






1.dfs算法理解
dfs算法的原理就是:一条路走到黑,然后再逐步回退(回溯)
2.引入
2024年4月2日15:15:45添加:
================================================
【1、2、3】的全排列
先写以1 开头的全排列:[1,2,3];[1,3,2] 即 1+[2,3] 的全排列
再写以2开头的全排列:[2,1,3] ; [2,3,1] 即 2+[1,3] 的全排列
最后写以3开头的全排列: [3,1,2] ; [3,2,1] 即 3+[1,2]的全排列
总结搜索的方法:按顺序枚举每一位可能出现的情况,已经选择的数字在 当前要选择的数字中不能出现。按照这种策略搜索就能够做到不重不漏。
================================================
例题:1、2、3的全排列
-
把 1,2,3 这三个数全排列,你会怎么排?
首先,我们定义一个约定——总是先排最小的那个 1开头:123,132 2开头:213,231 3开头:312,321 如此,我们就完成了1,2,3的全排列
这里面就蕴涵了我们的dfs思想
-
怎么就用了dfs呢?我们给(全排列)这个问题形象化
问:假设我有三个盒子(序号为1,2,3)和1,2,3这三张纸牌, 现在我们要把这三张牌放到三个盒子中, 且每个盒子只能放一张纸牌,一共有多少种放法? (其实就是实现1,2,3三个数字的全排列) 解: 以下,1表示纸牌,【1】表示盒子 还是那个约定:每次都先放手里最小的那张牌 (按照【1】【2】【3】的顺序放哦) 我们要开始放了。 -
以下是简图(我也不爱看大段的文字嘿嘿。拍的有点歪,见谅~)

首先,把1放到【1】中(因为手里1最小)
然后,把2放到【2】中
最后,把3放到【3】中
这时,我们完成了第一种方案,排序为123
现在手里是没有牌的 (重点来了) 我们需要把牌拿出来,才能进行第二次放牌
怎么拿呢?——》这就用到了dfs中回溯的思想,也是dfs的核心思想——》我们不需要(也一定不要)把所有的牌都取出来
我们现在站在【3】这,那就先把3拿出来
现在手里就有了3号纸牌,和空箱子【3】(虽然手里有牌-》能放吗?—》不能,放了不就重复了)
所以,要到【2】中把2拿出来(我们从【3】到【2】就是回退了一步)
现在手里有2,3两张纸牌,面前有【2】【3】两个空箱子
(现在是不是还要按照约定先放最小的呢?当然是)
但,刚刚已经在3之前先放了2,所以要放除2以外最小的,也就是3
综上,方案二的操作为:
取3
取2
3放入【2】
2放入【3】
方案三就为:
取3-》取2-》取1
2放【1】-》1放【2】-》3放【3】
综上,按照这样的思路就可以得到1,2,3的全排列
代码部分
-
提前说明
写代码之前,我们需要解决这几个问题: 1.怎么往盒子里放牌? 2.怎么保证一个盒子只放一张牌? 3.怎么取牌? 4.怎么走到下一个盒子那,放下一张牌? 解决: 1.放牌:定义一个a[k]数组,k表示盒子号 那么令 a[k]=纸牌号 即可 2.一个盒子放一张牌:定义一个book[k]数组,k表示盒子号 那么定义 book[k]=1时,表示盒子不是空 book[k]=0,表示盒子为空 (也可以 定义一个boolean变量,当其为true时,盒子不空;其为false时,盒子为空) 3.取牌:book[k]=0 即可 其实在代码逻辑中,我们定义一个需要排序的数组,这个数组是一直存在的,我们需要时候直接用就行 所以,只需要把盒子清空 就好 4.走向下一个盒子:k+1 不就代表了下一个盒子吗 只是在这里,处理k+1的方式要稍复杂些 因为每到一个盒子面前,我都要进行放牌的操作(但总不能每次放牌都要写一个循环吧), 因此我们考虑把以上三个问题封装为一个函数,用递归来解决 走向下一个盒子就变成了dfs(k+1) 这里有一个问题,我运行代码的时候只有k+1能正确运行,k++和++k都不可以 AI给出的解释是这样的

- 代码实现
import java.util.Scanner;
public class Main {
static int n;
static int[] a;
static boolean book[];
public static void main(String[] args) {
Scanner scanner=new Scanner(System.in);
n=scanner.nextInt();
a=new int[n+2];
book=new boolean[n+2];
dfs(1);
scanner.close();
}
public static void dfs(int k) {
// 回头条件
if(k==n+1){ //说明n个盒子都已经放完了
for(int i=1;i<=n;i++){
System.out.print(a[i]+" ");
}
System.out.println();
return; //这里的return是返回上一级dfs(可以理解为,方案一执行完了,还要进行方案二的排序)
}
// 放牌等操作
for(int i=1;i<=n;i++){ //进行1~n号牌的排序
if(book[i]==false){ //当这个盒子里没有牌时,可以进行以下操作
a[k]=i; //i号牌放入k号盒子中
book[i]=true; //标记盒子不为空
dfs(k+1); //带着手中的牌,走向下一个盒子
book[i]=false; //箱子置空。其实每次循环都执行到dfs(k++),只有当执行到没有路可走的时候,才会"回头";也就相当于例子中的,要从3号箱开始往回一个个收牌了
}
}
return;
}
}
======================
3. !!迷宫问题(重重重点!!)
