







原文链接:Accelerating the Super-Resolution Convolutional Neural Network | SpringerLink
pytorch开源代码:https://github.com/yjn870/FSRCNN-pytorch
一、摘要
作为一种成功应用于图像超分辨率(SR)的深度学习模型,超分辨率卷积神经网络(SRCNN)[1,2] 在速度和恢复质量上均优于以往的手工设计模型。然而,其高昂的计算成本仍阻碍了它在需要实时性能(24 fps)的实际场景中的应用。本文旨在加速当前的SRCNN,并提出一种紧凑的沙漏形CNN结构,以实现更快、更好的超分辨率重建。我们从三个方面重新设计了SRCNN结构:
- 引入反卷积层:在网络末端加入反卷积层,直接从原始低分辨率图像(无需插值)学习到高分辨率图像的映射。
- 重构映射层:在映射前缩减输入特征维度,映射后再扩展回高维,以降低计算量。
- 优化滤波器配置:采用更小的滤波器尺寸,但增加映射层数以平衡精度与效率。
所提出的模型在速度上提升超过40倍的同时,甚至实现了更优的恢复质量。此外,我们给出了在通用CPU上实现实时性能(24 fps)的参数设置,且仍能保持良好性能。针对不同放大因子,还提出了一种快速迁移策略,以加速训练和测试过程。
关键点分析
(1)核心问题:SRCNN虽性能优越,但计算复杂度高,难以满足实时性需求(如视频超分辨率需24 fps)。
(2)三大改进:
- 反卷积层替代插值:传统SRCNN需先对低分辨率图像插值(如双三次上采样),再输入网络,计算冗余;FSRCNN直接输入原始低分辨率图像,末端通过反卷积上采样,减少预处理开销。
- 特征维度压缩-扩展:映射层(非线形变换)前通过1×1卷积压缩通道数,降低计算量,映射后再扩展回高维。
- 小滤波器+深结构:用多层小尺寸卷积(如3×3)替代大滤波器(如9×9),提升效率且保留感受野。
(3)成果:
- 40倍加速:通过结构优化显著减少计算量(FLOPs)。
- 实时CPU推理:通过参数调整(如减少滤波器数量)在CPU上达到24 fps,兼顾性能与速度。
- 迁移策略:共享部分网络参数(如特征提取层)支持多尺度超分辨率(×2, ×3, ×4),减少重复训练成本。
(4)意义:
- 轻量化设计典范:为后续实时超分辨率模型(如ESPCN、ESRGAN)提供参考。
- 端到端革新:直接学习低分辨率→高分辨率的端到端映射,避免手工预处理。
贡献
-
紧凑的沙漏形CNN结构 + 端到端映射
-
沙漏形设计:网络结构中间窄(低维特征)、两端宽(输入/输出),减少计算量。
-
反卷积层替代插值:直接在网络末端使用反卷积(Deconvolution)上采样,无需对输入LR图像进行预插值(如双三次上采样),实现真正的端到端学习。
-
-
40倍加速 + 实时CPU推理
-
相比SRCNN的扩展版本(SRCNN-Ex),FSRCNN速度提升至少40倍,同时保持甚至超越其超分性能。
-
轻量化版本:在通用CPU上实现实时处理(>24 fps),且恢复质量仍优于原SRCNN。
-
-
跨尺度迁移策略
-
通过共享部分卷积层参数(如特征提取层),支持不同放大因子(×2, ×3, ×4)的快速训练与测试,无需为每个尺度重新训练完整模型,且不损失性能。
-
二、网络结构分析
SRCNN
1.核心设计思想
