






摘要:物理人工智能系统需要在物理世界中感知、理解并执行复杂动作。在本文中,我们介绍了Cosmos-Reason1模型,该模型能够通过长链思维推理过程理解物理世界,并以自然语言生成适当的具身决策(例如,下一步动作)。我们首先定义了物理人工智能推理的关键能力,重点聚焦于物理常识和具身推理。为了表示物理常识,我们采用了一种层次化本体论,它捕捉了关于空间、时间和物理学的基本知识。对于具身推理,我们依赖于一种二维本体论,该本体论能够跨不同的物理具身进行泛化。基于这些能力,我们开发了两个多模态大型语言模型,即Cosmos-Reason1-8B和Cosmos-Reason1-56B。我们通过四个阶段来整理数据和训练模型:视觉预训练、通用监督微调(SFT)、物理人工智能SFT以及物理人工智能强化学习(RL)作为后训练。为了评估我们的模型,我们根据本体论构建了物理常识和具身推理的全面基准。评估结果显示,物理人工智能SFT和强化学习带来了显著的提升。为了促进物理人工智能的发展,我们将在NVIDIA开放模型许可证下,通过https://github.com/nvidia-cosmos/cosmos-reason1提供我们的代码和预训练模型。Huggingface链接:Paper page,论文链接:2503.15558
研究背景
随着人工智能技术的不断进步,特别是在自然语言处理和计算机视觉领域的突破,开发能够理解物理世界并进行具身推理的物理人工智能(Physical AI)系统已成为一个重要的研究方向。传统的AI系统,尤其是基于大规模文本数据训练的大型语言模型(LLMs),虽然在编码、数学和一般知识问答等任务上展现出了强大的能力,但在理解和交互物理世界方面仍显不足。物理AI系统需要不仅能够处理文本和视觉信息,还需要能够将这些信息与物理常识和具身推理相结合,以在物理世界中执行复杂任务。
物理常识是物理AI系统的基础,它涉及对空间、时间和物理学基本知识的理解。这些知识对于预测物理世界中可能发生的事情至关重要。而具身推理则要求AI系统能够根据自身的物理形态(如机器人手臂、自动驾驶汽车等)和环境条件,进行感知、规划和执行动作。然而,现有的AI系统往往缺乏这些能力,导致它们在处理与物理世界直接相关的任务时表现不佳。
因此,开发能够理解和推理物理世界的AI系统,对于推动人工智能技术在机器人、自动驾驶、智能家居等领域的应用具有重要意义。这不仅需要改进现有的AI模型,还需要构建新的数据集和基准测试,以全面评估这些模型在物理世界中的表现。
研究目的
本文的研究目的是开发一种能够从物理常识到具身推理的物理AI系统。具体来说,我们旨在通过构建多模态大型语言模型,使AI系统能够理解和推理物理世界,并根据自身的物理形态和环境条件生成适当的具身决策。为了实现这一目标,我们进行了以下工作:
- 定义物理AI推理的关键能力:我们重点关注物理常识和具身推理两种能力,并构建了相应的本体论来表示这些能力。
- 开发多模态大型语言模型:我们开发了两个多模态大型语言模型,即Cosmos-Reason1-8B和Cosmos-Reason1-56B,这些模型能够处理文本和视觉信息,并进行物理AI推理。
- 构建数据集和基准测试:我们整理了大规模的数据集,并构建了物理常识和具身推理的基准测试,以全面评估我们的模型在这些任务上的表现。
- 改进模型训练方法:我们通过视觉预训练、通用监督微调(SFT)、物理AI SFT和物理AI强化学习(RL)等阶段来训练我们的模型,以提高它们在物理世界中的表现。
- 推动物理AI系统的发展:我们将我们的代码和预训练模型开源,以促进物理AI系统的发展和研究。
研究方法
模型架构
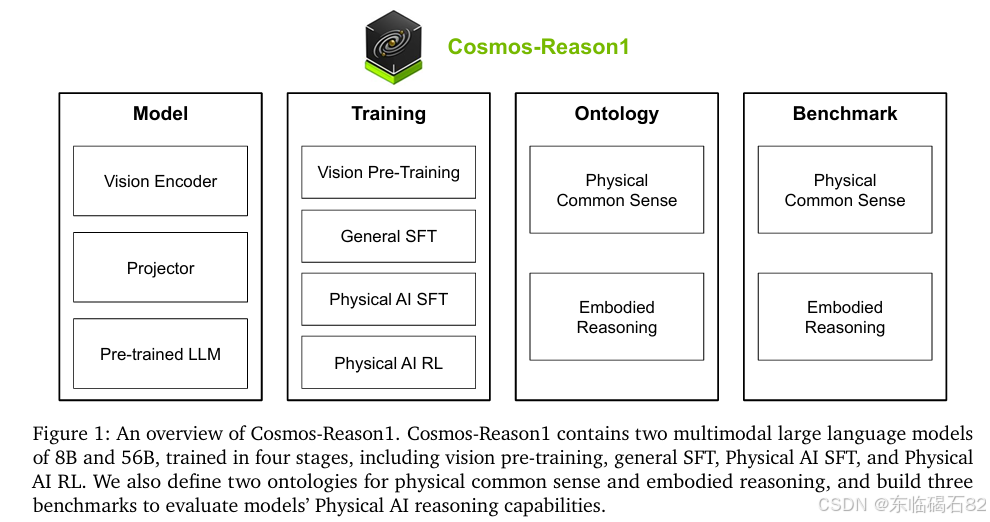
我们采用了解码器-编码器架构来构建我们的多模态大型语言模型。该架构包括一个视觉编码器,用于将图像或视频转换为文本令牌嵌入空间中的视觉令牌;一个投影仪,用于对齐视觉令牌和文本令牌;以及一个解码器-仅大型语言模型(LLM)骨干网络,用于生成自然语言响应。
