






C++(进阶) 第4章 map和set的使⽤
文章目录
前言
上一篇博客写了二叉搜索树,这一篇博客会在上一篇博客原来的上在深入介绍
我们搜索一个数通常有下面几种方式
- 暴力查找->效率低下
- 排序+二分查找 ->插入删除代价大,因为它底层是数组
- 链式结构的二叉搜索树,它输入数据最多最优只需要走它的高度即可,做差也有N的时间复杂度
为了稳定二叉树时间复杂度,这里引入平衡二叉树(AVL,红黑树)
- 二叉搜索树O(N)
- 平衡二叉树(AVL,红黑树) O( log N)
- 多叉平衡搜索树(B树系列)
- 哈希
我们现实中模式差不多有俩种
- key模式 ->在不在 ,比如门禁系统
- key/value 通过一个值(key)找另一个值(value), 比如词典,输入中文显示出它的英文
一、序列式容器和关联式容器
- 序列容器:前⾯我们已经接触过STL中的部分容器如string、vector、list、deque、array、forward_list等,这些容器统称为序列式容器,因为逻辑结构为线性序列的数据结构,两个位置存储的值之间⼀般没有紧密的关联关系,⽐如交换⼀下,他依旧是序列式容器。顺序容器中的元素是按他们在容器中的存储位置来顺序保存和访问的。
- 关联式容器也是⽤来存储数据的,与序列式容器不同的是,关联式容器逻辑结构通常是⾮线性结构,
两个位置有紧密的关联关系,交换⼀下,他的存储结构就被破坏了。顺序容器中的元素是按关键字来
保存和访问的。关联式容器有map/set系列和unordered_map/unordered_set系列。
二、set
set和multiset参考⽂档
https://legacy.cplusplus.com/reference/set/
set 是一种key模式
1. insert
这个就和之前的容器都一样比较简单
#include<bits/stdc++.h>
#include<set>
using namespace std;
int main()
{
set<int> s;
s.insert(5);
s.insert(2);
s.insert(7);
s.insert(4);
s.insert(1);
s.insert(9);
return 0;
}
2.迭代器遍历
