






Flume(采集行为数据)
1.Flume体系结构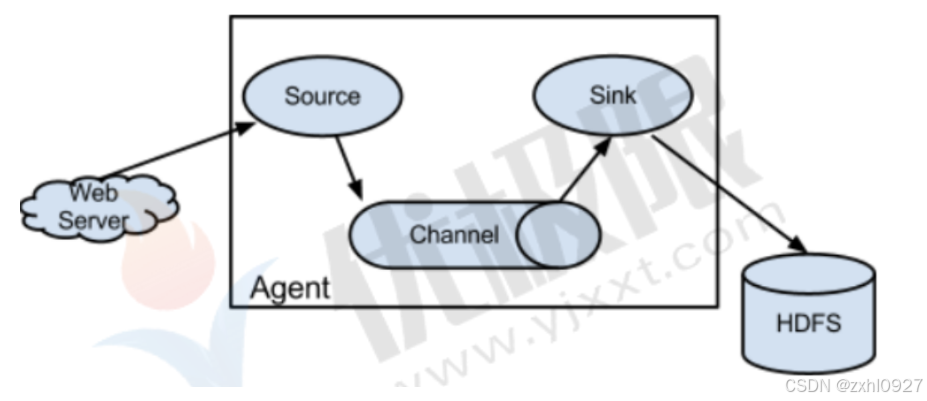
Client生产数据,运行在一个独立的线程。

Flow:Event从源点到达目的点的迁移的抽象。
Agent:一个独立的Flume进程,包含组件Source、 Channel、 Sink。
Source:数据收集组件。(source从Client收集数据,传递给Channel)
