







背景
Prompt Engineering(提示工程)是一种设计和优化提示(文本输入)的实践,旨在增强大型语言模型(LLMs)的生成能力。其目的是通过精心设计的指令引导模型生成期望的响应。最常见的提示技术包括:
- Chain-of-Thought(思维链): 通过逐步推理来得出结论。模型被要求“思考过程”(如DeepSeek),显式地列出逻辑步骤,从而得出最终答案。
- ReAct(Reason+Act,推理+行动): 结合推理去执行操作。模型不仅要思考问题,还要基于推理采取行动执行任务。这种方法更具交互性,模型在推理步骤与执行操作之间不断的循环,迭代优化自己的下一步推理。本质上它是一个“思考—行动—观察”的循环。
举个例子让大家更容易理解:假设我让AI“找出1000块以下最好的笔记本电脑”。我们用不同的提示词技术可以得到不同的回复:
- 普通回答: “联想ThinkPad。”
- 思维链回答: “我需要考虑性能、电池续航和做工质量等因素。然后,我会检查哪些笔记本的价格低于1000美元。根据我目前的知识数据,联想ThinkPad是最优选择。”
- ReAct回答: 与思维链回答相同,但同时执行代理操作,例如进行“2024年1000美元以下最佳笔记本”网页搜索,并分析搜索结果(可能得出的结论不再是“联想ThinkPad”)。
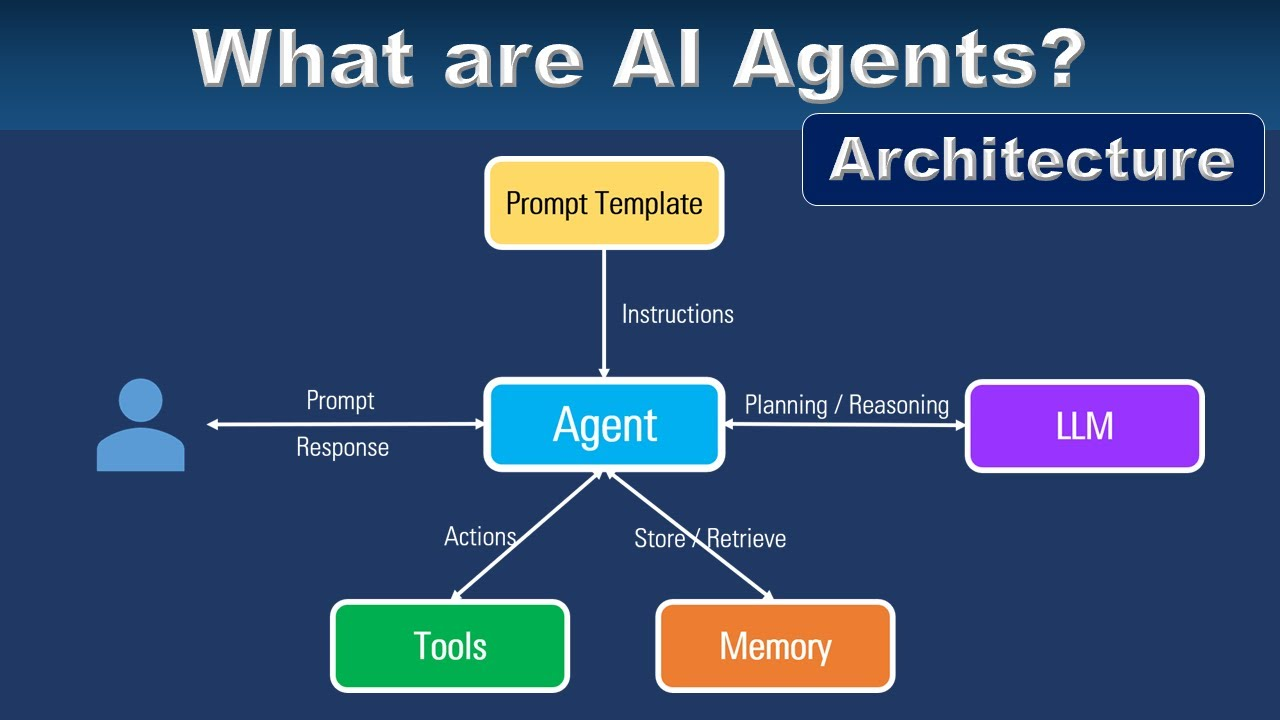
而代理(Agents)就是基于ReAct技术而构建的,因此它们与普通AI模型相比,还具备了执行操作的能力。代理是一种能够进行连续推理的AI系统,在大语言模型的通用知识不足时,可以执行外部工具(如数据库查询、网页搜索)。简单来说,普通的AI聊天机器人在无法回答用户问题时可能会生成随机文本产生幻觉,而代理则会调用工具来填补知识空白,并提供更具体的答案。
在本教程中,我将从零开始构建一个经人工微调的多代理系统。我会分享全部Python代码,大家可以直接复制、粘贴并运行,同时我也会逐行解析代码并附加注释,以便大家能够轻松复现该示例。
本文将介绍的具体内容包括:
- 环境和AI模型的设置
- 使用LangChain构建工具
- 使用Ollama进行决策
- 采用Pydantic定义代理结构
- 基于LangGraph设计图工作流
- 多代理与人工干预
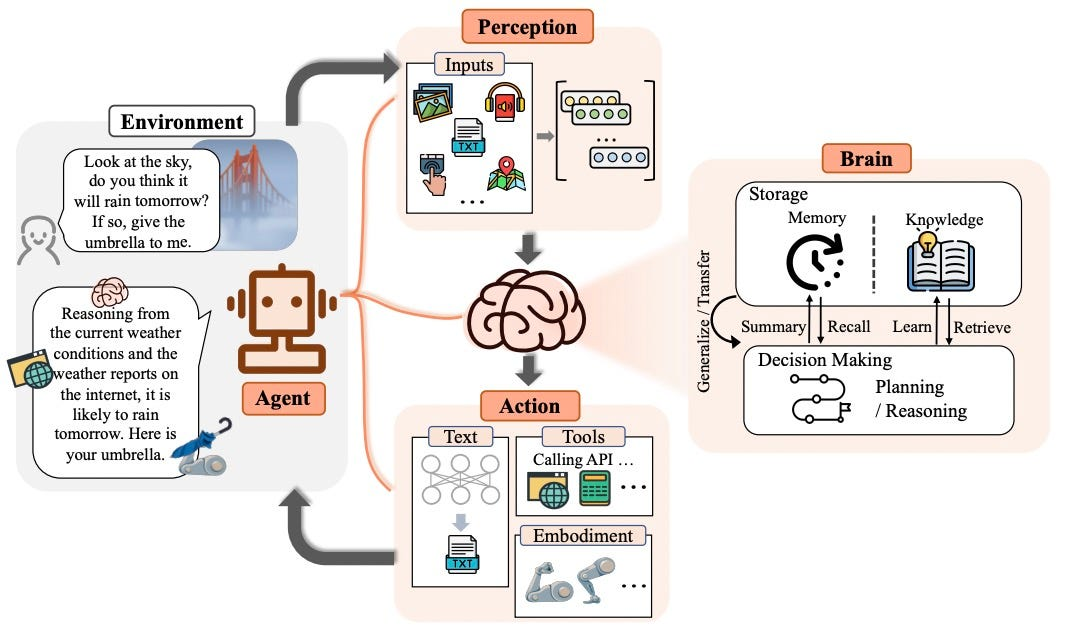