#include<bits/stdc++.h>
#include<set>
using namespace std;
int main()
{
set<int> s;
s.insert(5);
s.insert(2);
s.insert(7);
s.insert(4);
s.insert(1);
s.insert(9);
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
return 0;
}
可以看到这里迭代器默认走的是中序的

3.范围for
这个也挺简单的
#define _CRT_SECURE_NO_WARNINGS
#include<bits/stdc++.h>
#include<set>
using namespace std;
int main()
{
set<int> s;
s.insert(5);
s.insert(2);
s.insert(7);
s.insert(4);
s.insert(1);
s.insert(9);
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : s)
{
cout << e << " ";
}
return 0;
}

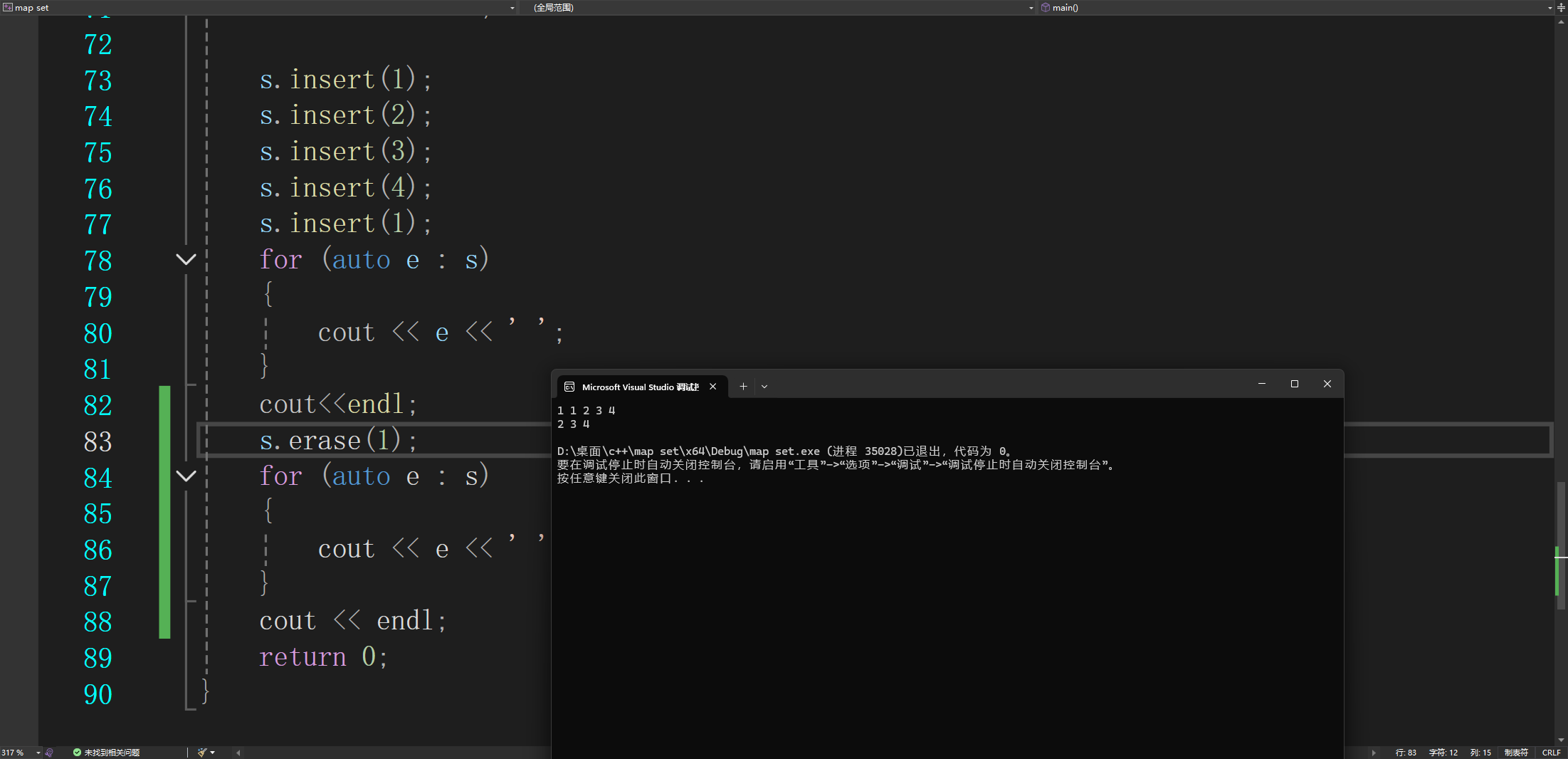
4.erase

这里有一个细节假如要删除这颗树里最小的值可以直接用迭代器删除

5.count
这个函数的功能不能统计次数,这个是用来判断在不在的

6.lower_bound和upper_bound
这俩个函数返回的都是查找的那个数的迭代器这类配合erase可以删除一个范围的数
#include<bits/stdc++.h>
#include<set>
using namespace std;
int main()
{
set<int> s;
for (int i = 1; i <= 5; i++)
{
s.insert(i);
}
for (auto e : s)
{
cout << e << ' ';
}
cout << endl;
auto itlow = s.lower_bound(2);
auto itup = s.upper_bound(4);
s.erase(itlow, itup);
