






摘要:近年来,大型语言模型(LLMs)取得了显著进展,展现出了强大的通用推理能力,然而它们在金融推理方面的有效性仍有待深入探索。在本研究中,我们全面评估了16款功能强大的推理型和通用型大型语言模型在三项复杂金融任务上的表现,这些任务涉及金融文本、表格数据和方程式,评估内容涵盖数值推理、表格解读、金融术语理解、长上下文处理以及基于方程式的问题解决。研究结果显示,虽然更优质的数据集和预训练能够提升金融推理能力,但像思维链(Chain of Thought, CoT)微调这样的通用增强方法并不总是能带来一致的性能提升。此外,所有推理策略在提高长上下文和多表任务性能方面都面临挑战。为了克服这些局限,我们基于Llama-3.1-8B-Instruct开发了一款金融推理增强模型,通过思维链微调和结合领域特定推理路径的强化学习进行训练。即使仅使用一个金融数据集进行简单微调,我们的模型也在各项任务上实现了平均10%的一致性能提升,超越了所有80亿参数(8B)模型,甚至在平均性能上超过了Llama3-70B-Instruct和Llama3.1-70B-Instruct。我们的研究结果强调了金融任务中领域特定适配的必要性,并为未来的研究方向提供了指引,如多表推理、长上下文处理以及金融术语理解。我们所有的数据集、模型和代码均已公开可用。此外,我们还推出了一个排行榜,用于对未来数据集和模型进行基准测试。Huggingface链接:Paper page论文链接:2502.08127
1. 引言
1.1 研究背景
近年来,大型语言模型(LLMs)在自然语言处理领域取得了显著进展,展现出了强大的通用推理能力。然而,尽管这些模型在一般任务中表现出色,但它们在金融推理方面的有效性仍有待深入探索。金融任务因其对数值计算、金融术语理解、法规遵守和经济原则掌握的严格要求,而具有高度的专业性和复杂性。因此,评估LLMs在金融领域的推理能力,对于填补通用AI推理与金融应用之间的鸿沟具有重要意义。
1.2 研究目的
本研究旨在全面评估现有强大的推理型和通用型LLMs在金融任务中的表现,深入分析它们在金融推理方面的优势和局限性,并为未来的金融AI研究提供有价值的见解。
2. 方法
2.1 数据集
为了全面评估LLMs在金融任务中的性能,本研究选用了三个具有不同属性的数据集:
- FinQA:一个大规模数据集,专注于金融领域的数值推理。它包含专家标注的问答对,涉及复杂的数值推理,要求整合结构化数据(如表格)和非结构化数据(如文本描述)。
- DocMath(simplong):一个综合性基准数据集,旨在评估LLMs在数值推理方面的能力,特别关注长文本和表格。其中的simplong子集专门用于评估LLMs在处理包含多个和多层表格的长金融或专业文档时的数值推理能力。
- XBRL-Math:一个旨在评估LLMs在XBRL(可扩展商业报告语言)文件上下文中数值推理能力的数据集。XBRL文件使用标准化的分类法编码财务数据,确保监管申报的一致性和互操作性。该数据集包含结构化财务文档、US GAAP XBRL标签、方程式和多层数值关系。
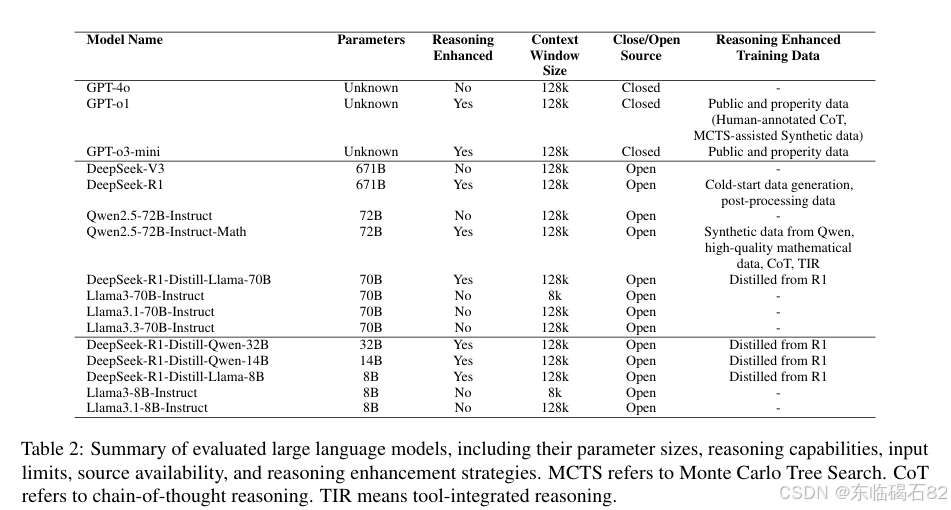
2.2 评估模型
本研究选择了来自GPT、LLaMA、DeepSeek和Qwen家族的多种模型进行评估,这些模型在自然语言处理任务中表现出色。评估模型包括从小规模(80亿参数)到大规模(700亿参数)的多种模型,以及最先进的闭源模型,如GPT-4o和GPT-o1。
2.3 评估设置
在每个数据集中,LLMs被要求基于提供的金融报告、表格、方程式和数学符号等上下文来回答问题。为了评估模型性能,本研究采用了一种基于LLM的评估方法,即首先使用LLM(如GPT-3.5-Turbo)从模型输出中提取最终答案,然后通过数学比较方法确定答案是否正确。
3. 结果与分析
3.1 整体结果分析
研究结果显示,虽然增强推理能力的模型(如DeepSeek-R1)在某些数据集上表现出色,但并非所有增强方法都能在金融任务中带来一致的性能提升。具体来说:
- 通用推理增强方法的有效性:像CoT微调这样的通用增强方法并不总是能提升金融推理性能。例如,GPT-o1在金融任务上的表现甚至不如一些通用模型(如GPT-4o)。
