






Lesson13—模板进阶
C++第13章模板的进阶
文章目录
前言
之前的博客里面有介绍简单的模板,例如为什么模板声明和定义不能分离,这一篇会详细介绍
一、模板的非类型模板参数
假如我现在有一个静态的栈,假如我s1要10大小的,s2
要20大小的这里就没有办法总不可能在写一个,可以发现用宏灵活性是不太好的,这个时候我们就可以引入模板的非类型参数
#pragma once
#define N 10
template<class T>
class Stack
{
private:
T* _arr[N];
int _top;
};
int main()
{
Stack<int> s1;
Stack<int> s2;
return 0;
}
#pragma once
template<class T,size_t N>
class Stack
{
private:
T* _arr[N];
int _top;
};
int main()
{
Stack<int,10> s1;
Stack<int,20> s2;
return 0;
}
这里加入非类型的模板参数就非常完美的解决了这个问题
模板也并不是局限于只能传入类型,它还可以像函数一样传入一个变量进来
#pragma once
template<class T,size_t N=10>
class Stack
{
private:
T* _arr[N];
int _top;
};
int main()
{
Stack<int> s1;
Stack<int,20> s2;
return 0;
}
这里依旧可以传入缺省参数
二、静态数组
了解一下就好比较失败的设计可以直接用vector
数组的检查机制
在c++11 里面增加了array这个类就是用非类型模板参数写的

它的定义可以这样写
#include"test.h"
#include<array>
int main()
{
array<int, 10> arr1;
return 0;
}
那么它对比我们平时写的数组有什么区别呢
#include"test.h"
#include<array>
int main()
{
array<int, 10> arr1;
int arr2[10];
return 0;
}
数组的检查机制它只会检查临近的越界问题
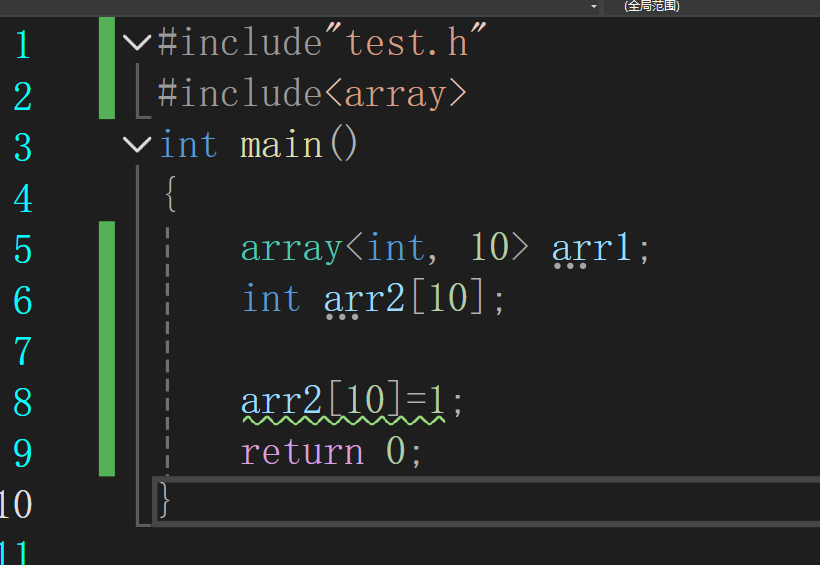
这里10会检查
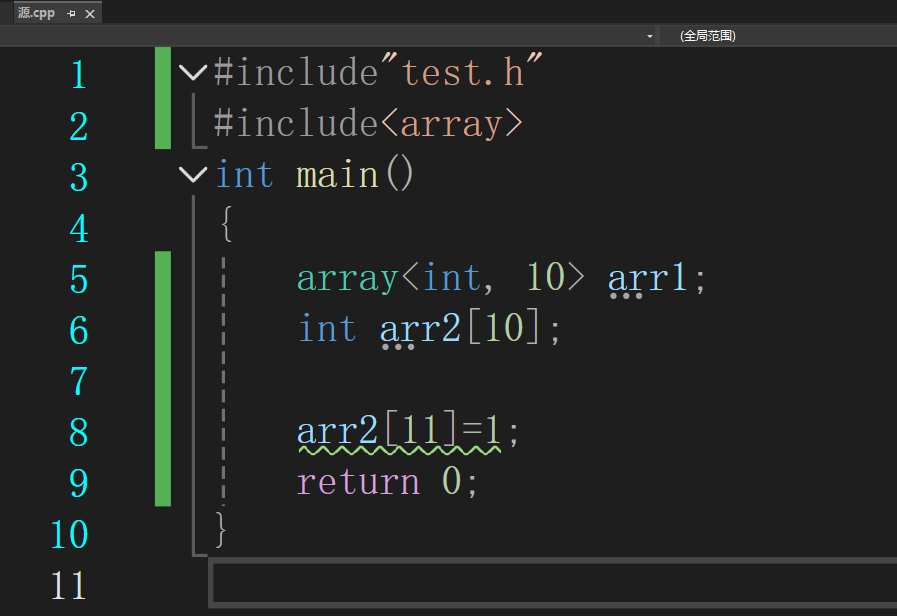
这里11也会检查,但是从12开始就不会在检查了,不同的人编译器不一样

上面就检查不出来了,但有时候越界访问很容易出现问题
甚至可以直接去访问
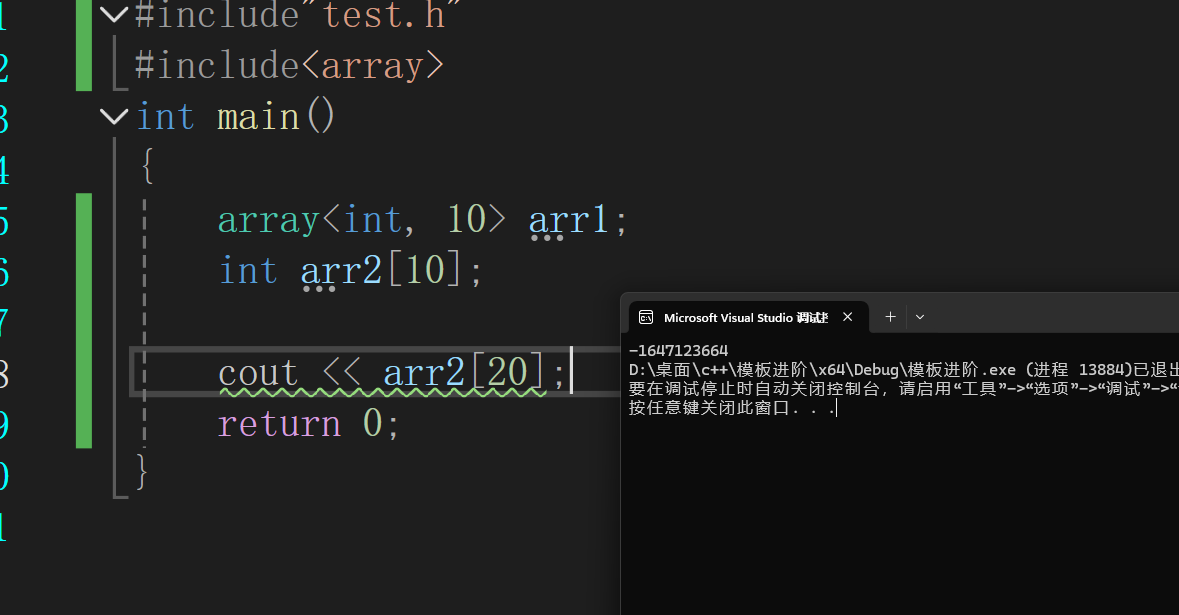