for (auto e:s)
{
cout << e << ' ';
}
return 0;
}
三、multiset
1.multiset 和set 的区别
这个和set的区别就是set不允许数据有重复的,但是这个就可以,这个是直接排序

它的set的区别就是这个查找一个有相同的数的时候它返回的是中序遍历的第一个这个可以直接去查找这一段相同的值
int main()
{
multiset<int> s;
s.insert(1);
s.insert(2);
s.insert(3);
s.insert(4);
s.insert(1);
for (auto e : s)
{
cout << e << ' ';
}
cout << endl;
auto pos = s.find(1);
int x;
cin >> x;
while (pos !=s.end() && *pos == x)
{
cout << *pos << " ";
pos++;
}
return 0;
}

这样就更有意义
2.erase
假如在multiset里面erase一个重复的数,那么是删一个还是全部删呢
答案是全删
四、map
map是一种key/value模式
1.insert
c++这里提供了五种写法
1.有名(垃圾)
int main()
{
map<string, string> dict;
pair<string, string> kv("left", "左边");
dict.insert(kv);
return 0;
}
2. 匿名(垃圾)
dict.insert(pair<string, string>("right", "右边"));
3.make_pair(垃圾)
dict.insert(make_pair("insert", "插入"));
4. 花括号
dict.insert({ "string","字符串" });
5.适配器
map<string, string> dict = { { "left", "左边" }, { "right", "右边" }, { "insert", "插入" },
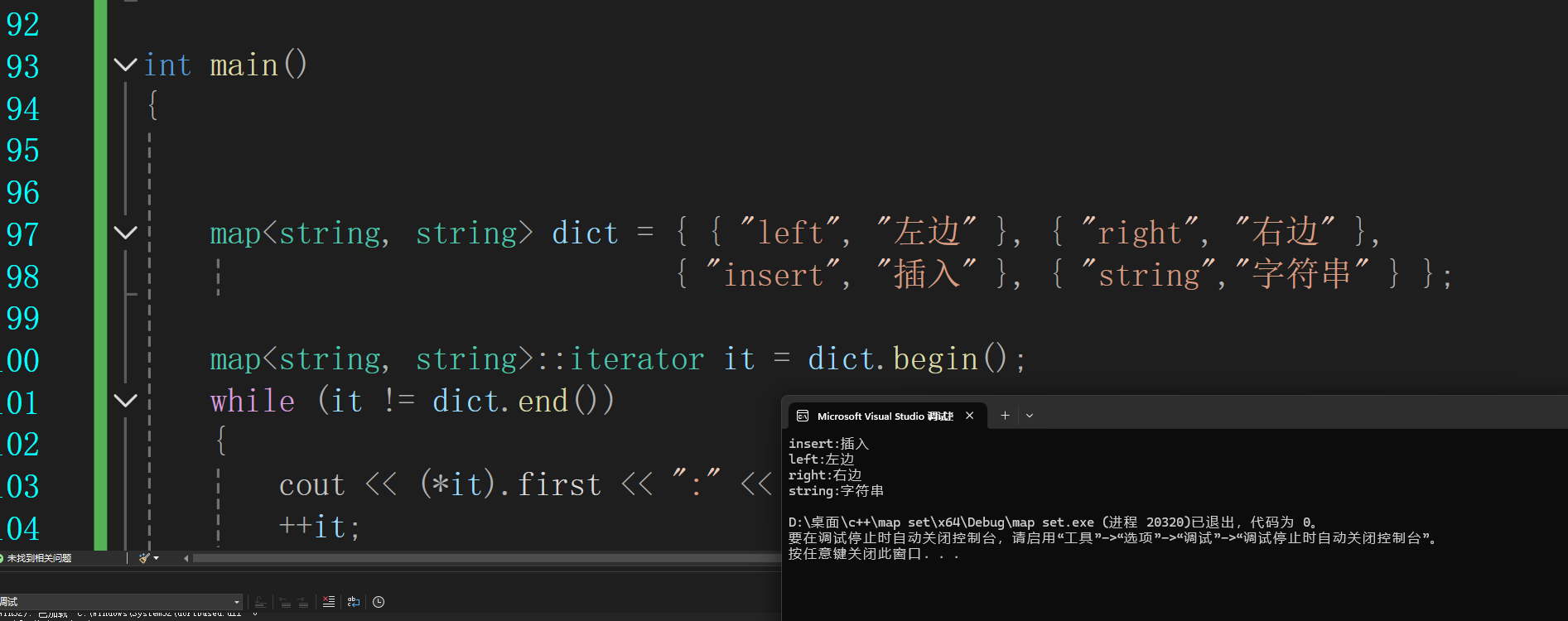
2.遍历
map这种是key/value的怎么去取里面的数据呢?
