







目录
4.4.2 余弦相似度损失(Cosine Similarity Loss)
4.4.3 多负样本排名损失(Multiple Negatives Ranking Loss)
5.2 Augmented SBERT(增强版 SBERT)
第九章:多模态大语言模型-优快云博客![]() https://blog.youkuaiyun.com/m0_67804957/article/details/145913106文本嵌入模型是许多强大自然语言处理应用的基础。它们为已经非常令人印象深刻的技术,如文本生成模型,提供了基础。我们在本书中已经在多个应用中使用了嵌入模型,例如监督分类、无监督分类、语义搜索,甚至为像ChatGPT这样的文本生成模型提供记忆功能。可以说,嵌入模型在该领域的重要性几乎无法夸大,因为它们是许多应用背后的驱动力。
https://blog.youkuaiyun.com/m0_67804957/article/details/145913106文本嵌入模型是许多强大自然语言处理应用的基础。它们为已经非常令人印象深刻的技术,如文本生成模型,提供了基础。我们在本书中已经在多个应用中使用了嵌入模型,例如监督分类、无监督分类、语义搜索,甚至为像ChatGPT这样的文本生成模型提供记忆功能。可以说,嵌入模型在该领域的重要性几乎无法夸大,因为它们是许多应用背后的驱动力。
因此,在本章中,我们将讨论如何创建和微调嵌入模型,以提高其表征和语义能力。首先,让我们了解嵌入模型是什么以及它们通常是如何工作的。
一、嵌入模型
嵌入和嵌入模型在本书的第4、5和8章中已经讨论过,展示了它们的有用性。在开始训练这种模型之前,让我们回顾一下我们对嵌入模型的理解。
未经结构化处理的文本数据通常是很难处理的。它们是我们无法直接处理、可视化并从中得出可操作结果的值。我们首先必须将这些文本数据转换为我们可以轻松处理的内容:数字表示。这一过程通常被称为将输入嵌入以输出可用的向量,即嵌入,如图10-1所示。

嵌入输入的过程通常由大语言模型(LLM)执行,我们称之为嵌入模型。这种模型的主要目的是尽可能准确地将文本数据表示为嵌入。然而,准确表示是什么意思呢?通常来说,我们希望捕捉文档的语义特征——即其含义。如果我们能够捕捉到文档所传达的核心内容,我们希望能够理解文档的主题。在实践中,这意味着我们期望表示相似内容的文档的向量彼此相似,而表示完全不同内容的文档的嵌入应该不相似。我们在本书中已经多次见过语义相似性的概念,并在图10-2中进行了可视化。这是一个简化的示例。尽管二维可视化有助于说明嵌入之间的接近性和相似性,但这些嵌入通常存在于高维空间中。
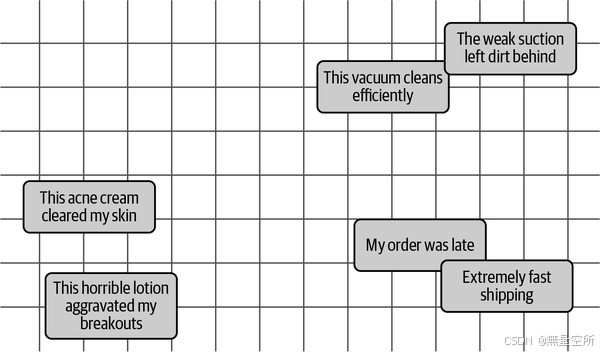
然而,嵌入模型可以根据不同的目的进行训练。例如,当我们构建情感分类器时,我们更关心文本的情感而不是它们的语义相似性。如图10-3所示,我们可以微调模型,使文档在n维空间中根据情感而非语义更接近。
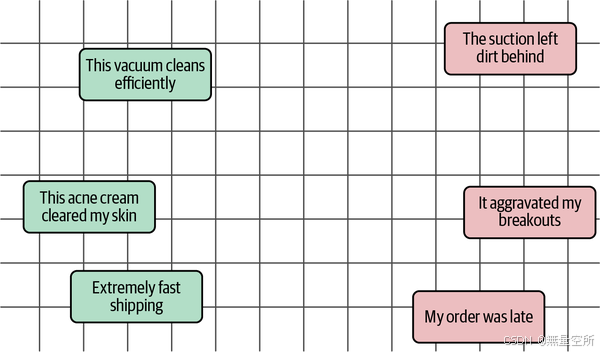
无论哪种方式,嵌入模型的目标都是学习使某些文档彼此相似的因素,而我们可以引导这个过程。通过向模型提供足够多的语义相似的文档示例,我们可以将其引导到语义方向,而使用情感的示例则将其引导到情感方向。
有很多方法可以训练、微调和引导嵌入模型,但最强大且广泛使用的技术之一叫做对比学习。
二、什么是对比学习?
对比学习是训练和微调文本嵌入模型的一种重要技术。对比学习的目标是训练嵌入模型,使得相似文档在向量空间中彼此更接近,而不相似的文档则距离更远。如果这听起来很熟悉,那是因为它与第二章中提到的word2vec方法非常相似。我们在图10-2和图10-3中已经看到过这个概念。
对比学习的基本思想是,学习和建模文档之间的相似性/不相似性的最佳方式是向模型提供相似和不相似的文档对。为了准确捕捉文档的语义特征,通常需要将其与另一篇文档进行对比,以便模型学习什么使它们相似或不同。这种对比过程非常强大,且与文档的写作背景相关。这个高层次的过程在图10-4中得到了展示。
另一种看待对比学习的方式是通过解释的性质。一个有趣的例子是,一个记者问一个抢银行的贼:“你为什么抢银行?”他回答:“因为那里有钱。”尽管这是一个事实正确的回答,但问题的意图并不是问他为什么专门抢银行,而是为什么他会抢银行。这个问题被称为对比性解释,指的是理解某个特定的情况,“为什么是P?”与其他替代方案,“为什么是P而不是Q?” 在这个例子中,问题可以有多种解释,最好通过提供一个替代方案来阐明:“为什么你抢银行(P),而不是遵守法律(Q)?”对比替代方案对问题的理解也适用于嵌入模型如何通过对比学习进行学习。通过向模型提供相似和不相似的文档对,它开始学习什么使某些文档相似或不同,更重要的是,为什么。
例如,你可以教模型理解什么是“狗”,通过让它发现“尾巴”、“鼻子”、“四条腿”等特征。这个学习过程可能很困难,因为这些特征往往没有明确的定义,而且可以有多种解释。一个有“尾巴”、“鼻子”和“四条腿”的生物也可能是“猫”。为了帮助模型朝着我们感兴趣的方向学习,我们实际上是通过问它:“为什么这是狗而不是猫?”来帮助它理解。通过提供两个概念之间的对比,它开始学习定义这个概念的特征以及与之无关的特征。当我们将问题框定为对比时,我们获得的信息更多。我们在图10-5中进一步阐述了对比性解释的概念。

注意
在自然语言处理(NLP)领域,最早且最著名的对比学习例子之一实际上是word2vec,正如我们在第1章和第2章中讨论的那样。该模型通过训练单词在句子中的表示来学习单词的表示。与目标词在句子中相邻的词将构成正对,而随机抽取的词则构成不相似对。换句话说,邻近词的正向例子与随机选择的、非邻近的词对立。尽管这一点可能不为大众所知,但它实际上是NLP中首次广泛应用对比学习与神经网络的重大突破之一。
我们可以应用对比学习创建文本嵌入模型的方法有很多种,但最著名的技术和框架之一就是sentence-transformers。
三、SBERT
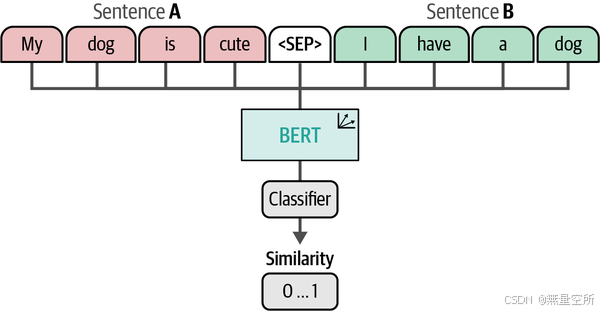
虽然对比学习有许多形式,但在自然语言处理(NLP)社区中,sentence-transformers 框架普及了这一技术。它解决了原始 BERT 实现中用于创建句子嵌入的一个主要问题,即计算开销。在 sentence-transformers 出现之前,句子嵌入通常使用一种叫做交叉编码器(cross-encoders)的架构与 BERT 结合使用。
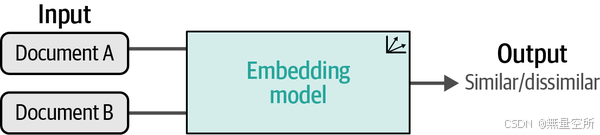
交叉编码器允许将两个句子同时输入到 Transformer 网络中,以预测这两个句子之间的相似度。它通过在原始架构上添加一个分类头来输出一个相似度分数。然而,当你需要在包含 10,000 个句子的集合中找到最相似的一对时,计算量会迅速增加。那将需要 n·(n−1)/2 = 49,995,000 次推理计算,因此产生了显著的开销。而且,交叉编码器通常不会生成嵌入,如图 10-6 所示。相反,它输出的是输入句子之间的相似度分数。
为了减少这种开销,可以通过对 BERT 模型的输出层进行平均或使用 [CLS] 标记来生成嵌入。然而,事实证明,这种方法比简单地平均词向量(例如 GloVe)效果更差。
然而,sentence-transformers 的作者采用了不同的方法,寻找了一种既快速又能生成可以语义比较的嵌入的方式。最终结果是对原始交叉编码器架构的一个优雅替代方案。与交叉编码器不同,在 sentence-transformers 中,分类头被去除,取而代之的是对最终输出层进行均值池化(mean pooling)以生成嵌入。这个池化层对词嵌入进行平均,并返回一个固定维度的输出向量。这保证了生成一个固定大小的嵌入。
3.1 训练
sentence-transformers 的训练使用了 Siamese 架构。在这种架构中,如图 10-7 所示,我们有两个相同的 BERT 模型,它们共享相同的权重和神经架构。这些模型接收输入句子,并通过对词标记嵌入的池化生成嵌入。然后,通过句子嵌入的相似性来优化这些模型。由于两个 BERT 模型的权重是相同的,我们可以使用一个模型,依次输入句子对。
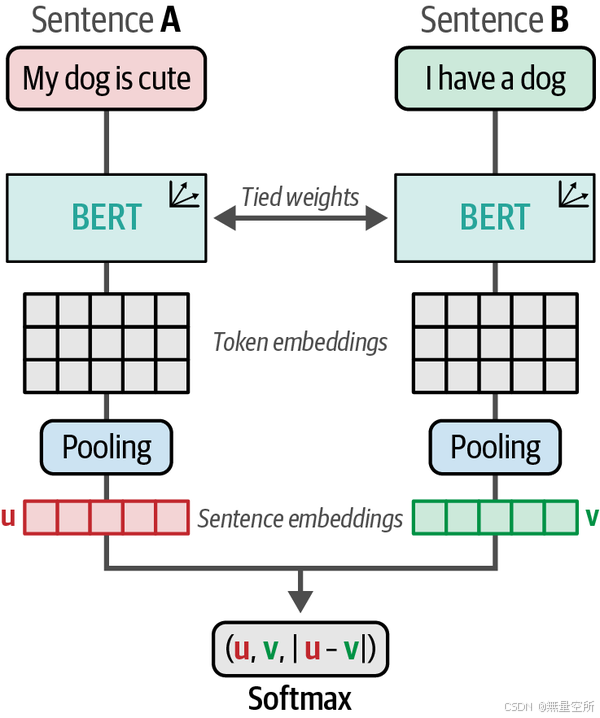