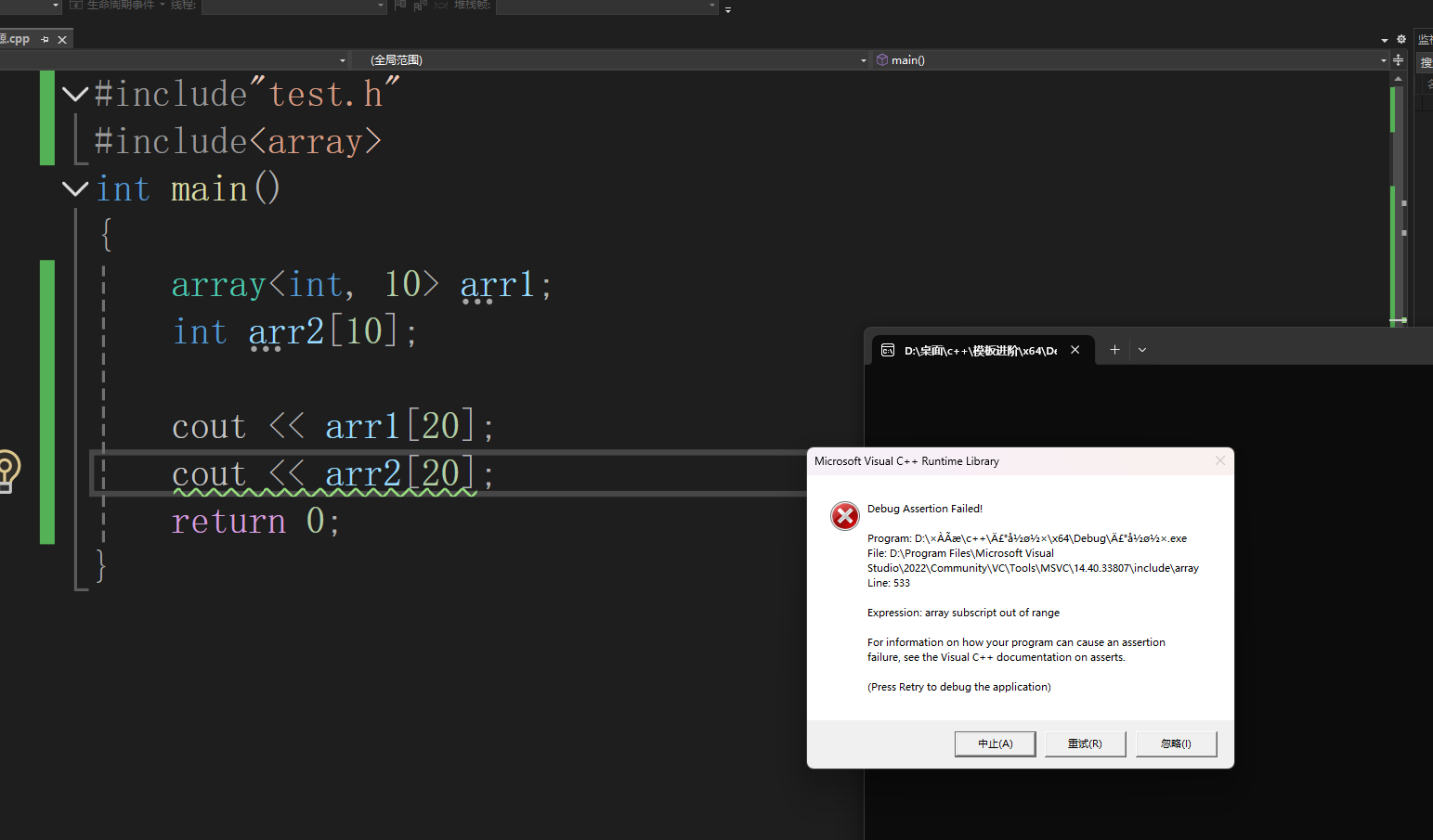
用新的定义方式就可以很好的解决这个问题,它对这些检查就非常的严格,它这里就根本不让读取
三、打印多类型vector
void PrintVector(const vector<int>& v)
{
vector<int>::const_iterator it = v.begin();
while (it != v.end())
{
cout << *it << ' ';
++it;
}
cout << endl;
}
int main()
{
vector<int> v1 = { 1,2,3,4,5 };
vector<double> v2 = { 1.1,2.2,3.3,4.4,5.5 };
PrintVector(v1);
return 0;
}
假如现在我有俩个vector一个int的一个double的这里显然没办法在不改代码的情况下打印俩个不同类型的vector,只要用到了不同类型就必须要用到模板
下面错误的
template<class T>
void PrintVector(const vector<T>& v)
{
vector<T>::const_iterator it = v.begin();
while (it != v.end())
{
cout << *it << ' ';
++it;
}
cout << endl;
}