SRCNN的核心目标是学习一个端到端的映射函数 F,将双三次插值后的低分辨率图像 Y 直接映射到高分辨率图像 X。其设计灵感来源于传统稀疏编码方法的三个步骤,但通过全卷积网络实现自动化学习。
2.网络结构分解
SRCNN由三层卷积层构成,每层对应稀疏编码超分辨率的经典步骤
3.关键问题
- 高计算成本:首层大卷积核(如9×9)和中间层高维映射导致计算量激增,难以满足实时需求。
- 冗余操作:输入需先进行双三次插值,增加了不必要的计算开销。
4. 与FSRCNN的对比改进
FSRCNN针对SRCNN的缺陷进行了三方面优化:
- 取消预插值:直接输入原始LR图像,末端通过反卷积上采样,减少预处理计算量。
- 特征压缩:在非线性映射前加入1×1卷积降维(如从64维压缩到12维),大幅降低计算负担。
- 小卷积核深网络:用多层3×3卷积替代单层9×9卷积,在保持感受野的同时减少参数量。
- 效果:FSRCNN的计算复杂度显著低于SRCNN,实现40倍加速且性能更优。
FSRCNN
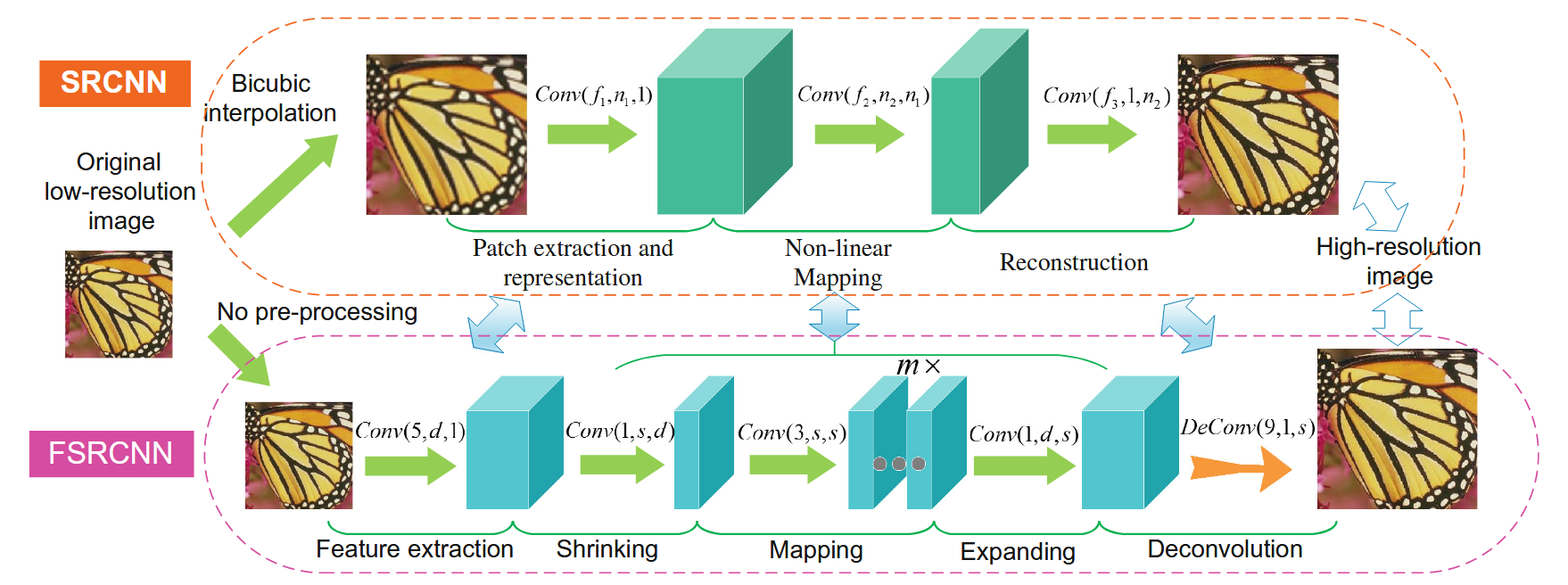
🌟 SRCNN 结构(上方橙色框)
流程:
-
输入: 原始低分辨率图像 → 先进行 双三次插值(Bicubic interpolation) 变成高分辨率大小;
-
Patch extraction & representation:
Conv(f₁, n₁, 1):大卷积(如 9x9),提取初步特征; -
Non-linear Mapping:
Conv(f₂, n₂, n₁):比如 1x1 卷积,用于非线性特征变换; -
Reconstruction:
Conv(f₃, 1, n₂):重构 HR 图像; -
输出: HR 图像
缺点: 一开始就对 LR 图像做双三次插值放大 → 计算成本高,且插值引入不必要信息。
🚀 FSRCNN 结构(下方紫色框)
重大改进:
1️⃣ 不再预插值(No Bicubic Interpolation)
-
直接对小图操作,输入仍是 LR 图像,避免多余计算。
2️⃣ 引入反卷积(Deconvolution)用于上采样
-
最后一层
DeConv(9, 1, s),用于可学习的上采样(可实现 ×2, ×3, ×4 放大); -
对比 SRCNN 的“先放大再处理”,FSRCNN 采用“先处理再放大”策略,更优雅高效。
3️⃣ 替换非线性映射为深层结构(Shrinking + Mapping + Expanding):
🔸 Feature Extraction:
-
Conv(5, d, 1)→ 类似于SRCNN的第一层,提取 LR 图像的基本特征。
🔸 Shrinking:
-
Conv(1, s, d)→ 用 1×1 卷积把高维特征压缩成低维,提高后续效率。
🔸 Mapping(非线性映射):
-
m × Conv(3, s, s)→ 多个 3×3 卷积堆叠,构成更深层次的特征学习模块。
🔸 Expanding:
-
Conv(1, d, s)→ 把特征维度从 s 恢复回 d,为后续上采样准备。
🔸 Deconvolution(反卷积):
-
DeConv(9, 1, s)→ 相当于插值的升级版,直接生成高分辨图像。
🧩 FSRCNN 多倍率训练与测试结构图
+---------------------------+
| 原始低分辨率图像 (LR) |
+---------------------------+
|
v
+------------------------------------+