- 数据集和预训练的影响:更优质的数据集和预训练能够提升金融推理能力,但模型性能在金融任务中往往趋于稳定,即使增加模型规模也不一定能带来显著提升。
- 不同推理策略的效果:不同推理策略在金融任务中的效果差异显著。例如,DeepSeek和Qwen-Math通过工具集成推理(TIR)和过程奖励模型(PRM)等方法提升了数值准确性,但在金融术语理解和长上下文建模方面仍有限制。
3.2 具体模型表现
- DeepSeek-R1:在所有评估模型中,DeepSeek-R1在整体性能上排名前列,这得益于其在XBRL-Math数据集上的出色表现。然而,该模型在金融术语理解和长上下文处理方面仍有待提升。
- GPT系列模型:GPT-4o在多个数据集上表现出色,证明了其强大的通用推理能力。然而,GPT-o1在金融任务上的表现相对一般,表明其推理策略在金融领域可能并不完全适用。
- Fino1模型:本研究基于Llama-3.1-8B-Instruct开发了一款金融推理增强模型(Fino1),通过CoT微调和结合领域特定推理路径的强化学习进行训练。实验结果显示,Fino1在各项任务上实现了平均10%的性能提升,超越了所有80亿参数模型,甚至在平均性能上超过了部分更大规模的模型。
3.3 错误分析
为了深入了解推理增强模型在金融任务中表现不佳的原因,本研究对FinQA数据集上的错误案例进行了深入分析。分析发现,DeepSeek-R1等模型在金融任务中常犯的错误包括过度推理和缺乏金融敏感性。例如,在某些情况下,模型会提供过多的细节而忽略了问题中的直接指令;或者,模型无法正确识别金融术语和概念,导致给出错误的答案。
4. 讨论
4.1 金融推理的独特性
金融推理与一般推理任务存在显著差异。它不仅要求模型具备强大的逻辑推理能力,还需要深入理解金融术语、法规和经济原则。因此,简单的通用推理增强方法可能无法有效提升金融推理性能。
4.2 领域特定适配的必要性
本研究结果表明,领域特定适配对于提升金融推理性能至关重要。通过结合金融领域的特定知识和数据,可以显著增强模型在金融任务中的表现。
4.3 未来研究方向
基于本研究的结果和分析,未来的研究可以关注以下几个方面:
- 增强金融知识适应:探索如何将金融领域的特定知识融入LLMs中,以提升其在金融任务中的表现。
- 改进多表推理和长上下文处理能力:开发更有效的推理策略来应对长金融文本和多表格数据的挑战。
- 优化推理增强策略:针对金融任务的独特性,设计更加精准的推理增强策略,以提升模型的金融推理能力。
5. 结论
本研究全面评估了16款强大的推理型和通用型LLMs在金融任务中的表现,并深入分析了它们在金融推理方面的优势和局限性。研究结果表明,虽然增强推理能力的模型在一般任务中表现出色,但并非所有增强方法都能有效提升金融推理性能。通过开发针对金融领域的特定适配模型(如Fino1),可以显著提升LLMs在金融任务中的表现。未来研究应关注金融知识的融入、多表推理和长上下文处理能力的提升以及推理增强策略的优化等方面。同时,本研究所公开的数据集、模型和代码将为未来的金融AI研究提供有力支持。
6. 研究限制与未来工作
6.1 研究限制
- 模型规模限制:本研究仅微调了一个80亿参数的模型(Fino1),更大规模的模型可能从推理增强中受益更多。
- 评估范围限制:本研究仅评估了三个金融推理任务,未能全面覆盖金融NLP应用的广泛领域。
- 数据集限制:Fino1模型的微调依赖于单个数据集(FinQA),限制了模型对不同金融推理模式的暴露。
- 推理路径构建方法限制:本研究采用了单一的推理路径构建方法(基于GPT-4o),探索多种方法可能进一步提升模型性能。
6.2 未来工作
未来的工作可以关注以下几个方面:
- 扩展模型规模:微调更大规模的模型以评估其在金融推理任务中的表现。
- 扩大评估范围:评估LLMs在更多金融NLP任务上的表现,如财务预测、金融情感分析和欺诈检测等。
- 融合多个数据集:使用多个金融数据集来微调模型,以提升其对不同金融推理模式的泛化能力。
- 探索多种推理路径构建方法:结合多种推理路径构建方法(如集成方法或人工标注路径)来进一步提升模型的金融推理能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