1.迭代器
如果是按照set的遍历方式这里编译都通过不了的,map是不支持流插入和流提取的

pair是有俩个成员函数的一个first一个second这里需要我们自己去调用
int main()
{
map<string, string> dict = { { "left", "左边" }, { "right", "右边" },
{ "insert", "插入" }, { "string","字符串" } };
map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
cout << (*it).first << ":" << (*it).second << endl;
++it;
}
/*pair<string, string> kv("left", "左边");
dict.insert(kv);
dict.insert(pair<string, string>("right", "右边"));
dict.insert(make_pair("insert", "插入"));
dict.insert({ "string","字符串" });*/
return 0;
}
但是这里插入的和输出的不一样这是因为这里是按asc码比
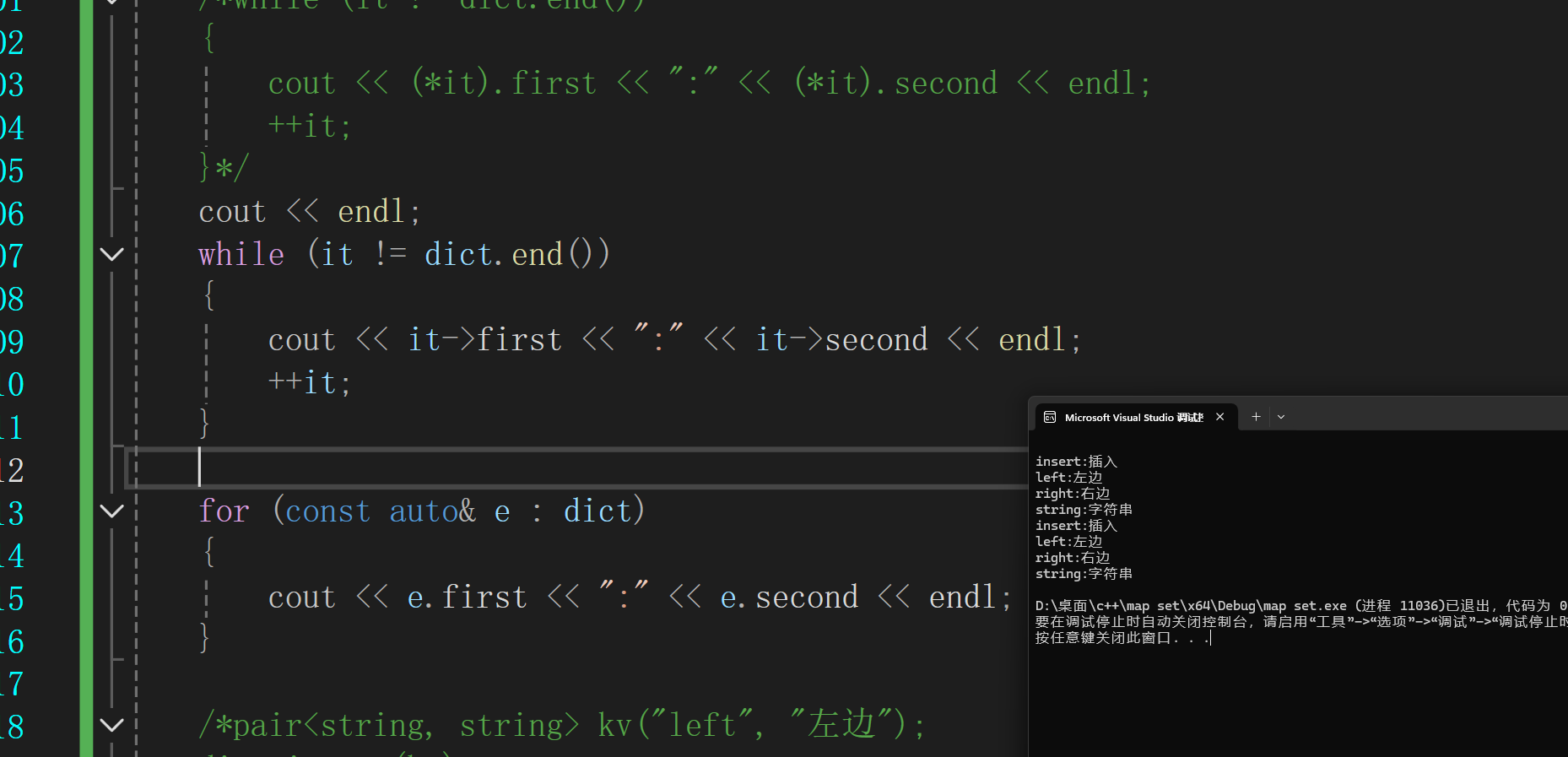
也可以这样,效果是一样的
int main()
{
map<string, string> dict = { { "left", "左边" }, { "right", "右边" },
{ "insert", "插入" }, { "string","字符串" } };
map<string, string>::iterator it = dict.begin();
cout << endl;
while (it != dict.end())
{
cout << it->first << ":" << it->second << endl;
++it;
}
return 0;
}
2.范围for
for (const auto& e : dict)
{
cout << e.first << ":" << e.second << endl;
}
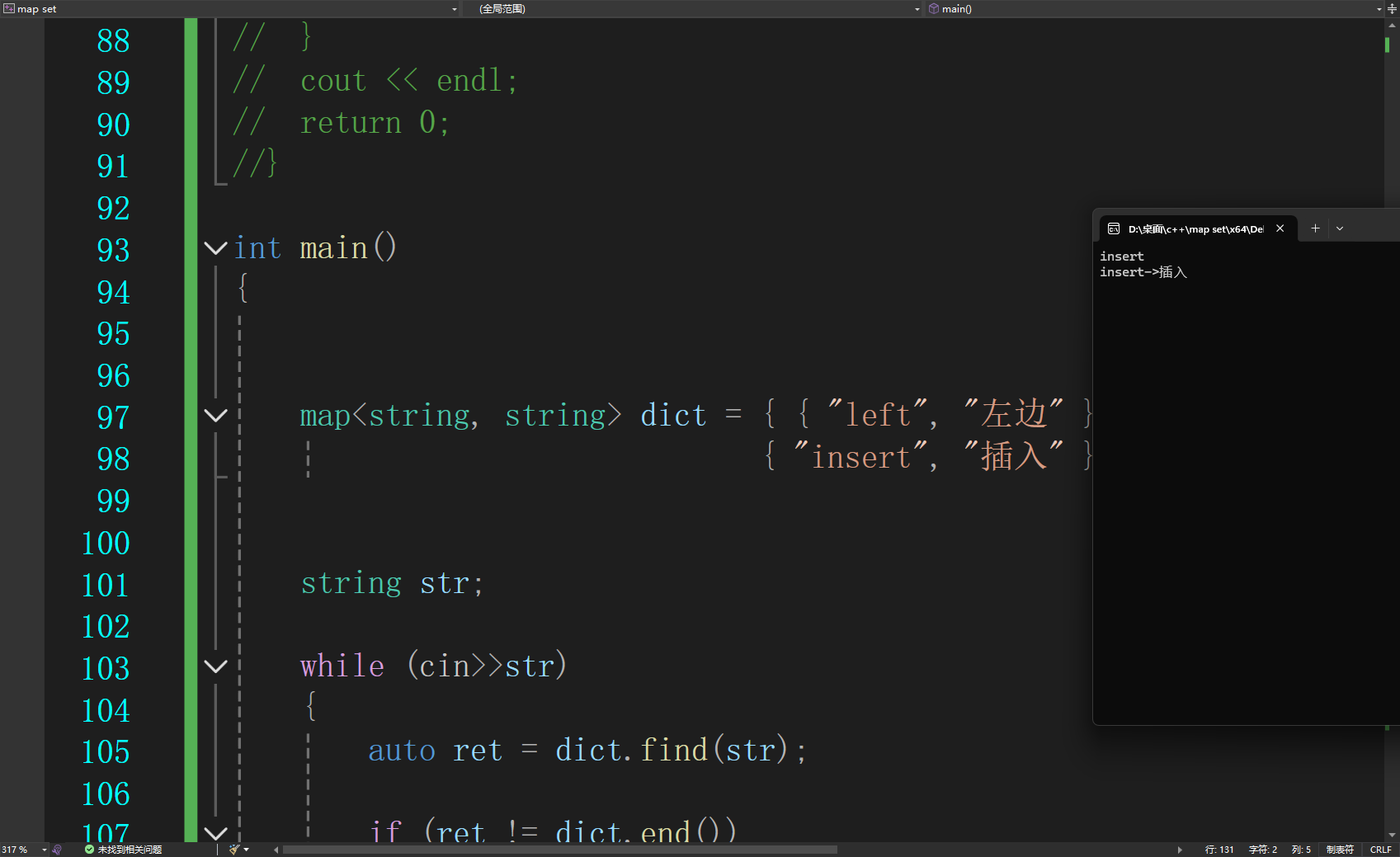
3.一个简单的词典