| 共享的卷积特征提取部分 |
| Conv(5,d,1) → Conv(1,s,d) → ... |
+------------------------------------+
|
+--------------+--------------+--------------+
| | |
v v v
+-------------------+ +-------------------+ +-------------------+
| Deconv for ×2 | | Deconv for ×3 | | Deconv for ×4 |
+-------------------+ +-------------------+ +-------------------+
| | |
v v v
+-------------------+ +-------------------+ +-------------------+
| HR image (scale 2)| | HR image (scale 3)| | HR image (scale 4)|
+-------------------+ +-------------------+ +-------------------+
配套说明:
-
🔧 卷积层(绿色部分):仅负责提取低分辨率图像的特征,与放大倍率无关;
-
🔄 反卷积层(橙色部分):负责将特征图上采样到目标分辨率,是唯一和放大倍率有关的部分;
-
🔁 训练过程:
-
训练好一个倍率的 FSRCNN(比如 ×3);
-
之后换倍率,只需要微调对应的
Deconv层;
-
-
🚀 测试过程:
-
对一张图像,只提一次特征(跑一遍卷积);
-
然后分别输入到不同的反卷积层,得到多个倍率的高清图。
-
论文中三点主要改进:
-
去掉预插值,直接用LR图输入 → 提升效率
-
非线性映射模块更深 + 更小卷积 → 提升表示能力
-
使用反卷积进行上采样 → 效果好、速度快
FSRCNN 的卷积层与放大倍率无关,仅反卷积层与倍率相关,因此我们可以:
-
🔁 重用卷积层,减少重复训练;
-
🚀 快速切换放大倍率,只微调最后一层;
-
⚡ 多倍率测试时非常高效。
总结对比
| 结构对比 | SRCNN | FSRCNN |
|---|---|---|
| 输入图像 | 先插值为HR再输入网络 | 直接输入LR原图 |
| 上采样方式 | 无(靠前插值) | 网络内最后用反卷积上采样 |
| 非线性映射结构 | 单层大卷积 | 多层3x3小卷积堆叠,更深 |
| 参数量 | 多(因图像先插值) | 更少(小图+通道压缩) |
| 速度 | 慢 | 快 |
| 性能 | 好 | 更好 |
| 可扩展性 | 差(针对固定放大倍数) | 强(通过不同stride控制倍数) |
三、代码讲解
PReLU(Parametric ReLU)
1.ReLU 和 PReLU 是什么?
1) ReLU(修正线性单元)
这是最常见的激活函数,定义是:
-
输入为正数时直接输出;
-
输入为负数时输出为0;
-
缺点:负数区域的梯度为0,容易导致“神经元死亡(dead neurons)”,即某些通道在训练过程中永远不会被激活,对模型没贡献。
2)PReLU(参数化 ReLU)
PReLU 改进了 ReLU 的负数区域定义:
-
对正数仍然是原样输出;
-
对负数,不是直接变成0,而是乘以一个系数
,这个系数是可学习的,每个通道都有一个;
