






文章:预测具有共享单元和多通道注意力机制的circRNA -疾病关联
原文链接:https://academic.oup.com/bioinformatics/article/41/3/btaf088/8056035
大多数方法未能充分挖掘跨视图的潜在信息,同时忽略了不同视图贡献不同程度的重要性这一事实。
circRNA -疾病关联的预测模型分为三类:网络传播模型、传统机器学习模型和深度学习模型。
基于网络的方法通过使用已知关联构建异构网络并计算它们的相似度来预测新的关联,但它们往往过于强调相似性得分。
传统的基于机器学习的模型通过使用人工提取的特征训练分类器来预测关联,但其性能严重依赖于提取的特征。
基于深度学习的方法擅长潜在特征的提取,而且利用多视图提取更加丰富的信息,但没有有效地利用不同视图之间的潜在特征。
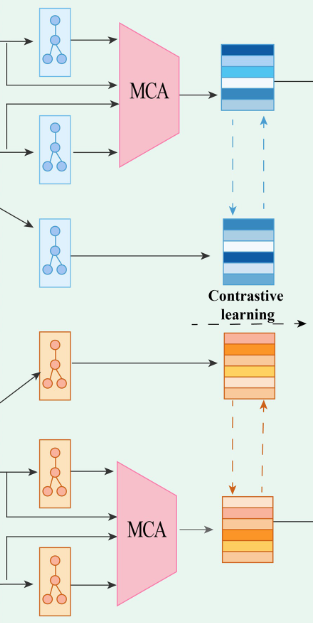
作者提出了MSMCDA,一种利用共享单元和注意力机制进行circRNA-疾病关联预测的新方法。首先,MSMCDA为circRNA和疾病构建相似性和元路径网络,并设计共享单元,以方便相似性和元路径网络之间的信息交换和融合。然后,我们使用注意力机制来合并多个相似性网络中的特征。最后,通过对比学习增强相似网络的特征,并使用MLP分类器来预测关联。
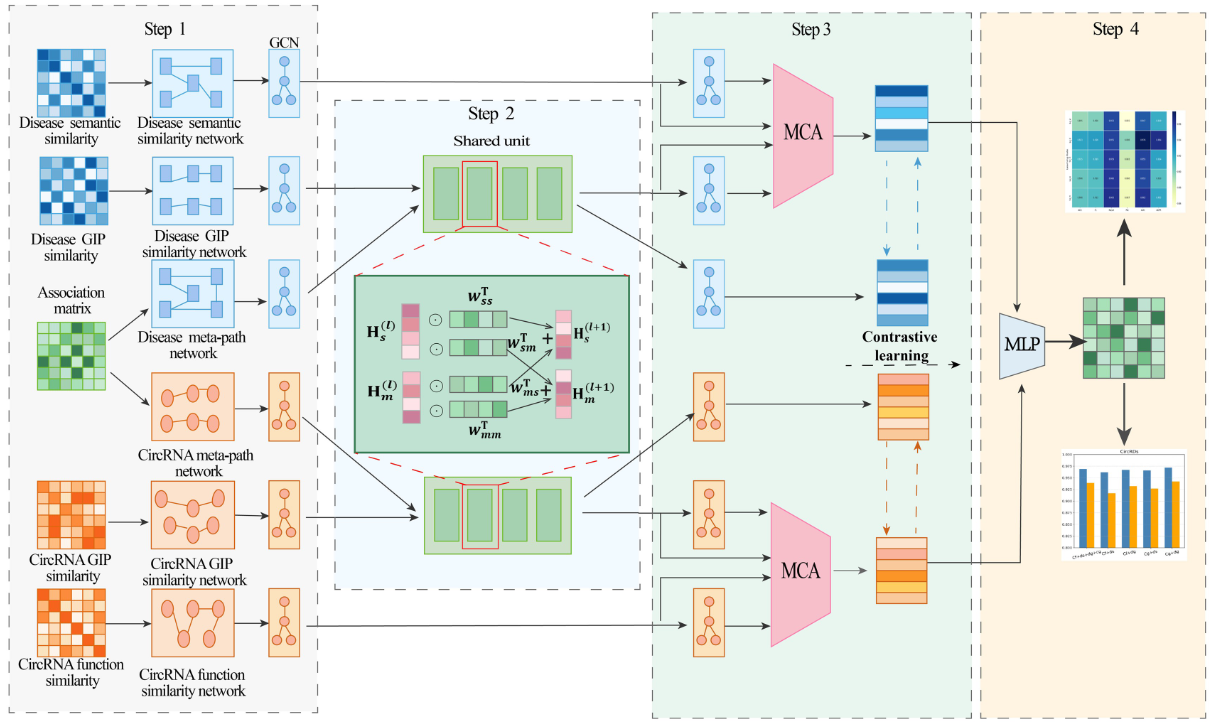
1 ) MSMCDA引入了便于跨视图特征交互的共享单元,实现了融合过程中的互补集成,捕获了潜在的跨视图信息。
2 ) MSMCDA使用注意力机制为不同相似性网络的特征分配不同的重要性等级。
3 ) MSMCDA引入了一种对比学习方法来充分利用视图间的互补信息,通过对齐相似特征和区分不相似特征来增强特征,从而提高模型捕获有意义信息的能力。
circRNAs与疾病相似性网络构建
相似性的度量采用两种方法:语义相似性和高斯核(GIP)相似性用于疾病,而功能相似性和GIP相似性用于circRNA。
疾病相似性网络的构建
作者从疾病本体数据集中检索每个疾病的疾病本体标识( Disease Ontology Identity,DOID )用于疾病语义相似度,并使用R语言包中提供的Dosim函数计算相似度。在疾病本体框架中,每个疾病由一个有向无环图( directed acyclic graph,DAG )表示。Dosim函数中的公式定义为:
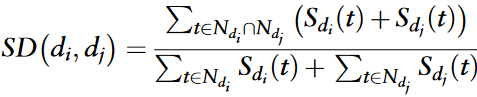
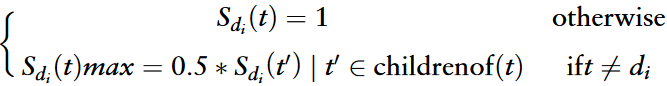
t≠di时,t'是t的孩子节点