Channel:中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接sources 和 sinks ,这个有点像一个消息队列。)
Sink:从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话(Sink从Channel收集数据,运行在一个独立线程。)

2.Flume事务
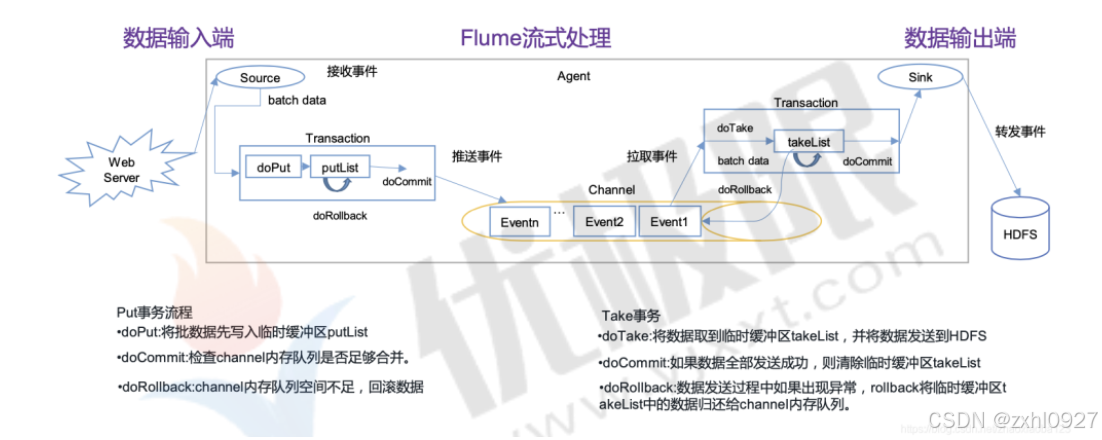
3.Flume使用
1)Source的操作
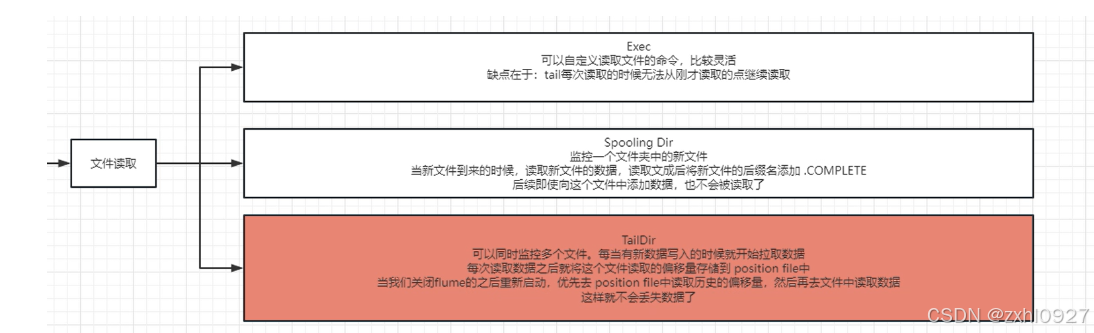
绝对路径,inode,偏移量
2)Interceptor(Source和Channel之间)