我们选择了InternViT-300M-V2.5作为视觉编码器,并采用了混合Mamba-MLP-Transformer架构作为LLM骨干网络。这种架构结合了Mamba架构的线性时间序列建模能力和Transformer架构的长上下文建模能力,能够高效地处理长序列数据。
数据整理与训练
为了训练我们的模型,我们整理了大规模的数据集,并进行了四个阶段的训练:
- 视觉预训练:在视觉预训练阶段,我们保持LLM骨干网络和视觉编码器冻结,并仅训练投影仪。我们使用了一个包含1.3亿个样本的多样化图像-文本预训练数据集,以对齐视觉和文本模态。
- 通用监督微调(SFT):在通用监督微调阶段,我们训练视觉编码器、投影仪和LLM骨干网络,以在各种任务导向的监督微调数据上建立核心能力。我们使用了一个包含600万个图像-文本样本和200万个视频-文本样本的通用SFT数据集。
- 物理AI监督微调(SFT):在物理AI监督微调阶段,我们针对物理AI特定数据对模型进行微调,以增强模型在物理常识和具身推理方面的能力。我们开发了一个专门的管道来仔细整理物理AI SFT数据,包括物理常识和视频问答(VQA)数据集,以及具身推理数据集。
- 物理AI强化学习(RL):在物理AI强化学习阶段,我们使用规则基、可验证的奖励对模型进行后训练,以进一步提高模型在物理常识和具身推理方面的能力。我们构建了一个自定义的RL框架,并采用了GRPO算法来优化模型。
基准测试
为了评估我们的模型,我们根据定义的本体论构建了物理常识和具身推理的全面基准测试。这些基准测试包括多个类别的问题,涵盖了空间、时间和物理学基本知识等方面。我们通过手动策划和自动生成的方式整理了这些问题,并确保了基准测试的质量和多样性。
研究结果
物理常识推理
在物理常识推理基准测试上,我们的模型表现出了显著的性能提升。特别是在大规模数据集上进行物理AI SFT和RL后,我们的模型在物理常识推理任务上的准确率得到了大幅提升。这表明我们的方法能够有效地增强模型在物理常识方面的能力。
具身推理
在具身推理基准测试上,我们的模型同样表现出了优异的性能。特别是在处理与机器人手臂、自动驾驶汽车等物理具身相关的任务时,我们的模型能够准确地预测下一步动作,并生成合理的解释和推理过程。这表明我们的模型在具身推理方面具有很强的能力。
强化学习的效果
我们的实验还表明,强化学习在进一步提高模型性能方面发挥了重要作用。通过在物理AI RL阶段使用规则基、可验证的奖励对模型进行后训练,我们能够进一步提升模型在物理常识和具身推理任务上的表现。
研究局限
尽管我们的研究在物理AI系统方面取得了显著的进展,但仍存在一些局限性:
- 数据集的局限性:尽管我们整理了大规模的数据集来训练我们的模型,但这些数据集可能仍然无法完全覆盖物理世界的复杂性和多样性。因此,在未来的研究中,我们需要进一步扩展和丰富数据集,以提高模型的泛化能力。
- 模型的局限性:尽管我们的模型在物理常识和具身推理方面表现出了强大的能力,但它们仍然可能无法处理某些极端或罕见的情况。此外,我们的模型在处理长序列和复杂场景时可能仍然存在一定的挑战。
- 计算资源的局限性:训练大型多模态语言模型需要大量的计算资源。尽管我们采用了高效的模型架构和训练方法,但在未来的研究中,我们仍然需要进一步优化算法和硬件资源,以降低训练成本并提高训练效率。
未来研究方向
为了推动物理AI系统的进一步发展,我们需要从以下几个方面进行深入研究:
- 扩展数据集:进一步扩展和丰富数据集,以涵盖更多物理世界的复杂性和多样性。这将有助于提高模型的泛化能力和鲁棒性。
- 改进模型架构:探索更高效、更强大的模型架构,以处理长序列和复杂场景。这将有助于提高模型的性能和可扩展性。
- 优化训练方法:研究更有效的训练方法,以降低训练成本并提高训练效率。这将有助于推动物理AI系统的实际应用和部署。
- 跨领域融合:探索物理AI系统与其他领域的融合应用,如机器人技术、自动驾驶、智能家居等。这将有助于推动人工智能技术的全面发展和应用落地。
总之,我们的研究为开发能够理解物理世界并进行具身推理的物理AI系统提供了重要的思路和方法。通过不断的研究和探索,我们有望在未来实现更加智能、更加自主的物理AI系统。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









