






SQL——连续登陆天数、点击次数_写一段sql统计点击按钮≥3次的用户id-优快云博客
一、列转行
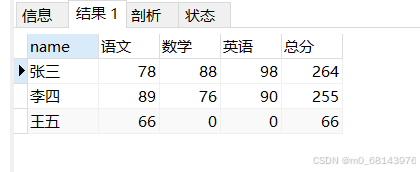
题目:将表Student
| name | subject | score |
|---|---|---|
| 张三 | 语文 | 78.0 |
| 张三 | 数学 | 88.0 |
| 张三 | 英语 | 98.0 |
| 李四 | 语文 | 89.0 |
| 李四 | 数学 | 76.0 |
| 李四 | 英语 | 90.0 |
| 王五 | 语文 | 66.0 |
转化为下面的形式展示
| name | 语文 | 数学 | 英语 | 总分 |
|---|---|---|---|---|
| 张三 | 78 | 88 | 98 | 264 |
| 李四 | 89 | 76 | 90 | 255 |
| 王五 | 99 | 0 | 0 | 66 |
解1:
select
name,
sum(case when subject = '语文' then score ELSE 0 END) as '语文',
sum(case when subject = '数学' then score ELSE 0 END) as '数学',
sum(case when subject = '英语' then score ELSE 0 END) as '英语',
sum(if(score is null,0,score)) as '总分'
from student
group by
name
解2:
select
name,
sum(if(subject = '语文',score,0)) as '语文',
sum(if(subject = '数学',score,0)) as '数学',
sum(if(subject = '英语',score,0)) as '英语',
sum(if(score is null,0,score)) as '总分'
from student
group by
name
二、row_number() over() 的使用
row_number() over() 在面试中经常和 rank() over()、dense_rank() over() 一起被问,在笔试中也经常需要用到,甚至在工作中也经常见到,反正是相当的重要!
在工作中其实用的是 row_number() over() 的变种,用 @ 。因为公司大都是MySQL5,但窗口函数在MySQL8中才出现,所以工作中都是 row_number 的思想,@的写法。关于@的使用有时间我写写。
题目:统计订单交易表(orders)每个商品交易金额最高的那一条数据
item_id trade_date trade_amount
A 2021/3/1 1500
A 2021/3/9 2500
A 2021/2/22 1000
B 2021/3/5 3000
B 2021/5/9 5000
B 2021/6/22 800
item_id=商品代码 trade_date=交易日期 trade_amount=交易金额
解:
select
a.item_id,
a.trade_date,
a.trade_amount
FROM
(select
item_id,
trade_date,
trade_amount,
row_number() over(partition by item_id order by trade_amount desc) as rn
from orders) a
where a.rn = 1
三、逐行累加
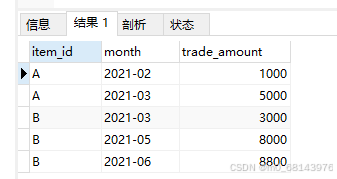
题目:还是订单交易表(orders),对商品按照月份累加汇总。比如,一月份显示一月的交易金额,二月份显示一月份+二月份的交易金额
展示结果应该为:
| item_id | trade_date | trade_amount |
|---|---|---|
| A | 2021/2 | 1000 |
| A | 2021/3 | 5000 |
| B | 2021/3 | 3000 |
| B | 2021/5 | 8000 |
| B | 2021/6 | 8800 |
解:
先对每个月份的金额进行聚合操作,之后用sum() over()函数对其进行累计求和操作。
select
a.item_id,
a.month,
SUM(a.trade_amount) over(partition by a.item_id ORDER BY a.month) as trade_amount
FROM
(select
item_id,
DATE_FORMAT(trade_date,'%Y-%m') as month,
sum(trade_amount) as trade_amount
from orders
group by item_id,DATE_FORMAT(trade_date,'%Y-%m')) a
GROUP BY a.item_id,a.month
四、rank() over() 开窗函数的使用(以下三道都是滴滴面试过程中手撕)
表:订单表t,(网约车订单明细表,每日增量)
dt(分区格式yyyy-MM-dd),product_line, order_id,car_id, driver_id,is_finish,is_cancel,start_time,end_time。
其中,is_finish=1代表订单完成。is_cancel=1代表订单取消。product_line:品类(如快车、专车等)。
题目:查询近7天内上一单是取消单的,近7天完单量top100的司机。
题目解读:上一单 = 最近一单的上一单,最近一单 = 当前单
解:
select
driver_id,
count(1) as top
from t
where datediff(current_date,dt)<7
and is_finish=1
and driver_id in -- 近七天完成量且上一单是取消的
(select
a.driver_id
from
(select
driver_id,
is_cancel,
rank() over(partition by driver_id order by dt desc) as rn
from t
where datediff(current_date(),dt)<7) a -- 求出7天所有司机的信息
where a.rn =2 and a.is_cancel=1) --求出上一单是取消的司机的信息id
group by driver_id
order by top desc
limit 100
3.一张用户交易记录表buyer_trade,3个字段:日期p_date(yyyymmdd)/订单order_id/买家 buyer_id,想看-下用户在2024年3月如果有购买后,在接下来的30天里是否还会购买。最后统计该月份的复购人数占比?
