







 本文介绍使用PyTorch 1.7.1和预训练模型进行目标检测,重点讨论RetinaNet的输入和输出格式。输入格式为[N, C, H, W],输出包括boxes、labels和scores。通过predict()函数处理图像,根据设定阈值筛选预测结果。"
64500801,5720221,非递归遍历二叉树的方法,"['数据结构', '存储', '遍历', '操作系统']
本文介绍使用PyTorch 1.7.1和预训练模型进行目标检测,重点讨论RetinaNet的输入和输出格式。输入格式为[N, C, H, W],输出包括boxes、labels和scores。通过predict()函数处理图像,根据设定阈值筛选预测结果。"
64500801,5720221,非递归遍历二叉树的方法,"['数据结构', '存储', '遍历', '操作系统']
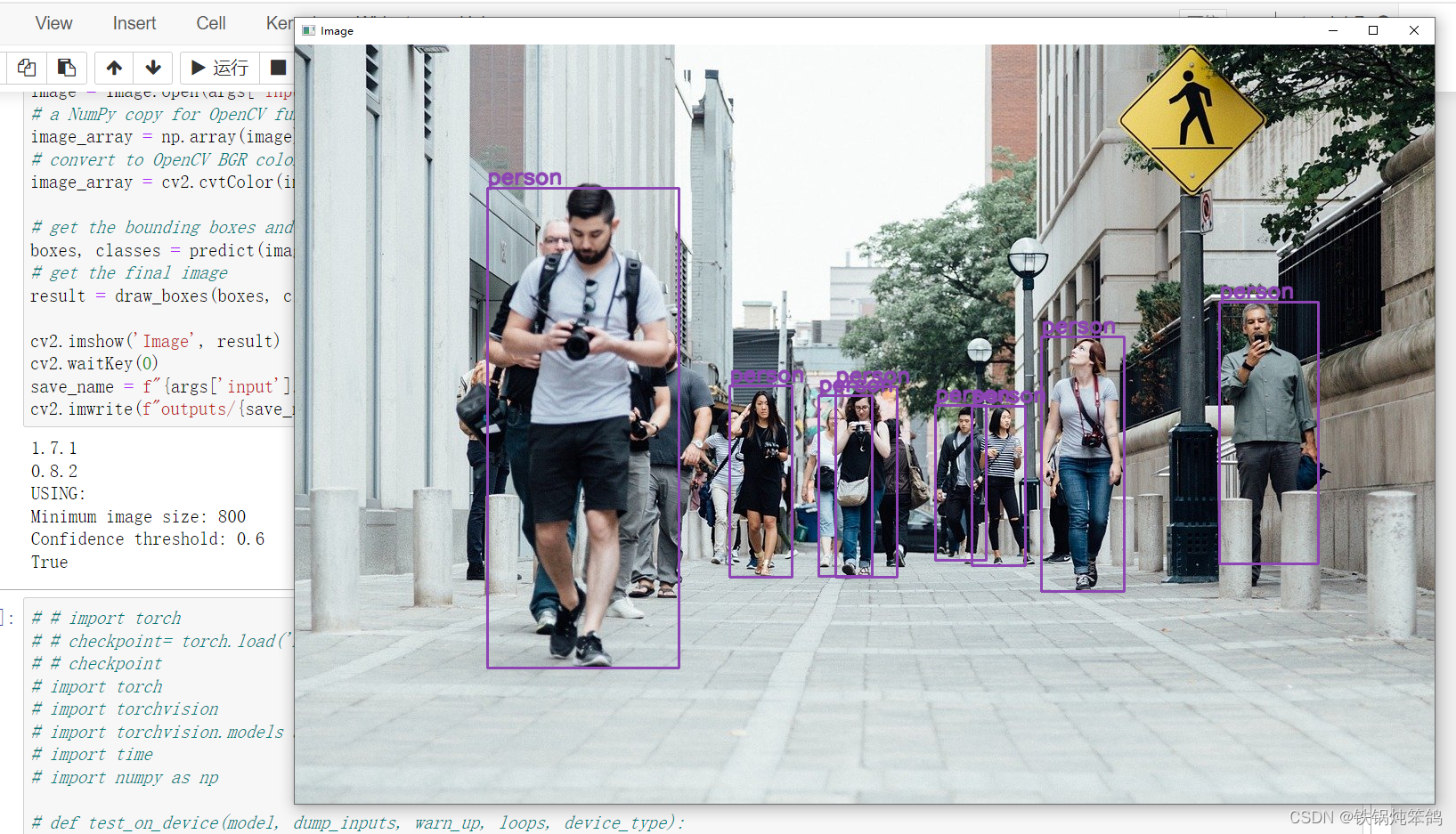
本文使用的是pytorch1.7.1,使用Pytorch提供的预训练模型,使用这个预训练模型,我们可以检测COCO数据集中超过80种物体。
RetinaNet的输入格式
输入图像的格式为[C, H, W],即(channels, height, and width),我们也需要提供一个batch size。batch size指一次处理多少张图像。所以输入图像格式为[N, C, H, W]。同时,图像的像素值要在0-1之间。
RetinaNet的输出格式
它输出一个列表包括一个字典,其包含结果张量。格式为List[Dict[Tensor]]。这个Dict包括以下keys:
boxes (FloatTensor[N, 4]):被预测的boxes是[x1, y1, x2, y2]格式
labels (Int64Tensor[N]):每个图片的预测标签
scores:(Tensor[N]):每个预测的得分

coco_names.py
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis',  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2013
2013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