实验环境配置
目前市场上有两个主要的AI模型和代理的代码框架:
- LangChain —— 适用于构建需要复杂交互和工作流的大规模AI应用。它提供了一整套工具,专注于创建复杂的工作流。LangChain采用“组件链”模式,每个处理步骤和任务可以使用不同的AI模型。LangChain还提供了专门的多代理系统模块——LangGraph。
- LlamaIndex —— 适用于有大量数据搜索和检索能力的AI应用,特别适用于处理大规模数据集。它专注于数据的摄取、结构化和访问,使AI模型能够高效地消费数据。LlamaIndex旨在提供快速和高精度的数据检索功能,适用于需要快速访问海量数据的场景。LlamaIndex也提供了代理模块:Llama-Agents。
在本次实验中,我将使用LangChain,因为它更具灵活性。安装的命令如下:
pip install langchain安装后我们就能访问其全部模块,包括:
langchain:核心组件,包含链(Chains)、代理(Agents)和检索策略langchain-core:提供基本抽象层(如LLMs、向量存储、检索器的通用接口),被langchain包所调用langchain-community:由社区维护的第三方工具库langchain-experimental:包含实验性工具(如允许代理执行代码调用外部API的工具)- 相关配套库,如
langchain-openai、langchain-anthropic - 用于部署AI应用的工具,如LangServe和LangSmith
此外,我还将安装LangGraph来使用节点边(node-edges)架构的工作流构建代理,节点-边主要用于定义任务流的关系和执行顺序。
pip install langgraph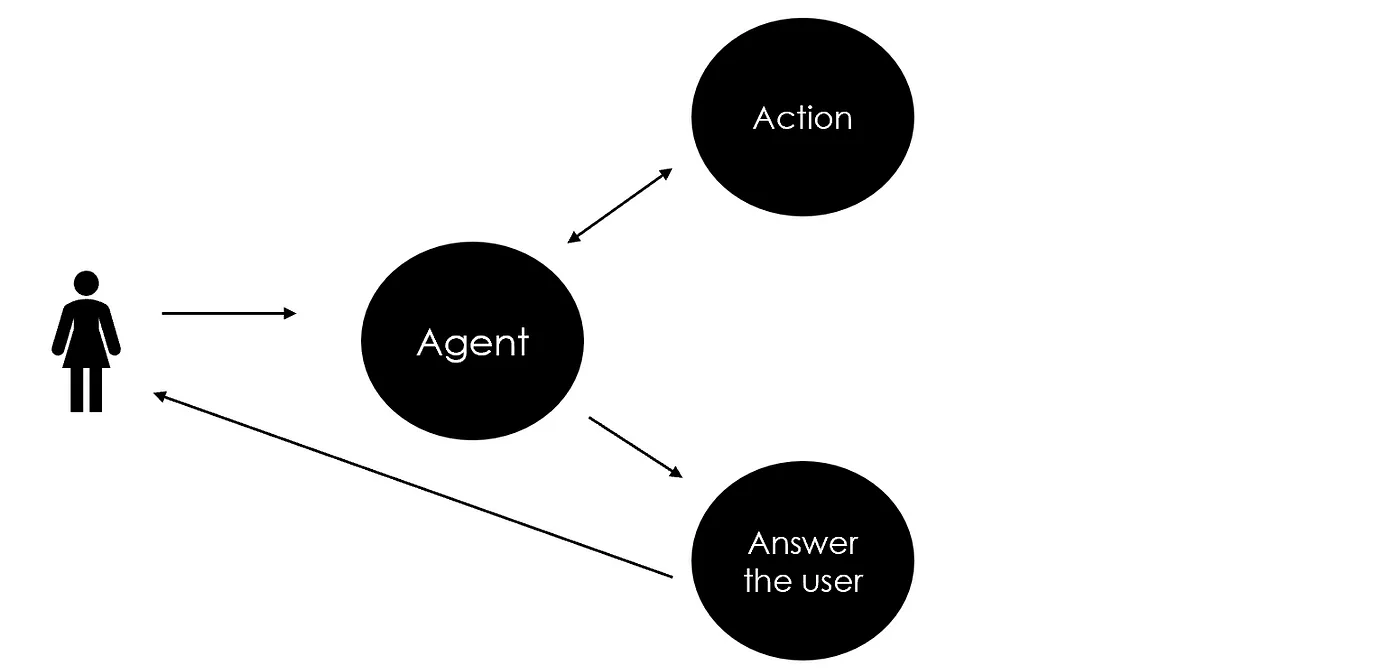
利用Ollama与Llama模型交互
在接下来的实验里,我将在本地运行我们的AI Agent,使用Ollama框架,并选择使用Meta的Llama 3.1,因为它是可以在无GPU环境下运行的最强大LLM。
pip install ollama与ollama交互的代码段为:
import ollama
llm = "llama3.1"
q = '''who died on September 9, 2024?'''
res = ollama.chat(model=llm,