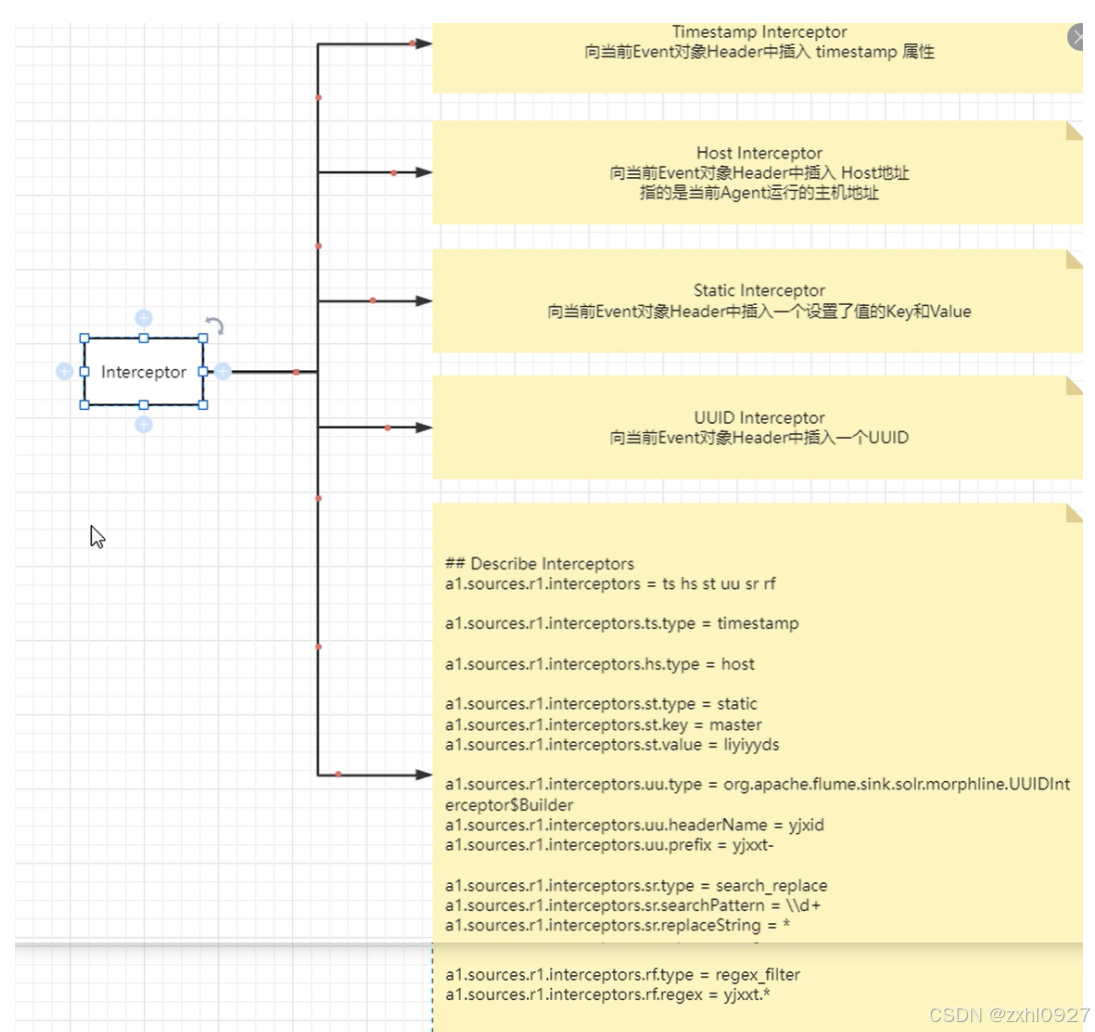
3)Channel
Memory Channel(稳定情况下使用)–将 Event 数据存储在内存中。
JDBC Channel(放入同一个JDBC 中)–将 Event 数据存储在持久化存储中,Flume Channel 内置支持 Derby。
File Channel–将 Event 数据存储在磁盘文件中。
