







 文章介绍了在React中如何通过状态提升来处理共享状态的问题,以一个示例展示了两个子组件如何共享并影响彼此的薪资输入值,同时进行货币转换。当一个组件的输入值变化时,会更新父组件的状态,进而影响另一个组件的显示。此外,还包含了一个判断是否为‘有钱人’的功能,根据薪资转换后的值进行判断。
文章介绍了在React中如何通过状态提升来处理共享状态的问题,以一个示例展示了两个子组件如何共享并影响彼此的薪资输入值,同时进行货币转换。当一个组件的输入值变化时,会更新父组件的状态,进而影响另一个组件的显示。此外,还包含了一个判断是否为‘有钱人’的功能,根据薪资转换后的值进行判断。
状态提升
通常,多个组件需要反映相同的变化数据,这时我们建议将共享状态提升到最近的共同父组件中去。让我们看看它是如何运作的。
案例说明:
两个子组件都可以输入薪资,单位分别是人民币(CNY)和美金(USD). 其中一个被输入,同时会被换算(汇率按照6.65)成另一个币种显示换算后的结果. 两个组件输入的值会相互影响. 同时外部组件会根据薪资判断是否是”有钱人”.
在这里两个子组件的input值都是分别被另一个子组件共享的,所以这个值我们把它提升到父级组件. 通过对父级组件的修改,从而影响另一个组件的输入. 这个就是input.value的状态提升.

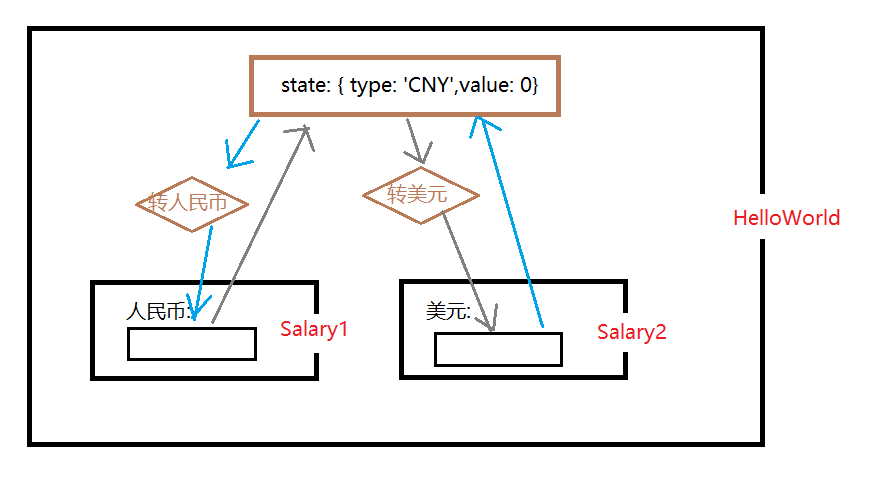
代码部分:
class Salary extends React.Component {
constructor(props) {
super(props);
this.handleChange = this.handleChange.bind(this);
}
handleChange(e) {
this.props.onChange(e.target.value);
}
render() {
return (
<div>
<fieldset>
<legend>薪资{this.props.cType}:</legend>
<input onChange={this.handleChange} value={this.props.cValue||''}/>
{this.props.cTypeIcon}
</fieldset>
</div>
);
}
}
class HelloWorld extends React.Component {
constructor(props){
super(props);
this.state = {
type: 'CNY',
salary: 0
},
this.reverse = this.reverse.bind(this);
this.handleCNYChange = this.handleCNYChange.bind(this);
this.handleUSDChange = this.handleUSDChange.bind(this);
}
componentDidUpdate(){
console.log(this.state);
}
reverse(type,salary){
// 费率
const C = 6.65;
var outValue = 0;
var inputValue = parseFloat(salary);
if(Number.isNaN(inputValue)){
return '';
}
// 转换成人民币
if(type == 'CNY'){
outValue = salary*C;
}else{
outValue = salary/C;
}
// 四舍五入 保留2位
var roundValue = Math.round(outValue*100)/100;
// 格式化
if(roundValue.toString().indexOf('.')==-1){
roundValue += '.00';
}else{
//小数部分
var dotNumber = roundValue.toString().split('.')[1];
dotNumber = dotNumber.length==1? dotNumber+'0': dotNumber;
roundValue = roundValue.toString().split('.')[0]+'.'+dotNumber;
}
return roundValue;
}
// 人民币转换美元
handleCNYChange(salary){
this.setState({
type: 'CNY',
value: salary
})
}
handleUSDChange(salary){
this.setState({
type: 'USD',
value: salary
})
}
// 判断是否是高收入
areUOk(){
// 人民币高于1000算高收入
if(this.state.type == 'CNY'){
return this.state.value>1000;
}else{
return this.reverse('CNY',this.state.value)>1000;
}
}
render() {
var type = this.state.type;
var value = this.state.value;
var CNY_value = type=='CNY'? value: this.reverse('CNY',value);
var USD_value = type=='USD'? value: this.reverse('USD',value);
return(
<div>
<Salary key="1" onChange={this.handleCNYChange} cValue={CNY_value} cType="人民币" cTypeIcon="¥"/>
<Salary key="2" onChange={this.handleUSDChange} cValue={USD_value} cType="美元" cTypeIcon="$"/>
<p>{this.areUOk()?'您真是有钱人!':'你还需要加油啊!'}</p>
</div>
)
}
}
















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









