



在上一篇文章中,我们见证了8-bit量化领域三位“奠基者”的精彩博弈。它们用各自的智慧,成功地在W8A8这条路上实现了精度与效率的平衡,让我们首次看到了为大模型“瘦身”并“提速”的曙光。然而,随着模型参数的军备竞赛愈演愈烈,一个更严峻的现实摆在了我们面前:对于那些动辄数百亿、上千亿参数的“巨兽”来说,8-bit,依然太“胖”了。
让我们来算一笔账:一个700亿(70B)参数的大模型,即便经过了8-bit量化,其模型体积依然高达约70GB。这个数字,对于绝大多数消费级显卡,乃至许多企业级的推理卡来说,都是一个难以逾越的天堑。仅仅是把模型加载到显存这一步,就足以将无数潜在的应用场景拒之门外。
为了彻底打破这道“显存之墙”,让每个人都能在自己的设备上运行强大的语言模型,将LLM真正推向“平民化”,量化技术必须向着更极致的压缩率迈进。于是,4-bit量化,这片充满挑战与机遇的“新大陆”,应运而生。
从8-bit到4-bit,看似只是压缩率从4倍提升到8倍(相较于FP16)的数字变化,但其背后,是量化难度呈指数级的增长。如果说8-bit量化(256个等级)是用一把还算精密的“游标卡尺”去测量世界,那么4-bit量化(仅16个等级)就无异于用一把刻度稀疏的“学生尺”去丈量精密的机械零件。任何微小的误差都会被急剧放大,任何简单的量化策略都将导致不可接受的精度崩塌。
这片充满荆棘的土地,也因此成为了各路算法“高手”们展现其顶尖智慧的最佳舞台。面对更严苛的挑战,他们创造出的“武功招式”也变得更加精妙和深刻:
- • 我们将首先拜访“精确雕刻家”——GPTQ。它不再满足于简单的映射,而是将量化视为一个严谨的误差补偿问题,通过复杂的二阶数学,对每一次量化引入的“伤痕”进行“像素级”的修复。
- • 紧接着,我们会见识“重点保护者”——AWQ的独特洞察。它告诉我们,无需对所有权重一视同仁,只要基于激活值的“情报”,找到并保护那1%最关键的“将领”,就能守住整个模型的“战线”。
- • 最后,我们将领略“生态颠覆者”——QLoRA的“双剑合璧”。它石破天惊地将4-bit量化与高效微调技术LoRA结合,不仅解决了“如何量化”的问题,更回答了“如何在量化模型上继续成长”的终极命题,彻底改变了LLM的微调生态。
现在,就让我们踏入这个4-bit量化的黄金时代,看看这些当今最炙手可热的算法,是如何在精度和效率的“刀尖”上,跳出最华丽的舞蹈。
一、 GPTQ:基于误差补偿的“精确雕刻”
1.1 核心思想:非破坏性的重建
与SmoothQuant那种通过“难度迁移”来规避问题的思路不同,GPTQ(Generative Pre-trained Transformer Quantizer)选择了一条更直接、也更“硬核”的道路。它将量化问题视为一个严谨的逐层重建(Layer-wise Reconstruction)问题。
它的核心哲学可以概括为:“每一次量化都是一次微小的‘破坏’,而我们的任务,就是在这次“破坏”发生后,立刻对周围的‘组织’(未量化的权重)进行一次精密的“修复手术”,以补偿这次破坏带来的损失。”
GPTQ的目标不是简单地将浮点数映射到整数,而是要找到一个量化后的权重矩阵,使得其输出与原始权重矩阵的输出之间的均方误差(MSE)最小。 它的优化目标可以用下面的公式来精确描述:
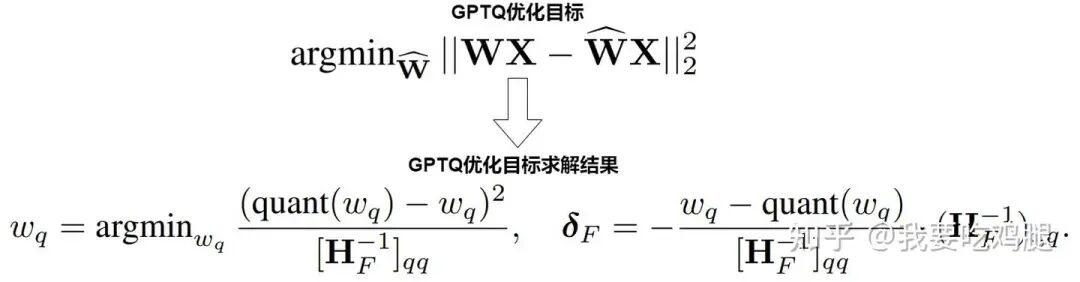
GPTQ优化目标公式
这个公式的含义是:我们要寻找一个量化矩阵,使得用它替换原始矩阵后,对任意输入,新旧两个层的输出和之间的差异(用二范数的平方MSE衡量)最小,它不是简单追求每个权重的最小误差,而是整体输出的误差最小。
为了实现这个宏大的目标,GPTQ不能像其他方法那样“一蹴而就”地完成所有权重的量化。相反,它像一位技艺高超的雕刻家,手持“二阶信息”这把精密的刻刀,对权重矩阵进行逐列、逐元素的精细“雕刻”,逐个权重、逐步量化并补偿。
量化步骤的目标函数
- • 其中 表示待量化的单个权重。
- • 表示量化后该权重的值(比如4-bit整数)。
- • 是二阶信息矩阵的逆,来自损失关于权重的Hessian矩阵(Fisher信息矩阵的近似),反映每个权重对整体输出误差的“敏感度”。
- • 分母 其实是为了实现“难度加权”:对影响大(敏感度高)的权重,量化误差需要被更严格控制。
立即补偿函数
每量化一个权重后,为了补偿新产生的误差,GPTQ会即时修正剩下的未量化权重:
- • 是对未量化权重的补偿量。
- • 直观理解:每当对某个权重 q 产生量化误差,立刻用Hessian矩阵的相关行列(反映权重之间的耦合/影响关系)去分摊、补偿这部分误差,保证整体输出扰动最小。
它的工作流程是迭代式的:
1.选择一个权重:从当前层尚未量化的权重中,选择一个进行量化。
2.执行量化:将这个浮点权重量化为4-bit整数。这一步,必然会产生一个量化误差(),即原始值与量化值的差值。
3.立即补偿:这是GPTQ思想的精髓所在。它不会让这个量化误差“不了了之”,而是立即更新该层中所有其他尚未被量化的权重,通过对它们进行微小的调整,来最大程度地“吸收”和“抵消”刚刚那一步产生的量化误差。
4.重复循环:不断重复上述过程,直到该层所有的权重都被逐一“雕刻”并“修复”完毕。
通过这种“量化一步,补偿一步”的精细操作,GPTQ确保了每一步量化所引入的局部误差,都能被后续的补偿操作所修正,从而使得最终累积的全局误差最小化,实现了非破坏性的、高精度的重建。
这种严谨的误差补偿思想,并非凭空创造,而是源于一个经典而深刻的理论体系。下一节,我们将一同回顾历史,看看GPTQ的智慧是如何从剪枝领域的鼻祖OBD和OBS算法中一步步传承和演化而来的。
1.2 理论溯源:从OBD到OBQ的智慧传承
GPTQ那精妙的“误差补偿”思想,并非凭空创造,它站在了长达三十年的学术研究的巨人肩膀上。要真正理解GPTQ的精髓,我们必须开启一次“理论考古”,追溯其思想的源头。这条智慧的传承之路,清晰地贯穿了三种里程碑式的算法:从OBD到OBS,再到OBQ。
第一步:OBD (Optimal Brain Damage) - 朴素的二阶剪枝
时间回到1990年,神经网络领域的传奇人物Yann LeCun提出了OBD算法,这是最早尝试使用二阶信息进行模型压缩的经典方法之一。当时的目标还不是量化,而是更直接的剪枝(Pruning)——即永久性地移除(置为0)网络中的某些权重,以减小模型尺寸。
核心问题:如果要从成千上万的权重中“砍掉”一部分,我们应该选择砍掉哪些,才能让模型的性能损失最小?
OBD的答案:OBD认为,一个权重的重要性,可以用“移除它会对模型的总损失(Loss)产生多大的影响”来衡量。为了高效地估算这个影响,OBD创造性地使用了损失函数对权重的泰勒二阶展开来近似。

OBD算法的数学推导
1.理论基础:损失函数的泰勒展开
首先,我们来看一下标准的、通用的多元函数在点附近的二阶泰勒展开公式长什么样:
高阶无穷小
我们首先写出这个展开式的完整形态。它详细地描述了当权重从最优点U发生一个微小的变化δU时,总损失E会如何变化(即):
一阶项梯度贡献二阶对角项独立贡献二阶交叉项协同贡献高阶无穷小
这个公式看起来很复杂,但OBD的精髓就在于接下来如何通过一系列巧妙(且大胆)的假设,把它变得极其简单。
2.关键简化与假设
如上图所示,OBD的推导过程主要依赖于三个关键简化:
- • 简化一:假设网络已收敛 (梯度为0) 我们假设网络已经训练完毕,达到了损失函数的一个极小值点(山谷的底部)。在这个点上,损失函数的“坡度”为0,即所有权重的一阶导数(梯度)都为0。因此,整个一阶项可以被忽略。
- • 简化二:假设权重相互独立 (Hessian矩阵为对角阵) 这是OBD最大胆,也是其“朴素”之处。它假设所有权重之间是相互独立的,移除一个权重w_i,不会影响到另一个权重w_j对损失的贡献。在数学上,这意味着Hessian矩阵H是一个对角矩阵,所有描述权重之间相互作用的“交叉项”(其中)都为0。因此,二阶交叉项也可以被忽略。
- • 简化三:假设损失曲面是二次的 (忽略高阶项) 我们只关心极小值点附近的区域,并假设这个区域的形状可以用一个二次函数(抛物面)完美描述。因此,所有更复杂的三阶及更高阶的无穷小项也被忽略了。
3. OBD的最终公式与直观理解
经过这三步“大刀阔斧”的简化,估算损失变化的公式变得异常优美:这个公式告诉我们,一个权重的重要性(Saliency)只取决于两个因素的乘积:
1.它自身的大小():权重本身的绝对值越大,移除它(即让它发生的变化)可能会带来的影响就越大。
2.它对应的Hessian对角线元素:这个值代表了损失函数在这个“方向”上的弯曲程度,即“曲率”。我们可以这样理解:
- • 如果很大,说明损失函数的“山谷”在这个方向上非常陡峭和狭窄。即便只移动很小一步,也会迅速“爬上山坡”,导致损失E急剧增加。因此,这个权重非常重要,不能轻易移除。
- • 如果很小,说明“山谷”在这个方向上非常平缓和宽阔。移动较大一步,损失E也不会增加很多。因此,这个权重不那么重要,是剪枝的优先对象。
如果你也想通过学大模型技术去帮助自己升职和加薪,可以扫描下方链接【保证100%免费】👇👇

4. OBD的遗产与局限
OBD的贡献是开创性的,它首次证明了利用二阶信息可以进行高效、有理论依据的模型压缩。但其“权重相互独立”的假设在现实中过于理想化,忽略了参数之间复杂的相互作用,这为其后续的改进者——OBS留下了登场的舞台。
第二步:OBS (Optimal Brain Surgeon) - 引入误差补偿
在OBD提出几年后,OBS(Optimal Brain Surgeon)算法横空出世。它精准地抓住了OBD的核心弱点——“权重相互独立”这一过于理想化的假设,并提出了一项革命性的改进。这个改进,正是GPTQ思想的直接源头。
核心思想:OBS认为,神经网络是一个高度耦合的系统,权重之间是相互关联的,因此我们不能忽略Hessian矩阵的非对角线项。更重要的是,它开创性地提出,在剪掉一个权重后,我们不应该“听之任之”,而应该主动地更新网络中所有其他的权重,来补偿(Compensate)这次剪枝所造成的误差。OBS的整个过程,就像一次精密的“外科手术”:

OBS算法的数学推导
这个过程大家可能看不懂,我们来详细讲一下这里面的公式推导
第一步:泰勒展开(Taylor Expansion)
这是整个推导的基础。图中的第一行,
就是将函数 在某个点附近进行二阶泰勒展开。
上标 T (转置) 是怎么回事?为什么位置还不一样?