按照之前写类的时候,正常来说就是这么写但是这里编译器
这里编译器就是报错什么原因呢?而且这个报错根本就看不懂什么意思?
这里先直接说结论
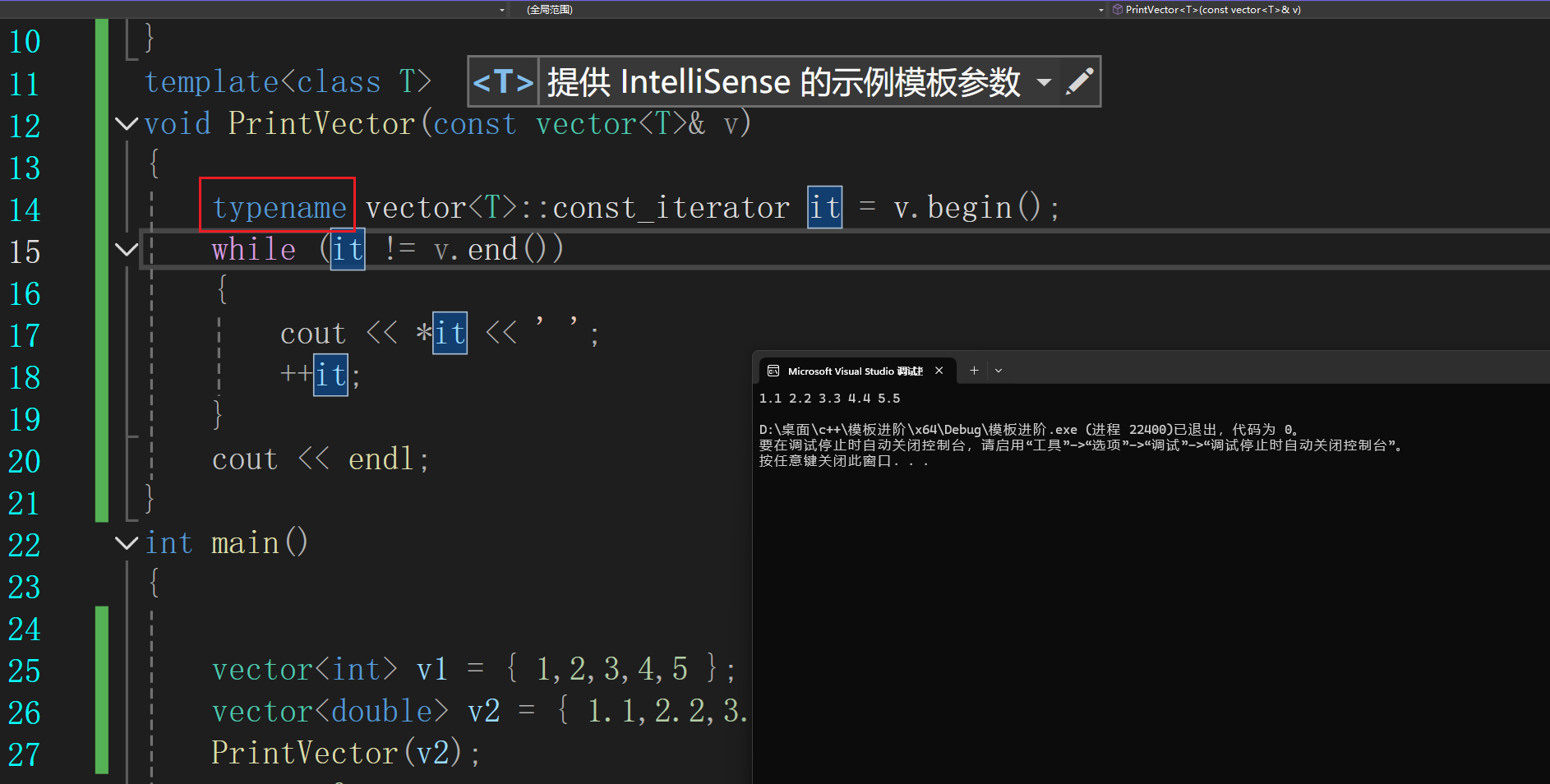
这里加一个typename就可以直接过
原因:编译器是从上到下,当程序执行到了这一行的时候它在之前就看到了有包含vector的头文件,但是编译器并不会很详细的去看看这个头文件下面有什么东西,然后就是模板的一大痛点就是上面的vector模板并没有实例化。
这里加个typename就是告诉编译器等vector实例化以后再去查找
那么知道了原理了以后,就还可以用跟简单的方式
template<class T>
void PrintVector(const vector<T>& v)
{
auto it = v.begin();
while (it != v.end())
{
cout << *it << ' ';
++it;
}
cout << endl;
}
int main()
{
vector<int> v1 = { 1,2,3,4,5 };
vector<double> v2 = { 1.1,2.2,3.3,4.4,5.5 };
PrintVector(v2);
return 0;
}
四、类模板的特化
这样可以对特殊情况的类进行优先特殊处理