Kafka Channel-(直接就不需要sink了)–将 Event 数据存储在 Kafka 中。
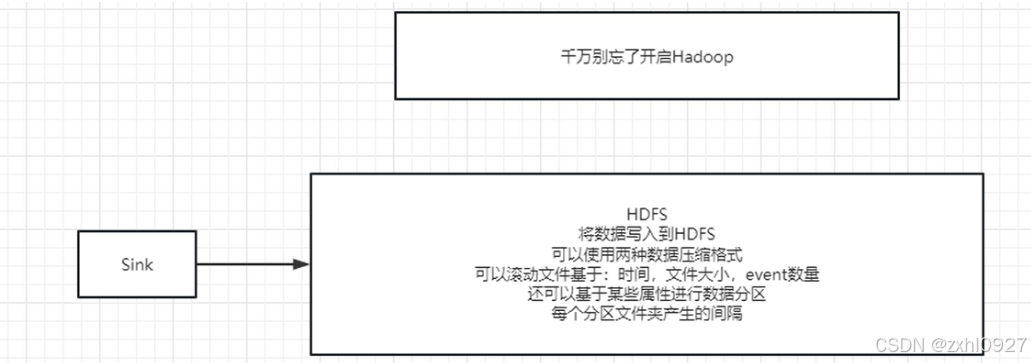
4)sink(hdfs)

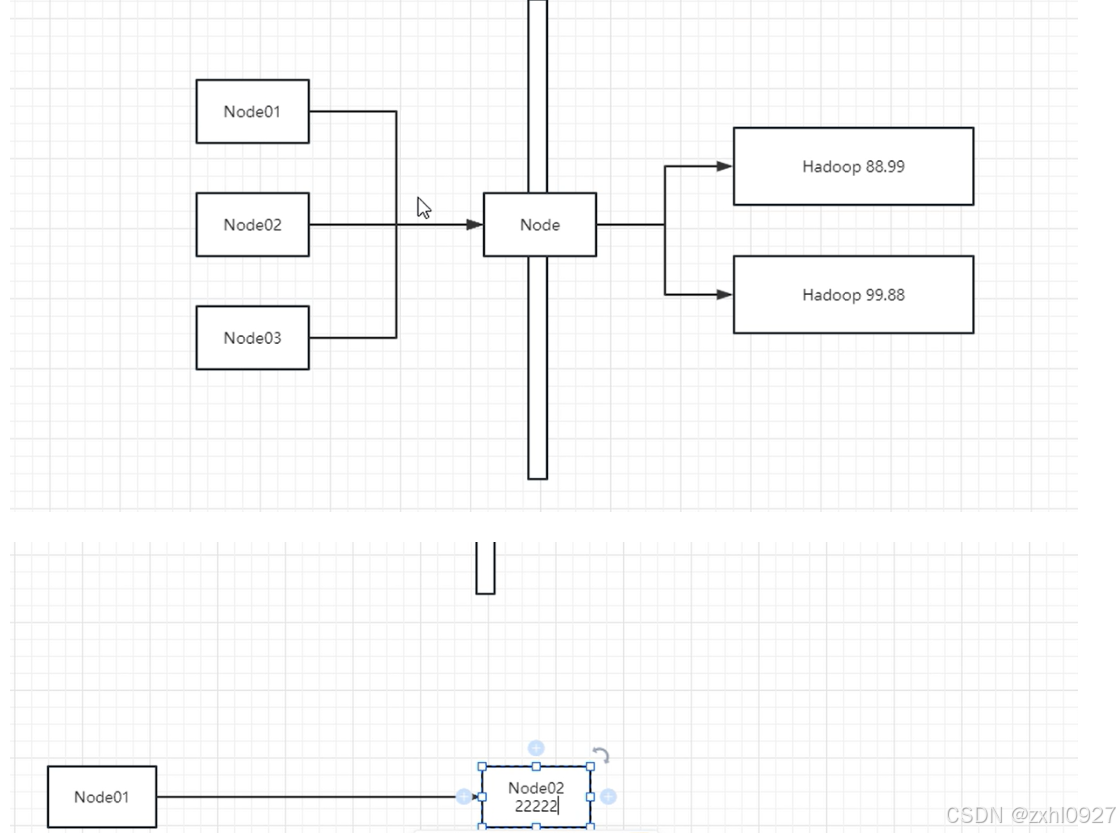
5)flume连接(avro)
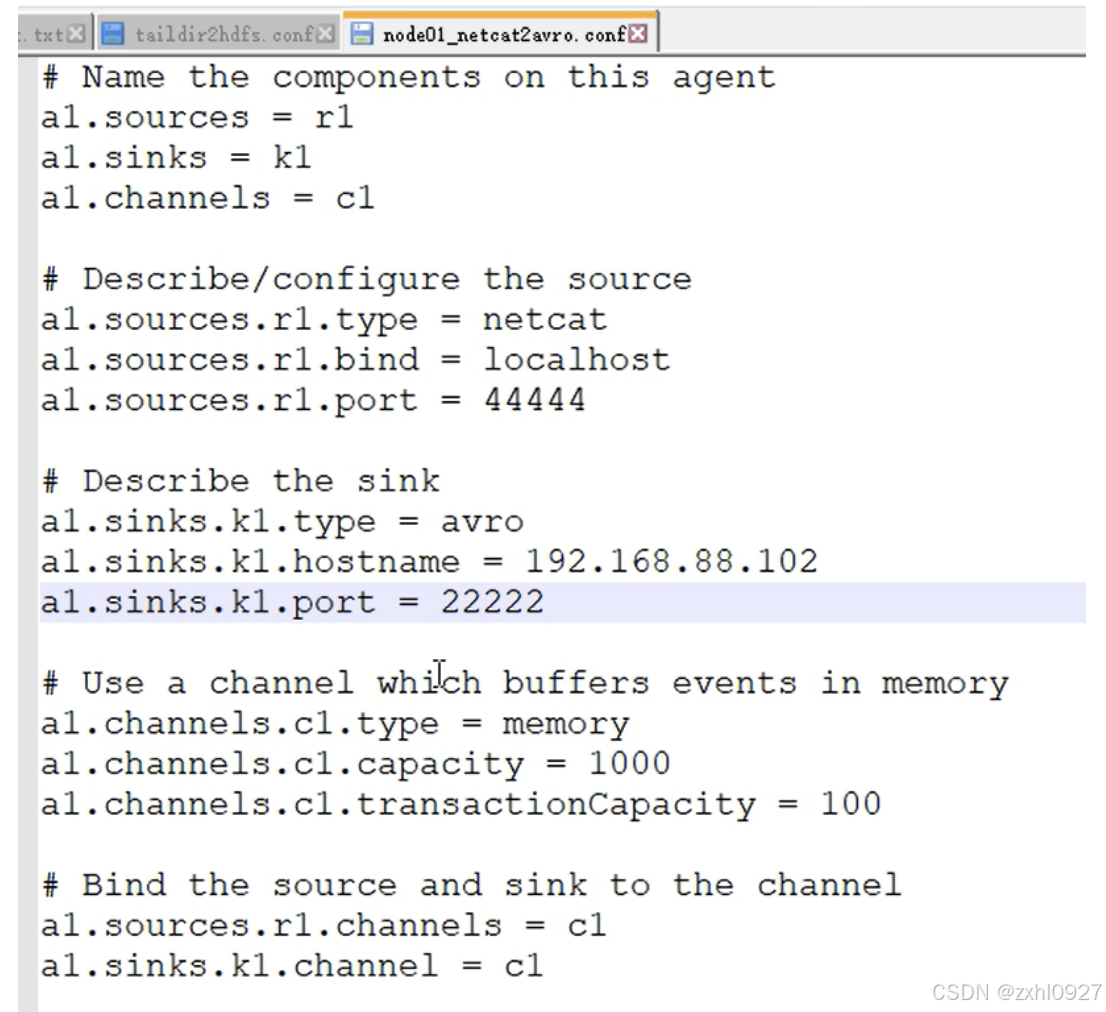