T代表转置,即把列向量变成行向量。它位置不同是为了严格遵守矩阵乘法规则,确保每一项的结果都是一个标量(数字)。
在一阶项中,梯度和都是列向量(n x 1),必须将梯度转置成行向量(1 x n)才能相乘,得到一个(1 x 1)的标量。
在二阶项中,为了让(n x 1)的列向量、(n x n)的矩阵和(n x 1)的列向量相乘得到标量,唯一的合法顺序就是 (1 x n) * (n x n) * (n x 1),所以转置必须放在第一个向量上。
- • 是一个函数,通常代表损失函数(或称误差函数),我们想要让它最小化。
- • 是我们想要优化的参数,通常是一个向量。
- • 是参数 的微小变化量,也就是和最优参数 的差值。
- • 是损失函数 对参数 的梯度。
- • 是海森矩阵,由 的二阶偏导数组成。
- • 是高阶无穷小项,代表泰勒展开的误差。
核心思想:我们用一个二次多项式来近似一个复杂的损失函数 在 附近的形状。
第二步:简化展开式
在第二步,图中做了一些简化和假设,这个跟OBD的假设是一样的,但还是简单说一下。
- • 假设网络参数完善:如果当前参数 已经接近局部最小值,那么梯度 将非常小,接近于0。所以第一项 ,可以忽略不计。
- • 忽略高阶余项:因为 是一个很小的向量,它的三次方项 比二次项小得多,所以在近似计算中,通常可以忽略不计。
经过这两步简化,的表达式就只剩下海森矩阵的那一项了:
核心思想:当我们足够接近最小值时,损失函数的变化主要由二阶导数(海森矩阵)决定,即由函数的曲率决定。
第三步:引入约束条件
到这里,问题从“如何让最小”转变为一个有约束条件的优化问题。图中的 是什么意思呢?
首先,我们来拆解这个表达式:
- • 是一个向量,代表网络中所有的参数,比如 。
- • 是参数的微小变化量,它也是一个向量,。
- • 是参数向量的第 个分量,一个标量。
- • 是一个特殊的单位向量,它在第 个位置上是1,在其他所有位置上都是0。比如当 n=4 且 q=2 时,。
的作用是从 向量中取出第 个分量 。
现在,我们来看内积。
这个内积的运算结果就是向量 的第 个分量 。
所以, 实际上就是约束条件,也就是 。
这个约束条件背后的物理/优化意义非常深刻,它将稀疏性(Sparsity) 的概念引入了优化过程,这在一些特定的二阶优化算法(例如L-BFGS-B等拟牛顿法)中非常重要。
在普通的泰勒展开优化中,我们想一次性找到所有参数的最优更新量 。但在实践中,这可能会非常耗时,尤其当参数量非常大时。所以,一个更实用的策略是:每次只考虑修正一个或几个对损失函数影响最大的参数,而将其他参数的修正量暂时设为0。
这个约束 实际上是在说:“我们现在只考虑对第 个参数 进行修正,并且我们希望它能被修正到0(即 )。” 这是一个非常激进的修正,因为它意味着这个参数对整体的损失贡献非常大,我们希望通过把它“归零”来获得最大的损失下降。
整个推导过程就是为了回答一个问题:在所有可能的参数中,哪个参数 如果被修正为0,能使损失函数 获得最大的下降?
这个约束条件就是用来测试和筛选这个“最有价值”的参数 的。通过不断地迭代这个过程,每次找到最优的 q 并更新它,就能逐步让损失函数收敛到最小值,同时达到稀疏化(即很多参数最终都为0或趋近于0)的效果。
简单来说,这个约束条件的作用是:
1.引入稀疏性:将一个复杂的优化问题(同时更新所有参数)简化为一个迭代的、每次只更新一个关键参数的问题。
2.筛选关键参数:通过这个约束和拉格朗日乘子法,我们能够找到那个“最值得”被修正的参数,从而使优化过程更高效。
因此, 不仅仅是一个数学表达式,它代表了一种智能的参数更新策略,特别适用于需要处理大规模参数的优化问题。
第四步:拉格朗日乘子法(Lagrangian Multiplier Method)
为了解决这个有约束的优化问题,我们引入了拉格朗日乘子法。
- • 目标函数:我们想最小化 。
- • 约束条件:。
根据拉格朗日乘子法,我们构建一个新的函数 : = 目标函数约束条件
其中 就是拉格朗日乘子。
为了找到 的最小值,我们对 求关于和 的导数,并令其为0。
第五步:求解 和
对 求导并求解,可以得到:
- • 对 求导:
- • 代入约束条件 :
- • 再把 代回 的表达式,就得到了图中给出的 :
这里的 等于矩阵 的第 行第 列的元素 。所以这个表达式可以写成:
同样地,把 代入的表达式中,可以得到:
这表示在给定约束下,损失的最小变化量。
第六步:寻找最优的稀疏参数
最后一步,我们想要找到一个参数 ,使得在约束 下,损失变化 最小。换句话说,我们要找到哪个参数 q 的修正量最能有效地降低损失。
- • 我们想要最小化 。
- • 这等价于找到一个,使得 最小。
所以,最后的表达式 就是在寻找能让损失变化最小的稀疏(即变化量最大)参数索引。
这个复杂的推导过程是二阶优化算法(如牛顿法或拟牛顿法)的理论基础之一,它解释了如何利用二阶信息来更精确地确定参数的更新方向和步长。
“外科手术”般的修复:OBS的整个过程,就像一次精密的“外科手术”:
1.诊断(选择目标):它不再使用简化的对角线Hessian,而是考虑完整的Hessian矩阵。它通过求解Hessian的逆矩阵,找到了一个更精确的衡量权重重要性的指标。如上图推导所示,移除权重所造成的最小损失为: 我们只需要选择让这个L最小的那个权重作为“手术”目标。
2.手术(剪枝与补偿):在“切除”(将其置为0)的同时,OBS会立即计算出一个最佳的更新向量,并将其施加到所有剩余的权重上。这个更新向量的计算公式同样依赖于Hessian逆矩阵: 这个操作确保了,在剪掉一个权重后,网络的整体损失增加量是所有可能中最小的。
OBS的遗产与瓶颈:
OBS的“误差补偿”思想是革命性的,它使得模型压缩的精度达到了新的高度。然而,它的致命弱点也显而易见:计算极其昂贵。在每一步迭代中,它都需要计算和使用完整的Hessian逆矩阵,对于一个有个参数的网络,其计算复杂度高达,这在面对现代神经网络时是完全不可行的。
至此,GPTQ所需的核心理论拼图已经集齐。OBD提供了“二阶信息”的思路,而OBS则贡献了“误差补偿”的哲学。接下来,就看OBQ是如何将这两者巧妙地结合,并从“剪枝”的世界,跨越到“量化”的世界了。
第三步:OBQ (Optimal Brain Quantization) - 从“剪枝”到“量化”的跨越
OBD和OBS算法,虽然精妙,但它们的目标始终是剪枝——一种将权重彻底置为0的“极端”操作。而我们更普遍的需求是量化——将权重近似到任意一个低比特值。
核心思想:从“剪枝”到“量化”的优雅推广
OBQ (Optimal Brain Quantization) 的核心思想,是将在剪枝(Pruning)领域被验证为极其有效的“误差补偿”哲学,巧妙地推广应用到更广泛的量化(Quantization)问题上。它完成了从“切除”到“塑形”的关键思想转变,剪枝,本质上是量化的一种特殊形式。
- • 在OBS (Optimal Brain Surgeon) 这样的剪枝算法中,目标是将某个权重彻底置为0。
- • 在量化任务中,目标是把一个权重近似到离它最近的一个预设值上(例如,4-bit整数能代表的16个值之一)。
OBQ的作者意识到,将权重置为0,无非就是把它“量化”到了数值0这个点上。从这个角度看,剪枝是量化问题的一个特例。这一点在算法的数学推导中也有清晰体现:OBQ的公式中包含一个通用的量化函数quant(w),如果这个函数永远返回0,那么整个OBQ算法就退化成了原版的OBS剪枝算法。
既然底层的数学逻辑是相通的,那么OBS那套被证明极为精确的“外科手术”式流程就可以被直接继承和扩展。OBS的核心是 “切除一个权重,立即修复其他权重”。OBQ将其推广为“量化一个权重,立即修复其他权重”。
这个思想的转变意义重大:
- • 从“破坏”到“重塑”:操作的目标不再是“移除”一个权重,而是将其“重塑”或“近似”为最接近的量化值。这是一种非破坏性的重建过程。
- • 误差补偿的普适性:每当一个权重w被量化为,必然会产生一个微小的量化误差 。OBQ不会让这个误差孤立存在,而是利用Hessian逆矩阵所揭示的权重间相互关联性,将这个误差的“影响”分配、补偿到其他尚未被量化的权重上,从而保证网络整体的输出扰动最小。
总而言之,OBQ的核心思想就是通过将剪枝视为量化的特例,成功地将OBS那套基于二阶信息的、严谨的误差补偿机制,从一个相对极端的应用(权重归零)解放出来,使其能够服务于更普遍、更精細的量化任务。
算法详解:贪心策略与误差补偿
为了实现“量化一个权重,修复其他权重”这一目标,OBQ 设计了一套精密的、逐层逐行处理的贪心算法。对于一个权重矩阵 ,它会将其拆分成独立的行,并对每一行分别执行以下迭代过程。
