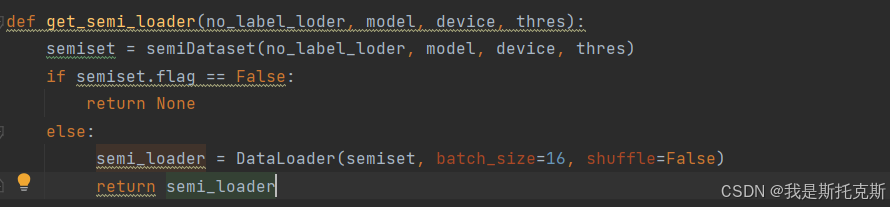
这个get_semi_loader函数的目的是创建一个用于半监督学习的PyTorch DataLoader。以下是该函数的详细功能和操作:
-
函数接收四个参数:
no_label_loader:一个没有标签的数据加载器。model:一个预训练的模型,用于预测标签。device:用于运行模型的设备,如CPU或GPU。thres:一个阈值,用于确定预测的置信度是否足够高以被视为可靠标签。
-
函数内部操作:
- 首先,它实例化
semiDataset类,创建一个名为semiset的数据集对象。这个对象会使用预训练的model为no_label_loader中的数据生成伪标签,并筛选出高置信度的预测。 - 接着,函数检查
semiset.flag。如果flag为False,这意味着没有足够高置信度的预测标签,因此函数返回None。 - 如果
flag为True,这意味着有可靠的预测标签,函数会继续创建一个DataLoader对象semi_loader。这个DataLoader会以batch_size=16和shuffle=False(默认值,可能根据需要修改)的配置来加载数据集semiset。
- 首先,它实例化
-
函数返回:
- 如果有可靠的预测标签,函数返回一个
DataLoader对象,可以用于后续的模型训练。 - 如果没有可靠的预测标签,函数返回
None。
- 如果有可靠的预测标签,函数返回一个
总的来说,get_semi_loader函数的作用是:
- 使用预训练的模型为无标签数据生成伪标签。
- 如果生成了足够多的高置信度伪标签,则创建并返回一个
DataLoader对象,用于加载这些伪标签数据以进行半监督学习。 - 如果没有生成足够的伪标签,则不返回任何
DataLoader对象。
二、Model
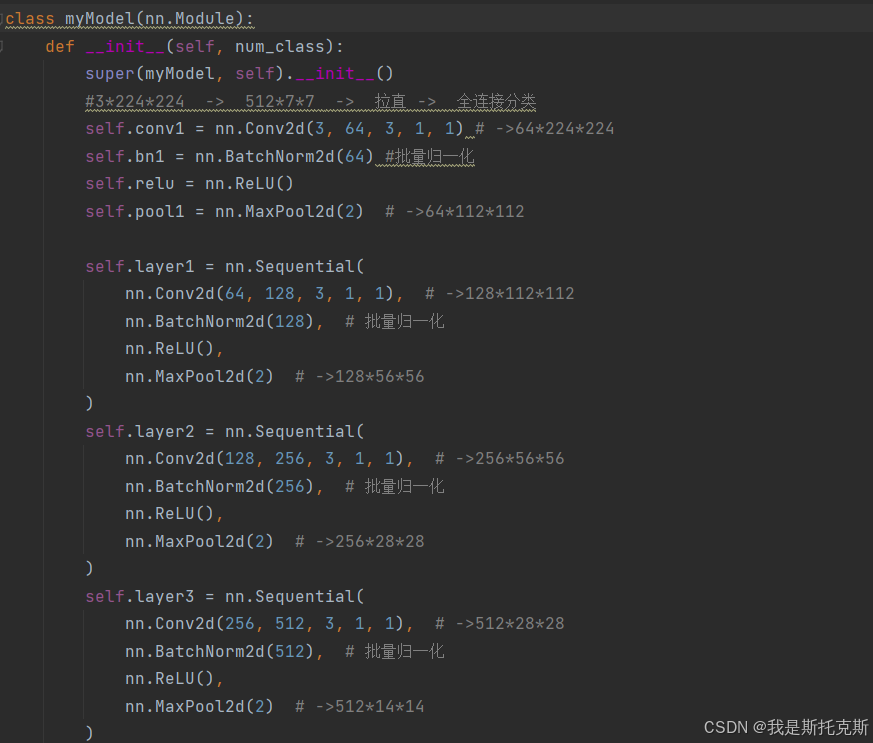
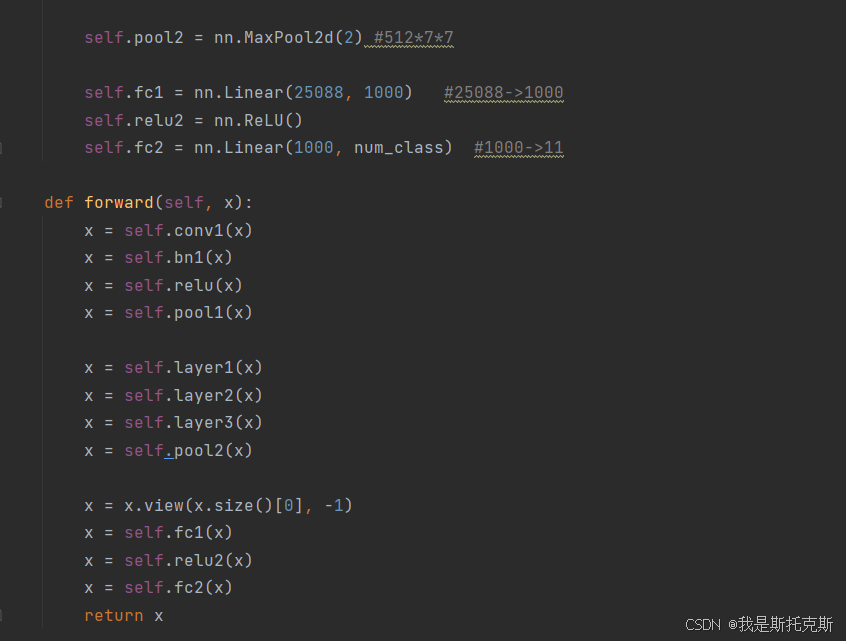