sink端
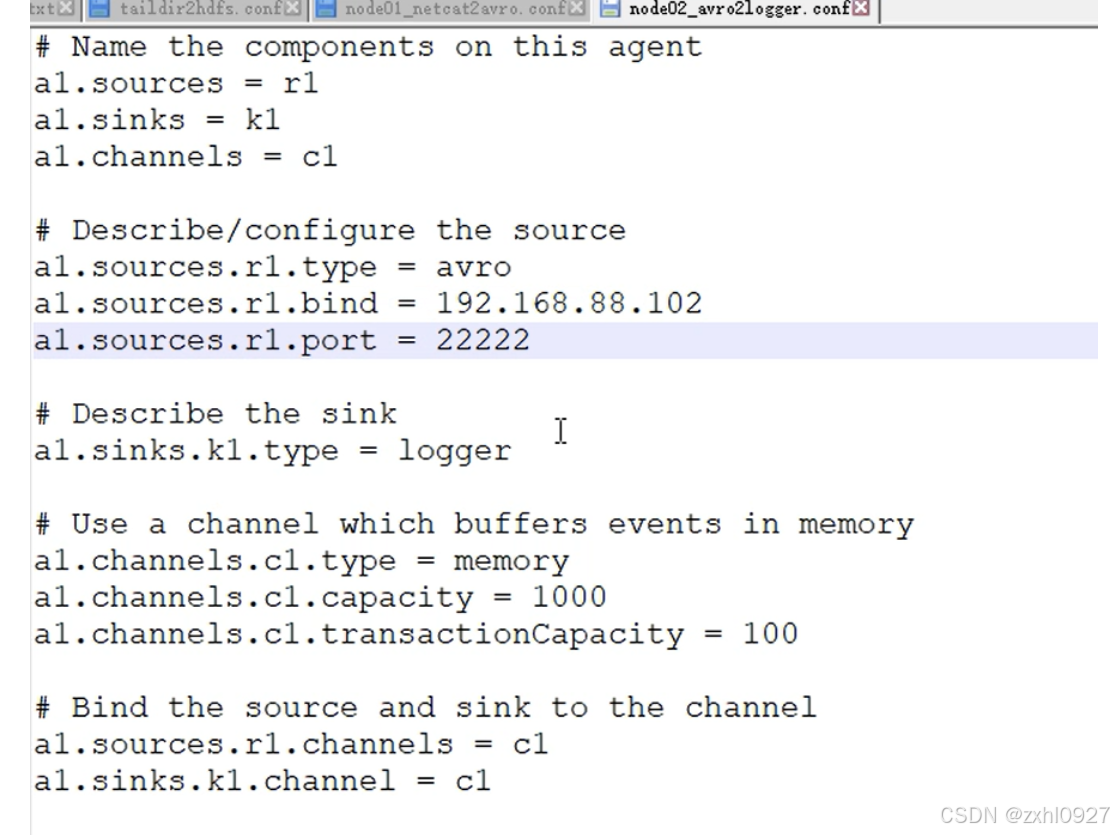
source端
6)故障转移
(多个节点利用优先级接收)
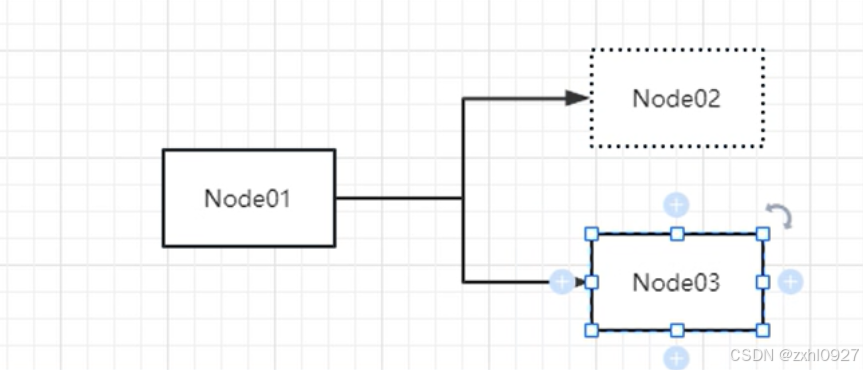

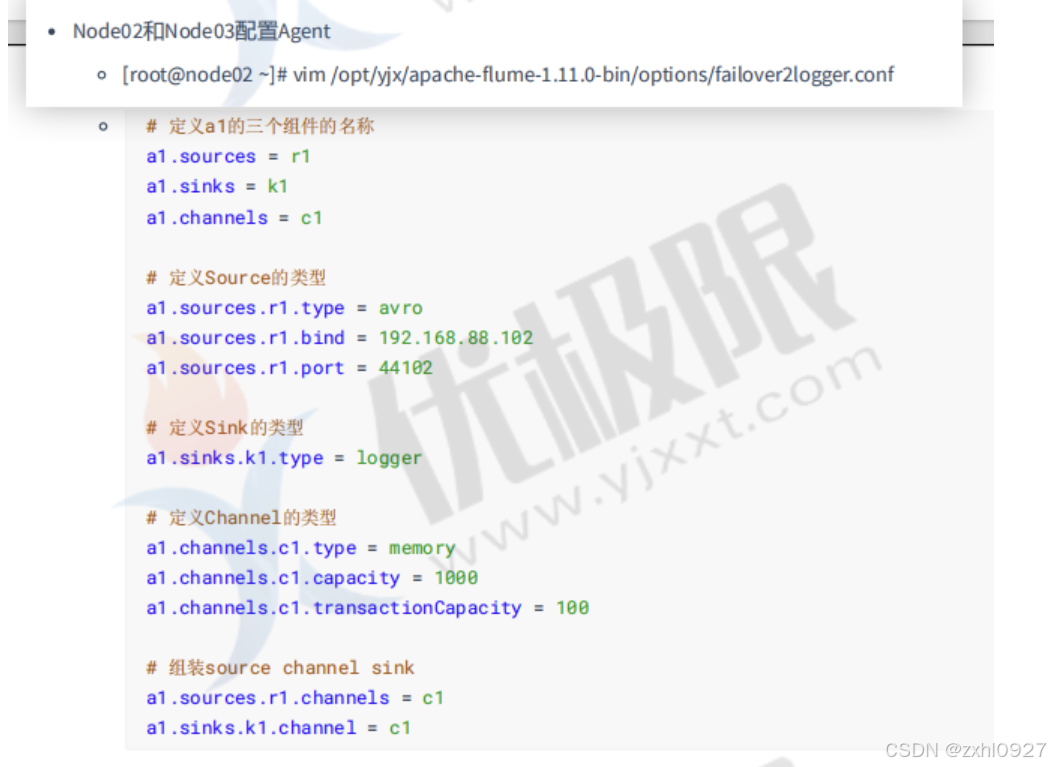

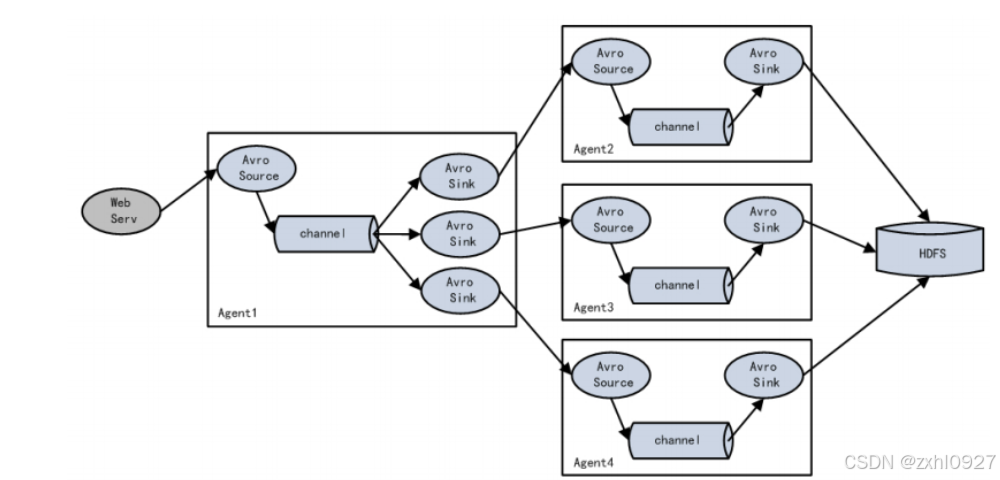
