



最好的学习时间是昨天,其次是现在。清明节的第一天,窗外春风拂面,阳光洒满大地,大家是不是已经迫不及待想放松一下心情了?不如趁着假期,我们一起来聊聊RAG!如果你已经完全掌握了RAG原理,请帮我看看我讲的和你理解的是否一致。最近,像 coze 和 dify 这样的低代码平台把 RAG 功能做得越来越亲民,但想要真正玩转它,搞清楚背后的流程可是关键,不做文档搬运工。今天,我就带你一步步拆解 RAG 系统,用最轻松的方式告诉你,它是怎么让大语言模型(LLM)变得更聪明、更贴心的。
一、RAG系统:智能问答的秘密武器
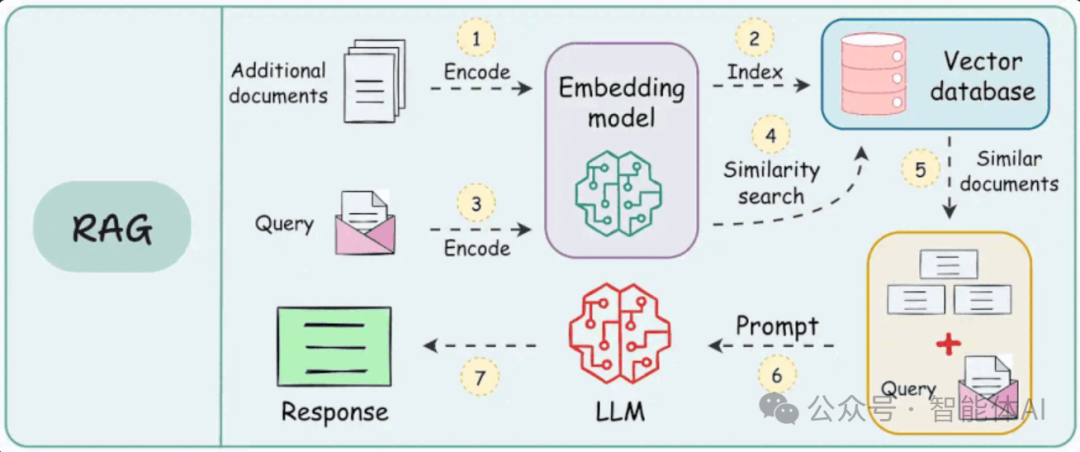
RAG 系统是什么?简单来说,它就像一个超级能干的“知识管家”:一边从海量的外部资料里翻出你需要的“干货”,一边用大语言模型的“语言魔法”把这些干货整理成清晰、自然的回答。RAG 的魅力——“检索+生成”双剑合璧,让智能问答不再是冷冰冰的机器回复,而是温暖又靠谱的对话体验。接下来,我们就来拆开 RAG 的“魔法书”,看看它到底是怎么一步步施展魔法的。
二、RAG系统的核心环节
简单来说,RAG 系统就是一种“检索+生成”的组合拳。它能从海量的外部知识中挖出有用的信息,再借助大语言模型的语言天赋,把这些信息整理成清晰、自然的回答。想象一下,它就像一个知识渊博又会讲故事的朋友,既能找到你需要的内容,还能用最舒服的方式讲给你听。