select
month(a.p_day) as Month,
count(distinct b.buyer_id) as repeat_buyers,
count(distinct a.buyer_id) as all_buyers,
round((count(distinct b.buyer_id)/(count(distinct a.buyer_id),2) as repeat_buyer
from
(select
p_day,
buyer_id from buyer_trade
where p_day between '20240301' and '20240331'
group by
p_day,
buyer_id) a
left join buyer_trade b
on a.buyer_id = b.buyer_id
and b.p_date >a.p_date AND b.p_date <= a.p_date + 30
group by
month(a.p_day)
五、hive中列转行函数 collect_set 的使用
表:订单表t,(网约车订单明细表,每日增量)
dt(分区格式yyyy-MM-dd),product_line, order_id,car_id, driver_id,is_finish,is_cancel,start_time,end_time。
其中,is_finish=1代表订单完成。is_cancel=1代表订单取消。product_line:品类(如快车、专车等)。
题目:查询近30天内,司机完单的品类集合、完单天数。产出3个字段:司机id, 近30日完单品类列表,近30日完单天数。
函数科普:
-
collect_set:group by后,将分组中的某列转为一个数组返回,set去重
-
collect_list:group by后,将分组中的某列转为一个数组返回,list不去重
解:
select
driver_id,
collect_set(product_line),
count(distinct(dt))
from t
where datediff(current_date(),dt) < 30
and is_finish=1
group by driver_id
六、sql不光要写出来,也要注意效率——调优
表:订单表t1,(订单明细表,每日增量)
dt(分区格式yyyy-MM-dd), product_line, order_id,car_id, driver_id,is_finish,is_cancel,start_time,end_time。
其中,is_finish=1代表订单完成。is_cancel=1代表订单取消。product_line:品类(如快车、专车、拼车等)。
司机表t2,(每日全量)
dt(分区格式yyyy-MM-dd), driver_id, work_type。
其中,work_type=1代表全职
题目:查询近7天内,各品类中,完单量top100的全职司机。
SELECT product_line,driver_id,num
FROM(
SELECT product_line,driver_id,num,rank() over(PARTITION BY product_line ORDER BY num DESC) AS sort
FROM(
# 各品类中各全职司机的完单量
SELECT product_line,driver_id,num
FROM(
SELECT product_line,driver_id,COUNT(*) num
FROM t1
WHERE DATEDIFF(CURRENT_DATE,dt)<7 AND is_finish=1
GROUP BY product_line,driver_id
)a
LEFT JOIN
(
SELECT *
FROM t2
WHERE DATEDIFF(CURRENT_DATE,dt)<7 AND work_type=1
)b
ON a.driver_id = b.driver_id
)t1
)t2
WHERE sort <= 100
找出连续N天登陆的用户id
数据: 现有用户登录记录表user_log
用户id 登录日期
userid login_data
yh001 2019-11-25
yh001 2019-11-26
yh001 2019-11-27
yh001 2019-12-01
yh001 2019-12-02
yh001 2019-12-26
yh001 2019-12-27
yh002 2019-12-29
yh002 2019-12-30
解1:
select
distinct a.userid,
DATE_SUB(a.login_data,interval rk day) as days,
COUNT(1) as lianxu_day
from
(select
userid,
login_data,
row_number() over(partition by userid order by login_data ASC) as rk
from
user_log) a
group by
a.userid,
DATE_SUB(a.login_data,interval rk day)
having count(1) >=N
解2:
select
distinct a.userid,
DATEDIFF(a.rk,a.login_data) as days
FROM
(select
userid,
login_data,
lead(login_data,N-1) over(partition by userid order by login_data ASC) as rk
from
user_log) a
where DATEDIFF(a.rk,a.login_data) =N-1
统计用户连续登陆最大天数
解:
select
b.userid,
max(continuous_days) as max_continuous_days
from
(select
a.userid,
date_sub(a.login_data,interval a.rn day) as day_gap,
count(1) as continuous_days
from
(select
userid,
login_data,
row_number() over(partition by userid order by login_data) as rn
from user_log
) a
group by
a.userid,
date_sub(a.login_data,interval a.rn day) )b
group by
b.userid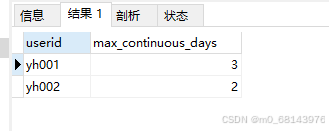
连续点击N次,且中间别人不能点击的用户id
问题:
select
distinct c.user_id
from
(select
b.user_id,
b.rn,
lead(b.rn,2) over(partition by b.user_id order by b.rn) as rn2
from
(select
a.user_id,
a.click_time,
row_number() over(order by a.click_time) as rn from
(select
distinct user_id,
click_time
from a) a) b) c
where c.rn2-c.rn =2

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