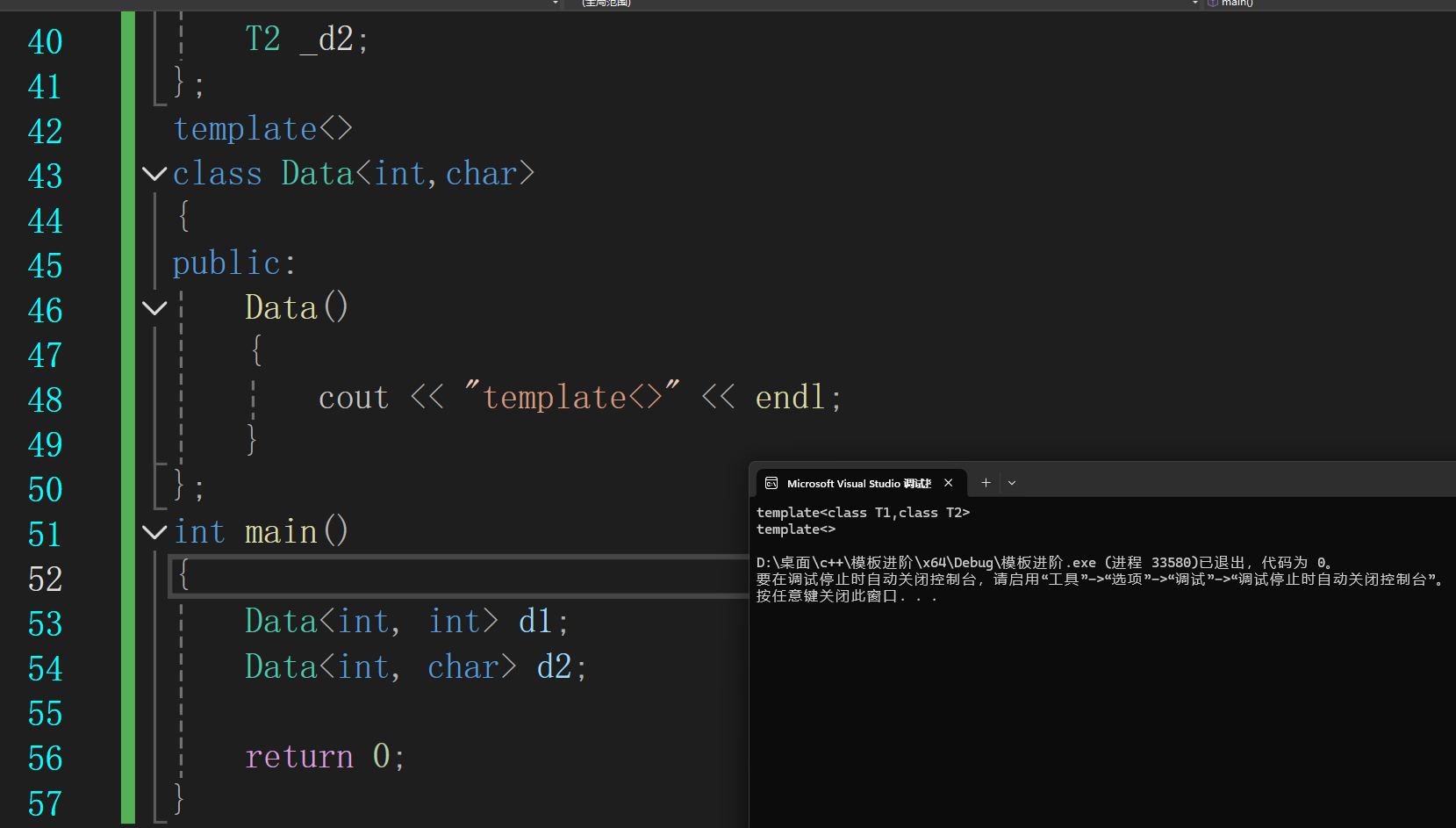
1.全特化
注意看,全特化是没有写成员函数的
template<class T1,class T2>
class Data
{
public:
Data()
{
cout << "template<class T1,class T2>" << endl;
}
private:
T1 _d1;
T2 _d2;
};
template<>
class Data<int,char>
{
public:
Data()
{
cout << "template<>" << endl;
}
};
int main()
{
Data<int, int> d1;
Data<int, char> d2;
return 0;
}
2.半特化(偏特化)
特化部分参数
emplate<class T1>
class Data<T1, int>
{
public:
Data()
{
cout << "template<class T1>-半特化" << endl;
}
};
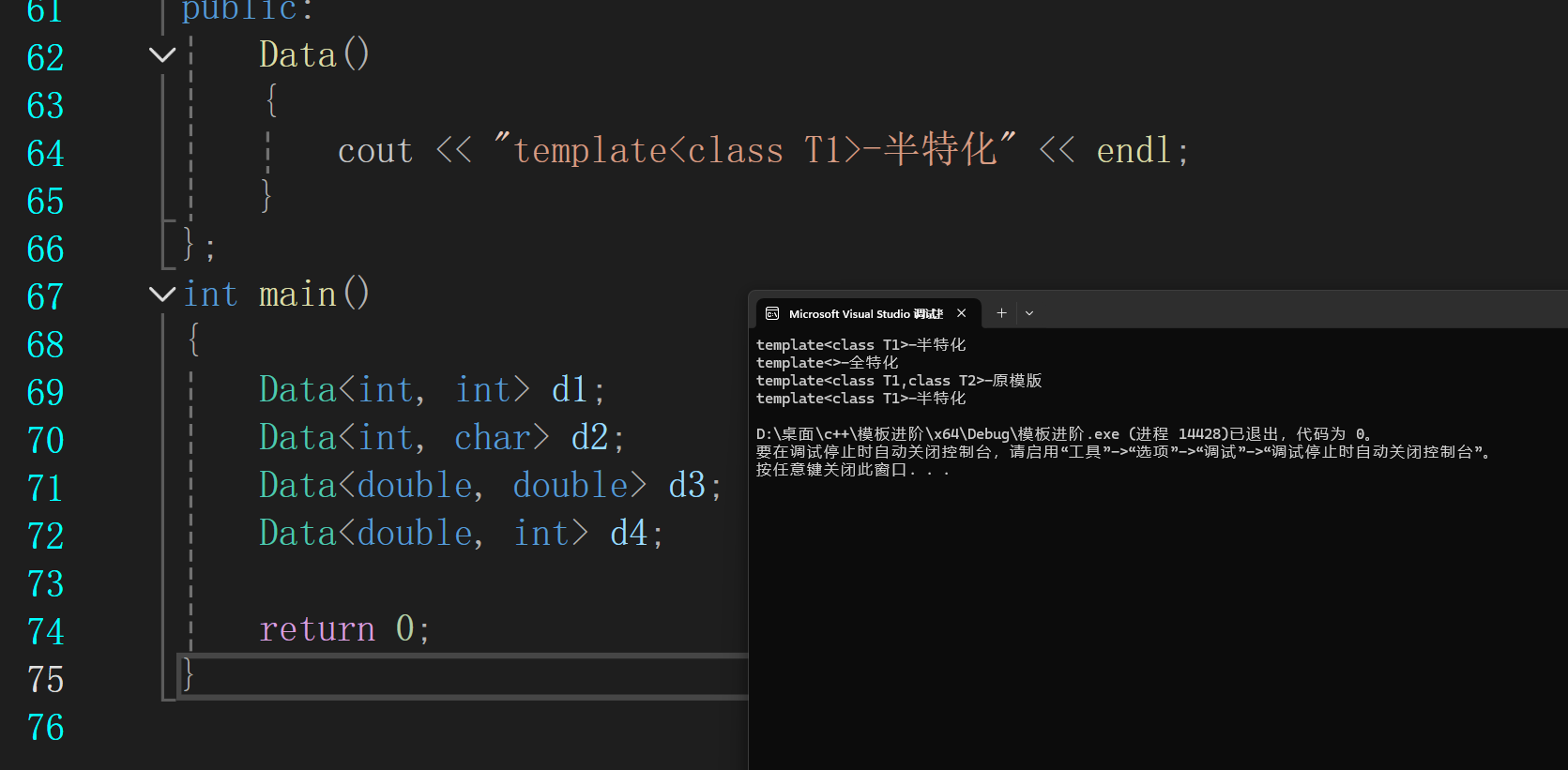
可以看到半特化的优先级是非常的高的
五、模板为什么不支持分离编译
1.什么是分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
2.为什么分离编译会报错
假如现在我分离编译