3.2 优化过程
这些句子对的优化是通过损失函数完成的,损失函数对模型的性能有重要影响。在训练过程中,首先将每个句子的嵌入与它们之间的差异进行连接。然后,通过 softmax 分类器优化这个生成的嵌入。
最终得到的架构也被称为双编码器(bi-encoder)或 SBERT(sentence-BERT)。尽管双编码器速度非常快,并且能够生成准确的句子表示,但交叉编码器通常能取得比双编码器更好的性能,但不会生成嵌入。
双编码器像交叉编码器一样,也利用了对比学习;通过优化句子对之间的(不)相似性,模型最终会学习到句子的特征。
3.3 对比学习的要求
要进行对比学习,我们需要两样东西。首先,我们需要构成相似/不相似对的数据。其次,我们需要定义模型如何定义并优化相似性。
四、创建嵌入模型
创建嵌入模型有许多方法,但通常我们会选择对比学习。这是许多嵌入模型的关键,因为该过程能够有效地学习语义表示。
然而,这并不是免费的过程。我们需要了解如何生成对比示例、如何训练模型以及如何正确评估模型。
4.1 生成对比示例
在预训练嵌入模型时,您通常会看到使用自然语言推理(NLI)数据集的数据。NLI 是研究在给定前提下,假设是否成立(entailment)、是否矛盾(contradiction)或二者皆非(neutral)的任务。
例如,当前提是“他在电影院看《可可夜总会》”且假设是“他在家看《冰雪奇缘》”时,这些陈述是矛盾的。相反,当前提是“他在电影院看《可可夜总会》”且假设是“他在电影院看的是迪士尼电影《可可夜总会》”时,这些陈述被认为是成立的。这个原理如图 10-8 所示。
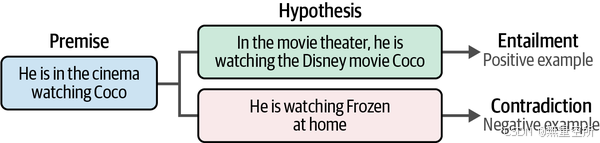
仔细观察蕴含和矛盾,它们描述了两个输入之间相似的程度。因此,我们可以利用 NLI 数据集生成负示例(矛盾)和正示例(蕴含)用于对比学习。
我们在创建和微调嵌入模型时所使用的数据来自通用语言理解评估基准(GLUE)。该 GLUE 基准包含了九个语言理解任务,用于评估和分析模型的性能。
其中一个任务是多种类自然语言推理(MNLI)语料库,它是一个包含 392,702 对句子的集合,这些句子已被标注为蕴含(contradiction, neutral, entailment)。我们将使用数据的一个子集——50,000 对标注句子,来创建一个简化的例子,这样就不需要训练几个小时。然而,请注意,数据集越小,训练或微调嵌入模型就越不稳定。如果可能的话,建议使用更大的数据集,只要它们仍然是高质量的数据:
from datasets import load_dataset
# 从 GLUE 中加载 MNLI 数据集
# 0 = 蕴含,1 = 中立,2 = 矛盾
train_dataset = load_dataset(
"glue", "mnli", split="train"
).select(range(50_000))
train_dataset = train_dataset.remove_columns("idx")
接下来,我们看一个示例:
dataset[2]
{'premise': 'One of our number will carry out your instructions minutely.',
'hypothesis': 'A member of my team will execute your orders with immense precision.',
'label': 0}
这显示了前提和假设之间的蕴含,因为它们在语义上是积极相关的,并且意义几乎相同。
4.2 训练模型
现在我们有了带有训练示例的数据集,我们需要创建嵌入模型。我们通常选择一个现有的 sentence-transformers 模型并对其进行微调,但在这个示例中,我们将从头开始训练一个嵌入模型。
这意味着我们必须定义两件事。首先,选择一个预训练的 Transformer 模型,用于生成单个词的嵌入。我们将使用 BERT 基础模型(uncased),因为它是一个很好的入门模型。然而,许多其他模型也已在 sentence-transformers 中进行评估。特别是,microsoft/mpnet-base 在用作词嵌入模型时常常能产生不错的结果。
from sentence_transformers import SentenceTransformer
# 使用基础模型
embedding_model = SentenceTransformer('bert-base-uncased')
注意
默认情况下,sentence-transformers 中的所有 LLM 层都是可训练的。尽管可以冻结某些层,但通常不建议这么做,因为解冻所有层时,模型的性能通常会更好。
接下来,我们需要定义一个损失函数来优化模型。正如本节开头所提到的,sentence-transformers 的早期实例使用了 softmax 损失。为了说明问题,我们暂时使用这种方法,但稍后会讨论更高效的损失函数。
from sentence_transformers import losses
# 定义损失函数。在 softmax 损失中,我们还需要明确设置标签的数量。
train_loss = losses.SoftmaxLoss(
model=embedding_model,
sentence_embedding_dimension=embedding_model.get_sentence_embedding_dimension(),
num_labels=3
)
4.3 评估模型
在训练模型之前,我们需要定义一个评估器,在训练过程中评估模型的性能,并确定保存最佳模型。
我们可以使用语义文本相似度基准(STSB)来评估模型的表现。它是一个人类标注的句子对集合,每对句子的相似度分数介于 1 到 5 之间。
我们使用这个数据集来探索模型在该语义相似度任务上的表现。此外,我们处理 STSB 数据,确保所有值都在 0 到 1 之间:
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
# 创建 STSB 的嵌入相似度评估器
val_sts = load_dataset("glue", "stsb", split="validation")
evaluator = EmbeddingSimilarityEvaluator(
sentences1=val_sts["sentence1"],
sentences2=val_sts["sentence2"],
scores=[score/5 for score in val_sts["label"]],
main_similarity="cosine",
)
现在我们有了评估器,我们创建 SentenceTransformerTrainingArguments,这类似于使用 Hugging Face Transformers 进行训练(我们将在下一章中探索):
from sentence_transformers.training_args import SentenceTransformerTrainingArguments
# 定义训练参数
args = SentenceTransformerTrainingArguments(
output_dir="base_embedding_model",
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
warmup_steps=100,
fp16=True,
eval_steps=100,
logging_steps=100,
)
以下是一些需要注意的参数:
num_train_epochs
训练轮次。我们将其设置为 1,以加快训练,但通常建议增加该值。per_device_train_batch_size
每个设备(例如 GPU 或 CPU)上同时处理的样本数。较大的值通常意味着更快的训练。per_device_eval_batch_size
每个设备(例如 GPU 或 CPU)上同时处理的样本数。较大的值通常意味着更快的评估。warmup_steps
在该步骤数内,学习率将从零线性增加到初始学习率。请注意,我们没有为此训练过程指定自定义学习率。fp16
