






import os
import base64
import sys
from bs4 import BeautifulSoup
# 环境 有python编译器 本人在pycharm中安装库文件
# 首先在设置中的python解释器中安装Beautifulsoup4库,然后在终端通过镜像源安装lxml库
# python -m pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
# 将保存好的typora_images.py放到html的同级目录下
# 在html目录运行终端后 输入:python typora_images.py "你的笔记.html"
SUPPORTED_EXT = {
'.png':'image/png',
'.jpg':'image/jpeg',
'.jpeg':'image/jpeg',
'.gif':'image/gif',
'.bmp':'image/bmp',
'.svg':'image/svg+xml',
'.webp':'image/webp'
}
def get_image_datauri (image_path):
"""将图片转换为Base64 Data URI"""
try:
ext = os.path.splitext (image_path) [1].lower ()
if ext not in SUPPORTED_EXT:
raise ValueError (f"不支持的图片格式: {ext}")
with open (image_path,'rb') as img_file:
encoded = base64.b64encode (img_file.read ()).decode ('utf-8')
return f"data:{SUPPORTED_EXT [ext]};base64,{encoded}"
except Exception as e:
print (f"处理图片失败: {image_path}\n错误详情: {str (e)}")
return None
def process_html (html_file):
"""处理HTML文件"""
try:
with open (html_file,'r',encoding = 'utf-8') as f:
soup = BeautifulSoup (f,'lxml') # 明确指定使用lxml解析器
base_dir = os.path.dirname (os.path.abspath (html_file))
modified = False
for img in soup.find_all ('img'):
src = img.get ('src','')
if src.startswith (('http://','https://','data:')):
continue
img_path = os.path.normpath (os.path.join (base_dir,src))
if not os.path.exists (img_path):
print (f"图片不存在: {img_path}")
continue
data_uri = get_image_datauri (img_path)
if data_uri:
img ['src'] = data_uri
modified = True
print (f"成功处理: {os.path.basename (img_path)}")
if modified:
output_file = html_file.replace ('.html','_plus.html')
with open (output_file,'w',encoding = 'utf-8') as f:
f.write (str (soup))
print (f"\n 处理完成!已生成文件: {output_file}")
else:
print (" 未发现需要处理的本地图片")
except Exception as e:
print (f"严重错误: {str (e)}")
sys.exit (1)
if __name__ == '__main__':
if len (sys.argv) != 2:
print ("使用方法: python typora_images.py 你的文件.html")
sys.exit (1)
input_file = sys.argv [1]
if not os.path.isfile (input_file):
print (f"文件不存在: {input_file}")
sys.exit (1)
process_html (input_file)还有一个一劳永逸的办法-通过脚本命令
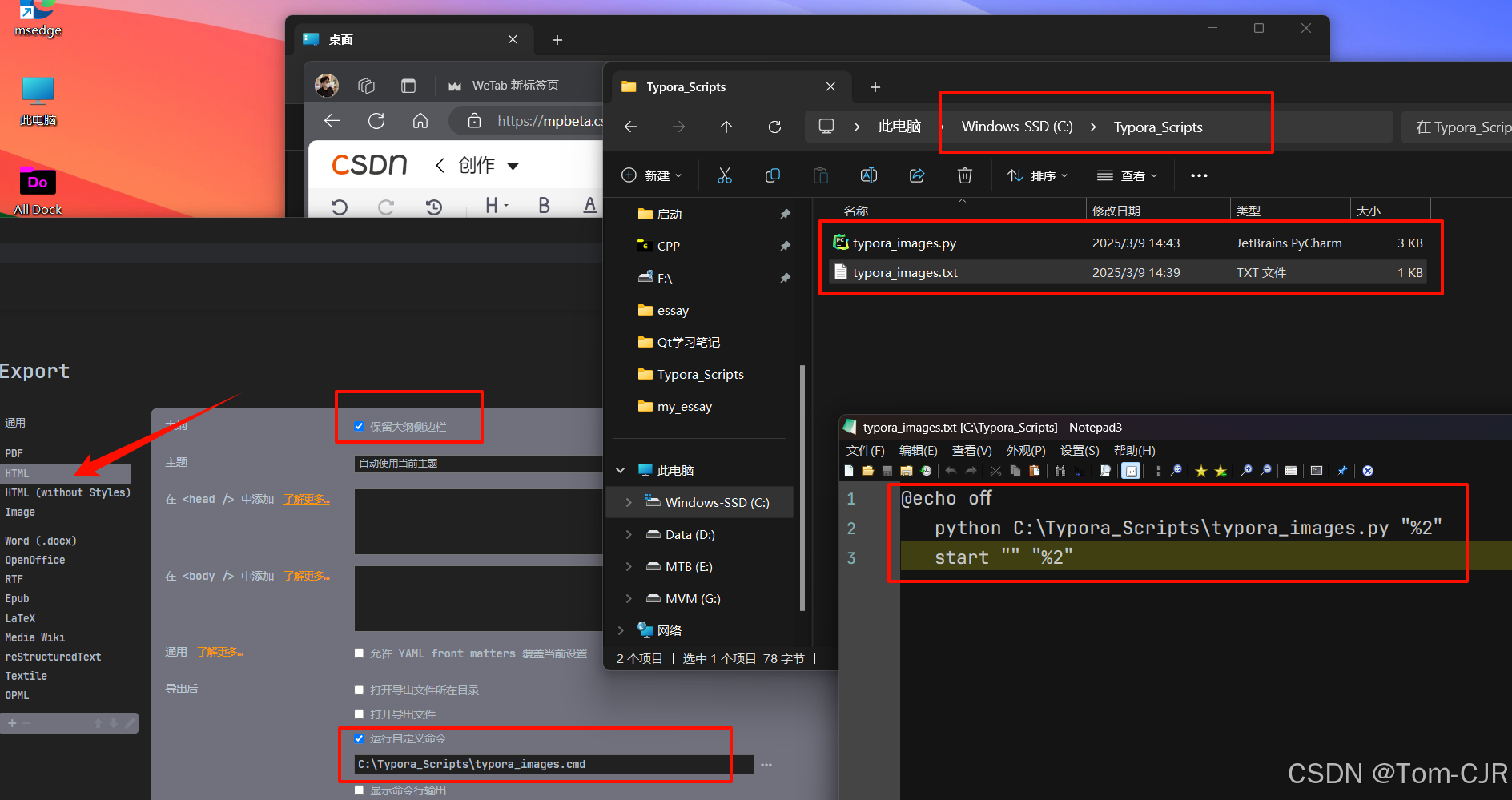
把脚本文件放到C盘某个文件夹下(自定义),然后写一个记事本文件,内容如图所示,保存并且更改后缀为cmd;然后在typora设置中找到html导出设置,运行脚本,并且输入命令,就完美啦!

















 2491
2491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