在myModel类中,特征图的维度变换过程如下:
-
初始输入图像的维度为 (batch_size, 3, 224, 224),其中:
- batch_size 是批量大小。
- 3 是图像的通道数(RGB)。
- 224x224 是图像的高度和宽度。
-
经过
self.conv1卷积层后,特征图的维度变为 (batch_size, 64, 224, 224):- 使用了64个3x3的卷积核,步长为1,填充为1。
-
经过
self.bn1批量归一化层,特征图的维度不变,仍然是 (batch_size, 64, 224, 224)。 -
经过
self.reluReLU激活函数,特征图的维度不变。 -
经过
self.pool1最大池化层,特征图的维度变为 (batch_size, 64, 112, 112):- 使用了2x2的池化窗口,步长默认为窗口大小,因此特征图尺寸减半。
-
经过
self.layer1序列层,特征图的维度变为 (batch_size, 128, 56, 56):- 先经过一个卷积层,维度变为 (batch_size, 128, 112, 112)。
- 然后经过批量归一化、ReLU激活函数和最大池化层,维度变为 (batch_size, 128, 56, 56)。
-
经过
self.layer2序列层,特征图的维度变为 (batch_size, 256, 28, 28):- 先经过一个卷积层,维度变为 (batch_size, 256, 56, 56)。
- 然后经过批量归一化、ReLU激活函数和最大池化层,维度变为 (batch_size, 256, 28, 28)。
-
经过
self.layer3序列层,特征图的维度变为 (batch_size, 512, 14, 14):- 先经过一个卷积层,维度变为 (batch_size, 512, 28, 28)。
- 然后经过批量归一化、ReLU激活函数和最大池化层,维度变为 (batch_size, 512, 14, 14)。
-
经过