1. 贪心选择 (Greedy Selection)
在每一行的量化过程中,OBQ 并不会随意选择一个权重量化,而是遵循一个“贪心”原则。在每一步迭代中,它都会在所有尚未被量化的权重中进行评估,并选择那个“最优”的量化目标。
这个“最优”的定义是:选择那个在被量化后,对本层输出造成的损失增量 最小的权重。这个选择过程严格遵循下图所示的公式(2)。

OBQ核心公式推导与注释
这个公式的含义是,OBQ 会寻找一个权重 ,使得其量化误差的平方 与其对应的Hessian逆矩阵对角线元素的倒数 的乘积最小。我们可以这样直观理解:
- • 代表了量化这个权重会引入多大的直接误差。
- • 反映了模型对这个权重变化的敏感度。这个值越小,代表权重越“重要”或越“敏感”,任何微小的变动都可能对最终输出产生巨大影响。
因此,OBQ 的贪心策略会优先选择那些本身离量化点就很近(误差小),或者对模型输出影响较小(不敏感)的权重进行量化,从而确保每一步操作都尽可能地“无痛”。
2. 误差补偿 (Error Compensation)
这正是 OBQ 思想的精髓所在。一旦通过贪心策略选定了权重 w_q 并将其量化,算法会立即计算由此产生的量化误差。关键在于,它不会让这个误差凭空消失,而是利用Hessian逆矩阵中包含的权重间相关性信息,将这个误差的“影响”分配并更新到该行所有其他尚未被量化的权重上。
这个补偿过程的计算如上图中的 公式所示。它精确地计算出一个更新量,施加到所有剩余权重上,其目的是为了最大程度地抵消刚刚量化 所带来的负面影响。这个方法之所以行之有效,正是因为它承认了权重之间是相互关联的。当一个权重发生变化时,相关的权重也应该进行适应性调整。
下面的示意图生动地将“贪心选择”与“误差补偿”两个步骤结合在了一起,完整地展示了这一核心机制。
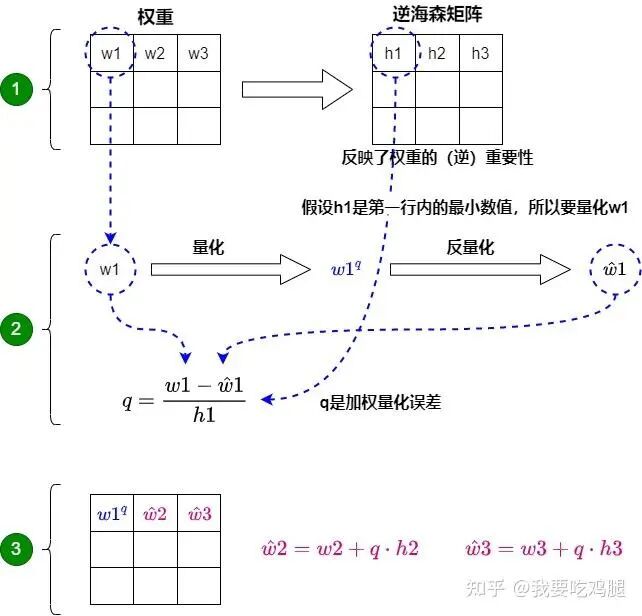
OBQ单行工作流程图解
整个过程如同一次精密的“外科手术”,分为三步:
- • 第1步 (诊断):根据逆海森矩阵(h1, h2, h3)反映的(逆)重要性,选择对模型影响最小的权重w1作为量化目标。这对应了贪心选择。
- • 第2步 (手术):对w1进行量化()和反量化(ŵ),然后计算出加权的量化误差q。
- • 第3步 (修复):将这个加权误差q,根据其他权重的重要性(),成比例地分配出去,更新和。这对应了误差补偿。
通过这种“量化一步,补偿一步”的精细操作,OBQ 确保了每一步量化所引入的局部误差,都能被后续的补偿操作所修正,从而使得最终累积的全局误差最小化。
算法流程可视化解析
OBQ 的原论文提供了一张流程图,生动地展示了上述贪心算法的执行过程(以剪枝为例)。
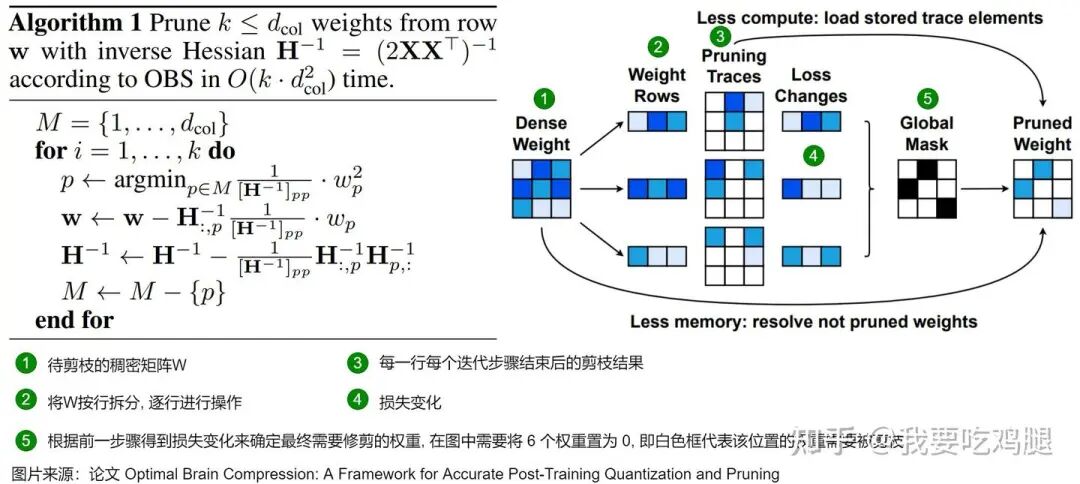
OBQ算法流程图
这张图详细描述了从一个完整的权重矩阵到最终量化(或剪枝)状态的全过程,我们可以将其分解为以下几个阶段:
① 初始状态 (Dense Weight):算法的输入是一个原始的、未经处理的稠密权重矩阵 W。
② 逐行分解 (Weight Rows):算法将整个矩阵按行拆分,准备以行为单位进行独立的、并行的量化操作。
③-④ 迭代与追踪 (Pruning Traces & Loss Changes):
- • Pruning Traces (剪枝/量化轨迹):对于每一行,算法会迭代地选择权重进行量化。这个部分记录了在每一个迭代步骤后,哪些权重被量化了。
- • Loss Changes (损失变化):与量化轨迹同步,这里记录了每一步量化操作后所导致的损失增量。颜色的深浅代表损失的大小,颜色越深,损失越大。
⑤ 生成掩码 (Global Mask):在所有迭代完成后,算法会根据之前记录的损失变化 Loss Changes 来确定最终需要被量化(或剪枝)的权重集合,并生成一个全局掩码。在图中,白色框代表该位置的权重是最终被选定的操作对象。
此外,该图还指出了两种工程实现上的权衡策略:
- • Less compute (减少计算):如果内存充足,可以通过存储中间步骤的 Pruning Traces,来避免在后续需要时重新进行完整的迭代计算。
- • Less memory (减少内存):如果内存空间有限,则不存储 Pruning Traces。当需要结果时,可以重新运行一次迭代过程来得到最终的量化权重。
OBQ的这套方法在理论上非常优雅,精度也极高。但它的“阿喀琉斯之踵”也暴露无遗——计算极其昂贵,慢得令人发指。
- • Hessian求逆的诅咒:它继承了OBS对完整Hessian逆矩阵的依赖,计算复杂度极高。
- • 贪心选择的拖累:在每一步迭代中,它都需要遍历所有未量化的权重,来寻找那个“最优”的量化目标,这又引入了巨大的额外计算量。
根据原论文的数据,用OBQ量化一个ResNet50模型就需要大约一小时,而量化一个百亿参数的LLM,则可能需要数天甚至数周的时间。这在实践中是完全不可接受的。
OBQ的最终遗产
尽管OBQ因其效率问题未能成为主流,但它为GPTQ的诞生铺平了最后一段道路。它贡献了完整的、基于误差补偿的量化框架。现在,历史的舞台已经搭好,所有的理论基石均已奠定,只等待一位“天才工程师”登场,通过一系列精妙的算法和工程优化,来攻克OBQ遗留下的效率瓶颈。
这位“天才工程师”,就是我们本节的主角——GPTQ。
1.3 技术详解:GPTQ的三大加速创新
GPTQ继承了OBQ那严谨的误差补偿核心思想,但它深知,若不解决其令人望而却步的计算效率问题,再好的理论也无法应用于动辄千亿参数的大模型。为此,GPTQ的作者们像一位高明的“效率工程师”,通过三项关键的算法与工程创新,成功地将OBQ的计算复杂度降低了数个数量级,使其能够在短短数小时内完成对一个1750亿参数模型的量化。
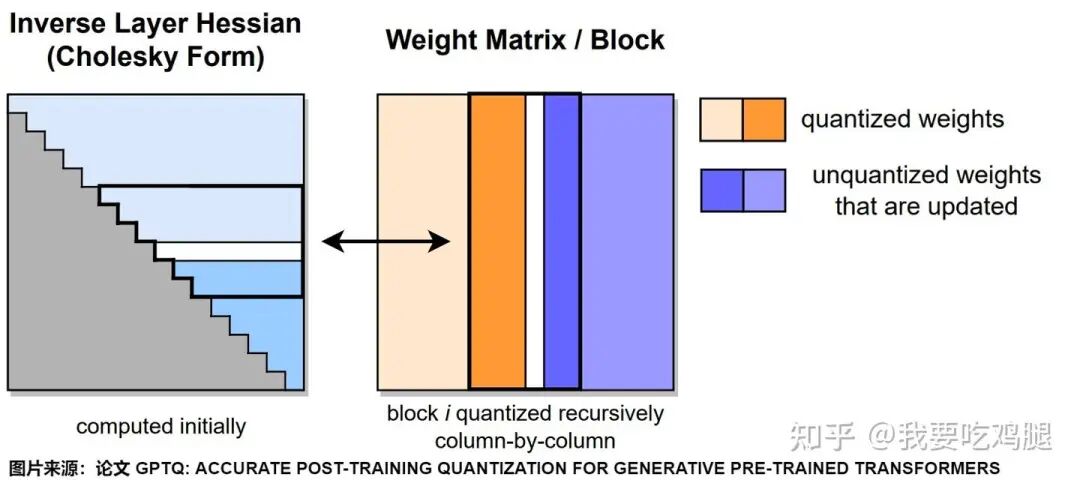
GPTQ核心工作流程示意图
上图宏观地展示了GPTQ的工作流程,其高效的秘诀,就蕴含在以下三大创新之中。
创新一:固定量化顺序,实现并行
这是GPTQ迈出的、最具颠覆性的第一步。
- • OBQ的瓶颈:昂贵的“贪心” 我们回顾一下,OBQ为了追求理论上的最优,采用了一种贪心策略。在量化权重矩阵的每一行时,它都会在每一步迭代中,遍历所有尚未量化的权重,计算并比较它们如果被量化会带来的损失增量,然后选择那个损失最小的权重进行操作。
这种做法导致了两个问题:
- • 计算量巨大:每量化一个权重,都要进行一次全局“海选”。
- • 无法并行:由于每一行的权重分布都不同,导致其“最优”的量化顺序也各不相同。这意味着,我们必须对每一行都进行独立的、串行的迭代计算。
- • GPTQ的洞察:“差不多”就是“足够好”
GPTQ的作者们通过大量的实验敏锐地发现,对于参数极度冗余的大语言模型来说,OBQ那种精挑细选的“贪心”量化顺序,与简单的 “固定顺序”(例如,严格按照列的索引,从第0列、第1列、第2列…一直量化到最后一列)相比,最终对模型精度的影响微乎其微。
这个发现是革命性的。它意味着我们可以为了巨大的工程效率提升,而放弃那一点点理论上的、几乎可以忽略不计的精度优势。
并行化的实现
这个看似“偷懒”的改动,却带来了巨大的工程优势。一旦所有行的量化顺序被固定下来(例如,大家都按列的顺序来),那么在每一步迭代中,所有行需要处理的都是同一列的权重。 这意味着,所有行都可以共享同一个Hessian矩阵信息,使得原本必须逐行、逐个处理的串行计算,可以被完美地并行化,用一个高效的矩阵运算在GPU上一次性完成。
图解对比
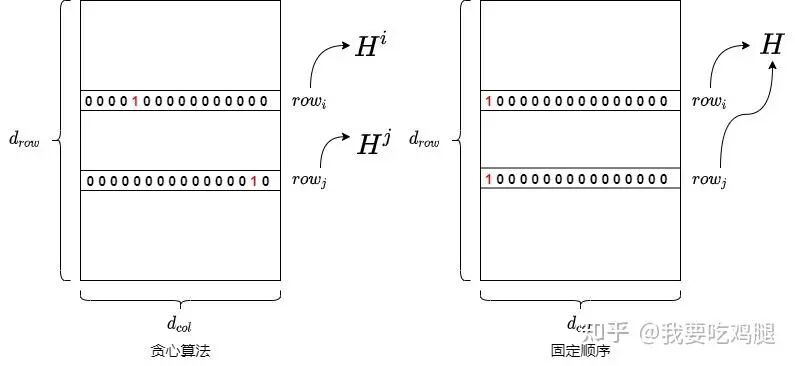
贪心算法 vs 固定顺序对比图
上图直观地展示了这一区别:
左侧(贪心算法): 每一行()都有自己独立的量化顺序,因此在迭代过程中,它们需要维护各自不同的Hessian矩阵状态(),无法统一处理。 右侧(固定顺序): 所有行都遵循相同的量化顺序,因此可以共享同一个全局的Hessian矩阵H,计算得以统一和并行。
通过这一项关键的改进,GPTQ摆脱了OBQ最沉重的计算枷锁,为在大模型上进行高效的误差补偿量化,铺平了道路。
创新二:惰性批量更新(Lazy Batch-Update),减少IO瓶颈
在通过“固定顺序”解决了并行计算的问题后,GPTQ的作者们又将目光投向了另一个主要的性能瓶颈——内存访问(IO)。
OBQ的瓶颈:被IO拖垮的计算
OBQ的误差补偿机制要求,每量化一个权重,就需要对所有剩余的权重进行一次更新。对于一个有列的权重矩阵,就需要进行次全矩阵的读写操作。在GPU中,这意味着大量的数据需要从高速但容量有限的缓存(SRAM)与大容量但速度较慢的显存(HBM)之间来回穿梭。 这导致了一个尴尬的局面:GPU大部分时间都在“等待”数据搬运,而其强大的计算核心却在“空转”,计算访存比极低。