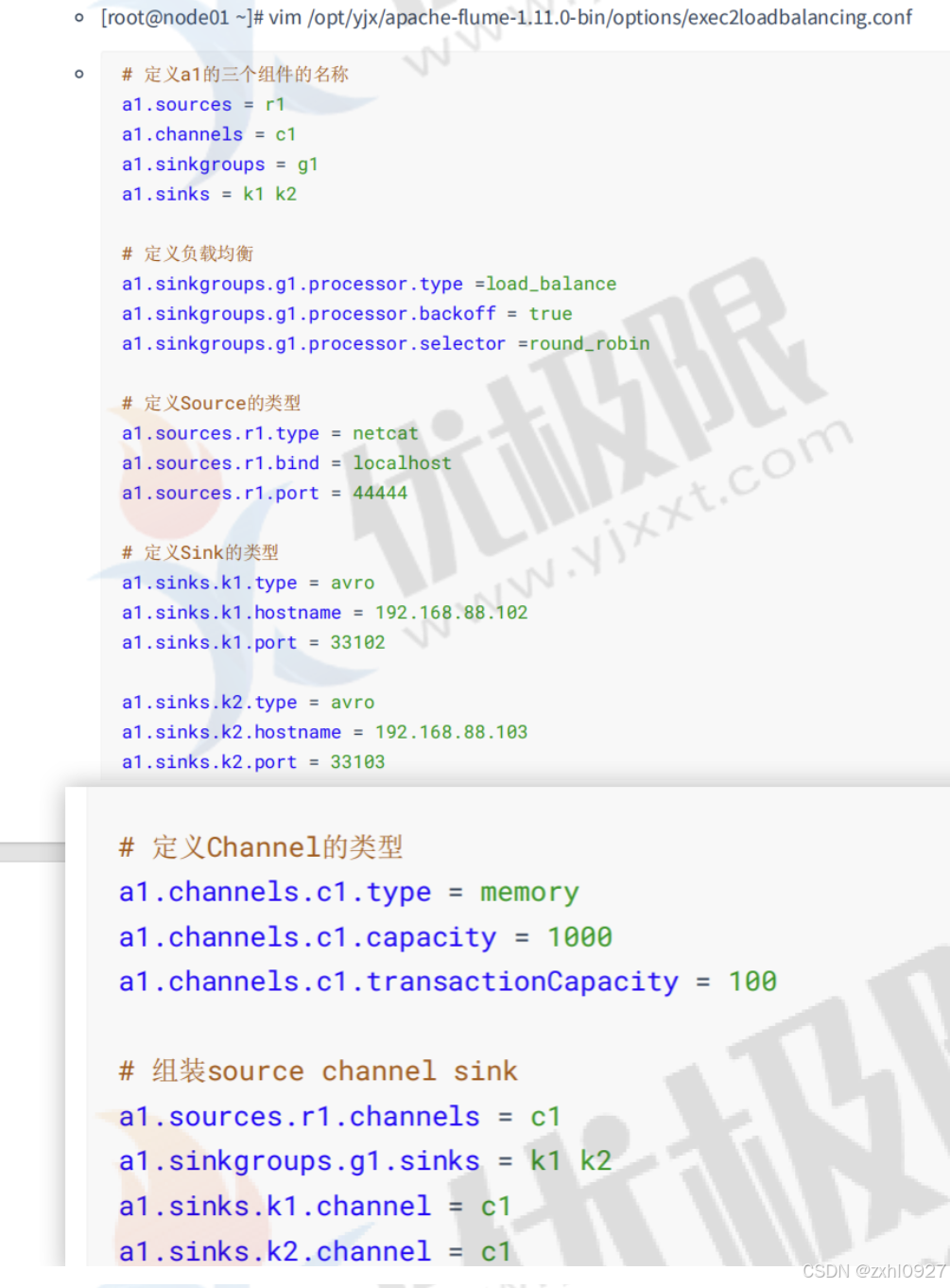
7)负载均衡
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
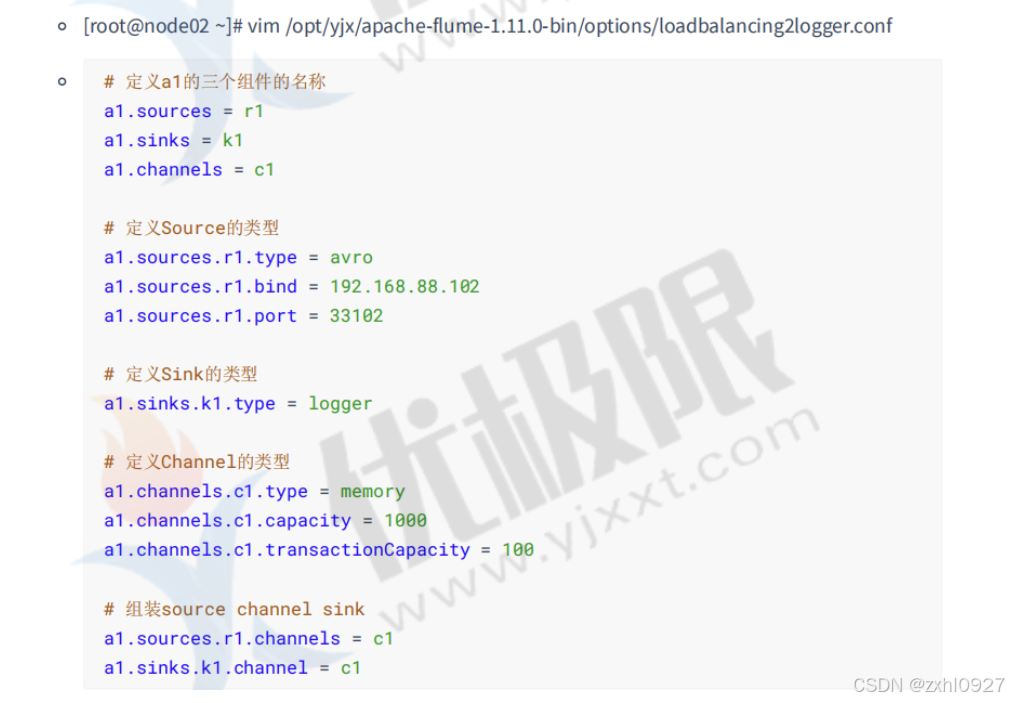
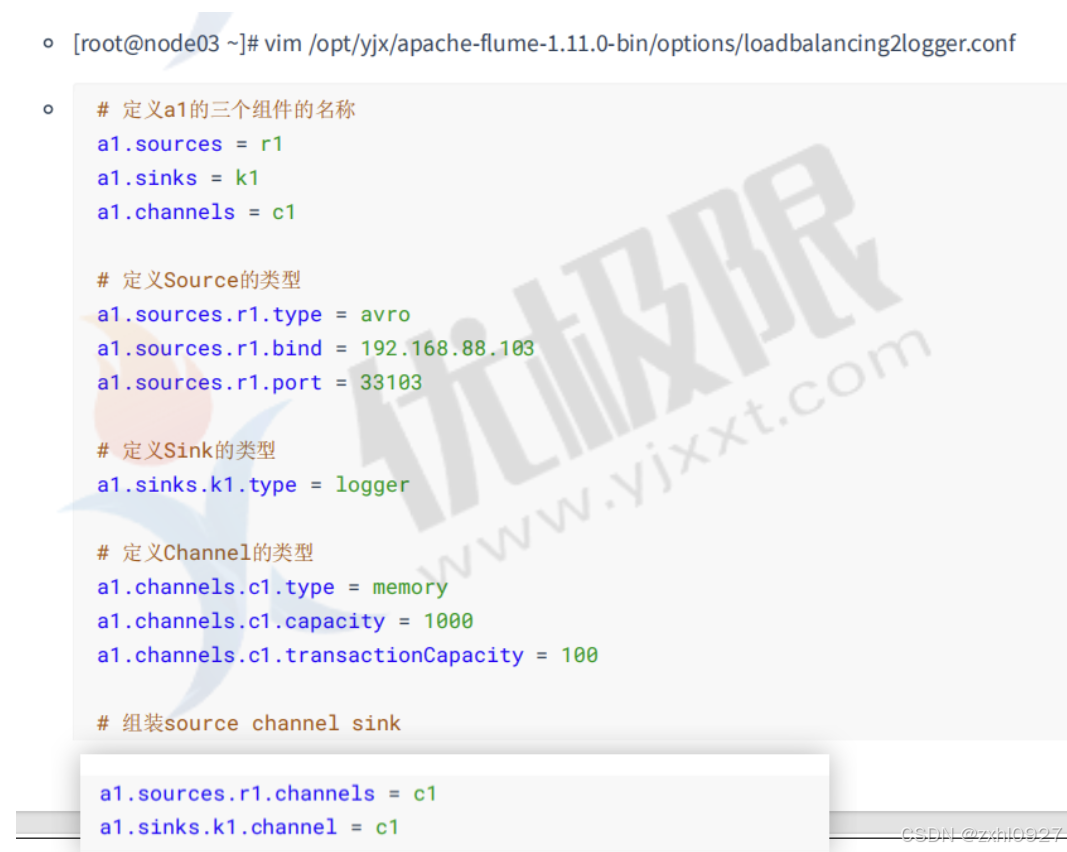
