






布隆过滤器
一.What
布隆过滤器是由很长的二进制向量(即可以理解成很长的0、1数组)与一系列随机映射函数(Hash函数)构成。

二.why
1.. 数据去重:
场景描述: 在一些需要对大量数据进行去重的场景,例如用户提交表单、数据同步等,布隆过滤器可以迅速判断某个数据是否已存在,避免重复插入。
应用实例: 在用户提交表单时,使用布隆过滤器判断该用户是否已经提交过相同的数据,从而防止重复提交。
2. 缓存穿透问题的解决:
场景描述:当缓存中不存在某个数据,而用户频繁查询该数据时,可能导致缓存穿透问题。布隆过滤器可以在缓存层之前迅速过滤掉不存在的数据,减轻数据库的压力。
应用实例: 在缓存中存储热门商品的ID列表,并使用布隆过滤器判断某个商品ID是否存在于列表中,从而决定是否查询数据库获取数据。
3. 爬虫数据去重:
场景描述: 在爬虫应用中,避免重复抓取相同的数据是一项关键任务。布隆过滤器可以帮助爬虫快速判断某个URL是否已经被抓取过。
应用实例: 在爬虫系统中,使用布隆过滤器存储已抓取的URL,以避免重复请求同一URL。
4. 安全黑名单:
场景描述: 在需要防范恶意攻击或恶意请求的场景中,布隆过滤器可以用于快速判断某个IP地址或请求是否在黑名单中。
应用实例: 在Web应用中,使用布隆过滤器维护一份IP黑名单,快速拦截恶意请求。
5. URL访问记录:
场景描述: 对于某些需要记录用户访问记录的应用,布隆过滤器可以用于判断某个URL是否已经被记录,避免重复记录。
应用实例: 在网站访问日志记录中,使用布隆过滤器判断某个URL是否已经被记录,防止访问记录过于庞大。
- HOW(原理)
1 数据结构
以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。
- 一个大型位数组(二进制数组):

- 多个无偏hash函数:无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。
2 增加元素
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1
通过k个无偏hash函数计算得到k个hash值
依次取模数组长度,得到数组索引
将计算得到的数组索引下标位置数据修改为1
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1.
如图所示: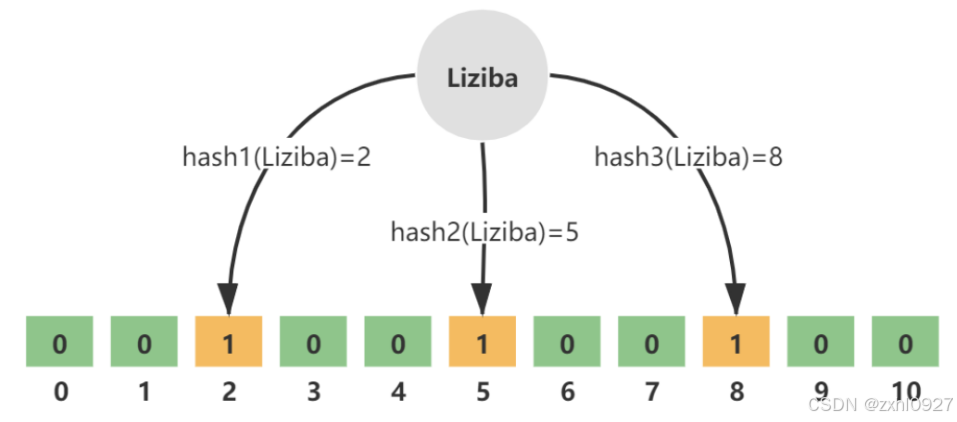
3.查询元素
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
通过k个无偏hash函数计算得到k个hash值
依次取模数组长度,得到数组索引
判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
4、关于误判
随着大量的数据添加到布隆过滤器,当一个不在布隆过滤器的元素进行hash计算后,根据得到的数组下标查询数据时,这些数据被其他元素在插入时置为1了,则会误判该元素存在于布隆过滤器。
hash冲突的原因。假设元素a和元素b具有相同的hash值,同时假定进行3次hash计算,hash值为1,2,3
将元素a插入了布隆过滤器,a[1]=a[2]=a[3]=1
元素b没有插入布隆过滤器,当查询元素b时,经过hash计算,得到的数组下标为1,2,3,由于元素a将这些数据置为1,则判断b元素存在于布隆过滤器,误判就出现了。
降低误判率:
- 增加哈希函数的个数
原理:哈希函数的个数越多,每个元素在布隆过滤器中对应的位数组位置被置为1的概率就越高,这有助于减少因哈希碰撞导致的误判。
实现:在设计布隆过滤器时,可以根据预期的数据量和误判率要求,适当增加哈希函数的数量。例如,在某些实现中,当误判率从0.01降低到0.001时,哈希函数的个数可能会从7增加到10。
注意事项:哈希函数的个数不能无限制增加,因为这会带来额外的计算开销,并可能导致性能下降。因此,需要在误判率和性能之间做出权衡。
b. 增大位数组的长度
原理:位数组的长度越大,哈希碰撞的概率就越低,因为更多的位置可以被用来存储哈希值。
实现:在创建布隆过滤器时,可以指定一个较大的位数组长度。例如,当误判率从0.01降低到0.001时,位数组的长度可能会从9585058增加到14377587。
注意事项:位数组长度的增加会占用更多的内存空间,因此需要根据实际可用的内存资源进行合理选择。
四.布隆过滤器优缺点
优点:
时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
保密性强,布隆过滤器不存储元素本身
存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set、Map集合)
缺点:
有一定的误判率,但是可以通过调整参数来降低
无法获取元素本身

















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









