






 Spark Streaming是基于Spark的实时数据处理框架,提供高吞吐量和容错能力。其主要特点是易于使用和与Spark生态整合。DStream作为核心抽象,表示连续的数据流,由多个RDD组成。Spark Streaming通过DStream的转换操作处理数据,接收数据时使用Receiver。在本地运行需注意线程配置,集群上运行时Executor需分配足够资源。本文还展示了如何利用Spark Streaming完成词频统计任务,包括安装nc,创建Maven项目,设置依赖,创建日志文件,以及编写和启动流式词频统计程序。
Spark Streaming是基于Spark的实时数据处理框架,提供高吞吐量和容错能力。其主要特点是易于使用和与Spark生态整合。DStream作为核心抽象,表示连续的数据流,由多个RDD组成。Spark Streaming通过DStream的转换操作处理数据,接收数据时使用Receiver。在本地运行需注意线程配置,集群上运行时Executor需分配足够资源。本文还展示了如何利用Spark Streaming完成词频统计任务,包括安装nc,创建Maven项目,设置依赖,创建日志文件,以及编写和启动流式词频统计程序。
目录
(二)分段流 - DSteam (Discretized Stream)
一,spark Streaming概述
(一)什么是Spark streaming
SparkStreaming类似于ApacheStorm,用于流式数据的处理。根据官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。SparkSteaming支持的数据输入源很多,例如Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象源语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外SparkStreaming也能和MLib(机器学习)以及Graphx完美融合。
和Spark基于RDD的概念很相似,SparkStreaming使用离散化流(discretized stream)作为抽象表示,叫做DStream。Dstream是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD存在,而DStream是由这些RDD所组成的序列,因此得名“离散化”。
(二)Sparing Streaming的主要特点
Spark Streaming是构建在Spark上的实时计算框架,且是对Spark Core API的一个扩展,它能够实现对流数据进行实时处理,并具有很好的可扩展性、高吞吐量和容错性。Spark Streaming具有如下显著特点。
1,易于使用
Spark Streaming支持Java、Python、Scala等编程语言,可以像编写离线程序一样编写实时计算的程序求照的器。
2,易于与Spark体系整合
通过在Spark Core上运行Spark Streaming,可以在Spark Streaming中使用与Spark RDD相同的代码进行批处理,构建强大的交互应用程序,而不仅仅是数据分析。
二,Spark Streaming工具原理
(一)Spark Streaming工作流程图
Spark Streaming接收实时输入的数据流,并将数据流以时间片(秒级)为单位拆分成批次,然后将每个批次交给Spark引擎(Spark Core)进行处理,最终生成以批次组成的结果数据流
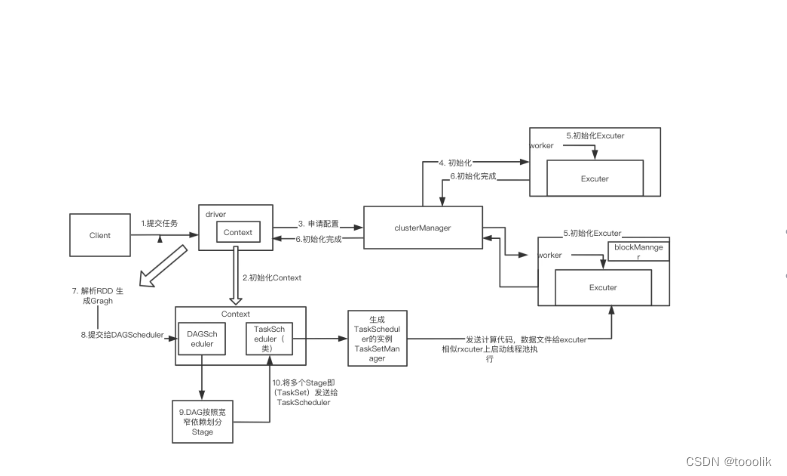
(二)分段流 - DSteam (Discretized Stream)
1,分段流的概念