// .h
#pragma once
#include"bits/stdc++.h"
using namespace std;
template<class T>
T Add(const T& x, const T& y);
//.cpp
#include"test.h"
template<class T>
T Add(const T& x, const T& y)
{
cout << "T Add(const T& x, const T& y)" << endl;
return x + y;
}
void func()
{
cout << "void func()" << endl;
}
#define _CRT_SECURE_NO_WARNINGS
#include"test.h"
using namespace std;
int main()
{
Add(1, 2);
return 0;
}
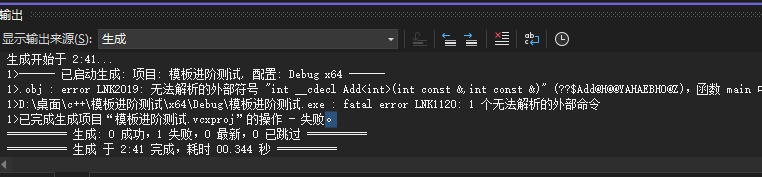
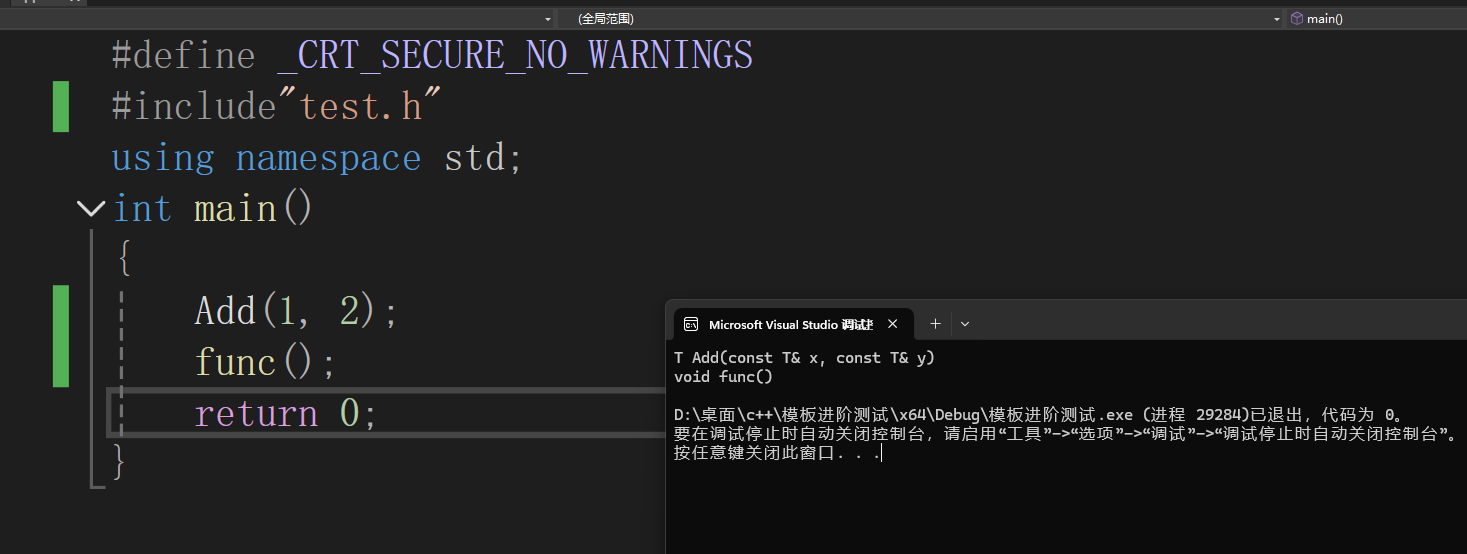
这里编译器报了链接错误
为了测试的严谨性,我这里在假如一个没有用模板的函数
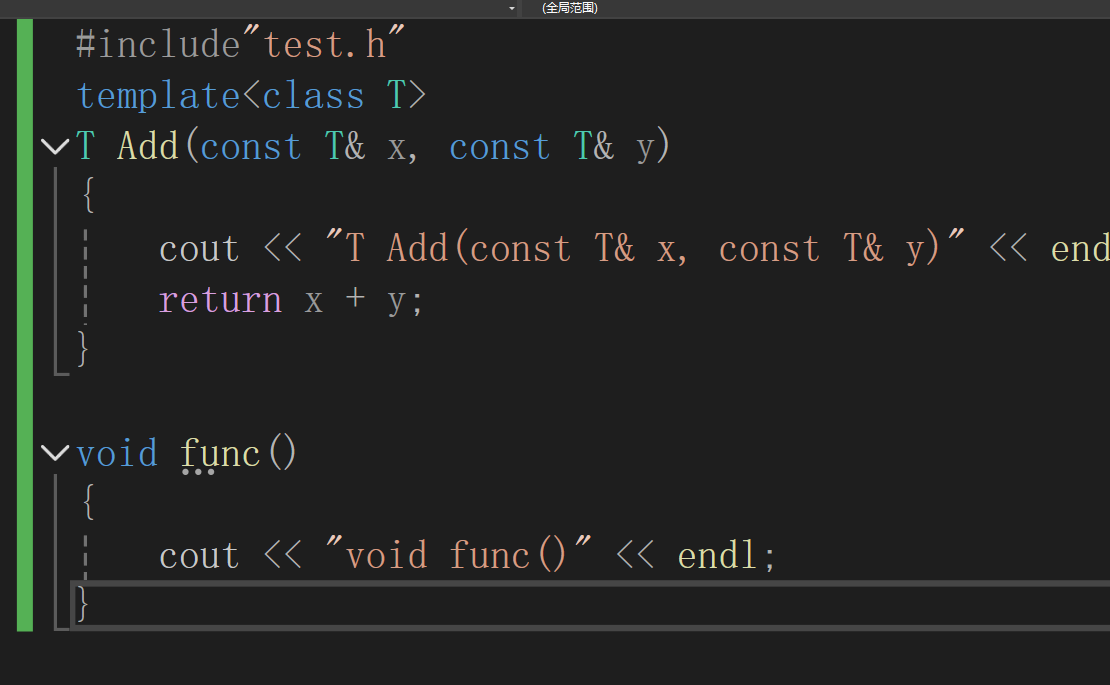
这里的测试结果是可以运行,这里就可以说明是模板的问题,那为什么这里会报错呢?