下面,我们就来拆解 RAG 系统的工作流程,看看每个环节是怎么串起来的。
1. 文本分块:把大书拆成小页
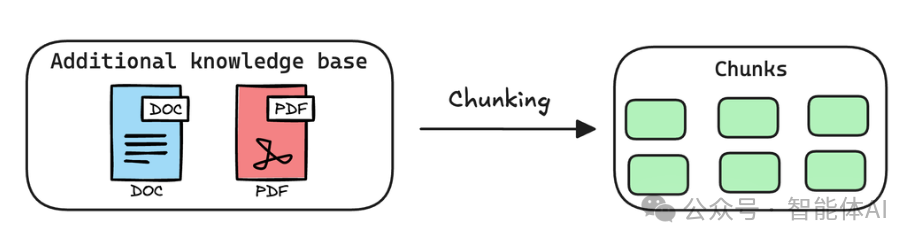
假设你有一本超级厚的书,里面全是知识,但每次查东西都要翻完整本书,太麻烦了。所以,第一步就是把这本书拆成一页一页的小块,也就是“文本分块”。
为什么要这么做呢?有三个原因:
-
文档太大不好处理:有些资料可能有几百页,直接扔进去分析,电脑也吃不消。
-
模型有长度限制:就像我们吃饭得一口一口来,嵌入模型也只能一次处理有限的文字量。
-
方便找重点:如果整本书只有一个标签,查东西时就很难精准找到相关内容。
所以,文本分块就像是给知识“切片”,让后续步骤更顺利。
2. 生成嵌入:给每页书贴上“标签”
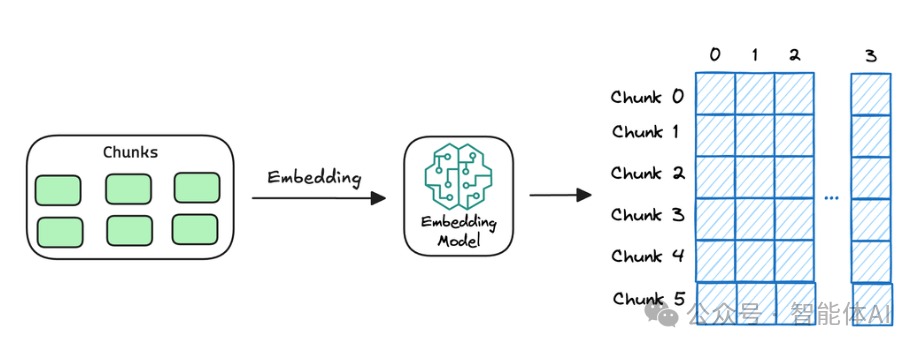
分好块之后,我们需要给每个文本块贴上一个特殊的“标签”,这个标签其实是一串数字,叫“嵌入向量”。生成这个向量的工具就是嵌入模型,它能把文字的意思浓缩成数字形式。
举个例子,这就像给每页书打上一个独一无二的“指纹”,通过这个指纹,我们就能快速判断这页书讲的是什么。后面找资料的时候,靠这些指纹就能快速匹配。
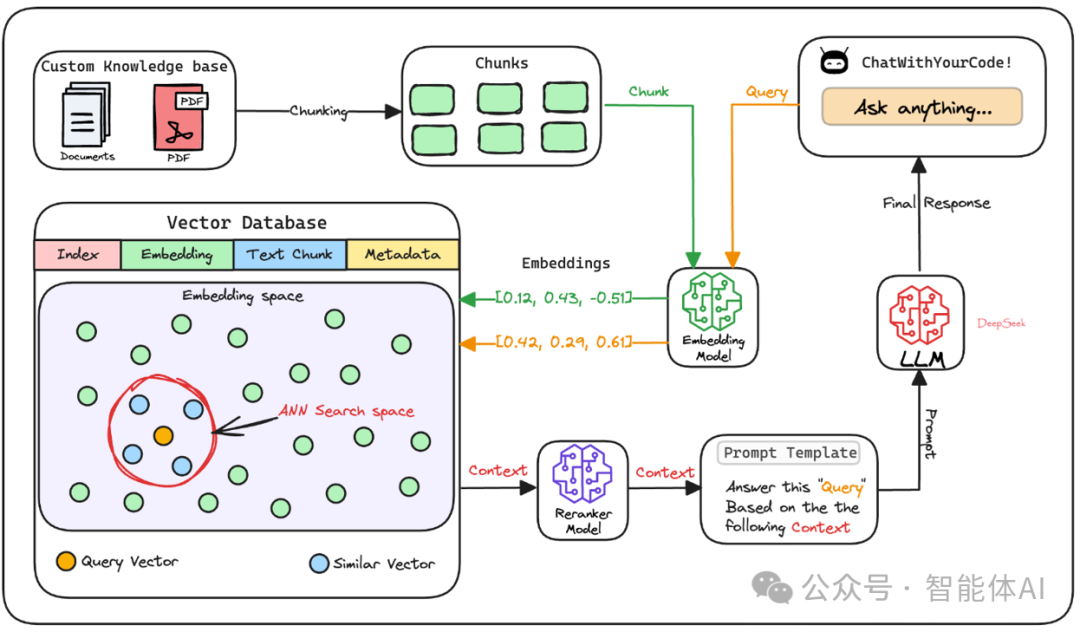
3. 向量数据库存储:建一个“记忆仓库”