Spark Streaming提供了一种高级抽象,称为DStream(Discretized Stream)。DStream表示一个连续不断的数据流,它可以从Kafka、Flume和Kinesis等数据源的输入数据流创建,也可以通过对其他DStream应用高级函数(例如map()、reduce()、join()和window())进行转换创建
2,分段流的实质
在内部,对输入数据流拆分成的每个批次实际上是一个RDD,一个DStream由多个RDD组成,相当于一个RDD序列。
3,分段流中的RDD
DStream中的每个RDD都包含来自特定时间间隔的数据

4,分段流的操作
应用于DStream上的任何操作实际上都是对底层RDD的操作。例如,对一个DStream应用flatMap()算子操作,实际上是对DStream中每个时间段的RDD都执行一次flatMap()算子,生成对应时间段的新RDD,所有的新RDD组成了一个新DStream。对DStream中的RDD的转换是由Spark Core引擎实现的,Spark Streaming对Spark Core进行了封装,提供了非常方便的高层次API。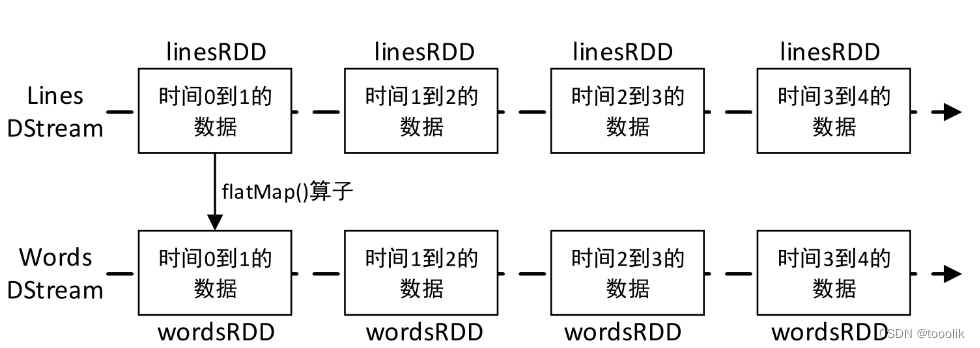
(三)输入DStream与Receiver
1,输入DStream与Receiver的关系
输入DStream表示从数据源接收的输入数据流,每个输入DStream(除了文件数据流之外)都与一个Receiver对象相关联,该对象接收来自数据源的数据并将其存储在Spark的内存中进行处理。
如果希望在Spark Streaming应用程序中并行接收多个数据流,那么可以创建多个输入DStream,同时将创建多个Receiver,接收多个数据流。但需要注意的是,一个Spark Streaming应用程序的Executor是一个长时间运行的任务,它会占用分配给SparkStreaming应用程序的一个CPU内核(占用Spark Streaming应用程序所在节点的一个CPU内核),因此Spark Streaming应用程序需要分配足够的内核(如果在本地运行,就是线程)来处理接收到的数据,并运行Receiver。
2,本地运行Spark Streaming应用程序
在本地运行Spark Streaming应用程序时,不要使用local或local[1]作为主URL。这两种方式都意味着只有一个线程将用于本地运行任务。如果正在使用基于Receiver的输入DStream(例如Socket、Kafka、Flume等),那么将使用单线程运行Receiver,导致没有多余的线程来处理接收到的数据(Spark Streaming至少需要两个线程:一个线程用于运行Receiver接收数据;另一个线程用于处理接收到的数据)。因此,在本地运行时,应该使用“local[n]”作为主URL,其中n大于Receiver的数量(若Spark Streaming应用程序只创建了一个DStream,则只有一个Receiver,n的最小值为2)
3,集群上运行Spark Streaming 应用程序
每个Spark应用程序都有各自独立的一个或多个Executor进程负责执行任务。将Spark Streaming应用程序发布到集群上运行时,每个Executor进程所分配的CPU内核数量必须大于Receiver的数量,因为1个Receiver独占1个CPU内核,还需要至少1个CPU内核进行数据的处理,这样才能保证至少两个线程同时进行(一个线程用于运行Receiver接收数据,另一个线程用于处理接收到的数据)。否则系统将接收数据,但无法进行处理。若Spark Streaming应用程序只创建了一个DStream,则只有一个Receiver,Executor所分配的CPU内核数量的最小值为2。
三,利用Spark Streaming完成词频统计
(一)提出任务
假设需要监听TCP Socket端口的数据,实时计算接收到的文本数据中的单词数