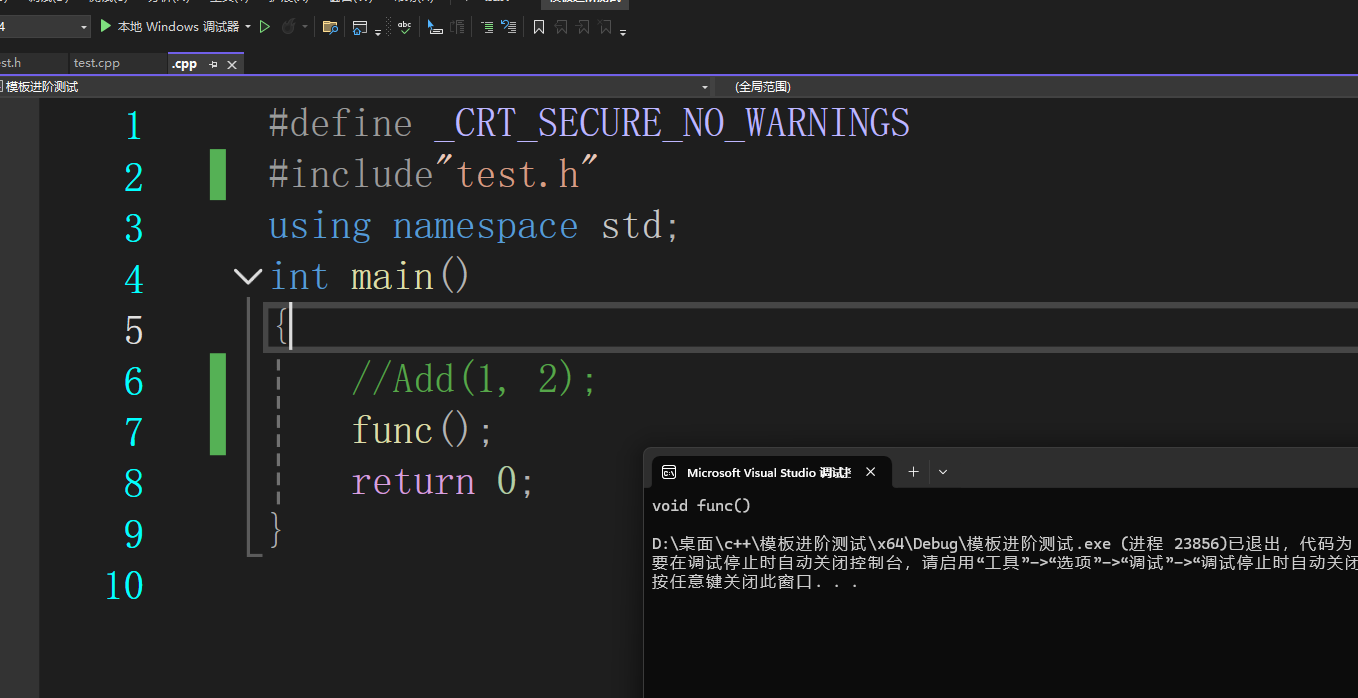
这里查看底层的汇编代码,可以看到这里的汇编调用我们的写的函数都是call一个函数的地址
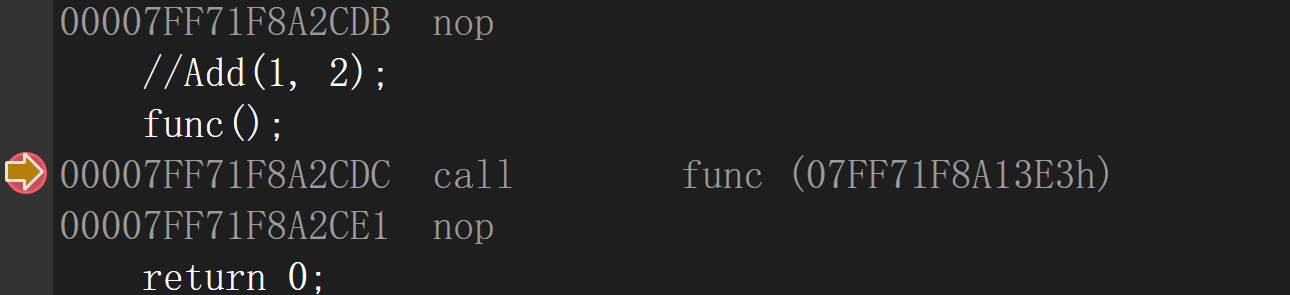
这里可以发现我们在测试文件里面只要包上.h的代码那么为什么只包了头文件的代码就可以直接跑,因为声明会开空间去存放位置,编译器会先把声明拿过来汇总成符号表,然后在按照符号表上的地址再去找这个函数
实际上编译完成以后只会有这俩个文件
这里func找的到是因为在编译以后的文件里面可以找到,但是函数模板是不会生成地址的,也就没有add的函数地址放进符号表,所以链接也就找不到,因为编译器根本就不知道模板被实例化成什么
声明的时候知道被实例化成声明东西了但是声明根本就不知道实例化成什么东西了也就自然没有函数地址了

差不多就是这样
3.解决方法