GPTQ的洞察:更新的“单向依赖性”
GPTQ的作者们通过分析更新规则发现,权重的更新具有一种 “单向依赖性” 。即,对第i列权重的量化,其产生的误差补偿,只会影响到它后面()的列,而不会影响到它前面已经被量化好的列。
这个发现带来了巨大的优化空间。既然当前的量化只影响未来的列,我们完全没有必要在每一步都去更新整个矩阵。我们可以让这些更新“再飞一会儿”,把它们“攒起来”再一次性处理。
实现:分块处理与批量更新
基于这个思想,GPTQ设计了惰性批量更新(Lazy Batch-Update) 机制。它不再是每量化一列就更新一次整个矩阵,而是将权重矩阵按列分组(例如,每128列为一个块(Block))。
1.块内更新: 在处理一个块时,所有的误差补偿更新都仅限于该块内部。对第j列的量化,其误差只更新到这个块内列之后、第127列之前的权重上。
2.块间更新: 当这128列全部处理完毕后,再一次性地将这128次量化所累积的全部误差,统一应用到矩阵中所有剩余的、尚未处理的块上。
3.图解:
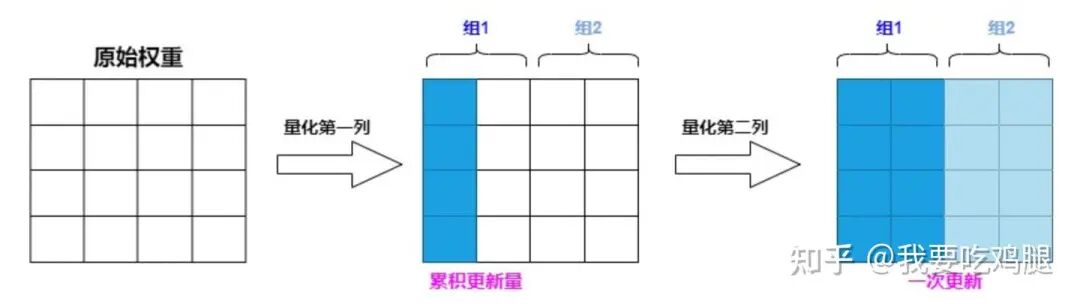
惰性批量更新图解
上图生动地展示了这个过程。通过将多次小规模的IO操作,合并为一次大规模的IO操作,GPTQ极大地提升了计算访存比,有效缓解了IO瓶颈,充分释放了GPU的计算潜力。
创新三:Cholesky(乔莱斯基) 分解,保证数值稳定性
在通过“固定顺序”和“惰性更新”解决了并行性与IO效率这两大瓶颈后,GPTQ还面临着最后一个,也是最隐蔽的“敌人”——数值不稳定性(Numerical Instability)。
问题的根源:重复更新带来的“精度漂移”
我们回顾一下OBQ的误差补偿公式,其核心在于对Hessian逆矩阵的反复使用和更新。在理想的数学世界里,这个过程是完美的。但在有限精度的计算机浮点数世界里,每一次矩阵减法和乘法都可能引入微小的舍入误差。
当GPTQ处理一个包含数百万甚至上亿参数的巨大权重矩阵时,这种更新操作需要被重复执行成千上万次。微小的舍入误差在这一次次的迭代中不断累积,如同水滴石穿,最终可能导致灾难性的后果。这个过程被称为精度漂移(Precision Drift)。
这种漂移可能会让计算出的Hessian逆矩阵逐渐失去其应有的数学性质(例如“正定性”),最终在某一步更新中,计算结果突然“崩溃”,产生无穷大(inf)或非数字(NaN)的错误值。一旦发生这种情况,整个量化过程便前功尽弃。
对于小模型,一个简单的“治标”方法是在Hessian矩阵的对角线上加上一个微小的常数来增加其稳定性。但对于动辄百亿参数的大模型,我们需要一种更“治本”的、釜底抽薪式的解决方案。
GPTQ的解决方案:用稳健的“分解”代替高风险的“求逆”
为了从根本上解决这个问题,GPTQ采用了数值线性代数中一种更高级、更稳健的矩阵处理技术——Cholesky分解(Cholesky Decomposition)。
它的核心思想是:与其直接跟难以捉摸的逆矩阵打交道,不如去跟其更稳定、更“友善”的分解形式打交道。
1.什么是Cholesky分解?
对于任何一个对称正定矩阵(Hessian矩阵通常满足此条件),我们都可以将其唯一地分解为一个下三角矩阵与其共轭转置 的乘积。即: 这个下三角矩阵被称为的Cholesky因子。Cholesky分解的过程在数值上是极其稳定的。
2.如何规避求逆?
在GPTQ的误差补偿计算中,我们经常需要求解形如这样的项。传统的做法是先求出,再做矩阵乘法。而GPTQ的做法是,将这个问题转化为求解一个线性方程组:。
将Cholesky分解代入,我们得到:。
这个问题可以通过两步非常稳定且高效的代换法来解决:
- • 第一步(前向代换): 令,我们先求解线性方程组得到。
- • 第二步(后向代换): 然后再求解线性方程组得到最终的解。
整个过程,我们完全没有进行任何一次矩阵求逆操作,而是用两次数值上高度稳定的求解三角方程组的操作来代替,从而从根本上避免了精度漂移的风险。
在GPTQ中的体现
GPTQ核心工作流程示意图
在GPTQ的实际算法流程中(如上图所示),它会在量化开始前,就先对Hessian矩阵进行一次Cholesky分解,并将结果(Cholesky因子)存储起来。在后续所有的迭代更新中,它都基于这个稳定的分解形式来进行计算。

GPTQ完整伪代码
在其最终的伪代码中,我们也可以看到Cholesky(H⁻¹)这样的步骤,这正是其数值稳定性得以保证的关键所在。
通过这三大加速创新,GPTQ成功地将OBQ这个“理论上的屠龙之术”,改造为了一个可以在大模型上高效运行的“实战利器”,为高精度的4-bit量化时代拉开了序幕。
1.4 优劣评析
GPTQ通过其精妙的误差补偿机制和一系列高效的工程优化,成功地将OBQ的理论带入了大规模实践,成为了4-bit权重量化领域的一座丰碑。然而,如同所有技术方案一样,它在获得巨大优势的同时,也存在其固有的局限性。
优点:
1.极高的量化精度:这是GPTQ最核心、最引以为傲的优势。得益于其严谨的、基于Hessian二阶信息的逐层误差补偿机制,GPTQ能够在将权重压缩至4-bit甚至3-bit的极端情况下,依然保持极高的模型性能。在许多评测中,GPTQ量化后的模型精度(W4A16)被认为是近乎无损的(near-lossless),是目前精度最高的4-bit权重量化方案之一。
2.出色的通用性:GPTQ的理论基础是通用的,不依赖于特定的模型架构。只要是包含线性层的Transformer模型,都可以应用GPTQ进行量化,这使其具有非常广泛的适用性。
缺点:
1.量化过程相对耗时:尽管比OBQ快了数个数量级,但GPTQ的量化过程仍然是一个相对“重”的操作。因为它需要:
- • 加载校准数据,并通过模型进行前向传播来计算Hessian矩阵。
- • 执行复杂的矩阵运算,如Cholesky分解和迭代更新。这使得其量化过程通常需要数小时,远比AWQ等更轻量级的方案要耗时。
2.强依赖于校准数据集:GPTQ的“精确雕刻”是建立在对模型在特定数据分布下行为的深刻理解之上的。这个理解,完全来自于校准数据集。Hessian矩阵的计算,直接依赖于输入数据。因此,如果校准集的分布与模型在真实应用场景中遇到的数据分布存在较大偏差,那么计算出的Hessian信息就可能是“错误”的,基于此进行的误差补偿效果也会大打折扣,从而影响最终的量化精度。
总结:GPTQ是一种典型的 “以时间换精度” 的高级量化方案。它不惜投入更多的离线计算资源,来换取最终模型近乎无损的性能表现。对于那些对模型精度有极致要求、且可以接受较长离线量化时间的场景,GPTQ无疑是4-bit权重量化的“王者之选”。
然而,GPTQ那略显复杂的理论和耗时的过程,也促使研究者们思考:有没有一种更简单、更快速的方法,也能达到类似的效果呢?另一位“高手”——AWQ,正是从一个完全不同的、更直觉化的角度,给出了它的答案。
二、 AWQ:激活感知的“重点保护”
如果说GPTQ像一位手持精密刻刀、遵循古典主义的“雕刻家”,那么AWQ(Activation-aware Weight Quantization)则更像一位洞察力敏锐、风格简约的现代主义“艺术家”。它不追求对每一个细节都进行像素级的修复,而是相信,只要抓住了事物的核心,就能以最少的笔触,还原出神韵。
2.1 核心思想:保护那“1%最重要”的权重
AWQ的核心哲学,源于一个简单而又深刻的观察:在一个庞大的神经网络中,并非所有权重都同等重要。
当我们将一个拥有数百亿参数的模型进行4-bit量化时,巨大的精度损失似乎是不可避免的。但AWQ的作者们反其道而行之,他们提出,我们或许并不需要让所有权重都“毫发无损”。模型的整体性能,可能并非由那99%的普通权重所决定,而是由其中一小部分、可能仅占总数0.1%到1%的 “显著权重” (Salient Weights)所主导。
这就如同在一支庞大的军队中,决定战役走向的,往往是少数几位运筹帷幄的“将领”,而非绝大多数的“士兵”。AWQ的策略就是,在资源有限(只能用4-bit)的情况下,我们应该集中所有“精良的装备”(即更高的量化精度),来武装这些关键的“将领”,确保他们的指挥能力不受影响。只要“将领”安然无恙,即便其他大量的“士兵”受到了一定的量化损失(装备从“铁剑”降级为“木棒”),整个军队的“核心战力”依然能得到很好的维持。
因此,AWQ将量化这个复杂的优化问题,巧妙地转化为了一个更简单、更聚焦的识别与保护问题。它的核心任务不再是“如何减少所有权重的平均误差”,而是转变为:“我们该如何准确地识别出那1%的‘将领’,并对他们进行重点保护?”