self.pool2最大池化层,特征图的维度变为 (batch_size, 512, 7, 7):- 使用了2x2的池化窗口,步长默认为窗口大小,因此特征图尺寸再次减半。
-
特征图被拉直成一维向量,维度变为 (batch_size, 25088):
- 这里的25088是通过计算得到的,即 512 (通道数) * 7 (高度) * 7 (宽度)。
-
经过
self.fc1全连接层,特征图的维度变为 (batch_size, 1000)。 -
经过
self.relu2ReLU激活函数,特征图的维度不变。 -
最后,经过
self.fc2全连接层,特征图的维度变为 (batch_size, num_class),其中num_class是类别数量。
以上就是整个特征图维度变换的过程。
但在实际训练中,自己的模型效果太差,所以只作为理解参考。使用了迁移学习,借鉴了大佬的模型

initialize_model函数是一个自定义函数,它用于初始化一个预训练的ResNet-18模型,并对其进行一些定制,以便它可以用于特定的任务。根据给出的函数调用model, _ = initialize_model("resnet18", 11, use_pretrained=True),以下是对这个函数调用中每个参数的解释:
-
"resnet18": 这是一个字符串参数,指定了要使用的模型架构。在这个例子中,它指定了ResNet-18架构。 -
11: 这是一个整数参数,指定了输出层的类别数量。在这个例子中,模型将用于一个有11个类别的分类任务。 -
use_pretrained=True: 这是一个布尔参数,指定是否使用在ImageNet数据集上预训练的模型权重。设置为True意味着模型将使用预训练的权重。
三、train
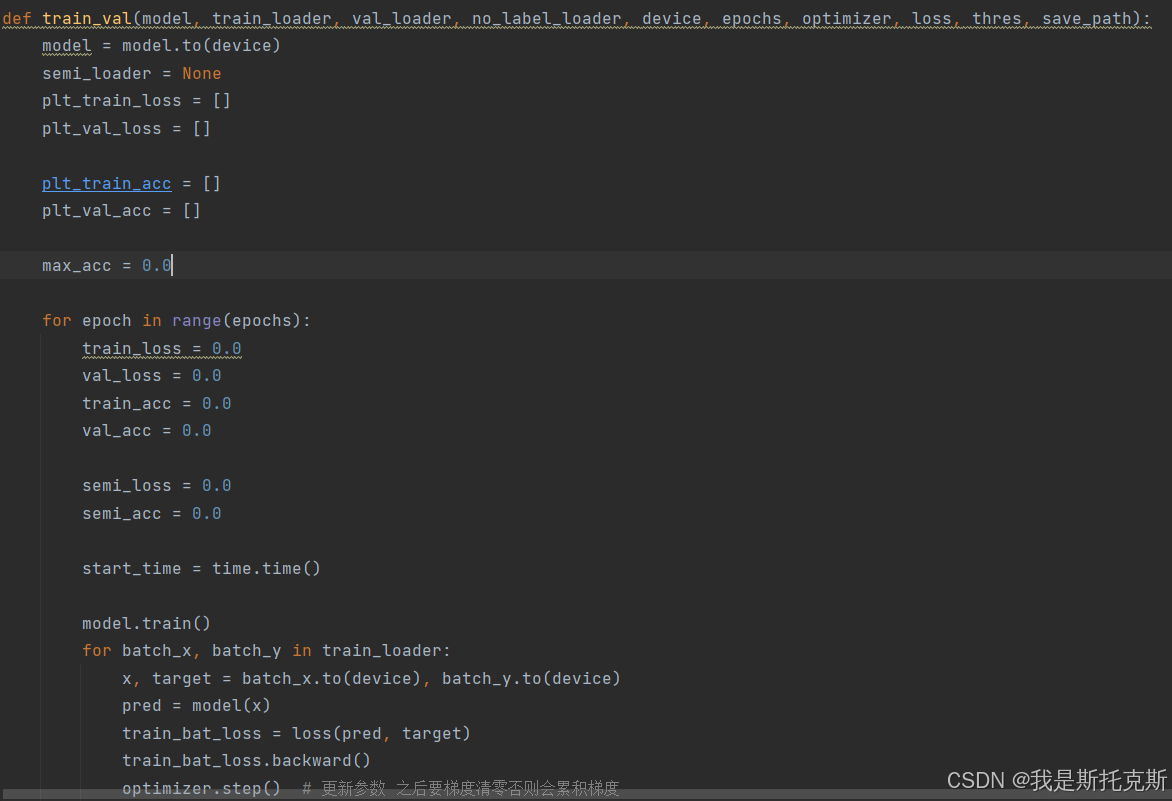
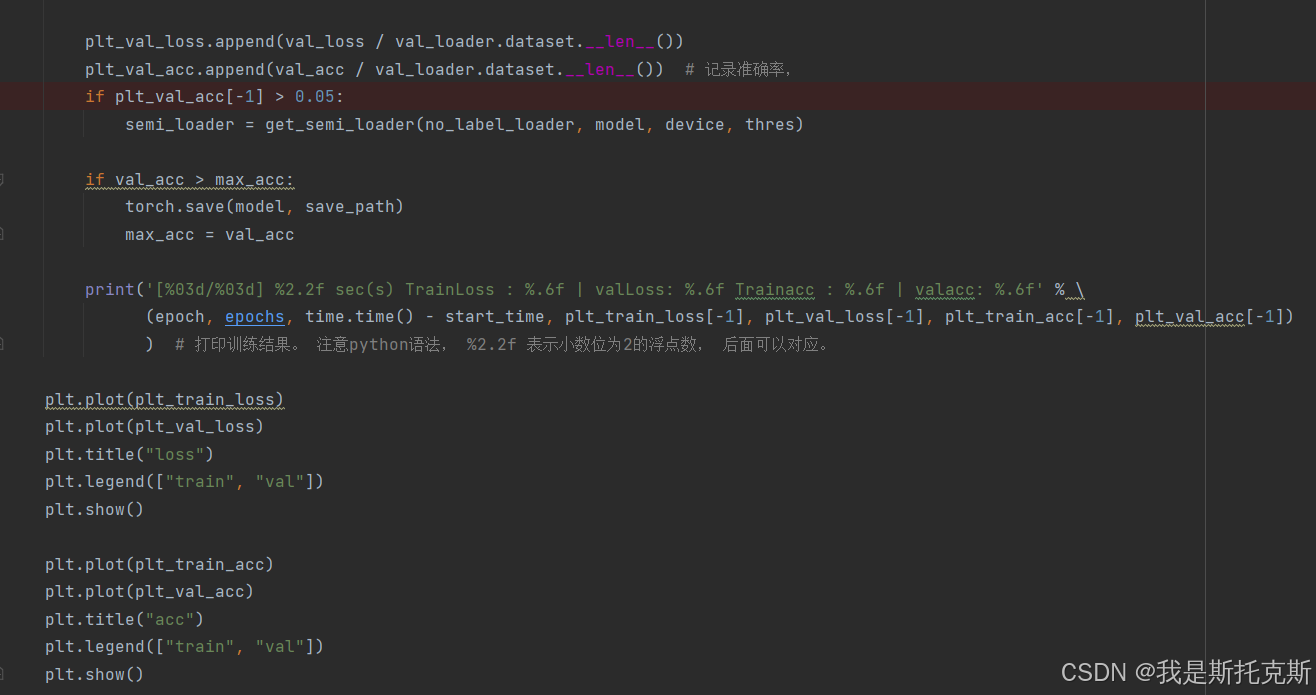
以下是train_val函数的详细解释,包括每一步的具体操作:
-