messages=[{"role":"system", "content":""},
{"role":"user", "content":q}])
res我们可以得到如下响应:

需要注意的是,AI模型的知识受其最后一次训练所用的数据时间限制。在与AI聊天机器人交互时,存在三种角色:
"role": "system"—— 用于向模型提供系统指令,指导对话进行方式"role": "user"—— 代表用户的提问"role": "assistant"—— 代表模型的回复
Agent工具调用
网页搜索是AI Agent最常见的工具之一。在Python中最简单的网页搜索方式是使用DuckDuckGo的私密搜索。
pip install duckduckgo-search对于我们使用的Ollama,有两种方式创建外部调用工具:使用LangChain提供的标准装饰器(这是最常见的方法)。
from langchain_core.tools import tool
from langchain_community.tools import DuckDuckGoSearchRun
@tool("tool_browser")
def tool_browser(q: str) -> str:
"""Search on DuckDuckGo browser by passing the input `q`"""
return DuckDuckGoSearchRun().run(q)
# test
print( tool_browser(q) )得到回复:

另外我们还可以通过创建函数代码,并使用Semantic Router将其转换为Ollama的输入输出数据格式。Semantic Router是一个用于简化工具创建的库。
pip install semantic-router此外代理的定义中,我们也必须定义代理最终回复的结构:在每次用户提问后,代理需要决定是调用工具还是直接生成最终回答。请注意定义答案结构的提示词描述得越具体,模型的表现就越好。示例代码如下:
@tool("final_answer")
def final_answer(text:str) -> str:
"""Returns a natural language response to the user by passing the input `text`.
