







1. Recurrent Neural Network 介绍
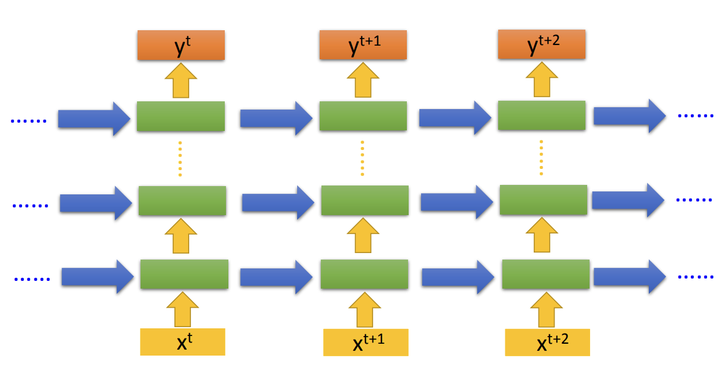
1.1 Recurrent Neural Network (RNN)
RNN是一种适合处理序列数据的神经网络,可以通过隐藏层状态保存序列信息。它通过循环结构更新隐藏状态,捕获时间序列的依赖关系。
其中:
-
:当前时间步隐藏状态
-
:上一时间步隐藏状态
-
:当前输入
-
:权重和偏置
-
:激活函数(如tanh或ReLU)
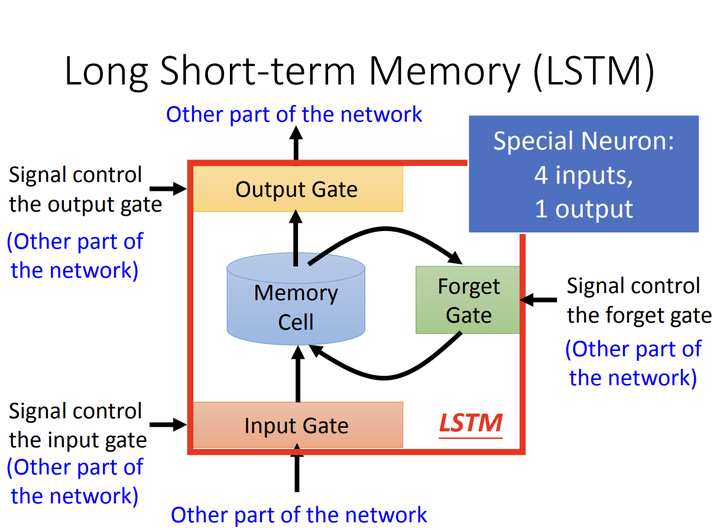
1.2 Long Short-Term Memory (LSTM)
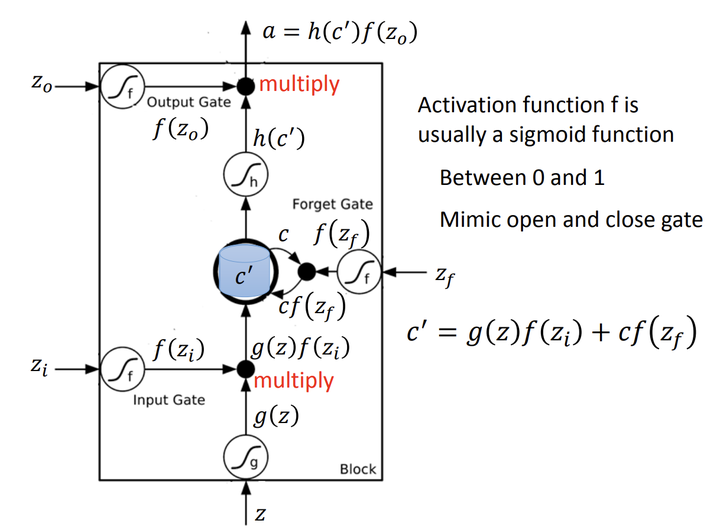
LSTM是简单RNN模块的改进版本,解决了普通RNN的梯度消失问题。它引入了“门”机制(输入门、遗忘门、输出门)和细胞状态,用于长期依赖建模。
遗忘门:
输入门:
Cell 状态更新:
输出门:
其中: 是Sigmoid函数,
表示逐元素乘法。
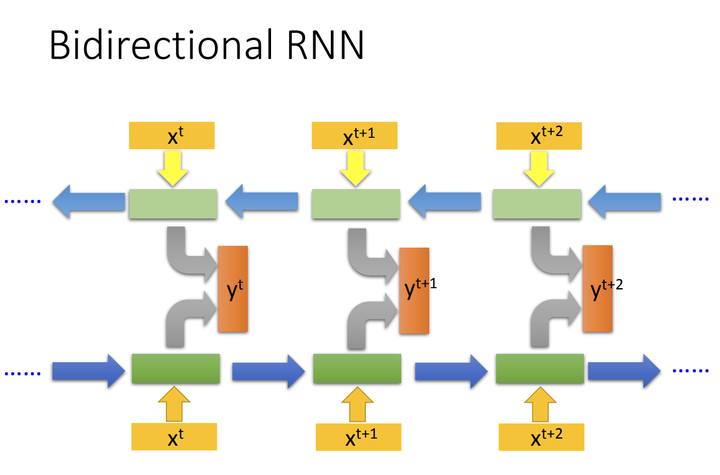
1.3 Bidirectional LSTM (BiLSTM)
BiLSTM是LSTM的扩展,结合了前向和后向两个方向的信息,适合捕获序列的全局上下文。它利用两个LSTM:前向(从左到右)和后向(从右到左),并在输出将前向和后向的隐藏状态拼接
其中 和
分别表示前向和后向隐藏状态。
2. Homework Results and Analysis
HW2 是一个多分类任务,我们将根据语音进行逐帧的音素预测。音素是语言中最小的语音单位,可以用来区分不同的单词。音素与字母不同,它们代表的是发音。在书写中,一个音素可能对应多个字母或字母组合。
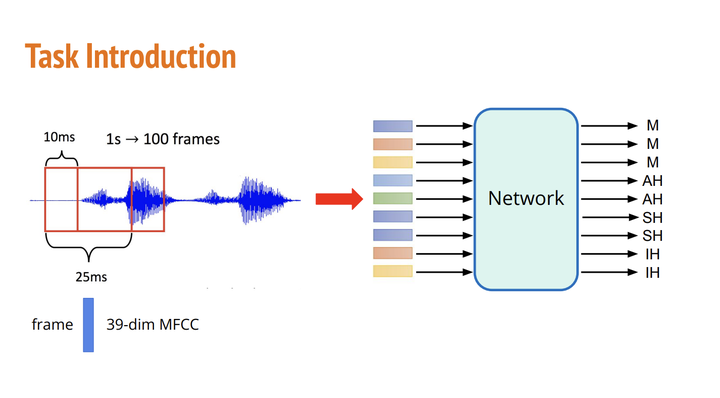
音频信号将被划分为重叠的帧,每帧持续 25 毫秒,相邻帧之间的间隔为 10 毫秒。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









