







多层感知器(MLP)被认为是最基本的神经网络构建模块之一。最简单的MLP是对第3章感知器的扩展。感知器将数据向量作为输入,计算出一个输出值。在MLP中,许多感知器被分组,以便单个层的输出是一个新的向量,而不是单个输出值。在PyTorch中,正如您稍后将看到的,这只需设置线性层中的输出特性的数量即可完成。MLP的另一个方面是,它将多个层与每个层之间的非线性结合在一起。
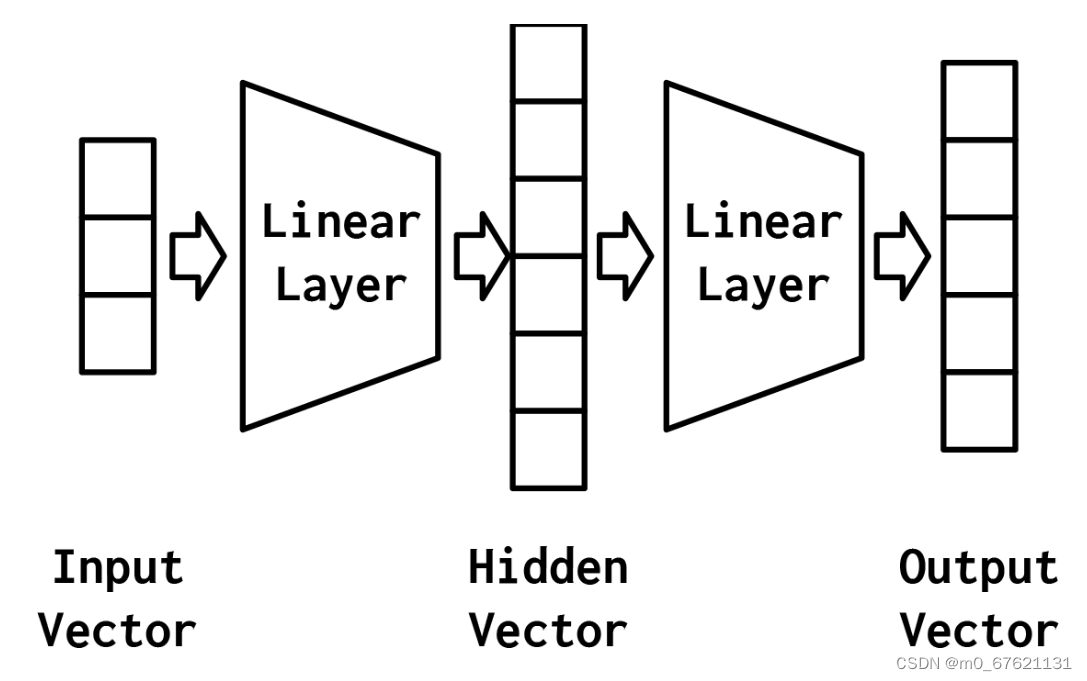
最简单的MLP,如图4-2所示,由三个表示阶段和两个线性层组成。第一阶段是输入向量。这是给定给模型的向量。在“示例:对餐馆评论的情绪进行分类”中,输入向量是Yelp评论的一个收缩的one-hot表示。给定输入向量,第一个线性层计算一个隐藏向量——表示的第二阶段。隐藏向量之所以这样被调用,是因为它是位于输入和输出之间的层的输出。我们所说的“层的输出”是什么意思?理解这个的一种方法是隐藏向量中的值是组成该层的不同感知器的输出。使用这个隐藏的向量,第二个线性层计算一个输出向量。在像Yelp评论分类这样的二进制任务中,输出向量仍然可以是1。在多类设置中,将在本实验后面的“示例:带有多层感知器的姓氏分类”一节中看到,输出向量是类数量的大小。虽然在这个例子中,我们只展示了一个隐藏的向量,但是有可能有多个中间阶段,每个阶段产生自己的隐藏向量。最终的隐藏向量总是通过线性层和非线性的组合映射到输出向量。
我们使用MLP来进行姓氏分类任务,将姓氏分类到其原籍国家。这种应用可以帮助理解如何处理和利用人口统计信息,如国籍,以确保在建模和产品应用中避免引入不公平的结果。
重要教训包括MLP的实现和训练源于感知器的基本原理,但通过引入多层和非线性激活函数,MLP能够更有效地处理复杂的分类任务。在这个过程中,我们将姓氏的字符进行拆分和向量化,类似于处理文本数据时的方法,通过词汇表、向量化器和DataLoader构建数据处理管道,以便将原始数据转换为模型可处理的格式。
MLP的模型结构与实验3中感知器的例子类似,但在这里我们引入了多类输出和适当的损失函数,如交叉熵损失,以优化模型的训练过程。训练过程类似于“餐馆评论的情绪分类”的例子,利用反向传播和优化器进行模型参数的调整,以提高分类准确性。
总结来说,这个例子展示了如何利用MLP处理具有受保护属性的数据,如人口统计信息,同时强调了在使用这些信息时需要谨慎的重要性,以确保结果的公平性和准确性。
载入数据集和实现姓氏矢量器
class SurnameDataset(Dataset):
# Implementation is nearly identical to Section 3.5
def __getitem__(self, index):
row = self._target_df.iloc[index]
surname_vector = \
self._vectorizer.vectorize(row.surname)
nationality_index = \
self._vectorizer.nationality_vocab.lookup_token(row.nationality)
return {'x_surname': surname_vector,
'y_nationality': nationality_index}class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def __init__(self, surname_vocab, nationality_vocab):
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""Vectorize the provided surname
Args:
surname (str): the surname
Returns:
one_hot (np.ndarray): a collapsed one-hot encoding
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
for index, row in surname_df.iterrows():
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