You should provide as much context as possible and specify the source of the information.
"""
return text代理执行决策的定义
在创建AI代理过程中,我们需要通过提示词,以定义代理的行为方式。
prompt = """
You know everything, you must answer every question from the user, you can use the list of tools provided to you.
Your goal is to provide the user with the best possible answer, including key information about the sources and tools used.
Note, when using a tool, you provide the tool name and the arguments to use in JSON format.
For each call, you MUST ONLY use one tool AND the response format must ALWAYS be in the pattern:
```json
{"name":"<tool_name>", "parameters": {"<tool_input_key>":<tool_input_value>}}
```
Remember, do NOT use any tool with the same query more than once.
Remember, if the user doesn't ask a specific question, you MUST use the `final_answer` tool directly.
Every time the user asks a question, you take note of some keywords in the memory.
Every time you find some information related to the user's question, you take note of some keywords in the memory.
You should aim to collect information from a diverse range of sources before providing the answer to the user.
Once you have collected plenty of information to answer the user's question use the `final_answer` tool.
"""
使用Ollama,我们可以直接利用它来测试和观察代理的决策过程。我们需要提前定义代理可用的工具。
dic_tools = {"tool_browser":tool_browser,
"final_answer":final_answer}
str_tools = "\n".join([str(n+1)+". `"+str(v.name)+"`: "+str(v.description) for n,v in enumerate(dic_tools.values())])
prompt_tools = f"You can use the following tools:\n{str_tools}"
print(prompt_tools)得到输出:

提示词(Prompt)、代理调用的工具和AI模型共同构成了代理的核心。通过上述的组件,AI能够自主决策。例如:如果用户没有提问,代理应该能够自主回复引导用户提问。
# LLM deciding what tool to use
from pprint import pprint
llm_res = ollama.chat(
model=llm,
messages=[{"role":"system", "content":prompt+"\n"+prompt_tools},
{"role":"user", "content":"hello"}
], format="json")
pprint(llm_res)得到回复:
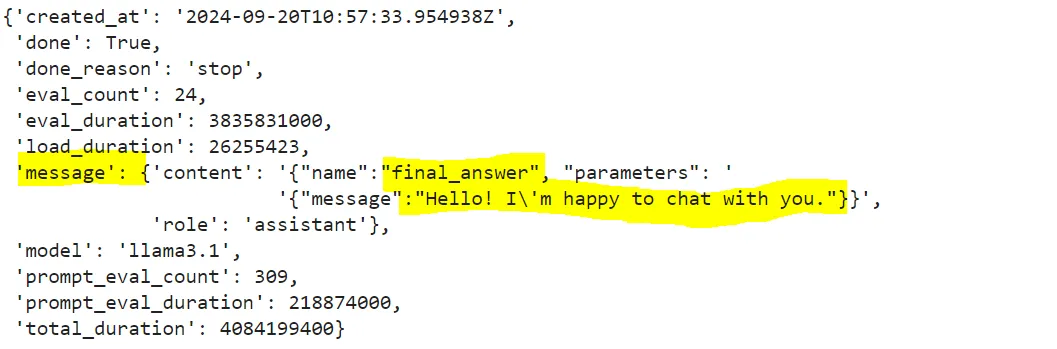
如果用户提出具体问题,代理应该调用网页搜索工具,并基于请求自动生成查询内容。
# LLM deciding what tool to use (output format = json)
llm_res = ollama.chat(
model=llm,
messages=[{"role":"system", "content":prompt+"\n"+prompt_tools},
{"role":"user", "content":q}
], format="json")
llm_res["message"]["content"]得到回复:

我们会将代理的查询结果作为上下文传递给LLM,通过打印输出可以看到代理如何处理这些数据。
# LLM with context
import json
tool_input = json.loads(llm_res["message"]["content"])["parameters"]["q"]
context = tool_browser(tool_input)
print("tool output:\n", context)
llm_output = ollama.chat(
model=llm,
messages=[{"role":"system", "content":"Give the most accurate answer using the folling information:\n"+context},
{"role":"user", "content":q}
])
print("\nllm output:\n", llm_output["message"]["content"])得到回复:

通过上述的测试,我们可以看到AI代理的核心逻辑和代码模块已经可以跑通。然而AI模型可能会生成不准确或不一致的内容(即所谓的“幻觉”),因此通常需要明确数据输入和输出结构,使模型遵循预定义格式。在本系列的下篇中,我们将继续介绍如何为AI代理定义明确的AI模型输入/输出结构,并创建AI代理让他可以执行复杂的任务流。请打击继续关注小李哥,不要错过未来更多的国际前沿AI技术!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