其实只要看一下其他文件里面的实例化就可以解决这个问题为什么编译器不这么做呢,但是真的项目里面是有几百个文件的这会大大的降低速度,得不偿失
这种不好
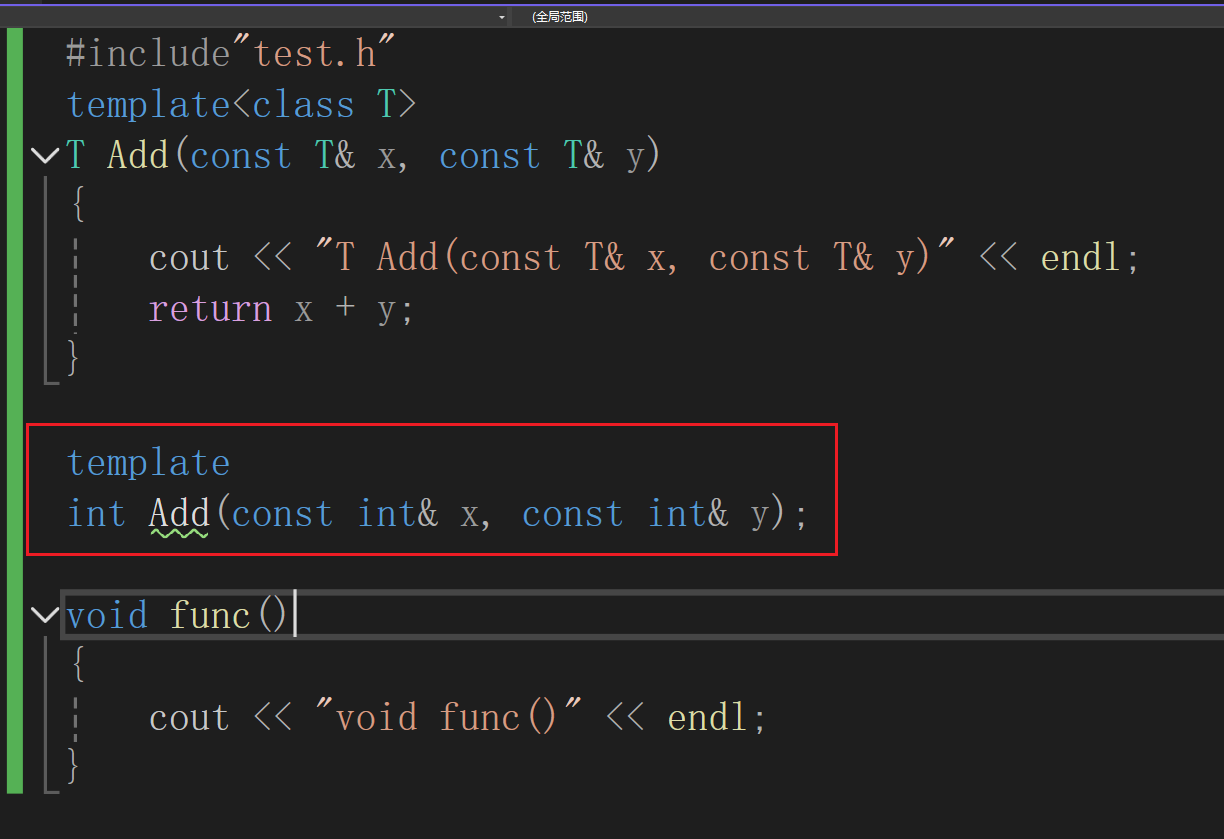
加上显示实例化也许,但是这样做的意义本来就违背模板的初衷,那我为什么不只用函数重载呢,没啥用,而且是一个大坑
最佳解决方式
不要分离到俩个文件可以叫.h也可以叫.hpp
总结
【优点】
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生
- 增强了代码的灵活性
【缺陷】 - 模板会导致代码膨胀问题,也会导致编译时间变长
- 出现模板编译错误时,错误信息非常凌乱,不易定位错误


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