这个思想的转变,是AWQ所有技术细节的出发点,也引领我们走向下一个关键问题:我们到底该用什么标准,来衡量一个权重是否是“将领”之才呢?
2.2 动机与洞察:权重的“价值”由激活值决定
上一节我们确立了AWQ的核心思想——“保护关键少数”。现在,下一个问题自然是:我们到底该用什么标准,来识别出那“1%最重要”的权重呢?
传统的观点可能会认为,权重自身数值的绝对值越大,它就越重要。这很符合直觉,但AWQ的作者们通过实验发现,如果仅仅保留那些自身数值最大的权重,对最终模型精度的提升效果甚微。
这个发现促使他们从一个全新的、更深层次的角度去思考“重要性”的定义。他们提出了一个颠覆性的、也是AWQ算法的立身之本的核心洞察:
一个权重对于模型的“价值”,并非由其自身的“身价”(数值大小)决定,而是由它所处理的“业务”的重要性决定的。这个“业务”,就是与它相乘的激活值(Activation)。一个权重,哪怕自身数值很小,但如果它经常与大幅度的激活值相乘,那么它对模型的最终输出就有着举足轻重的影响,它就是真正需要被保护的“显著权重”。
这个洞察,可以通过下面这张关键的实验对比图得到完美印证。
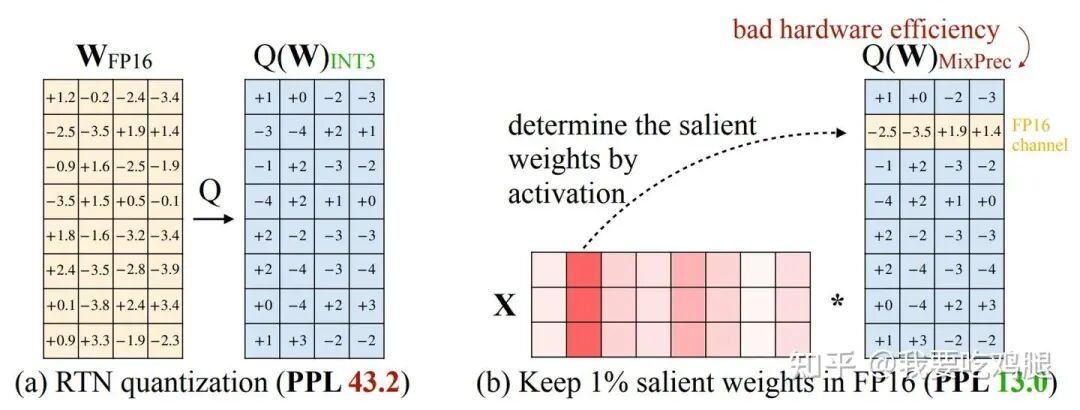
AWQ动机图
上图生动地展示了AWQ的完整思考过程:
(a) RTN量化: 首先,作者们尝试了最朴素的“四舍五入”(Round-to-nearest)4-bit量化方法。结果是灾难性的,模型的性能(用困惑度PPL衡量,越低越好)急剧恶化,PPL值高达43.2,说明模型几乎已经无法理解语言。
(b) 混合精度保护: 接下来,他们做了一个关键的验证实验。他们首先分析了激活值X的大小,找到了那些幅度最大的激活值通道,然后将权重W中与这些通道对应的部分(仅占总权重的1%),在量化时保持为高精度的FP16格式,而其余99%的权重依然量化为INT4。奇迹发生了,模型的PPL值骤降至13.0,几乎完全恢复了原始性能。
这个实验证明了两点:
1.洞察的正确性:由激活值大小决定的那一小部分权重,确实是模型性能的“命门”。
2.现有方案的困境:混合精度的方案虽然有效,但这又让我们陷入了LLM.int8()的老路——它需要特殊的计算核来处理,硬件效率低下(bad hardware efficiency),无法真正实现加速。
至此,AWQ要解决的核心问题已经昭然若揭:我们能否在不牺牲硬件效率(即不使用混合精度)的前提下,找到一种新的方法,来实现对这些由激活值决定的“显著权重”的重点保护呢?
AWQ给出的答案,是肯定的。它的解决方案,既优雅又高效,我们将在下一节详细拆解。
2.3 技术详解:激活感知的权重缩放
在上一节,我们面临一个棘手的两难困境:我们已经通过激活值的幅度,成功地识别出了那1%的“显著权重”,并且证明了用FP16高精度来保护它们,可以奇迹般地恢复模型性能。但这条路,又会让我们重蹈LLM.int8()的覆辙——牺牲硬件效率,无法真正实现加速。
AWQ的解决方案,堪称“神来之笔”。它与SmoothQuant有异曲同工之妙,但应用的动机和方式又截然不同。它也采用了缩放(Scaling)的技巧,但在不引入任何混合精度计算的前提下,巧妙地实现了对“显著权重”的重点保护。
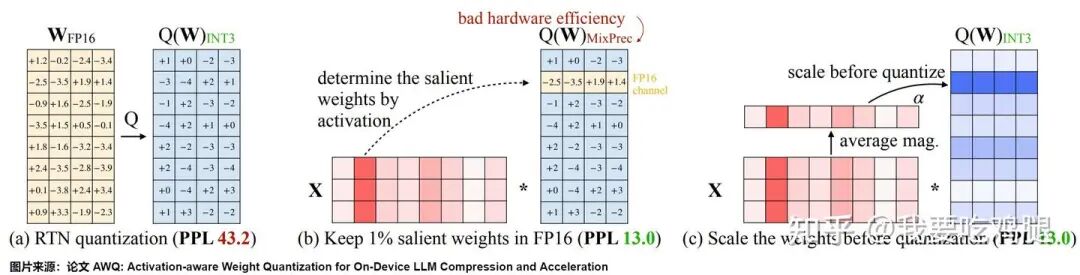
AWQ完整思想图
如果你也想通过学大模型技术去帮助自己升职和加薪,可以扫描下方链接【保证100%免费】👇👇
上图©部分清晰地展示了AWQ的最终解决方案,其核心机制可以分解为以下步骤:
第一步:识别显著通道
AWQ的第一步,是利用一小批校准数据,来执行它的“侦察”任务。它会分析激活值X的数值,并计算出每一个通道(channel)的平均激活值幅度。那些平均幅度最大的通道(如上图中X矩阵的红色高亮列),就被识别为 “显著通道” 。AWQ的理论认为,这些通道处理的是模型最重要的信息,因此与它们相对应的权重,就是需要被重点保护的“显著权重”。
第二步:对显著权重进行“预放大”
与SmoothQuant试图“削平”激活值的尖峰不同,AWQ的目标是“保护”权重的尖峰,确保它们在量化过程中不失真。它的做法是:
1.为这些被识别出的显著通道,计算一个缩放因子s > 1。
2.在量化之前,将这些通道内的权重值,统一乘以这个缩放因子s。
这个“预放大”操作,就如同在进行4-bit量化这种“有损压缩”之前,提前将最珍贵的“宝物”(显著权重)用“放大镜”看清楚,并为其准备一个更大的“保险箱”。
第三步:效果——给予关键权重更多“表示空间”
这个“预放大”操作的直接效果,就是在量化时,给予了这些显著权重一个更大的、更精细的表示范围。
- • 举个例子,一个原本在范围内的显著权重,在乘以缩放因子后,其范围被放大到了。
- • 当量化器用同样的16个等级(4-bit)去覆盖这个更大的范围时,原本拥挤在内的数值,现在可以在一个4倍大的空间里“舒展身体”,分配给它的有效精度自然就更高了,其信息得以更好地保留。
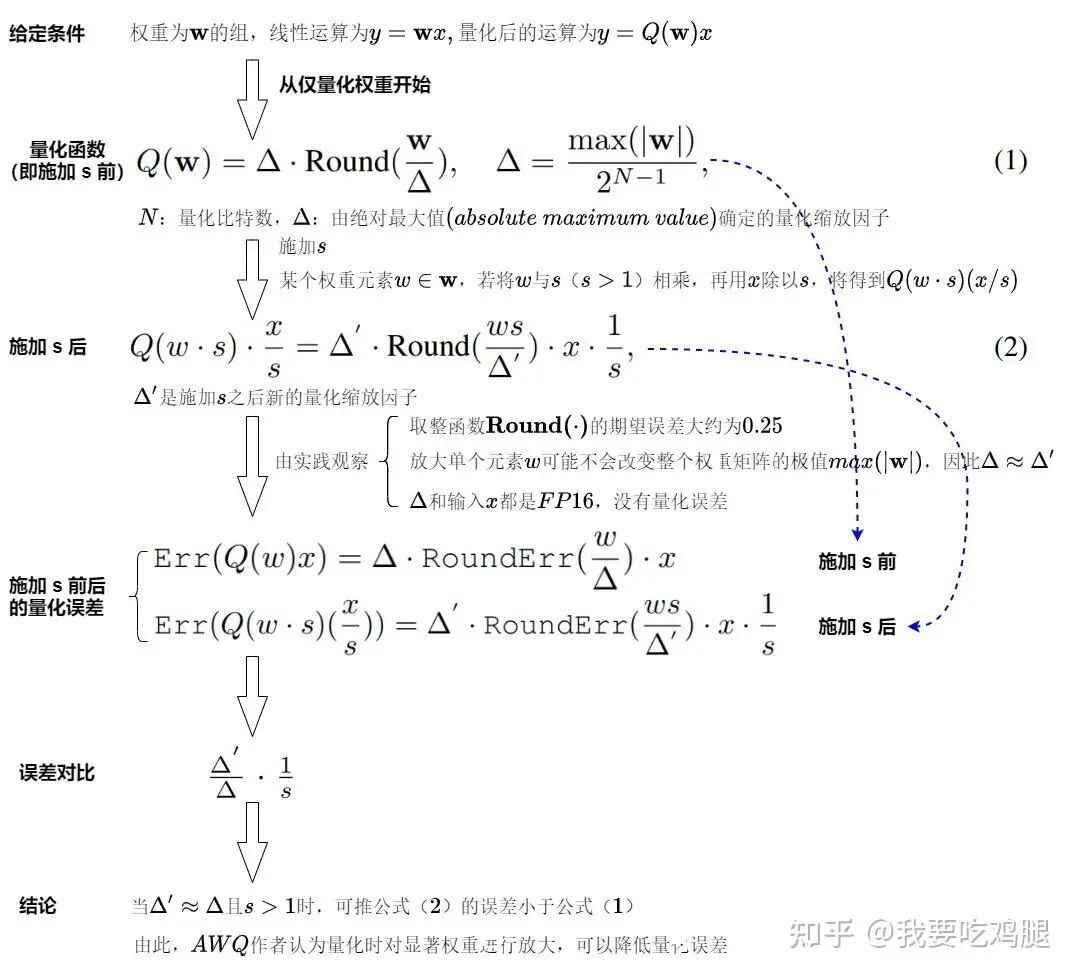
AWQ数学推导
上图从数学上严谨地推导了为何“量化前缩放”能够降低量化误差。它通过对比施加缩放因子s前后的量化误差公式,最终得出结论:当时,误差会减小为原来的1/s。
第四步:保持数学等价性
为了保持整个运算的数学等价性(),既然我们在量化前让权重乘以了,那么在实际计算时,就必须让对应的激活值 除以来抵消这个影响。
这个除法操作,同样可以被离线地融合(fuse) 到前一个计算层(如LayerNorm)中,因此没有额外的运行时开销,完美地保持了硬件友好性。
至此,AWQ通过一套优雅的“缩放”操作,成功地在不引入混合精度、不牺牲硬件效率的前提下,实现了对关键权重的保护。但还有一个关键问题悬而未决:这个至关重要的缩放因子s,到底应该取多大才最合适呢?