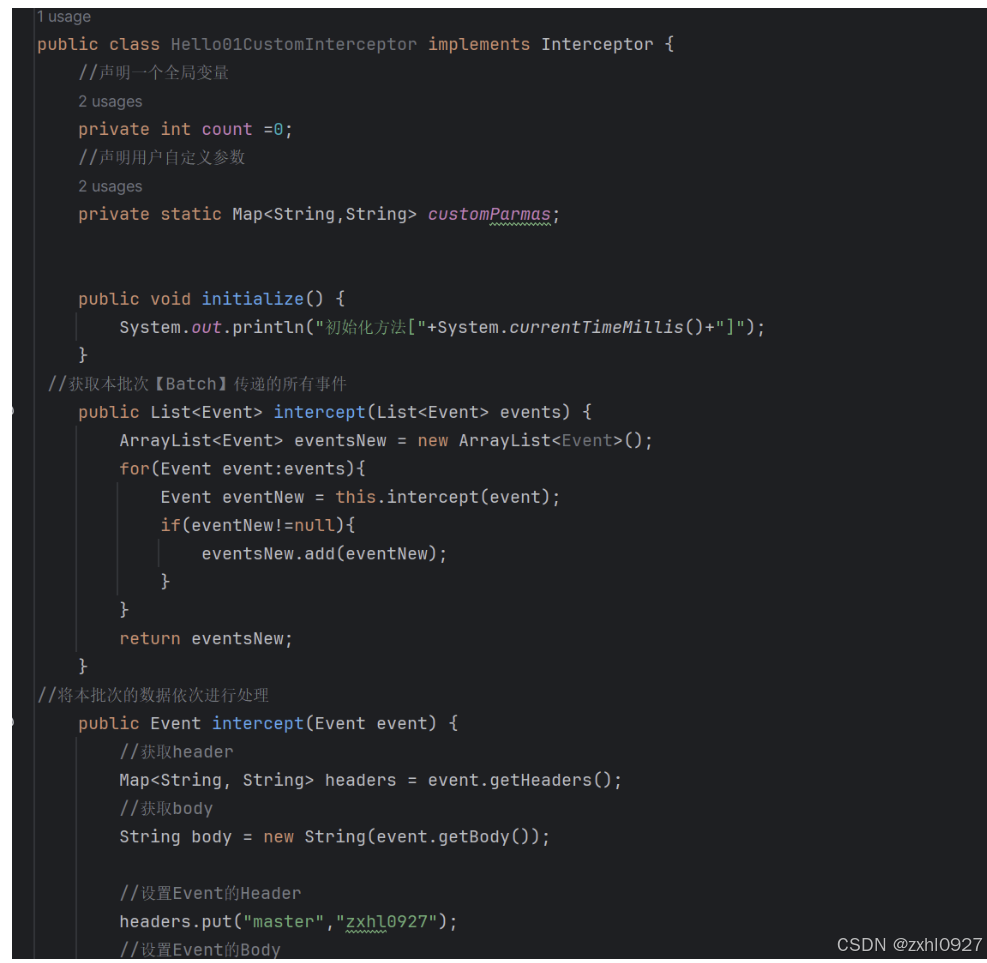
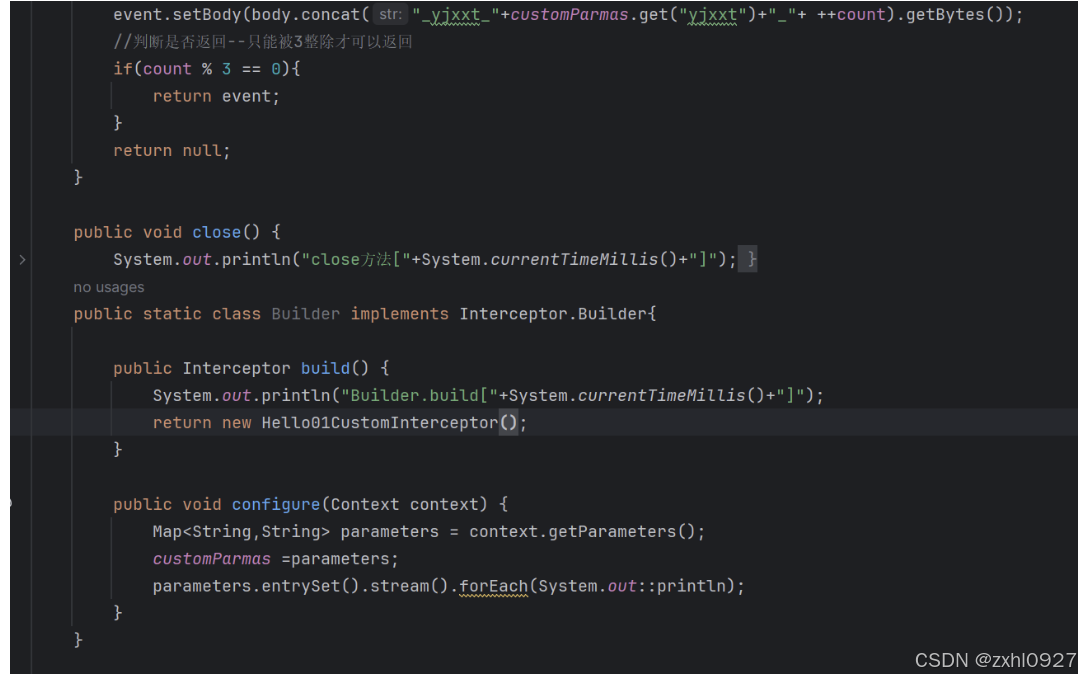
4.自定义Interceptor

$:内部类

















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