模型和设备配置:
python
复制
model = model.to(device)这行代码将模型移动到指定的设备上(CPU或GPU)。
-
初始化变量:
python
复制
semi_loader = None plt_train_loss = [] plt_val_loss = [] plt_train_acc = [] plt_val_acc = [] max_acc = 0.0初始化半监督数据加载器为
None,以及用于存储训练和验证损失及准确率的列表。max_acc用于跟踪最高的验证准确率。 -
训练和验证循环:
python
复制
for epoch in range(epochs):开始一个循环,迭代指定的
epochs次数。 -
每个epoch的初始化:
python
复制
train_loss = 0.0 val_loss = 0.0 train_acc = 0.0 val_acc = 0.0 semi_loss = 0.0 semi_acc = 0.0 start_time = time.time()在每个epoch开始时,重置训练损失、验证损失、训练准确率、验证准确率、半监督损失和准确率,并记录开始时间。
-
训练模式:
python
复制
model.train()将模型设置为训练模式,这对于某些层(如BatchNorm和Dropout)是必要的。
-
训练过程:
python
复制
for batch_x, batch_y in train_loader: x, target = batch_x.to(device), batch_y.to(device) pred = model(x) train_bat_loss = loss(pred, target) train_bat_loss.backward() optimizer.step() optimizer.zero_grad() train_loss += train_bat_loss.cpu().item() train_acc += np.sum(np.argmax(pred.detach().cpu().numpy(), axis=1) == target.cpu().numpy())- 对于训练数据加载器中的每个批次,执行以下操作:
- 将数据和标签移动到指定设备。
- 通过模型前向传播得到预测结果。
- 计算损失。
- 执行反向传播以计算梯度。
- 更新模型的参数。
- 清零梯度。
- 累加批次损失和准确率。
- 对于训练数据加载器中的每个批次,执行以下操作:
-
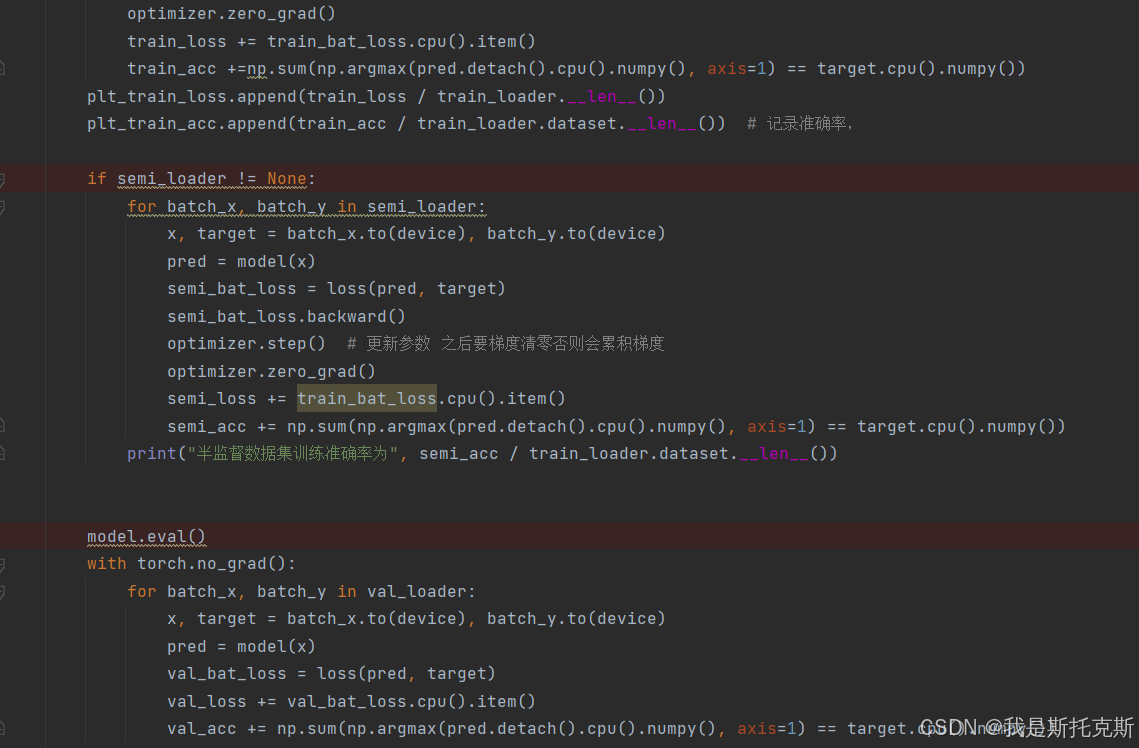
记录训练结果:
python
复制
plt_train_loss.append(train_loss / train_loader.__len__()) plt_train_acc.append(train_acc / train_loader.dataset.__len__())将平均训练损失和准确率记录到列表中。
-
半监督训练(如果适用):
python
复制
if semi_loader != None: # ... (与训练过程类似)如果有半监督数据加载器,对无标签数据进行类似的训练过程。
-
评估模式:
python
复制
model.eval() with torch.no_grad(): # ... (与训练过程类似,但不执行反向传播)将模型设置为评估模式,并禁用梯度计算,然后对验证数据进行前向传播,计算损失和准确率。
-
记录验证结果:
python
复制
plt_val_loss.append(val_loss / val_loader.dataset.__len__()) plt_val_acc.append(val_acc / val_loader.dataset.__len__())将平均验证损失和准确率记录到列表中。
-
半监督数据加载器生成:
python
复制
if plt_val_acc[-1] > 0.05: semi_loader = get_semi_loader(no_label_loader, model, device, thres)如果验证准确率超过阈值,则生成半监督数据加载器。