2.4 如何寻找最优缩放因子?
至此,AWQ的方案只剩下最后一块、也是最关键的一块拼图:我们已经知道了需要用一个缩放因子来“预放大”显著权重,但这个到底应该取多大才最合适呢?
如果太小,对显著权重的保护就不够,量化后精度损失依然很大。
如果太大,虽然显著权重被完美保护了,但这相当于极大地“压榨”了非显著权重的表示空间,可能会损害这些权重,导致整体性能下降。
AWQ寻找最优缩放因子的过程,也充分体现了其“简单高效”的哲学。它并非像SmoothQuant那样直接用一个固定的公式计算,而是通过一次快速的网格搜索(Grid Search)来确定。

AWQ优化目标与搜索空间
如上图公式(1)所示,理论上,我们希望寻找到一个最优的缩放因子向量,使得经过缩放、量化再反量化的层输出,与原始的层输出之间的误差最小。 然而,直接求解这个问题几乎是不可能的。因为量化函数包含了round(四舍五入)操作,这个操作是不可导的,所以我们无法使用梯度下降等常规的优化方法来直接求解最优的s,因此,AWQ做了一个巧妙的简化:
面对这个棘手的优化难题,AWQ再次展现了其“简单高效”的哲学。它没有去硬解那个复杂的公式,而是做了一个非常巧妙的简化:
1.核心假设: AWQ的作者们认为,一个通道的最优缩放因子,应该主要由该通道的激活值大小(这里的代表第j个通道激活值的平均幅度)来决定。
2.简化搜索空间: 基于这个假设,他们提出了一个极简的搜索关系(如上图公式2所示): 这个公式的魔力在于,它将一个极其复杂的问题——“寻找一个最优的、包含数千个元素的向量s”,降维打击成了一个极其简单的问题——“寻找一个最佳的、在[0, 1]之间的标量(单个数字)α”。
这里的,就如同我们之前在SmoothQuant中见到的迁移强度一样,是一个控制缩放力度的超参数。当时,,不进行任何缩放;当时,,进行最激进的缩放。
一旦问题被简化为寻找最优的α,解决方案就变得非常简单了。AWQ会进行一次快速的网格搜索:
- • 它会取一系列α的候选值,例如 。
- • 对于每一个候选的α值,它都会计算出对应的缩放因子s,并模拟量化过程,评估最终的量化误差。
- • 最后,那个能够使总误差最小的值,就被选为本次量化的“天选之子”。
通过这种“简化搜索空间 + 快速网格搜索”的策略,AWQ成功地在保持纯INT4计算、不牺牲硬件效率的前提下,实现了对关键权重的重点保护,最终达到了与GPTQ相媲美的高精度。
2.5 优劣评析
优点:
1.简单、快速、高效:这是AWQ最吸引人的地方。相比于GPTQ背后复杂的二阶数学和迭代补偿,AWQ的理念(保护由大激活值决定的权重)非常直观,实现相对简单。其量化过程主要涉及一次前向传播(用于收集激活值统计)和一次网格搜索,因此量化速度远快于GPTQ,能更快地完成对大模型的压缩。
2.精度表现出色:尽管方法更简单,但AWQ的“重点保护”策略被证明非常有效。在大量的公开评测中,AWQ量化后的模型(W4A16)在各项任务上的表现与GPTQ不相上下,甚至在某些模型上略有胜出。这使其成为当前最流行、效果最好的W4A16量化方案之一。
3.硬件友好:与GPTQ一样,AWQ最终产出的也是一个标准的INT4权重模型,可以被高效地部署在支持低比特推理的硬件上,享受访存带宽带来的加速。
缺点:
1.依赖核心假设:AWQ的成功,建立在“保护1%的显著权重就足够维持模型性能”这个核心假设之上。虽然这个假设在目前绝大多数的LLM上都得到了验证,但其普适性仍有待更多、更广泛的检验。对于未来可能出现的、具有不同激活值分布特性的新模型架构,这个假设是否依然成立,还是一个未知数。
2.同样依赖校准集:AWQ需要通过校准数据来分析激活值分布,从而确定哪些权重通道是“显著”的。因此,它也无法摆脱对高质量校准数据集的依赖。一个有偏差的校准集,可能会让它“保护”错对象,从而影响最终的量化精度。
总结:AWQ和GPTQ共同构成了当前4-bit权重量化领域的“双子星”。GPTQ代表了“数学最优”的路线,严谨、精确但耗时;而AWQ则代表了“启发式优化”的路线,简单、快速且效果惊人。它们从不同的哲学出发,却殊途同归,都为我们实现高精度的4-bit模型压缩提供了强大的武器。
在见识了这两种专注于“压缩存量知识”的PTQ方案后,下一节,我们将把目光投向一个更具革命性的领域:如何在已经量化的模型上,继续进行高效的“增量学习”?这便是QLoRA将
要为我们讲述的、关于量化与微调“珠联璧合”的精彩故事。
三、 QLoRA:量化与微调的“珠联璧合”
在我们详细剖析了GPTQ和AWQ这两种专注于推理时压缩(Inference-time Compression)的PTQ方案后,一个更深层次、也更具挑战性的问题浮出水面:
我们能否在一个已经被深度量化的、低精度的模型上,继续进行高效的“增量学习”或“微调(Fine-tuning)”呢?
这个问题至关重要。因为在真实世界中,我们很少直接使用基础大模型,而是需要针对特定的下游任务(如客服、医疗、法律等)对其进行微调,以注入领域知识。传统的全参数微调,需要为每个任务都保存一个完整的、巨大的模型副本,成本高昂。而像LoRA这样的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT) 技术,虽然大大降低了成本,但它通常要求基础模型保持在FP16高精度。
QLoRA(Quantized Low-Rank Adaptation)的出现解决了这个难题。它首次成功地将4-bit量化与低秩适配器(LoRA)这两种技术“珠联璧合”,实现了在被深度压缩的4-bit模型上进行高效微调的奇迹,革命性地降低了微调大模型的硬件门槛。
3.1 核心思想:在“冰层”上“搭暖房”
QLoRA的核心思想,可以用一个生动的比喻来形容——在“冰层”上“搭暖房”。
- • “冰层”——冻结的4-bit基础模型:QLoRA首先将一个庞大的、预训练好的基础模型,通过一种新颖的4-bit量化技术,压缩成一个体积小、精度低的“冰层”。这个“冰层”在整个微调过程中是完全冻结(Frozen)的,不参与梯度更新,因此几乎不消耗任何训练时的显存。
- • “暖房”——可训练的LoRA适配器:然后,QLoRA在这个冻结的“冰层”之上,嫁接一个(或多个)微小的、可学习的LoRA适配器。这个适配器就像一个轻便的“暖房”,它的参数保持在较高的精度(如BF16),并且是唯一在微调过程中需要更新的部分。
- • 工作流程:在微调时,梯度只在小小的“暖房”(LoRA适配器)中流动和计算,而冻结的“冰层”(4-bit基础模型)只负责提供基础的计算能力。这样,就以极低的显存开销,完成了对大模型的有效微调。
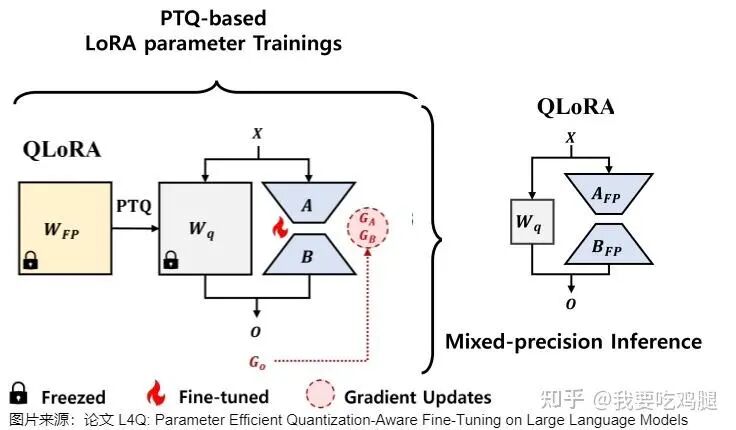
QLoRA训练与推理图
上图清晰地展示了这个过程。左侧的训练图中,基础权重被锁住(冻结),只有LoRA适配器和的参数在被更新(火焰标志)。
QLoRA的这种设计,就像是在一个巨大的、无法轻易改变的冰封大陆上,快速地搭建起一个个灵活、温暖的营地。我们无需融化整个大陆,就能在上面进行各种各样的科考和探索活动。这使得对大模型的“个性化定制”变得前所未有的轻便和高效。
3.2 技术详解:QLoRA的创新“全家桶”
QLoRA的成功,并非依赖单一的技术点,而是源于一个“全家桶”式的创新组合。它在量化数据类型、内存管理和参数组织等多个层面都进行了深度优化,才最终实现了在消费级GPU上进行大模型微调的奇迹。
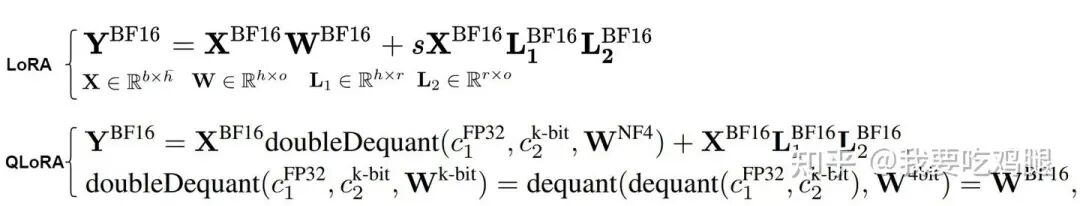
QLoRA数学公式对比
创新一:4-bit NormalFloat (NF4)量化
QLoRA要解决的第一个问题是:如何用区区4-bit(16个等级),尽可能无损地表示原本复杂的FP16权重?