int main()
{
map<string, string> dict = { { "left", "左边" }, { "right", "右边" },
{ "insert", "插入" }, { "string","字符串" } };
string str;
while (cin>>str)
{
auto ret = dict.find(str);
if (ret != dict.end())
{
cout << str << "->" << ret->second << endl;
}
}
return 0;
}
4.统计次数
int main()
{
//苹果-3
//西瓜-4
//香蕉-2
string arr[] = { "苹果","西瓜","西瓜","西瓜" ,"香蕉","西瓜","香蕉","苹果","苹果" };
map<string, int> countTree;
for (const auto& e : arr)
{
auto ret = countTree.find(e);
if (ret == countTree.end())
{
countTree.insert({ e ,1});
}
else
{
ret->second++;
}
}
for (auto e : countTree)
{
cout << e.first << "->" << e.second << endl;
}
}
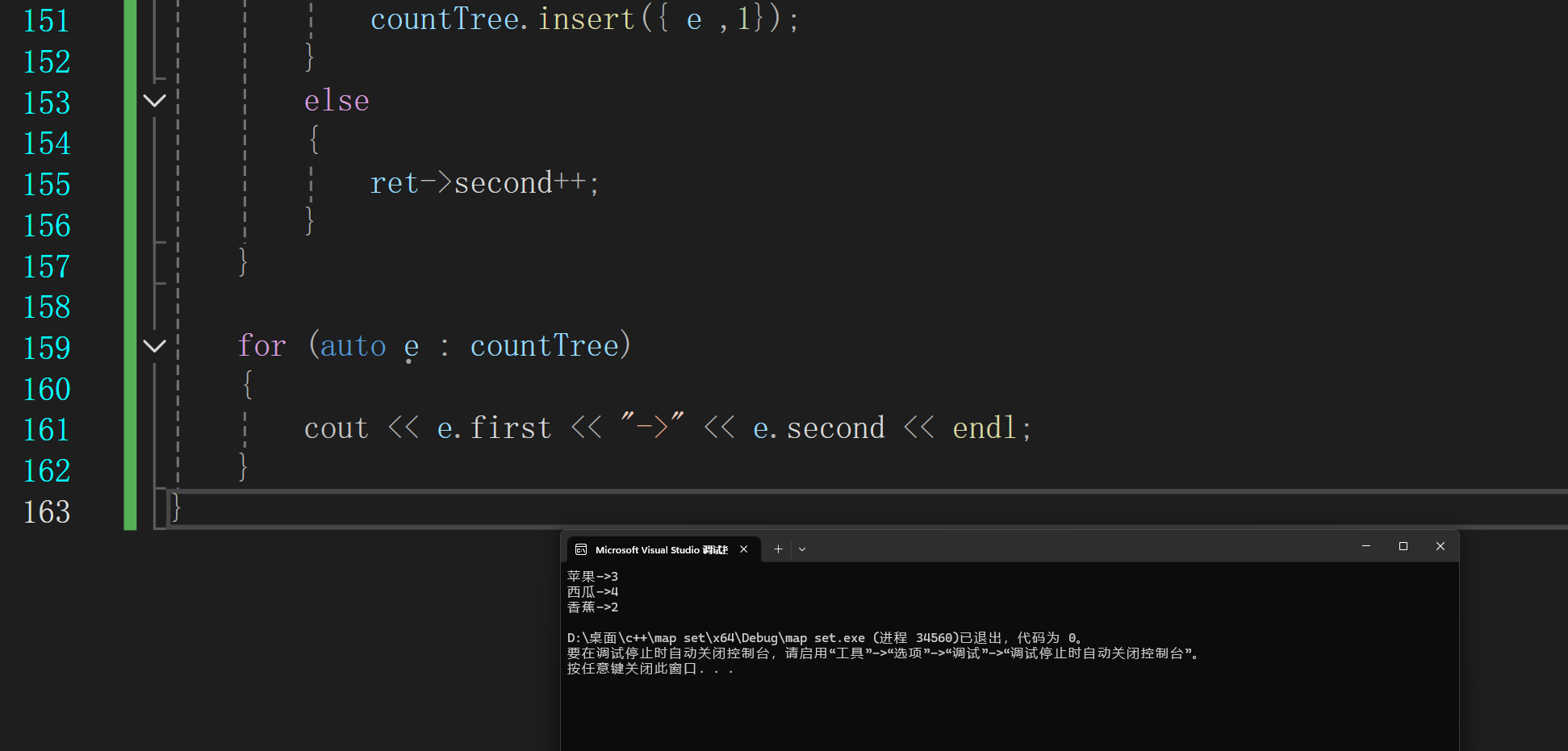
其他成员函数其实都差不多
但是这里还有一个更简单的方法
int main()
{
//苹果-3
//西瓜-4
//香蕉-2
string arr[] = { "苹果","西瓜","西瓜","西瓜" ,"香蕉","西瓜","香蕉","苹果","苹果" };
map<string, int> countTree;
for (auto e : arr)
{
countTree[e]++;
}
for (auto e : countTree)
{
cout << e.first << "->" << e.second << endl;
}
}
五、multimap
multimap和map的区别就是map的key值如果一样那么就不会插入了,但是multi这里不管是key或者是value一样都会插入
六、相关题目