启用此参数可启用混合精度训练,在该训练过程中,计算将使用 16 位浮动点数(FP16)而非默认的 32 位浮动点数(FP32)。这减少了内存使用量,并可能提高训练速度。
现在,我们已经定义了数据、嵌入模型、损失函数和评估器,可以开始训练模型。我们可以使用 SentenceTransformerTrainer 进行训练:
from sentence_transformers.trainer import SentenceTransformerTrainer
# 训练嵌入模型
trainer = SentenceTransformerTrainer(
model=embedding_model,
args=args,
train_dataset=train_dataset,
loss=train_loss,
evaluator=evaluator
)
trainer.train()
训练完成后,我们可以使用评估器来评估该任务的表现:
# 评估训练后的模型
evaluator(embedding_model)
{'pearson_cosine': 0.5982288436666162,
'spearman_cosine': 0.6026682018489217,
'pearson_manhattan': 0.6100690915500567,
'spearman_manhattan': 0.617732600131989,
'pearson_euclidean': 0.6079280934202278,
'spearman_euclidean': 0.6158926913905742,
'pearson_dot': 0.38364924527804595,
'spearman_dot': 0.37008497926991796,
'pearson_max': 0.6100690915500567,
'spearman_max': 0.617732600131989}
我们获得了几种不同的距离度量。我们最关心的是 pearson_cosine,它是基于余弦相似度的度量,值介于 0 到 1 之间,值越高表示相似度越大。我们得到了 0.59 的值,这是我们在本章中使用的基准。
提示
- 较大的批量大小通常在多个负排名(MNR)损失的情况下表现更好,因为较大的批量使得任务更具挑战性。原因在于,模型需要从更大的潜在句子对集合中找到最佳匹配句子。因此,增加批量大小会让模型在优化过程中处理更多的负样本对,从而提高模型的区分能力。
- 您可以调整代码中的批量大小,以观察其对模型训练和评估性能的影响。例如,较大的批量可能导致训练速度更快,但也可能增加计算负担或使得训练不稳定。尝试不同的批量大小可以帮助您找到性能最优的配置。
- 一般来说,如果在使用多个负样本时,较大的批量能帮助模型更好地学习区分不同句子的细微差异。如果想要进行更精细的实验,可以逐步调整批量大小,观察其对最终结果(如相似度评分)的影响。
4.4 深入评估
一个好的嵌入模型不仅仅是在 STSB 基准上获得高分!正如我们之前观察到的,GLUE 基准有多个任务可以评估嵌入模型的表现。然而,实际上还有更多基准可以用于评估嵌入模型的表现。为统一这种评估过程,Massive Text Embedding Benchmark (MTEB) 被开发出来。MTEB 涵盖了 8 个嵌入任务,覆盖了 58 个数据集和 112 种语言。
为了公开比较最先进的嵌入模型,创建了一个排行榜,展示了每个嵌入模型在所有任务中的得分:
from mteb import MTEB
# 选择评估任务
evaluation = MTEB(tasks=["Banking77Classification"])
# 计算结果
results = evaluation.run(model)
>> 结果
{'Banking77Classification': {'mteb_version': '1.1.2',
'dataset_revision': '0fd18e25b25c072e09e0d92ab615fda904d66300',
'mteb_dataset_name': 'Banking77Classification',
'test': {'accuracy': 0.4926298701298701,
'f1': 0.49083335791288685,
'accuracy_stderr': 0.010217785746224237,
'f1_stderr': 0.010265814957074591,
'main_score': 0.4926298701298701,
'evaluation_time': 31.83}}}
这为我们提供了该任务的多个评估指标,我们可以用来探索其性能。
MTEB 基准的一个优点不仅在于任务和语言的多样性,还在于它甚至记录了评估时间。尽管有许多嵌入模型存在,但我们通常更倾向于选择那些既准确又低延迟的模型。嵌入模型常常应用于语义搜索等任务,这些任务通常会受益于并且需要快速的推理速度。
由于在整个 MTEB 上测试模型可能需要几个小时,具体取决于您的 GPU,我们在本章中将使用 STSB 基准作为示范。
提示
每当您完成模型训练和评估时,重启笔记本是非常重要的。这将清除您的 VRAM,为接下来的训练示例腾出空间。通过重启笔记本,我们可以确保所有的 VRAM 都被清除。
4.4.1 损失函数
我们使用 softmax loss 训练了模型,以演示如何训练第一个 sentence-transformers 模型。然而,并不是所有损失函数都适用,softmax loss 通常并不推荐,因为有一些性能更好的损失函数。
除了软最大损失之外,有两个损失函数通常被广泛使用并且表现良好:
- 余弦相似度(Cosine Similarity)
- 多负样本排名损失(Multiple Negatives Ranking Loss, MNR)
注意:损失函数的选择远不止于这两种。例如,MarginMSE 损失函数在训练或微调 cross-encoder 时表现良好。sentence-transformers 框架中实现了许多有趣的损失函数。
4.4.2 余弦相似度损失(Cosine Similarity Loss)
余弦相似度损失是一种直观且易于使用的损失函数,适用于许多不同的用例和数据集。它通常用于语义文本相似度任务。在这些任务中,我们为句子对分配一个相似度分数,并通过该分数来优化模型。
与严格的正负句子对不同,我们假设句子对的相似性有一个特定的度量,通常这个值在 0 和 1 之间,用来表示句子对的相似度和不相似度(图 10-9)。
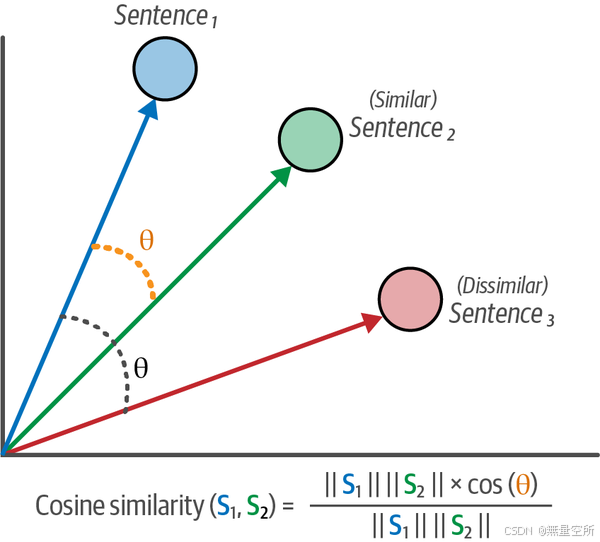
余弦相似度损失是直观的——它计算两文本嵌入之间的余弦相似度,并将该值与标签的相似度进行比较。模型将学会识别句子之间的相似度程度。
余弦相似度损失在有句子对和指示其相似度(0 到 1 之间的值)标签的数据上通常表现最好。为了使用这个损失函数,我们需要将 NLI 数据集中的 entailment(0),neutral(1) 和 contradiction(2) 标签转换为 0 到 1 之间的值。entailment 代表句子之间高度相似,因此将其标签的相似度设为 1。与此相反,由于 neutral 和 contradiction 代表不相似,因此将这些标签的相似度设为 0:
from datasets import Dataset, load_dataset
# 从 GLUE 加载 MNLI 数据集
# 0 = entailment, 1 = neutral, 2 = contradiction
train_dataset = load_dataset(
"glue", "mnli", split="train"
).select(range(50_000))
train_dataset = train_dataset.remove_columns("idx")
# (neutral/contradiction)=0 和 (entailment)=1
mapping = {2: 0, 1: 0, 0:1}
train_dataset = Dataset.from_dict({
"sentence1": train_dataset["premise"],
"sentence2": train_dataset["hypothesis"],