标准的4-bit整数(INT4)虽然压缩率高,但它的量化等级是均匀分布的(例如,-8, -7, …, 7)。然而,神经网络的权重通常呈现一种中间密集、两端稀疏的正态分布(高斯分布)。如果强行用均匀的INT4去表示这种不均匀的分布,就会导致大量权重被量化到少数几个中心值上,而两端的大部分量化等级则被闲置,造成严重的精度损失和空间浪费。
为了解决这个问题,QLoRA没有采用标准的INT4整数,而是引入了一种专为正态分布数据量身打造的新型4-bit数据类型——NormalFloat (NF4)。
思想来源:分位数量化(Quantile Quantization)
NF4的核心思想,源于一种更先进的量化哲学——分位数量化。
标准量化的问题:标准的整数(Integer)量化,是将数值范围均匀切分。
分位数量化的目标:它不再关注数值范围,而是关注数据的分布。它的目标是确保量化后,每一个“桶”(量化等级)里都装进同样数量的原始数据点。这意味着,在数据密集的区域,量化等级会更“密”;在数据稀疏的区域,量化等级会更“疏”。
NF4的实现:理论最优的量化网格
QLoRA将“分位数量化”这个思想运用到了极致。既然神经网络的权重是正态分布的,那么理论上最优的量化点,就应该是标准正态分布的分位数。
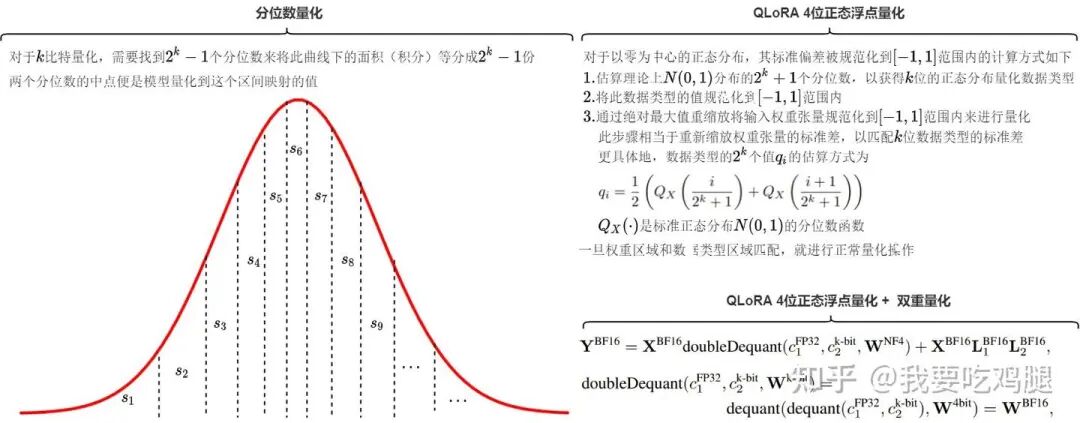
QLoRA的NF4量化与双重量化
QLoRA的作者们预先计算出了标准正态分布的16个等概率区间的分位点(如上图左侧所示),并将这16个点作为其固定的、不可更改的量化网格。
这意味着,NF4数据类型在信息论上,是表示正态分布数据的理论最优选择。在实际量化时,QLoRA的流程非常简单高效:
1.通过分块量化,为每个权重块计算出其缩放因子(通常是绝对值的最大值)。
2.用这个缩放因子,将该权重块的数据归一化到标准正态分布的范围内。
3.将归一化后的权重,四舍五入到离它最近的那个NF4分位点上。
通过这种方式,QLoRA确保了其4-bit的表示能力,被最大程度地用在了“刀刃”上,为高精度的4-bit微调打下了坚实的基础。
创新二:双重量化(Double Quantization)
在通过NF4数据类型解决了“如何用4-bit最高效地表示权重”的问题后,QLoRA的作者们将目光投向了一个通常被忽略、但积少成多后却异常可观的显存开销——量化参数(Quantization Constants)本身。
问题的提出:量化参数的“隐形成本”
为了提高精度,QLoRA采用了分块量化(Block-wise Quantization) 的策略,即不是为整个权重矩阵计算一个缩放因子,而是将权重分成小块(例如,每64个或256个权重为一块),并为每一个小块都计算一个独立的、高精度的缩放因子(通常是32-bit的浮点数)。
这个策略虽然有效,但也带来了一个“隐形成本”。我们来算一笔账:
- • 假设我们采用64的块大小,那么每64个4-bit的权重,就需要附带一个32-bit的缩放因子。
- • 平均到每一个参数上,其额外的显存开销就是:。
这意味着,在4-bit量化的基础上,我们还凭空多出了0.5 bit的开销,总成本变成了4.5 bit。对于一个70B的巨大模型来说,这0.5 bit就意味着数GB的额外显存占用!
解决方案:对“量化参数”再进行一次量化
为了将显存压缩到极致,QLoRA创造性地提出,对这些量化参数本身,再进行一次8-bit的量化。这个过程就叫做双重量化(Double Quantization)。
它的流程是:
1.第一次量化: 原始的FP16权重被量化为4-bit NF4,这个过程产生了一批第一级量化参数(即那些32-bit的缩放因子)。
2.第二次量化: 将这批“第一级量化参数”视为一个新的张量,再对它本身进行一次分块的8-bit量化,这个过程又会产生一批更少量的第二级量化参数。
3.效果:极致的显存节省
通过这个操作,每个参数的平均额外开销被大幅降低。以上面的例子计算,新的开销大约为:
相比于原来的0.5 bit,每个参数平均节省了约0.373 bit的显存。对于一个70B的大模型,这能额外节省出大约3GB的宝贵显存。
QLoRA的NF4量化与双重量化
上图右下角的公式中,doubleDequant函数就精确地描述了这个过程:它首先对第二级量化参数进行反量化,得到第一级量化参数,再用第一级量化参数对4-bit权重进行反量化,最终恢复出BF16格式的权重。
通过“双重量化”这项技术,QLoRA将量化压缩的理念贯彻到了极致,真正做到了“锱铢必较”,为在消费级硬件上微调大模型扫清了又一障碍。
创新三:分页优化器(Paged Optimizers)
在通过NF4量化和双重量化将模型的静态显存占用压缩到极致后,QLoRA还面临着最后一个棘手的工程挑战:如何应对在微调过程中,那些“神出鬼没”的显存峰值(Memory Spikes)?
问题的提出:“瞬间爆表”的显存危机
在使用梯度检查点(Gradient Checkpointing)等节省显存的技术来微调大模型时,模型的平均显存占用可能并不高。然而,在训练的某些特定阶段(例如,在反向传播过程中重新计算激活值时),显存的使用量会瞬间飙升。
这个短暂的显存峰值,就像一个突然涌来的“巨浪”,即使它只持续一瞬间,也足以冲垮硬件的显存上限,导致整个训练过程因为OOM(Out-of-Memory)错误而崩溃。这意味着,很多时候我们无法成功微调一个模型,不是因为“平均”显存不够,而是因为无法承受这瞬间的“浪涌”。
解决方案:引入操作系统的智慧——“虚拟内存”
为了解决这个问题,QLoRA引入了NVIDIA的“分页优化器(Paged Optimizers)”技术。这个技术的思想,与我们计算机操作系统中的虚拟内存(Virtual Memory)或页面交换(Paging)机制如出一辙。
我们可以做一个形象的比喻:
- • GPU显存(VRAM):就像我们电脑里速度飞快但容量有限的内存条(RAM)。
- • CPU内存(DRAM):就像我们电脑里速度稍慢但容量巨大的硬盘(SSD/HDD)。
分页优化器的工作流程是:
1.监控:它会实时监控GPU显存的使用情况。
2.“分页换出”(Page Out):当它预测到即将发生一次显存峰值,可能会导致显存溢出时,它会自动地、智能地将那些暂时用不到的数据(主要是优化器的状态,如动量、方差等),从宝贵的GPU显存中,“换出”到容量充裕的CPU内存中去“暂存”。
3.“分页换入”(Page In):当内存密集型的计算步骤完成后,显存峰值消退,优化器需要进行权重更新时,再将之前暂存到CPU内存中的状态,“换入”回GPU显存中。
4.效果:“削峰填谷”,保证训练稳定 通过这种在GPU和CPU之间智能地、自动化地“腾挪”数据的机制,分页优化器有效地“削平”了显存使用的峰值,将原本可能导致崩溃的“巨浪”,抚平为平缓的“波浪”。
这个机制是QLoRA能够宣称“在单张24GB显卡上就能微调65B模型”的底气所在。它极大地提升了训练过程的鲁棒性(Robustness),确保了微调任务不会因为偶然的显存波动而前功尽弃。
至此,QLoRA的三大核心创新我们已剖析完毕。正是通过NF4量化、双重量化和分页优化器这套精妙的“组合拳”,QLoRA才最终完成了这项看似不可能的任务,为大模型的个性化微调,开启了一个全新的、低门槛的时代。
3.3 优劣评析
QLoRA通过将4-bit量化与LoRA微调的巧妙结合,成功地解决了“如何在资源有限的情况下,让大模型继续学习”的世纪难题,对整个AI应用生态产生了深远的影响。
优点:
QLoRA的最核心的贡献,是极大地降低了微调大语言模型的硬件门槛。
在QLoRA出现之前,想要微调一个数十亿参数的LLM,通常需要一个由多张昂贵的、企业级的A100/H100 GPU组成的集群。而QLoRA通过其极致的显存优化技术,使得在单张消费级GPU(例如24GB显存的RTX 4090)上微调数十亿甚至上百亿参数的模型成为了可能。
这彻底改变了LLM的应用生态,开启了“人人可微调”的新时代。开发者、研究人员和中小型企业不再需要望“巨模”而兴叹,而是可以利用自己手边的有限资源,为基础大模型注入特定的领域知识,创造出各种各样定制化的、垂直领域的AI应用。从这个角度看,QLoRA是近年来LLM社区最具影响力的工作之一。
缺点:
然而,我们也必须清醒地认识到QLoRA的局限性。它最大的“缺点”在于,其本质上是一种训练/微调技术,而非推理优化方案。
- • 推理时无直接加速:虽然它使用了4-bit量化来降低训练成本,但在推理时,为了将LoRA适配器学习到的“增量更新”()与原始模型权重W相加,4-bit的基础权重W_q仍然需要被反量化(Dequantize)回与LoRA适配器相同的高精度(如BF16)。