-
保存最佳模型:
python
复制
if val_acc > max_acc: torch.save(model, save_path) max_acc = val_acc如果当前验证准确率高于之前的最大准确率,则保存模型。
-
打印训练和验证结果:
python
复制
print('[%03d/%03d] %2.2f sec(s) TrainLoss : %.6f | valLoss: %.6f Trainacc : %.6f | valacc: %.6f' % \ (epoch, epochs, time.time() - start_time, plt_train_loss[-1], plt_val_loss[-1], plt_train_acc[-1], plt_val_acc[-1]))打印每个epoch的训练和验证结果。
-
绘制损失和准确率曲线:
python
复制
plt.plot(plt_train_loss) plt.plot(plt_val_loss) plt.title("loss") plt.legend(["train", "val"])
四、main
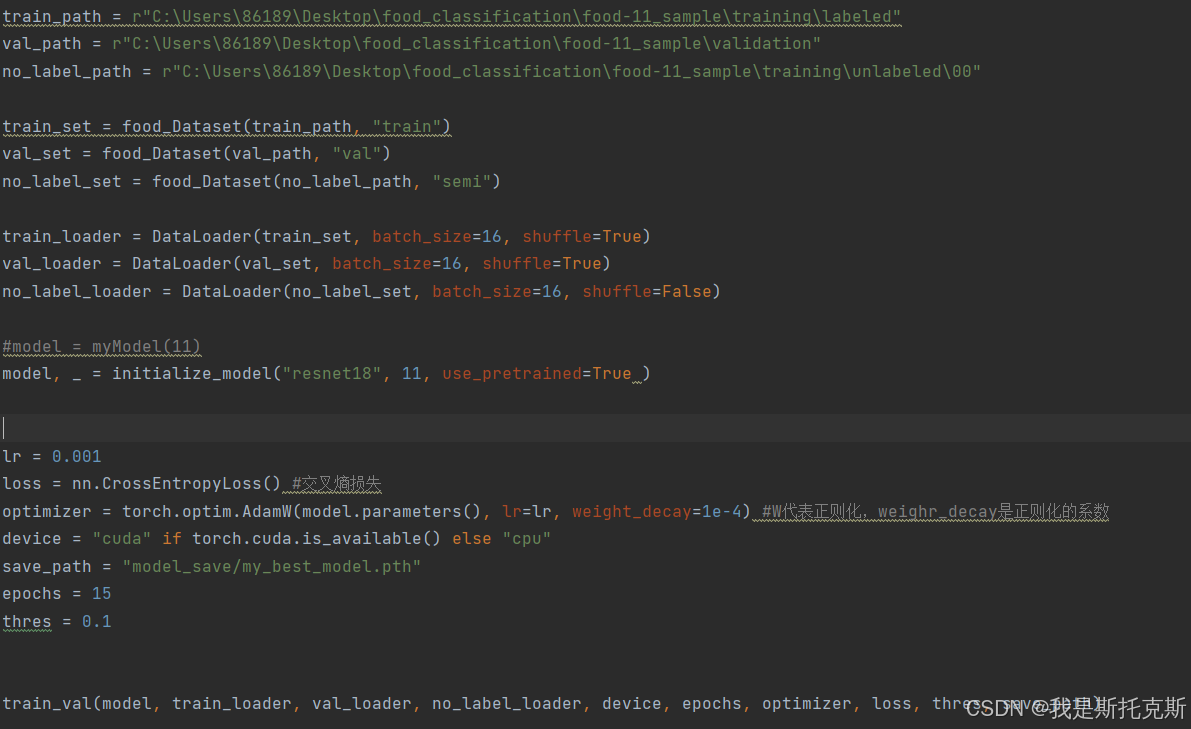
上述代码执行的是深度学习中的数据预处理、模型初始化、训练和验证的完整流程。以下是每一步的详细解释:
-
设置数据路径:
train_path,val_path,no_label_path:定义了训练数据、验证数据和无标签数据的文件系统路径。
-
创建数据集:
train_set = food_Dataset(train_path, "train"):创建一个food_Dataset对象,用于加载训练数据集,并设置为训练模式。val_set = food_Dataset(val_path, "val"):创建一个food_Dataset对象,用于加载验证数据集,并设置为验证模式。no_label_set = food_Dataset(no_label_path, "semi"):创建一个food_Dataset对象,用于加载无标签的数据集,并设置为半监督学习模式。