-
其实,dfs更经典的问题是——迷宫问题【2】
一只老鼠走迷宫 - 在每个路口,它都是先走右边,能走多远走多远 - 碰壁无法再继续往前走,回退一步,这一次改走左边,然后继续往下走 - 重复以上步骤。只要没到出口,就会走遍所有的路,而且不会重复(规定回退不算重复走) - 这就是dfs:“一路到底,逐步回退(回溯)" - dfs算法确定有解:只要有出口,肯定能走到 -
dfs算法一般用递归实现
先来举个 递归例子:斐波那契数列 1,1,2,3,5,8,13,21…
f(n)=f(n-1)+f(n-2);
//递归实现斐波那契
//打印第20个数
public class Main{
static int cnt=0;
public static int fib(int n){
cnt++;//记录递归的次数
if(n==1||n==2) //递归出口(终止条件)
return 1;
return fib(n-1)+fib(n-2); //递归两次--》O(2^n)
}
public static void main(String[] args){
System.out.println(fib(20));//output:6765
System.out.println(cnt);//output:13529
}
}
由此代码发现,递归的时间复杂度太大了
假如我们求fib(5),代码执行步骤:
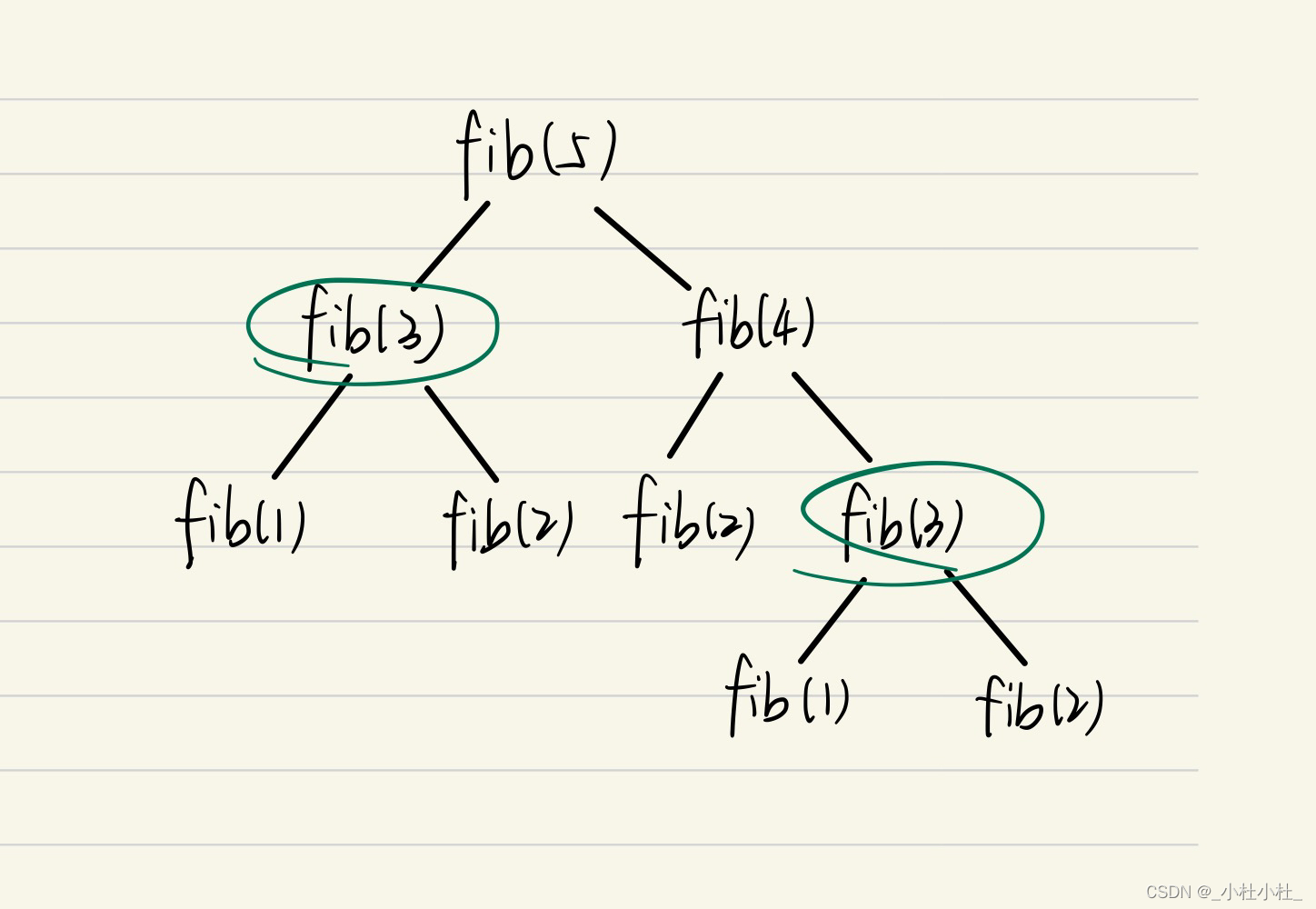
不难发现,递归过程中做了很多重复的工作——例如fib(3)计算了2次,其实只计算1次就够了
记忆化
- 由此引出递归的优化:记忆化
记忆化:为避免递归时重复计算子问题,可以在子问题得到解决时,保存结果,再次需要这个结果时,直接返回保存的结果就行了
//引入一个data[]数组,记录已经算过的fib的值
public class Main{
static int cnt=0;
static int[] data=new int[20+2]; //因为我们要求fib(20),所以数组大小可以直接给定(+2是为了防止数据溢出)
public static int fib(int n){
cnt++;
if(n==1||n==2){
data[n]=1;
return data[n];