-
所以:如果训练认为负值有用,就可以自动调整
2. FSRCNN 中为什么使用 PReLU?
FSRCNN 的目的是做图像超分辨重建,要从模糊或低分辨图中恢复出清晰图像,对特征的捕捉非常敏感。所以在这段话中,作者提出:
✅ 选择 PReLU 的原因:
-
避免“dead features”现象
ReLU 的负区间梯度为0,可能导致某些特征永远不更新(特别是在深层网络中)。PReLU 通过引入一个可学习的 -
充分利用每一层的所有参数
每一层都能有效地传递梯度,不会浪费掉部分通道的表达能力。 -
更稳定、更高性能
实验表明,使用 PReLU 的网络性能更稳定,有时候比 ReLU 好,可以看作是 ReLU 网络的性能上限。
3. 简单理解 PReLU 的优势
| 特性 | ReLU | PReLU |
|---|---|---|
| 负值处理 | 直接置0 | 乘以可学习参数 |
| 可学习性 | 否 | 是(每个通道一个参数) |
| 死神经元问题 | 容易出现 | 减少出现概率 |
| 训练稳定性 | 相对较差 | 更稳定 |
| 表达能力 | 可能浪费部分通道 | 尽量利用所有通道 |
model.py
import math
from torch import nn
class FSRCNN(nn.Module):
def __init__(self, scale_factor, num_channels=1, d=56, s=12, m=4):
"""
FSRCNN 模型构造函数
参数说明:
- scale_factor:放大倍数,如 2x、3x、4x
- num_channels:输入图像的通道数,灰度图为1,RGB图为3
- d:第一阶段输出通道数,默认56(特征维度压缩前的维度)
- s:中间层通道数,默认12(特征维度压缩后的维度)
- m:非线性映射中的中间层数,默认4
"""
super(FSRCNN, self).__init__()
# Feature Extraction 特征提取层
self.first_part = nn.Sequential(
nn.Conv2d(num_channels, d, kernel_size=5, padding=5//2), # 5x5卷积保持尺寸不变
nn.PReLU(d) # 使用带参数的PReLU激活,提升非线性能力,避免dead neurons
)
# Shrinking + Non-linear Mapping + Expanding 中间部分
self.mid_part = [
nn.Conv2d(d, s, kernel_size=1), # Shrinking:1x1卷积将维度压缩为s
nn.PReLU(s)
]
for _ in range(m):
# m个非线性映射层:每层是一个3x3卷积和一个PReLU激活
self.mid_part.extend([
nn.Conv2d(s, s, kernel_size=3, padding=3//2), # 保持尺寸不变
nn.PReLU(s)
])
self.mid_part.extend([
nn.Conv2d(s, d, kernel_size=1), # Expanding:再用1x1卷积还原维度
nn.PReLU(d)
])
self.mid_part = nn.Sequential(*self.mid_part)
# Deconvolution Layer(反卷积)用于图像上采样
self.last_part = nn.ConvTranspose2d(
d, num_channels, kernel_size=9,
stride=scale_factor, # 上采样倍数
padding=9//2,
output_padding=scale_factor - 1 # 调整输出尺寸,确保对齐
)
# 初始化权重
self._initialize_weights()
def _initialize_weights(self):
"""
权重初始化方法:
- 中间层Conv使用He初始化(适用于ReLU/PReLU激活)
- 最后反卷积层使用较小的标准差初始化
"""
for m in self.first_part:
if isinstance(m, nn.Conv2d):
# He初始化:均值0,方差2/fan_out
nn.init.normal_(m.weight.data, mean=0.0,
std=math.sqrt(2 / (m.out_channels * m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
for m in self.mid_part:
if isinstance(m, nn.Conv2d):
nn.init.normal_(m.weight.data, mean=0.0,
std=math.sqrt(2 / (m.out_channels * m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
# 反卷积层使用较小的初始化
nn.init.normal_(self.last_part.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(self.last_part.bias.data)
def forward(self, x):
"""
前向传播过程
输入:x 是低分辨率图像(形状为 NCHW)
输出:高分辨率图像
"""
x = self.first_part(x) # 特征提取
x = self.mid_part(x) # 压缩 -> 非线性映射 -> 解压
x = self.last_part(x) # 上采样生成高清图像
return x
FSRCNN 结构总结
-
特征提取层:5x5 卷积 + PReLU
-
维度压缩层:1x1 卷积 + PReLU
-
非线性映射层:m个 3x3 卷积 + PReLU(默认m=4)
-
维度扩展层:1x1 卷积 + PReLU
-
反卷积上采样层:9x9 反卷积,实现图像放大



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