"label": [float(mapping[label]) for label in train_dataset["label"]]
})
接着,我们创建评估器:
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
# 创建 STSB 的嵌入相似度评估器
val_sts = load_dataset("glue", "stsb", split="validation")
evaluator = EmbeddingSimilarityEvaluator(
sentences1=val_sts["sentence1"],
sentences2=val_sts["sentence2"],
scores=[score/5 for score in val_sts["label"]],
main_similarity="cosine"
)
然后,我们按照之前的步骤进行操作,但选择一个不同的损失函数:
from sentence_transformers import losses, SentenceTransformer
from sentence_transformers.trainer import SentenceTransformerTrainer
from sentence_transformers.training_args import SentenceTransformerTrainingArguments
# 定义模型
embedding_model = SentenceTransformer("bert-base-uncased")
# 损失函数
train_loss = losses.CosineSimilarityLoss(model=embedding_model)
# 定义训练参数
args = SentenceTransformerTrainingArguments(
output_dir="cosineloss_embedding_model",
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
warmup_steps=100,
fp16=True,
eval_steps=100,
logging_steps=100,
)
# 训练模型
trainer = SentenceTransformerTrainer(
model=embedding_model,
args=args,
train_dataset=train_dataset,
loss=train_loss,
evaluator=evaluator
)
trainer.train()
训练模型后,我们进行评估,结果如下:
# 评估训练后的模型
evaluator(embedding_model)
>> 返回结果为:
{'pearson_cosine': 0.7222322163831805,
'spearman_cosine': 0.7250508271229599,
'pearson_manhattan': 0.7338163436711481,
'spearman_manhattan': 0.7323479193408869,
'pearson_euclidean': 0.7332716434966307,
'spearman_euclidean': 0.7316999722750905,
'pearson_dot': 0.660366792336156,
'spearman_dot': 0.6624167554844425,
'pearson_max': 0.7338163436711481,
'spearman_max': 0.7323479193408869}
Pearson cosine 得分为 0.72,相比于 softmax loss 示例(得分 0.59),这是一项显著的提升。这展示了损失函数对模型性能的影响。
提示
确保重启您的笔记本,以便我们探索一种更常见且性能更好的损失函数,即 多负样本排名损失(MNR)。
4.4.3 多负样本排名损失(Multiple Negatives Ranking Loss)
多负样本排名损失(MNR Loss),也称为 InfoNCE 或 NTXentLoss,是一种使用正样本对或包含一个正样本对和一个额外不相关句子的三元组的损失函数。这个不相关的句子称为负样本,它代表了正样本之间的差异。
例如,你可能有问答对、图像和图像描述、论文标题和论文摘要等正样本对。一个很好的特点是,我们可以确信这些正样本对是很难的正样本对。在 MNR 损失(图 10-10)中,负样本对通过将一个正样本对与另一个正样本对混合来构造。例如,对于论文标题和摘要的例子,你可以通过将一篇论文的标题与一个完全不同的摘要结合来生成一个负样本对。这些负样本对被称为 批内负样本(in-batch negatives),也可以用于生成三元组。
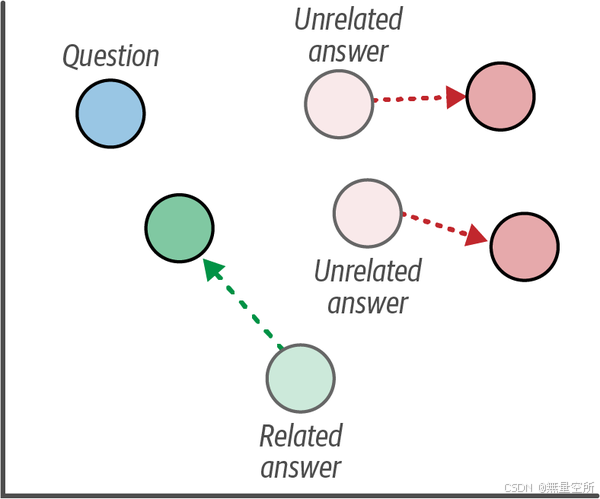
生成这些正负样本对后,我们计算它们的嵌入并应用余弦相似度。然后,使用这些相似度分数来回答这个问题:这些样本对是负的还是正的?换句话说,这被视为一个分类任务,我们可以使用 交叉熵损失 来优化模型。
为了生成这些三元组,我们从一个锚定句子开始(即标记为“premise”),它将用于与其他句子进行比较。然后,使用 MNLI 数据集,我们仅选择正样本对(即标记为“entailment”)。为了添加负样本,我们随机从“假设”句子中抽取。
import random
from tqdm import tqdm
from datasets import Dataset, load_dataset
# 从 GLUE 加载 MNLI 数据集
mnli = load_dataset("glue", "mnli", split="train").select(range(50_000))
mnli = mnli.remove_columns("idx")
mnli = mnli.filter(lambda x: True if x["label"] == 0 else False)
# 准备数据并添加软负样本
train_dataset = {"anchor": [], "positive": [], "negative": []}
soft_negatives = mnli["hypothesis"]
random.shuffle(soft_negatives)
for row, soft_negative in tqdm(zip(mnli, soft_negatives)):
train_dataset["anchor"].append(row["premise"])
train_dataset["positive"].append(row["hypothesis"])
train_dataset["negative"].append(soft_negative)
train_dataset = Dataset.from_dict(train_dataset)
由于我们只选择了标记为“entailment”的句子,因此数据行数从 50,000 行减少到了 16,875 行。
接下来,我们定义评估器:
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
# 为 STSB 创建嵌入相似度评估器
val_sts = load_dataset("glue", "stsb", split="validation")
evaluator = EmbeddingSimilarityEvaluator(
sentences1=val_sts["sentence1"],
sentences2=val_sts["sentence2"],
scores=[score/5 for score in val_sts["label"]],
main_similarity="cosine"
)
然后,我们按照之前的步骤进行训练,但使用 MNR 损失函数:
from sentence_transformers import losses, SentenceTransformer