}
if(data[n]!=0) //如果data[n]有值,那么就不用进行下面的运算了
return data[n];
data[n]=fib(n-1)+fib(n-2);
return data[n];
}
public static void main(String[] args){
System.out.println(fib(20));
System.out.println(cnt); //output:cnt=37
}
}
(其实上面的 book[i]=true 就是运用了记忆化搜索)
剪枝
例题:每个方块代表1~13中的某一个数字,但不能重复。求满足下面四个等式的方案,一共有多少种?
口+口=口
口-口=口
口*口=口
口/口=口
- 如果暴力枚举的话,就是13*12*11*…*1种可能的排序,也就是要求 13!的全排列
显然不可取,13太大了,不可能枚举那么多次
- 这时,可以用剪枝的思想
- 并不用生成一个完整的排列。例如一个排列的前3个数,如果不满足“口+口=口”,那么后面的就都不用算了,因为不论怎样排列,肯定都不对。
- 这种提前终止搜索的优化技术叫“剪枝”
ans; 答案,用全局变量表示
void dfs(层数){
if(出局判断){ //到达最底层,或者满足条件退出
更新答案; //答案一般用全局变量表示
return;
}
(剪枝) //在进一步dfs之前剪枝
for(枚举下一层可能的情况){ //对每一个情况继续dfs
if(used[i]==0){ //如果状态i没有用过,就可以进入下一层
used[i]=1; //标记状态i,表示已经用过,在更底层不能再使用
dfs(层数+1); //下一层
used[i]=0; //状态恢复,回溯时,不影响上一层对这个状态的使用
}
}
return; //返回到上一层
}
参考文章:
【1】【DFS入门级(模板) - 优快云 App】http://t.csdnimg.cn/vJplx
【2】【蓝桥杯软件类基础知识梳理:DFS-哔哩哔哩】 https://b23.tv/Ic4q1zV

















 30万+
30万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