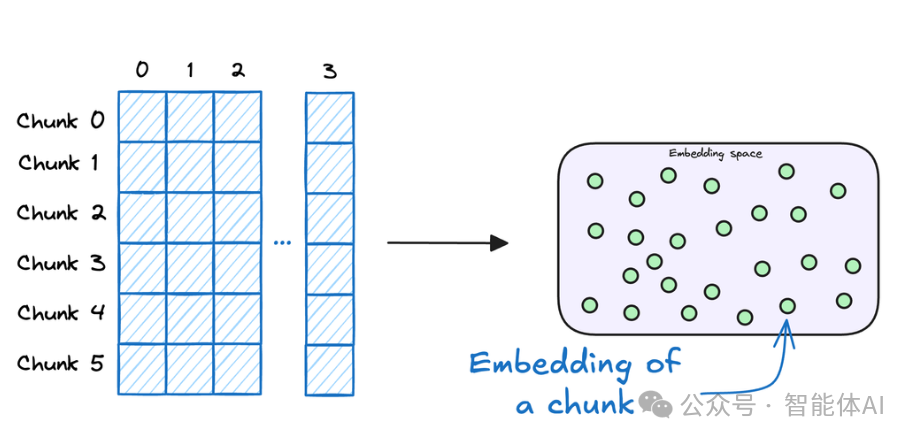
有了这些数字指纹,我们得找个地方存起来,这就用到了向量数据库。你可以把它想象成 RAG 系统的“记忆仓库”,里面装满了所有文本块的指纹和原始内容。
这个仓库不只是个储物柜,它还能随时接收新资料,保持知识的更新。以后用户提问时,系统就会从这里翻出最相关的“记忆”来回答。向量数据库里不仅存了数字指纹,还保留了原始文本和一些附加信息,方便随时调用。
4. 用户输入查询:提问时间到!
好了,准备工作做完了,现在轮到用户上场了。用户输入一个问题,比如“RAG 系统是啥?”——这就正式开启了查询阶段。
5. 查询向量化:问题也得有“指纹”
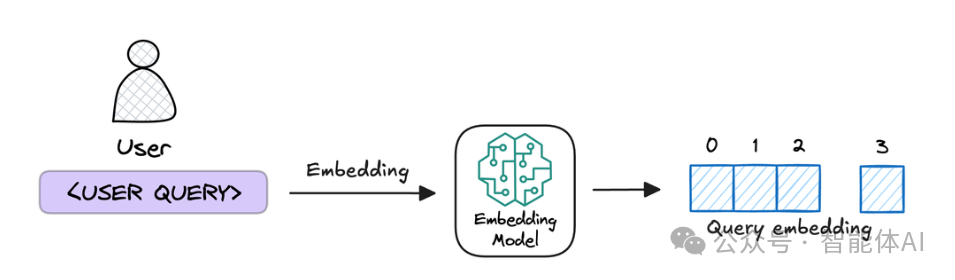
为了找到答案,我们得把用户的问题也变成数字指纹。用的还是那个嵌入模型,这样问题和数据库里的文本块就有了“共同语言”,可以互相匹配了。
6. 检索相似块:翻出最相关的资料
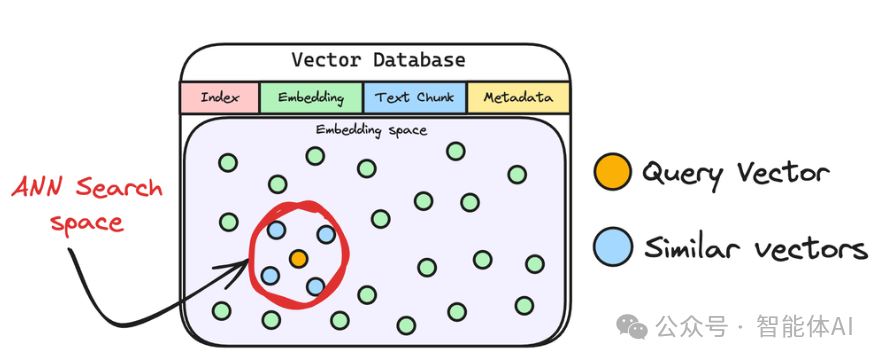
接下来,系统会拿着问题的指纹,在向量数据库里找“最像”的文本块。
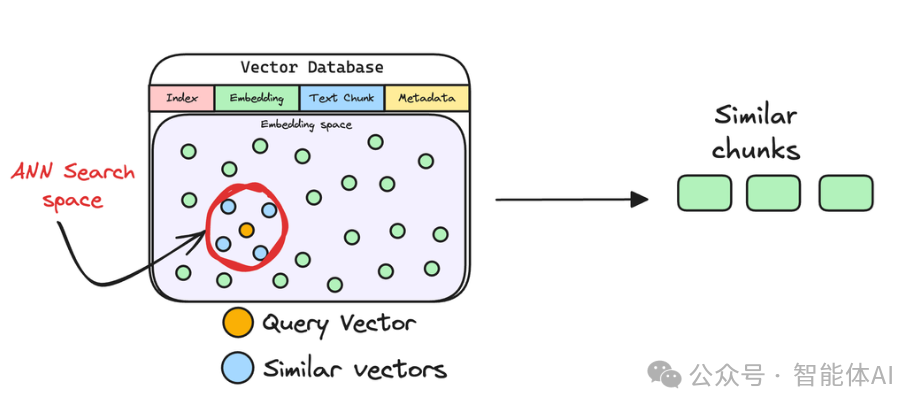
具体来说,它会挑出 K 个最相似的块(K 是提前设好的数量),这些块里很可能藏着问题的答案。这一步通常会用一种叫“近似最近邻搜索”的方法,速度快得像闪电。
7. 结果重排序(可选):再精挑细选一下