疾病语义相似度数据稀疏,引入GIP相似度来丰富相似度特征信息。根据疾病i和j在关联矩阵中的对应列,使用核函数计算疾病i和j之间的GIP相似性:
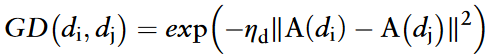
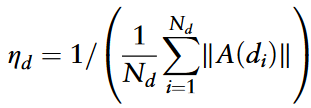
疾病语义相似度网络Gds中的边权重由SD(di,dj)确定;疾病GIP相似性网络Gdg中的边权重由GD(di,dj)确定。
circRNA相似性网络构建
circRNAs的功能相似性表明,具有相似功能的circRNAs往往与相似的疾病相关。用于计算circRNA ci和cj功能相似性的公式如下:
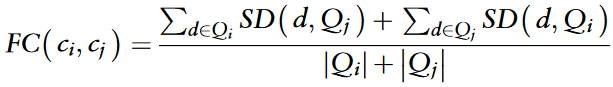
与疾病类似,circRNA也利用GIP相似性来丰富相似性信息。
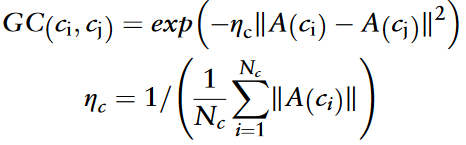
与疾病网络类似,circRNA功能相似性网络Gcf使用FC(ci,cj)定义的边权重;GIP相似性网络Gcg使用GC(ci,cj)定义的边权重。
元路径网络的构建
元路径全面地表示了circRNA和疾病之间的结构联系,使得捕获关联网络内的详细结构信息成为可能。
MSMCDA基于不同的元路径开发了circRNA和疾病的元路径网络。
作者定义了两种元路径:m1=CDC用于circRNAs,m2=DCD用于疾病。利用这些元路径构建了各自的元路径网络。circRNA网络的构建如下:
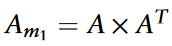
疾病的元路径网络m2由:
![]()
Gm1和Gm2中的边权重分别由其对应的Am1和Am2值确定。
多视图相似性网络的特征提取
作者使用GCN从构建的circRNA和疾病网络中提取相似性和元路径特征。该方法能够实现跨网络节点特征的有效集成和增强。经过1层GCN卷积后,circRNAs的更新特征计算如下:
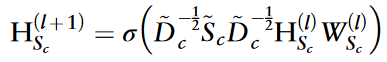
WSc表示可学习参数,σ为激活函数,HSc表示第l层的circRNA节点特征。
类似地,对于疾病相似性网络Sd,第l+1层的更新嵌入为:
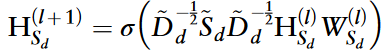
~Dd为度矩阵,HSd为第l层中的疾病节点特征。
元路径网络的特征学习过程遵循同样的方法。对于元路径网络Amn(n∈{1,2}),第l+1层节点特征如下:
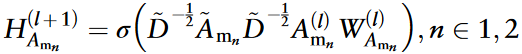
~D是其度矩阵,H(l)Amn表示第l层中的节点特征。
共享单元
为了增强circRNA和疾病网络中的特征对齐,促进相似性信息和元路径信息之间的跨视图交互,作者引入了一个新颖的共享单元,该单元包括4个线性操作模块,每个模块旨在促进跨视图的相互学习。