from sentence_transformers.trainer import SentenceTransformerTrainer
from sentence_transformers.training_args import SentenceTransformerTrainingArguments
# 定义模型
embedding_model = SentenceTransformer('bert-base-uncased')
# 损失函数
train_loss = losses.MultipleNegativesRankingLoss(model=embedding_model)
# 定义训练参数
args = SentenceTransformerTrainingArguments(
output_dir="mnrloss_embedding_model",
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
warmup_steps=100,
fp16=True,
eval_steps=100,
logging_steps=100,
)
# 训练模型
trainer = SentenceTransformerTrainer(
model=embedding_model,
args=args,
train_dataset=train_dataset,
loss=train_loss,
evaluator=evaluator
)
trainer.train()
让我们看看这个数据集和损失函数与我们之前的模型有什么不同:
# 评估我们训练后的模型
evaluator(embedding_model)
返回的结果如下:
{'pearson_cosine': 0.8093892326162132,
'spearman_cosine': 0.8121064796503025,
'pearson_manhattan': 0.8215001523827565,
'spearman_manhattan': 0.8172161486524246,
'pearson_euclidean': 0.8210391407846718,
'spearman_euclidean': 0.8166537141010816,
'pearson_dot': 0.7473360302629125,
'spearman_dot': 0.7345184137194012,
'pearson_max': 0.8215001523827565,
'spearman_max': 0.8172161486524246}
与我们之前使用 softmax loss 训练的模型(得分 0.72)相比,使用 MNR loss 的模型(得分 0.80)似乎更加准确!
提示
较大的批次大小在 MNR 损失中通常表现更好,因为较大的批次使任务变得更加困难。原因是,模型需要从更大的候选句子对集中找到最匹配的句子。你可以调整代码,尝试不同的批次大小,感受它们的影响。
MNR 损失函数的一个潜在缺点
我们使用该损失函数的方式存在一个缺点。由于负样本是从其他问答对中随机抽取的,因此我们使用的批内负样本或“简单”负样本可能与问题完全无关。结果,嵌入模型接下来要做的任务,即找到正确的答案,变得非常简单。为了更好地训练模型,我们希望负样本与问题非常相关,但不是正确的答案。这些负样本称为 硬负样本(hard negatives)。由于硬负样本使任务更具挑战性,因为模型需要学习更加细致的表示,所以嵌入模型的表现通常会有显著提升。
一个很好的硬负样本的例子是这样的:假设我们有一个问题:“阿姆斯特丹有多少人?” 一个相关的答案是:“阿姆斯特丹住着近百万的人。” 为了生成一个好的硬负样本,我们理想的做法是让答案包含一些关于阿姆斯特丹和居住人数的内容,但它不是正确的答案。例如:“在乌特勒支有超过一百万人住,比阿姆斯特丹还多。”这个答案与问题相关,但不是实际的答案,因此是一个很好的硬负样本。图 10-11 展示了简单负样本和硬负样本之间的区别。
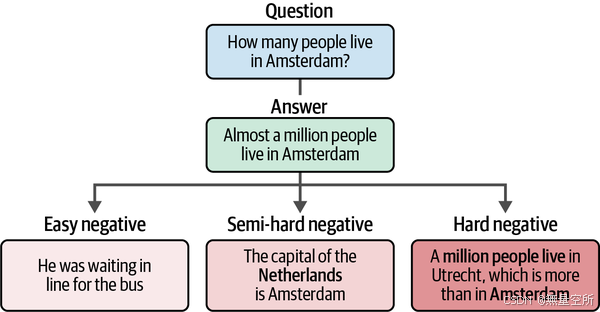
收集负样本的过程
收集负样本大致可以分为以下三种方法:
简单负样本
通过随机抽取文档,正如我们之前所做的。半硬负样本
使用预训练的嵌入模型,我们可以在所有句子的嵌入上应用余弦相似度,找出那些高度相关的句子。通常,这种方法不会生成硬负样本,因为它只是找到相似的句子,而不是问答对。硬负样本
这些通常需要手动标记(例如,通过生成半硬负样本),或者可以使用生成模型来判断或生成句子对。
确保在下一步操作之前重启你的笔记本,以便我们可以探索不同的细化嵌入模型的方法。
五、微调嵌入模型
在上一节中,我们介绍了从零开始训练嵌入模型的基础知识,并探讨了如何利用损失函数来进一步优化其性能。这种方法虽然强大,但需要从头创建嵌入模型,这一过程既昂贵又耗时。
相较之下,sentence-transformers 框架允许我们使用几乎所有预训练的嵌入模型作为基础进行微调。我们可以选择一个已经在大规模数据上训练的嵌入模型,并对其进行微调,使其更适用于我们的特定数据或任务。
根据数据的可用性和领域的不同,有多种微调模型的方法。本节将介绍两种方法,并展示如何有效利用预训练嵌入模型。
5.1 监督微调(Supervised)
最直接的微调方法是重复训练嵌入模型的过程,但用一个已经预训练的 sentence-transformers 模型代替 bert-base-uncased。我们可以选择许多不同的模型,但 all-MiniLM-L6-v2 在许多任务上表现良好,并且由于其体积较小,推理速度较快。
我们使用与 MNR 损失示例相同的数据集进行训练,但改为使用预训练的嵌入模型进行微调。首先,我们加载数据并创建评估器:
from datasets import load_dataset
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
# 加载 GLUE 数据集中的 MNLI 数据
# 0 = 蕴含(entailment),1 = 中性(neutral),2 = 矛盾(contradiction)
train_dataset = load_dataset("glue", "mnli", split="train").select(range(50_000))
train_dataset = train_dataset.remove_columns("idx")
# 加载 STS-B 数据集,作为评估器
val_sts = load_dataset("glue", "stsb", split="validation")
evaluator = EmbeddingSimilarityEvaluator(
sentences1=val_sts["sentence1"],
sentences2=val_sts["sentence2"],
scores=[score / 5 for score in val_sts["label"]],
main_similarity="cosine"
)
然后,使用 sentence-transformers 进行训练:
from sentence_transformers import losses, SentenceTransformer
from sentence_transformers.trainer import SentenceTransformerTrainer
from sentence_transformers.training_args import SentenceTransformerTrainingArguments
# 定义模型
embedding_model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# 选择损失函数
train_loss = losses.MultipleNegativesRankingLoss(model=embedding_model)
# 训练参数
args = SentenceTransformerTrainingArguments(
output_dir="finetuned_embedding_model",