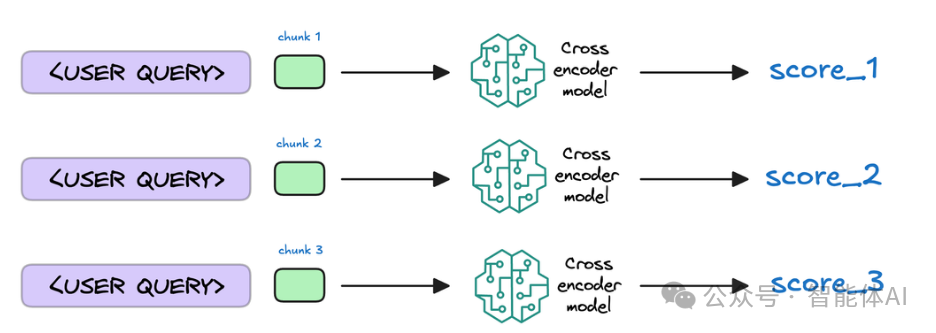
有时候,为了让答案更靠谱,系统会对找出来的文本块再排个序。这就像从一堆答案里挑出最贴切的几个,通常会用更厉害的模型(比如交叉编码器)来打分排序。不过,不是所有 RAG 系统都会这么做,很多直接用上一步的相似度结果就够了。
8. 生成最终响应:答案新鲜出炉
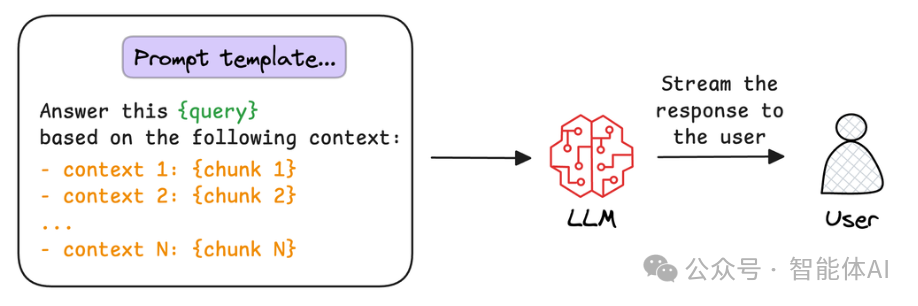
最后,把挑好的文本块交给大语言模型。模型会根据一个模板,把用户的问题和这些资料糅合在一起,生成一个既准确又自然的回答。整个过程就像厨师炒菜,原料是检索来的知识,火候是大语言模型的语言功底,最后端上桌的就是一道美味的答案。
三、总结
看完这8个步骤,RAG 系统的全貌是不是清晰多了它通过文本分块、嵌入生成、向量存储和检索生成这几步,把外部知识和大语言模型的能力完美结合了起来。结果呢?用户不仅能得到答案,还能收获更全面、更贴心的信息。
RAG的三大杀手锏
-
知识新鲜:随时更新数据库,答案永远不过时。
-
回答靠谱:检索机制确保不胡说八道。
-
用途超广:智能客服、学习助手,哪儿都能用!
希望下次聊到智能问答,你也能拍胸脯说:“这我熟!”,你不仅会操作还能讲原理。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