1.随机链表的复制
https://leetcode.cn/problems/copy-list-with-random-pointer/description/
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head)
{
map<Node*,Node*> nodeMap;
Node* copyhead = nullptr,*copytail = nullptr;
Node* cur = head;
while(cur)
{
if(copytail == nullptr)
{
copyhead = copytail = new Node(cur->val);
}
else
{
copytail->next = new Node(cur->val);
copytail = copytail->next;
}
nodeMap[cur] = copytail;
cur = cur->next;
}
cur = head;
Node* copy = copyhead;
while(cur)
{
if(cur->random == nullptr)
{
copy->random =nullptr;
}
else
{
copy->random = nodeMap[cur->random];
}
cur = cur->next;
copy = copy->next;
}
return copyhead;
}
};
2. 环形链表 II
https://leetcode.cn/problems/linked-list-cycle-ii/description/
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode* head)
{
set<ListNode*> s;
ListNode* cur = head;
while(cur)
{
auto ret = s.insert(cur);
if(ret.second == false)
{
return cur;
}
cur = cur->next;
}
return nullptr;
}
};
3.两个数组的交集
https://leetcode.cn/problems/intersection-of-two-arrays/description/
ps:相等的就是交集,小的就是差集,合并去重就是并集
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2)
{
set<int> s1(nums1.begin(),nums1.end());
set<int> s2(nums2.begin(),nums2.end());
vector<int> ret;
auto it1 = s1.begin();
auto it2 = s2.begin();
while(it1 != s1.end() && it2 != s2.end())
{
if(*it1 < *it2)
{
it1++;
}
else if (*it1 > *it2)
{
it2++;
}
else
{
ret.push_back(*it1);
it1++;
it2++;
}
}
return ret;
}
};
4. 前k个高频单词
https://leetcode.cn/problems/top-k-frequent-words/
class Solution {
public:
struct cmp
{
bool operator()(const pair<string,int>& x,const pair<string,int>& y )
{
return x.second > y.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k)
{
map<string,int> countmap;
for(auto e: words)
{
countmap[e]++;
}
vector<pair<string,int>> v(countmap.begin(),countmap.end());
stable_sort(v.begin(),v.end(),cmp());
vector<string> strv;
for(int i=0;i<k;i++)
{
strv.push_back(v[i].first);
}
return strv;
}
};
总结
map 和set 是俩个非常好用的容器,需要多练习,还有一些很好用的技巧,比如map统计次数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