(二)完成任务
1,在master虚拟机上安装nc
nc是一个简单而有用的工具,透过使用TCP或UDP协议的网络连接去读写数据。它被设计成一个稳定的后门工具,能够直接由其它程序和脚本轻松驱动。同时,它也是一个功能强大的网络调试和探测工具,能够建立你需要的几乎所有类型的网络连接。
执行命令:yum -y install nc
2,创建Maven
创建Maven项目 - SparkStreamingWordCount
将java目录改成scala目录
3,添加依赖与构建插件
在pom.xml文件里添加依赖与构建插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.az.count</groupId>
<artifactId>SparkStreamingWordCount</artifactId>
<version>1.0-SNAPSHOT</versio <dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>4,创建日志文件
在resources目录里创建log4j.properties
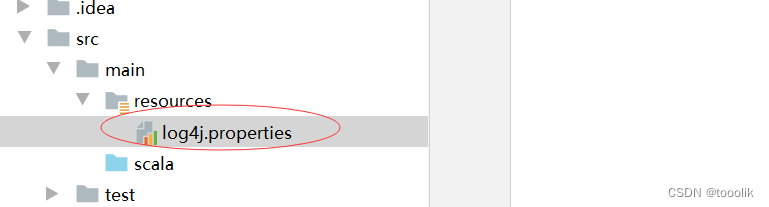
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5,创建流式词频统计单例对象
创建net.az.stream包
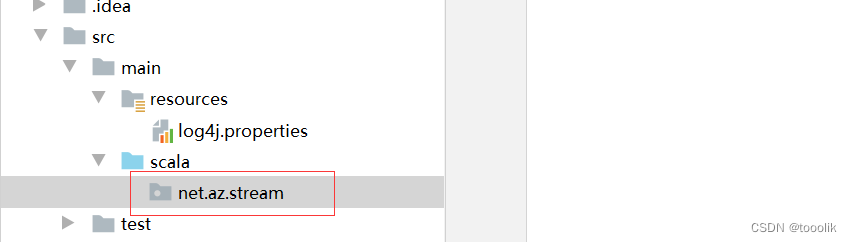
在net.az.stream包里创建SparkStreamingWordCount单例对象
package net.az.stream
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 功能:利用Spark Streaming实现词频统计
* 作者:阿珍
* 日期:2022年05月17日
*/
object SparkStreamingWordCount {
def main(args: Array[String]): Unit = {
// 创建Spark配置对象
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("SparkStreamingWordCount")
// 按照时间间隔为3秒钟切分数据流
val ssc = new StreamingContext(conf, Seconds(3))
// 创建行分段流(接收master节点9999端口的文本流数据)
val lines = ssc.socketTextStream("master", 9999)
// 生成单词分段流
val words = lines.flatMap(_.split(" "))
// 计算每一批次中的每个单词数量
val pairs = words.map((_, 1))
// 进行词频统计
val wc = pairs.reduceByKey(_ + _)
// 输出分段流中每个RDD的词频统计结果
wc.print()
// 开始计算
ssc.start()
// 等待计算结束
ssc.awaitTermination()
}
}
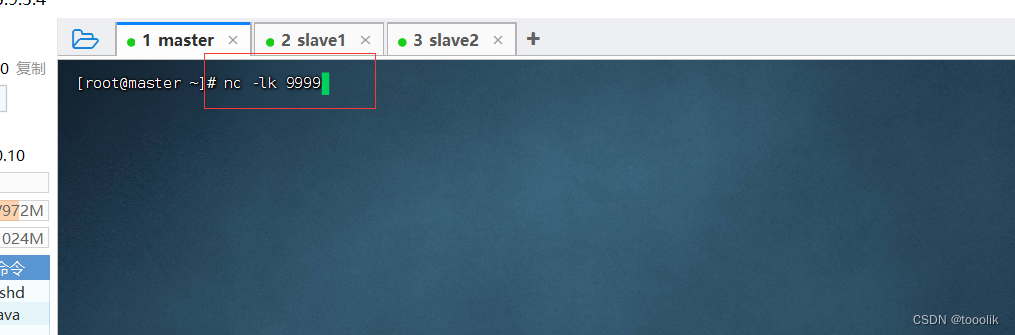
6,在master虚拟机上启动nc
执行命令:nc -lk 9999
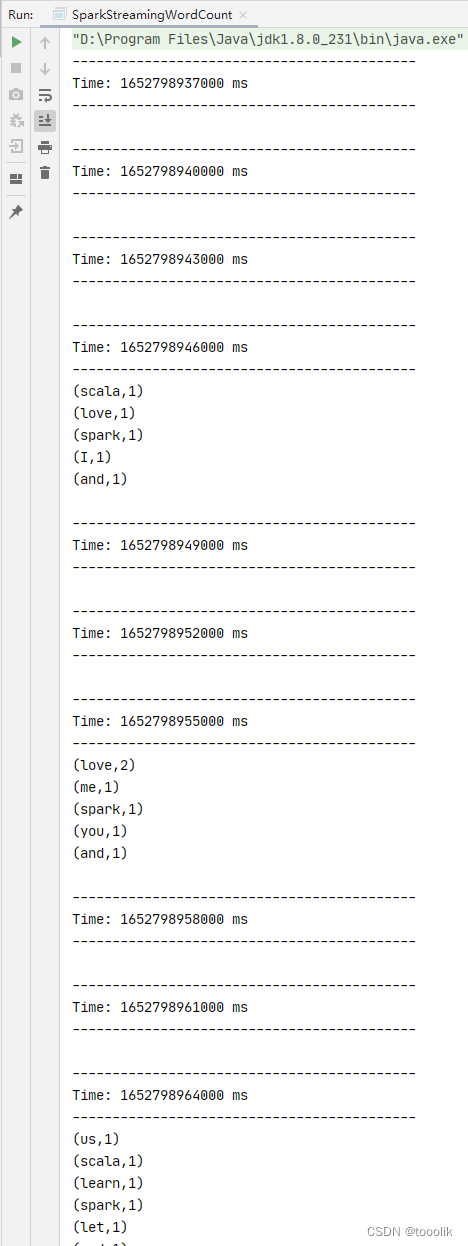
7,启动程序,查看结果
启动流式词频统计单例对象,然后在master虚拟机上输入一行又一行的数据
因为强行停止程序,所以退出码是-1

















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