-
创建数据加载器:
train_loader,val_loader,no_label_loader:使用DataLoader类创建数据加载器,它们会在训练过程中批量加载数据,并且可以选择打乱数据(对于训练集)。
-
初始化模型:
model, _ = initialize_model("resnet18", 11, use_pretrained=True):初始化一个预训练的ResNet-18模型,并将最后的全连接层调整为对应11个类别的输出。
-
设置训练参数:
lr:学习率。loss:损失函数,这里使用交叉熵损失,适用于多分类问题。optimizer:优化器,这里使用带有权重衰减(L2正则化)的AdamW优化器。device:选择运行模型的设备,优先使用CUDA(GPU),如果不可用则使用CPU。save_path:模型保存的路径。epochs:训练的总轮数。thres:一个阈值,可能在训练过程中用于某些决策,比如是否应用半监督学习策略。
-
执行训练和验证:
train_val(model, train_loader, val_loader, no_label_loader, device, epochs, optimizer, loss, thres, save_path):调用train_val函数开始训练和验证过程。这个函数将使用提供的参数进行模型训练,并在每个epoch后评估模型在验证集上的性能。如果验证准确率提高,模型将被保存。无标签的数据加载器可能用于半监督学习。
总的来说,这个过程是设置环境、加载数据、初始化模型、配置训练参数,然后开始训练和验证模型,并在训练过程中保存最佳模型。

















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









