




 本文介绍了百度智能云大数据解决方案,特别是针对存算分离场景的数据湖加速方案。文章详细阐述了大数据技术的演进,百度智能云的存算分离优势,以及基于对象存储BOS的原生层级Namespace和RapidFS缓存加速方案,旨在解决存算分离带来的挑战,提高大数据处理效率。
本文介绍了百度智能云大数据解决方案,特别是针对存算分离场景的数据湖加速方案。文章详细阐述了大数据技术的演进,百度智能云的存算分离优势,以及基于对象存储BOS的原生层级Namespace和RapidFS缓存加速方案,旨在解决存算分离带来的挑战,提高大数据处理效率。
今天给大家分享一下百度智能云面向大数据存算分离场景的数据湖加速方案。
下面我从四个方面去介绍。第一部分是介绍百度智能云大数据方案的概览;第二部分是介绍存算分离的优势和挑战;第三个重点会介绍我们百度的数据湖加速方案;最后是最佳实践。
1. 大数据方案概览
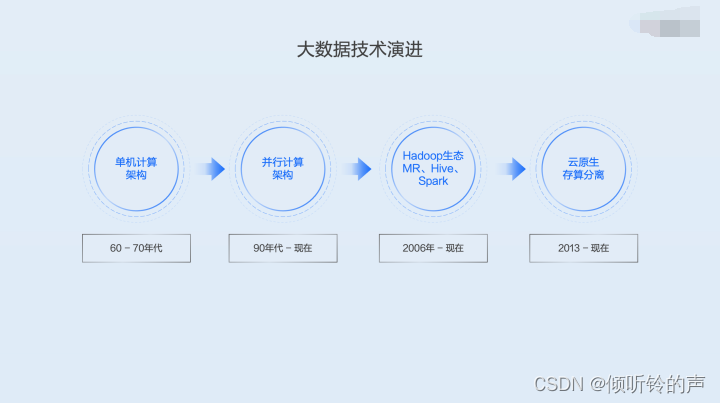
1.1 大数据技术的演进
在介绍百度智能云的大数据方案之前,先简单回顾一下大数据技术的演进。在上个世纪六七十年代,主要以单机计算架构为主,后面随着数据量增加,出现了并行的 MPP 架构,可以多台机器并行处理,加快计算速度。在 2006 年出现了 Hadoop 之后,大数据技术呈现出一个非常繁荣的发展态势,涌现出来一代又一代非常优秀的计算存储的引擎,像 MapReduce、Hive、Spark、Flink 等等。从 2013 年以后,随着大规模云业务的兴起,大数据技术呈现出新的一些特点,比如云原生、数据湖、存算分离等等。
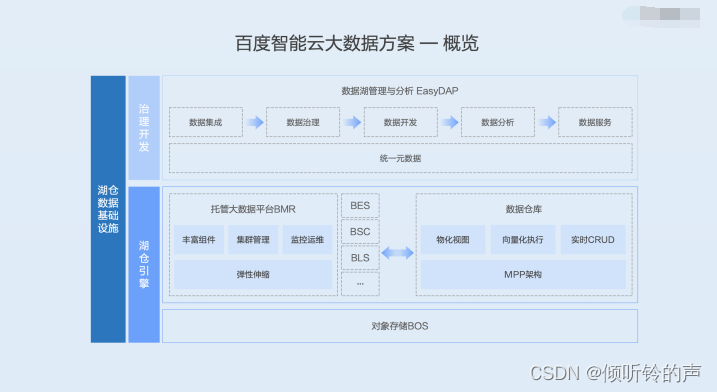
1.2 百度智能云大数据方案概览
下面这张图展示的是百度智能云大数据的整体的方案,最底层的数据湖存储使用的是对象存储 BOS。对象存储 BOS 支撑网盘近十年的时间,文件数超过万亿,存储规模超过数十个 EB,长期稳定运行。
在数据湖上面的计算引擎有两种:
-
第一种是托管大数据平台 BMR。BMR 完全兼容社区生态,有着非常丰富的主流的计算存储的组件,集群管理和运维监控也非常的完善,并且支持弹性的扩缩容。
-
另外一种是企业级的数据仓库 Doris。它通过物化视图向量化的一个执行以及现代化的 MPP 架构,以及极致的列式存储引擎等等,轻松的实现 PB 级数据的高效查询和报表工作。
最上层的平台是数据湖管理分析 EasyDAP 平台。EasyDAP 平台能够轻松的一站式的完成数据集成、数据治理、数据开发、数据分析和数据服务,并且有统一的元数据管理。
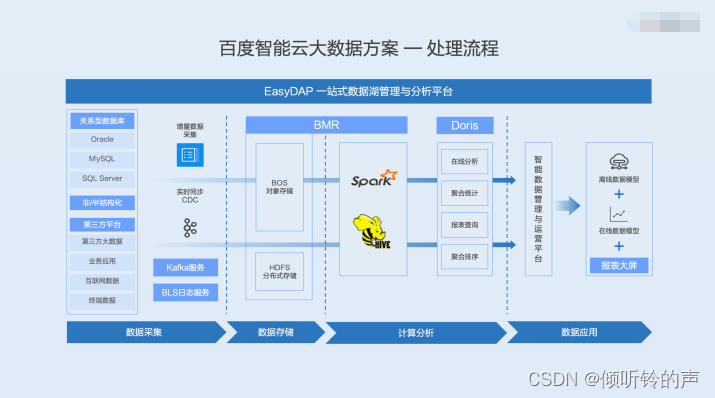
下图是百度智能云大数据的一个处理流程,分为四个部分,数据采集、数据存储、计算分析和数据应用。
在数据采集的这部分,通过 Kafka、日志传输服务、实时同步或者增量同步的方案,把数据从关系型的数据库如 Oracle、MySQL、SQL Server,或者半结构或者非结化的存储平台以及第三方的业务、互联网数据等等,传输到存储系统。
存储系统包括对象存储 BOS 和分布式的存储 HDFS 等,然后再通过 BMR 或者 Doris 的计算和分析,最后提供给数据应用使用。
因为后面介绍的数据湖加速方案都是基于对象存储 BOS 做的,所以在这里我简单的介绍一下 BOS 的架构。
百度智能云的对象存储 BOS 对外提供 RESTful 访问的 API,在最外层有一层四层负载均衡设备,四层负载均衡设备的下一层是 Webservice 服务,Webservice 提供标准的 HTTP(S) 访问,有流控、鉴权和切块校验等一些前置功能。
Webservice 下一层有两个分布式的集群,第一个分布式集群是存储 Metadata,就是元数据存储,第二个集群是一个数据存储集群,负责存储真正的数据。元数据存储集群采用 3 副本的全局有序的 Table 系统,数据存储采用的是在线 ErasureCoding 模式的存储系统。Blob Storage 有几种存储模式:第一种方式是多副本,第二种方式是离线 EC,第三种方式是在线 EC。EC 的方式相对于多副本存储方案有明显的一个成本优势。一般 EC 可以做到 1.5 副本、1.3 副本这样,但是如果是多副本的话,那可能最少是要 3 副本。
对象存储 BO
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