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
warmup_steps=100,
fp16=True,
eval_steps=100,
logging_steps=100,
)
# 训练模型
trainer = SentenceTransformerTrainer(
model=embedding_model,
args=args,
train_dataset=train_dataset,
loss=train_loss,
evaluator=evaluator
)
trainer.train()
评估结果
evaluator(embedding_model)
>> 结果
{
"pearson_cosine": 0.8509,
"spearman_cosine": 0.8484,
"pearson_manhattan": 0.8503,
"spearman_manhattan": 0.8475,
"pearson_euclidean": 0.8513,
"spearman_euclidean": 0.8484,
"pearson_dot": 0.8489,
"spearman_dot": 0.8484,
"pearson_max": 0.8513,
"spearman_max": 0.8484
}虽然 0.85 的得分是目前我们得到的最高分,但需要注意,我们使用的预训练模型已经在完整的 MNLI 数据集上训练,而我们只用了 50,000 条数据进行微调。这虽然显得有些多余,但这一示例展示了如何在自己的数据上微调预训练的嵌入模型。
提示
与其直接使用
bert-base-uncased或可能不匹配领域的all-mpnet-base-v2,你可以首先对预训练的 BERT 进行掩码语言模型(Masked Language Modeling, MLM)训练,使其适应你的领域(domain adaptation),然后再用该模型进行嵌入训练。在下一章节中,我们将介绍如何在预训练模型上进行掩码语言建模。
请注意,训练或微调模型的主要难点在于找到合适的数据。对于这些模型,我们不仅需要非常庞大的数据集,而且数据本身的质量也必须很高。创建正样本对通常比较简单,但添加难负样本(hard negative pairs)会显著增加构建高质量数据的难度。
如往常一样,请重新启动您的笔记本(notebook)以释放 VRAM,以便进行接下来的示例。
5.2 Augmented SBERT(增强版 SBERT)
微调嵌入模型的一个主要挑战是数据的获取。许多模型在超过 10 亿 句对(sentence pairs)上训练,而大多数情况下,我们只能获得几千条标注数据。
Augmented SBERT 通过数据增强的方式,使得即使在有限标注数据的情况下,我们仍然可以训练出高质量的嵌入模型。如图10-12所示,其主要思路如下:
- 训练一个 Cross-Encoder(BERT) 作为教师模型,使用小规模的高质量标注数据(Gold 数据集)。
- 生成新的句子对,即从原始数据集中构造未标注的句对(Silver 数据集)。
- 使用 Cross-Encoder 给新句子对打分,形成更大规模的 Silver 数据集。
- 结合 Gold + Silver 数据集,训练 Bi-Encoder(SBERT)。
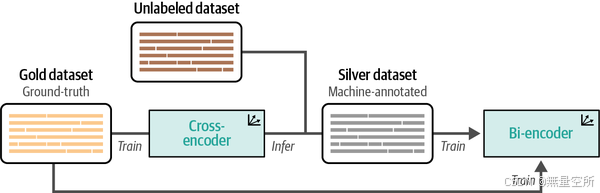
1、训练交叉编码器(cross-encoder),使用一个小型的金数据集进行微调。
2、 使用训练好的交叉编码器对未标注的数据集进行标注,生成一个更大的银数据集。
3、 结合金数据集和银数据集,训练双编码器(bi-encoder),从而提升模型的性能
在这里,gold dataset是一个规模较小但经过完整标注的数据集,它代表了真实标签(ground truth)。而silver dataset同样是一个经过完整标注的数据集,但它的标签并不一定是真实标签,因为它是通过交叉编码器(cross-encoder)的预测生成的。
在我们深入前述步骤之前,首先需要准备数据。与原始的 50,000 份文档不同,我们取其中的 10,000 份文档作为子集,以模拟有限标注数据的情况。与之前使用余弦相似度损失的示例相同,我们对标签进行如下映射:
- entailment赋值为 1
- neutral和contradiction 赋值为 0
import pandas as pd
from tqdm import tqdm
from datasets import load_dataset, Dataset
from sentence_transformers import InputExample
from sentence_transformers.datasets import NoDuplicatesDataLoader
# 为交叉编码器准备一个包含 10,000 份文档的小数据集
dataset = load_dataset("glue", "mnli", split="train").select(range(10_000))
mapping = {2: 0, 1: 0, 0: 1}
# 数据加载器
gold_examples = [
InputExample(texts=[row["premise"], row["hypothesis"]], label=mapping[row["label"]])
for row in tqdm(dataset)
]
gold_dataloader = NoDuplicatesDataLoader(gold_examples, batch_size=32)
# 转换为 Pandas DataFrame,便于数据处理
gold = pd.DataFrame(
{
"sentence1": dataset["premise"],
"sentence2": dataset["hypothesis"],
"label": [mapping[label] for label in dataset["label"]]
}
)
这是金数据集(gold dataset),因为它已经标注完成,并且代表了真实标签(ground truth)。
步骤 1:使用金数据集训练交叉编码器
from sentence_transformers.cross_encoder import CrossEncoder
# 在金数据集上训练交叉编码器
cross_encoder = CrossEncoder("bert-base-uncased", num_labels=2)
cross_encoder.fit(
train_dataloader=gold_dataloader,
epochs=1,
show_progress_bar=True,
warmup_steps=100,
use_amp=False
)
步骤 2:使用未标注数据生成银数据集
训练完交叉编码器后,我们使用剩余的 40,000 句对(来自原始 50,000 句对)作为银数据集(silver dataset)。
# 准备银数据集
silver = load_dataset(
"glue", "mnli", split="train"
).select(range(10_000, 50_000))
pairs = list(zip(silver["premise"], silver["hypothesis"]))
提示
如果没有额外的未标注句对,可以从原始的金数据集中随机采样。例如,可以从一行取前提(premise),另一行取假设(hypothesis)来构造新的句对。这种方法可以轻松生成比原始数据多 10 倍的句对,并使用交叉编码器进行标注。
不过,随机采样通常会生成更多不相似的句对。一个更优的方法是:
- **使用预训练的嵌入模型(embedding model)**对所有候选句子进行编码
- **使用语义搜索(semantic search)**选取最相似的句子对
尽管该方法仍基于近似选择(因为预训练模型未在我们的数据上训练),但效果远优于随机采样。
步骤 3:使用交叉编码器为银数据集标注
import numpy as np
# 使用微调后的交叉编码器为银数据集标注
output = cross_encoder.predict(