- • 推理时内存未减小:同理,因为需要反量化回高精度进行计算,其在推理时所占用的显存,与一个用标准LoRA微调后的FP16模型是基本相同的。
这意味着,QLoRA能帮你“用更少的资源训练出你的模型”,但它并不能直接帮你“用更少的资源运行你的模型”。后续的研究(例如,对LoRA适配器本身再进行量化)正在尝试解决这个问题,但这已超出了原始QLoRA的范畴。
总结:QLoRA的伟大,在于它巧妙地利用量化技术作为一种“手段”,去解决了“微调”这个“目的”。它虽然没有直接优化推理性能,但通过极大地降低学习和定制大模型的门槛,为整个AI应用的繁荣和创新,打开了一扇前所未有的宽阔大门。
四、 FlatQuant:学习最优变换来“夷平”异常值
在我们领略了GPTQ的精确、AWQ的敏锐和QLoRA的灵动之后,4-bit量化战场上还有一位追求极致的“全能型选手”——FlatQuant。它的目标,是挑战4-bit量化中最艰难的任务:W4A4全量化(即权重和激活值均为4-bit)。
4.1 动机:现有变换的局限性
FlatQuant认为,已有方法大多使用 pre-quantization transformations,通过在量化前对权重和激活值做等价变换得到更平坦的分布来降低量化误差,对于“夷平”异常值来说,无论是SmoothQuant的简单缩放,还是其他更复杂的固定变换,都并非最优解,我们结合下面的图来看看这是为什么。
1. Per-channel Scaling (例如 SmoothQuant): 局限的“跨坡搬运”
这种方法通过引入一个缩放因子,将激活值上的离群值“转移”到权重的相同通道上。
- • “搬土”类比:这相当于我们只能把左边土坡上某个位置的土,挖到右边土坡上完全相同的位置去。
- • 局限性:这种操作非常受限。离群值的影响仅仅是在权重和激活值的同一通道之间来回移动,并没有被真正地“分散”和“消化”。那些没有离群值的“非离群值通道”完全没有被利用起来。结果就是,离群值的问题依然存在,只是从激活值这个“坡”上,转移到了权重那个“坡”上而已。从下方 LLaMA-3-8B 的可视化结果 (a) 可以清晰地看到,变换后的激活值分布依然非常陡峭,存在明显的“山峰”。
2. Hadamard Transform: 固定的“坡内重整”
Hadamard变换是一种正交变换,它尝试将离群值重新分配到权重或激活值内部的其他通道上。
- • “搬土”类比:这相当于我们只能在单个土坡的内部,把高处的土挖到低处去,但不能把土从一个坡转移到另一个坡。
- • 局限性:变换方式单一:Hadamard变换对所有层都使用完全相同的“搬土”模式。但不同层的“土坡”形状(数据分布)千差万别,用同一种固定的方式去处理所有坡,效果自然不会是最优的。
- • 无法平衡难度:正交变换有一个性质,它不改变向量的模长。激活值中的大量离群值导致其整体模长远大于权重。因此,即便经过变换,激活值的量化难度依然显著高于权重。它不像 Per-channel Scaling 那样,可以灵活地在两个“坡”之间平衡量化难度。
对关键信息(Pivot Token)的伤害
这些变换的另一个致命缺陷在于,它们无法很好地处理对模型性能至关重要的关键词元(Pivot Token),例如输入序列的第一个词元。这些词元上往往存在着大量的离群值。从实验数据中可以看到,无论是 Per-channel Scaling 还是 Hadamard 变换,在处理这些关键信息时都会产生巨大的量化均方误差(MSE),严重影响模型性能。
它提出,我们应该更进一步,为模型的每一层学习(Learn) 一个独一无二的、最优的仿射变换(Affine Transformation),来让权重和激活值的分布同时达到最理想的“平坦”状态,也就是为每一个“土坡”学习和定制一把最优的“铲子”。
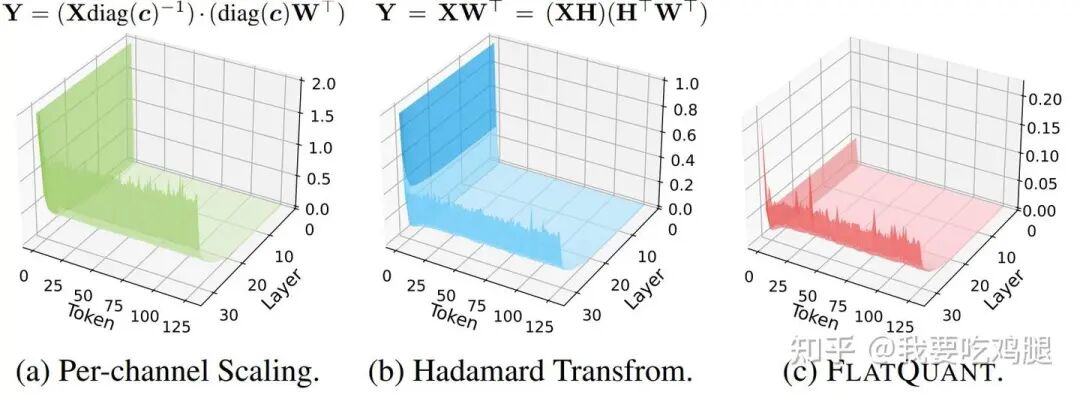
FlatQuant效果对比图
上图是FlatQuant最核心的动机证明。它通过3D可视化,清晰地展示了:
- • (a) Per-channel Scaling (如SmoothQuant):这种方法虽然能平滑一部分异常值,但其能力有限,变换后的激活值分布依然存在明显的“山峰”。
- • (b) Hadamard Transform (一种正交变换):这种方法同样无法完美地处理所有情况,变换后的分布依然“陡峭”。
- • © FLATQUANT: 只有通过FlatQuant学习到的、为该层量身定制的仿射变换,才能真正将激活值的分布“夷为平地”,为后续的4-bit量化创造最理想的条件。
4.2 核心思想与技术挑战:学习一个最优的仿射变换
FlatQuant的核心思想,是将在“变换派”的道路上走得最远、最彻底。它认为,无论是SmoothQuant基于规则的缩放,还是其他固定的变换,都只是对“最优变换”的一种“近似”。为了追求极致的平坦分布,我们应该让模型自己去 学习(Learn) 一个最适合每一层的、独一无二的仿射变换(Affine Transformation)。
这个思想,在数学上可以被优雅地表示为:在矩阵乘法中,插入一个可逆的仿射变换矩阵P,使得:
我们的目标,就是通过在校准集上进行优化,为每一层都找到一个最优的,使得变换后的激活值和变换后的权重,它们的数值分布都-变得极其平坦,从而为后续的4-bit量化创造最理想的条件。
然而,这个雄心勃勃的想法,面临着一个巨大的、近乎致命的工程挑战:
- • 变换后的权重,可以在量化前离线计算好,不会增加推理开销。
- • 但是,变换后的激活值,这个计算必须在在线推理时进行。
如果是一个与X和W同等大小的完整稠密矩阵(例如,),那么计算这一步,就相当于在原有的矩阵乘法之外,额外增加了一次同等规模的矩阵乘法! 这会导致计算量和存储开销翻倍,完全违背了我们进行量化以“提速降本”的初衷。
如何破解这个“额外开销”的魔咒,是FlatQuant方案能否成立的关键。
技术详解:Kronecker(克罗内克)分解的妙用
为了解决这个挑战,FlatQuant采用了一种精妙的数学技巧——Kronecker分解(Kronecker Decomposition)。

FlatQuant的Kronecker分解
如上图所示,FlatQuant并不直接学习一个巨大的稠密矩阵P,而是将其近似分解为两个更小的矩阵和的Kronecker积:
这个操作的魔力在于,它极大地减少了需要学习和存储的参数量,并相应地降低了计算复杂度。
- • 参数量的“降维打击”:
- • 假设原始的变换矩阵大小为,那么它有个参数。
- • 如果我们令,并将P分解为大小为的和大小为的。那么我们只需要学习和存储个参数。
- • 当我们选择时,参数量就从惊人地下降到了!
- • 计算量的优化:
利用Kronecker积的数学性质,原本需要计算量的在线变换,现在可以通过一系列巧妙的reshape和更小的矩阵乘法来高效完成,其计算开销也随之大幅降低。
通过Kronecker分解这个“四两拨千斤”的技巧,FlatQuant成功地将学习一个最优仿射变换的代价,降低到了一个完全可以接受的水平,从而使其在理论和实践上都变得可行。
4.3 整体架构与优劣评析
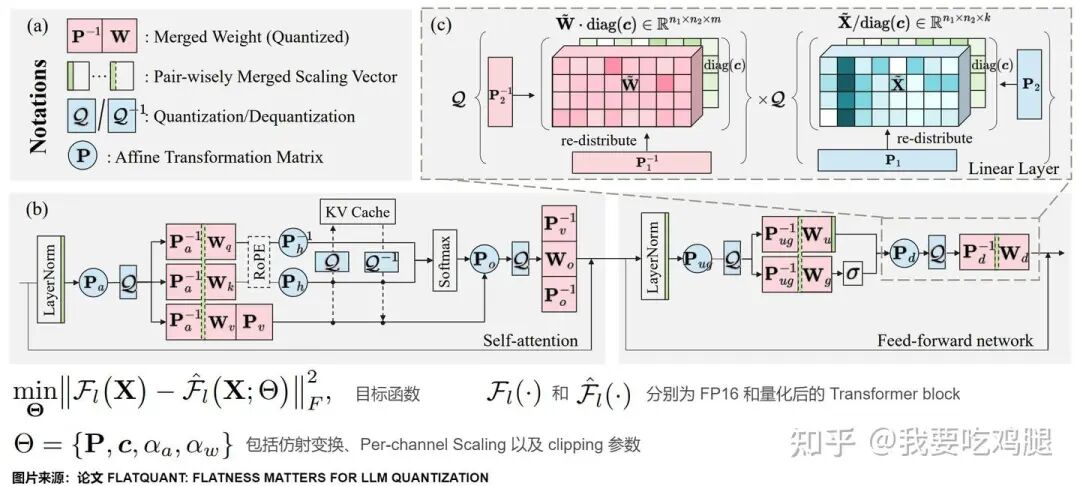
FlatQuant整体架构图
FlatQuant的最终方案,是为Transformer中的每一个线性层都配备一套通过Kronecker分解学习到的、轻量级的仿射变换。
优点:
- • 精度极高:通过学习最优变换,FlatQuant在极具挑战性的W4A4全量化任务上,取得了当前最好(State-of-the-art)的性能,显著优于其他PTQ方法。
缺点:
- • 实现更复杂:相比GPTQ和AWQ,它引入了一个额外的、基于学习的优化步骤,实现和部署的复杂度更高。
总结:FlatQuant代表了“转移派”量化思想的终极形态。它不再满足于固定的变换规则,而是通过“学习”为模型量身定制最优的“平滑”方案,为高精度的超低比特全量化,开辟了一条全新的、充满潜力的道路。
最后
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
如果你也想通过学大模型技术去帮助自己升职和加薪,可以扫描下方链接【保证100%免费】👇👇
为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
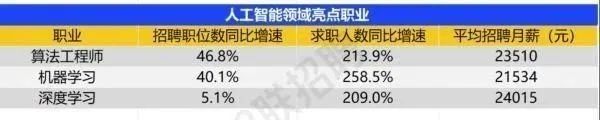
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**



















 1474
1474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