以circRNA为例,通过第一个线性模块对GIP相似性网络特征和元路径网络特征进行初步处理。随后,四个可训练权重自适应地确定每个输入特征在每个线性操作中的相对重要性。
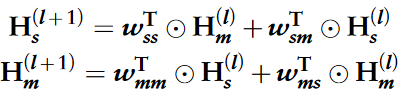
算子O表示逐元素乘法,wTss、wTsm、wTmm和wTms是可训练参数。
共享单元作为视图之间的桥接机制,促进跨视图的特征交互,以迭代地精化输入表示。
共享单元在GIP相似性和元路径视图中都被策略性地定位在GCN的第1层和第2层之间,从而能够在中间表征水平上实现信息的有效整合。
注意力机制
考虑到从不同相似度视图中提取的节点特征对结果的影响不同,作者引入多通道注意力机制来自适应调整每个视图的重要性。
首先,对circRNA相似性视图的重要性系数αc进行如下计算:
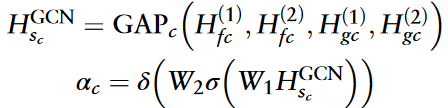
调整后的circRNA相似性特征计算如下:
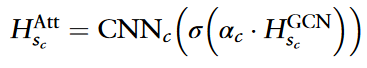
重要性系数和调整后的疾病相似性特征被计算为:
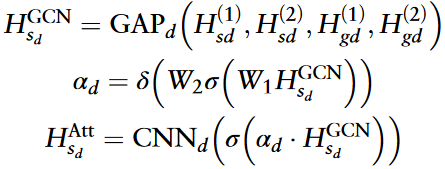
ReLU激活函数用σ表示,sigmoid函数用δ表示。
对比学习
在训练过程中使用对比学习最大化正样本内的相似性,最小化负样本间的相似性,以提高特征表示。正样本是指同一实体在不同视角下的特征,负样本是指不同实体在不同视角下的特征。
针对circRNAs的对比学习损失定义为:
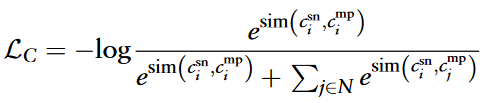
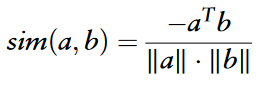
疾病的对比学习损失遵循相同的方程:
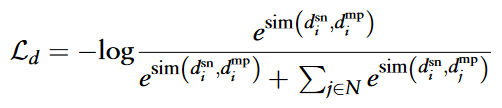
最终解码器
在预测阶段,使用元素乘法将circRNA和疾病特征相结合,然后传递到全连接层。随后,使用sigmoid激活函数输出最终的预测评分。
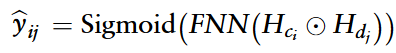
操作O表示元素级乘法,FNN为全连接层。sigmoid函数为激活函数。
为了优化整个模型,本研究使用了二元交叉熵损失,定义为:
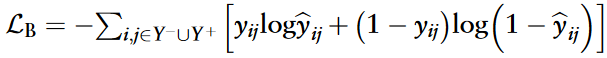
MSMCDA的最终损失函数L由下式给出,它集成了对比学习策略的两个损失函数:
![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