pairs, apply_softmax=True,
show_progress_bar=True
)
silver = pd.DataFrame(
{
"sentence1": silver["premise"],
"sentence2": silver["hypothesis"],
"label": np.argmax(output, axis=1)
}
)
步骤 4:合并金数据集和银数据集
# 合并金数据集和银数据集
data = pd.concat([gold, silver], ignore_index=True, axis=0)
data = data.drop_duplicates(subset=["sentence1", "sentence2"], keep="first")
train_dataset = Dataset.from_pandas(data, preserve_index=False)
步骤 5:定义评估器
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
# 加载 STS-B 验证数据集
val_sts = load_dataset("glue", "stsb", split="validation")
# 评估器:使用余弦相似度进行评估
evaluator = EmbeddingSimilarityEvaluator(
sentences1=val_sts["sentence1"],
sentences2=val_sts["sentence2"],
scores=[score/5 for score in val_sts["label"]],
main_similarity="cosine"
)
步骤 6:使用增强数据集训练嵌入模型
from sentence_transformers import losses, SentenceTransformer
from sentence_transformers.trainer import SentenceTransformerTrainer
from sentence_transformers.training_args import SentenceTransformerTrainingArguments
# 定义嵌入模型
embedding_model = SentenceTransformer("bert-base-uncased")
# 定义损失函数
train_loss = losses.CosineSimilarityLoss(model=embedding_model)
# 训练参数
args = SentenceTransformerTrainingArguments(
output_dir="augmented_embedding_model",
num_train_epochs=1,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
warmup_steps=100,
fp16=True,
eval_steps=100,
logging_steps=100,
)
# 训练模型
trainer = SentenceTransformerTrainer(
model=embedding_model,
args=args,
train_dataset=train_dataset,
loss=train_loss,
evaluator=evaluator
)
trainer.train()
步骤 7:评估模型
evaluator(embedding_model)
得到的结果:
{
'pearson_cosine': 0.7101597020018693,
'spearman_cosine': 0.7210536464320728,
'pearson_manhattan': 0.7296749443525249,
'spearman_manhattan': 0.7284184255293913,
'pearson_euclidean': 0.7293097297208753,
'spearman_euclidean': 0.7282830906742256,
'pearson_dot': 0.6746605824703588,
'spearman_dot': 0.6754486790570754,
'pearson_max': 0.7296749443525249,
'spearman_max': 0.7284184255293913
}
在原始余弦相似度损失示例中,我们使用完整数据集得到了 0.72 的分数。而现在,仅使用 20% 的数据,我们就取得了 0.71 的分数!
此方法能够在不需要手动标注数十万句对的情况下,扩展已有数据集的规模。你可以通过仅使用金数据集训练嵌入模型,然后与完整模型进行对比,以衡量银数据集对模型质量的贡献。
你可以重启 notebook,继续进行下一个示例:无监督学习(unsupervised learning)。
5.3 无监督学习
为了创建一个嵌入模型,我们通常需要标注数据。然而,并非所有现实世界的数据集都有一套完整的标签。因此,我们需要寻找在没有预定义标签的情况下训练模型的技术——无监督学习。存在许多不同的技术,例如 简单对比学习(SimCSE)、对比张力(CT)、基于变换器的序列去噪自编码器(TSDAE) 和 生成伪标签(GPL) 等。
在这一部分,我们将重点介绍 TSDAE,因为它在无监督任务以及领域适应方面展现了出色的性能。
5.3.1 基于变换器的序列去噪自编码器(TSDAE)
TSDAE 是一种非常优雅的无监督学习方法,用于创建嵌入模型。该方法假设我们没有任何标注数据,并且不需要我们人为地创建标签。
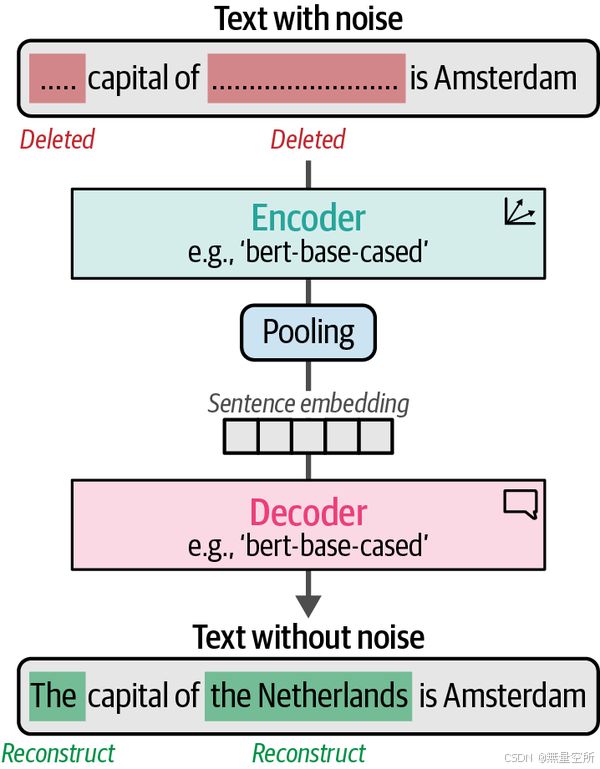
TSDAE 的基本思路是:通过去除输入句子的一定百分比的词汇来为输入句子添加噪声。这个“损坏的”句子通过编码器处理,并通过一个池化层将其映射到句子嵌入空间。然后,从这个句子嵌入中,解码器尝试从“损坏的”句子中重建原始句子,且没有人工噪声。这里的主要概念是,句子嵌入越准确,重建出的句子就会越准确。
该方法与 掩码语言建模(masked language modeling) 类似,我们试图重建并学习被掩码的词汇。不同的是,这里我们并不重建掩码的词汇,而是试图重建整个句子。
训练完后,我们可以使用编码器生成句子的嵌入,因为解码器仅用于判断嵌入是否能够准确地重建原始句子(如图 10-13 所示)。
数据准备
由于我们只需要一组句子,而不需要标签,训练该模型非常简单。首先,我们下载外部分词器,用于去噪程序:
# 下载额外的分词器
import nltk
nltk.download("punkt")
然后,我们将数据转换为简单句子,并去除所有标签,以模拟无监督设置:
from tqdm import tqdm
from datasets import Dataset, load_dataset
from sentence_transformers.datasets import DenoisingAutoEncoderDataset
# 创建一个简单句子的列表
mnli = load_dataset("glue", "mnli", split="train").select(range(25_000))
flat_sentences = mnli["premise"] + mnli["hypothesis"]
# 为输入数据添加噪声
damaged_data = DenoisingAutoEncoderDataset(list(set(flat_sentences)))
# 创建数据集
train_dataset = {"damaged_sentence": [], "original_sentence": []}
for data in tqdm(damaged_data):
train_dataset["damaged_sentence"].append(data.texts[0])
train_dataset["original_sentence"].append(data.texts[1])
train_dataset = Dataset.from_dict(train_dataset)
这会创建一个包含 50,000 句子的训练集。检查数据时,你会发现第一句是“损坏的”句子,第二句是原始句子:
train_dataset[0]
{'damaged_sentence': 'Grim jaws are.',
'original_sentence': 'Grim faces and hardened jaws are not people-friendly.'}
第一句展示的是“有噪声”的数据,而第二句是原始的输入句子。
定义评估器
和之前一样,我们需要定义一个评估器:
from sentence_transformers.evaluation import EmbeddingSimilarityEvaluator
# 创建一个 STSB 的嵌入相似度评估器
val_sts = load_dataset("glue", "stsb", split="validation")
evaluator = EmbeddingSimilarityEvaluator(
sentences1=val_sts["sentence1"],
sentences2=val_sts["sentence2"],
scores=[score / 5 for score in val_sts["label"]],
main_similarity="cosine"
)
创建嵌入模型
接下来,我们创建我们的嵌入模型,这一次使用 [CLS] token 作为池化策略,而不是 token 嵌入的均值池化。TSDAE 论文显示,使用 [CLS] token 更为有效,因为均值池化会丢失位置信息,而 [CLS] token 则不会:
from sentence_transformers import models, SentenceTransformer
# 创建嵌入模型
word_embedding_model = models.Transformer("bert-base-uncased")
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(), "cls")
embedding_model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
定义损失函数
使用我们的句子对,我们需要一个损失函数来尝试使用噪声句子重建原始句子,这就是 去噪自编码器损失(DenoisingAutoEncoderLoss)。通过这样做,模型将学习如何准确地表示数据。它类似于掩码,但不知道实际掩码的位置。
此外,我们还将两个模型的参数绑定在一起。即,编码器的嵌入层和解码器的输出层使用相同的权重。这意味着对一个层的任何更新都会反映到另一个层中:
from sentence_transformers import losses
# 使用去噪自编码器损失
train_loss = losses.DenoisingAutoEncoderLoss(
embedding_model, tie_encoder_decoder=True
)
train_loss.decoder = train_loss.decoder.to("cuda")
训练模型
最后,像之前一样训练模型,但由于这种损失函数会增加内存使用,我们将批量大小调小:
from sentence_transformers.trainer import SentenceTransformerTrainer
from sentence_transformers.training_args import SentenceTransformerTrainingArguments
# 定义训练参数
args = SentenceTransformerTrainingArguments(
output_dir="tsdae_embedding_model",
num_train_epochs=1,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_steps=100,
fp16=True,
eval_steps=100,
logging_steps=100,
)
# 训练模型
trainer = SentenceTransformerTrainer(
model=embedding_model,
args=args,
train_dataset=train_dataset,
loss=train_loss,
evaluator=evaluator
)
trainer.train()
评估模型
训练完后,我们可以评估模型,看看无监督技术的表现如何:
# 评估我们训练的模型
evaluator(embedding_model)
>> 得到的结果如下:
{'pearson_cosine': 0.6991809700971775,
'spearman_cosine': 0.713693213167873,
'pearson_manhattan': 0.7152343356643568,
'spearman_manhattan': 0.7201441944880915,
'pearson_euclidean': 0.7151142243297436,
'spearman_euclidean': 0.7202291660769805,
'pearson_dot': 0.5198066451871277,
'spearman_dot': 0.5104025515225046,
'pearson_max': 0.7152343356643568,
'spearman_max': 0.7202291660769805}训练完成后,我们得到了 0.70 的评分,考虑到我们使用的是 无标签数据,这个结果相当令人印象深刻。
5.3.2 使用 TSDAE 进行领域适应
当你几乎没有标注数据时,通常使用无监督学习来创建文本嵌入模型。然而,无监督技术通常在性能上不如有监督技术,并且在学习领域特定概念时可能会遇到困难。
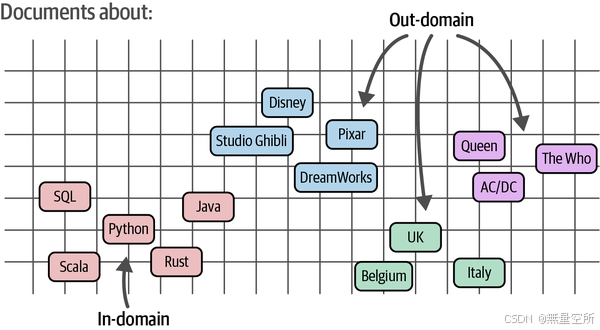
这时,领域适应(Domain Adaptation) 就显得尤为重要。它的目标是将现有的嵌入模型更新到包含与源领域不同的主题的特定文本领域。如图 10-14 所示,领域之间的内容可以大不相同。目标领域(或外部领域)通常包含源领域或内部领域中没有出现的词汇和主题。
一种进行领域适应的方法是 自适应预训练(adaptive pretraining)。你首先使用无监督技术(例如前面讨论的 TSDAE 或掩码语言建模)在特定领域的语料库上进行预训练。
然后,正如图 10-15 所示,使用一个训练数据集来微调该模型,数据集可以来自目标领域之外或目标领域内部。虽然来自目标领域的数据是首选,但由于我们已在目标领域上进行了无监督训练,因此来自外部领域的数据也能奏效。
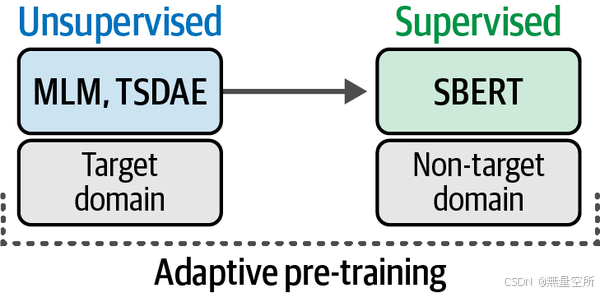
使用本章学到的所有知识,你应该能够再现这个流程!首先,你可以使用 TSDAE 在目标领域上训练一个嵌入模型,然后使用一般的有监督训练或增强型 SBERT 对其进行微调。
六、总结
在本章中,我们探讨了通过各种任务创建和微调嵌入模型。我们讨论了嵌入的概念及其在将文本数据表示为数值格式中的作用。接着,我们深入研究了许多嵌入模型的基础技术——对比学习,它主要通过(不)相似的文档对进行学习。
通过使用一个流行的嵌入框架 sentence-transformers,我们创建了基于预训练 BERT 模型的嵌入模型,同时探讨了不同的损失函数,如 余弦相似度损失 和 MNR 损失。我们讨论了(不)相似文档对或三元组的收集对于模型性能的关键作用。
在接下来的章节中,我们探讨了微调嵌入模型的技术。我们讨论了有监督和无监督技术,例如 增强型 SBERT 和 TSDAE 用于领域适应。与创建嵌入模型相比,微调通常需要更少的数据,是将现有嵌入模型适应特定领域的好方法。
在下一章中,我们将讨论为分类任务微调表示的方法。届时,BERT 模型和嵌入模型都将登场,并介绍一系列微调技术。

















 1786
1786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









