






1 背景
当业务数据在单表存储达到一定的数量级时,此时对表创建索引是要花费时间的。GaussDB为了解决这个问题采用并行创建索引技术,以提高创建索引的效率。
2 示例
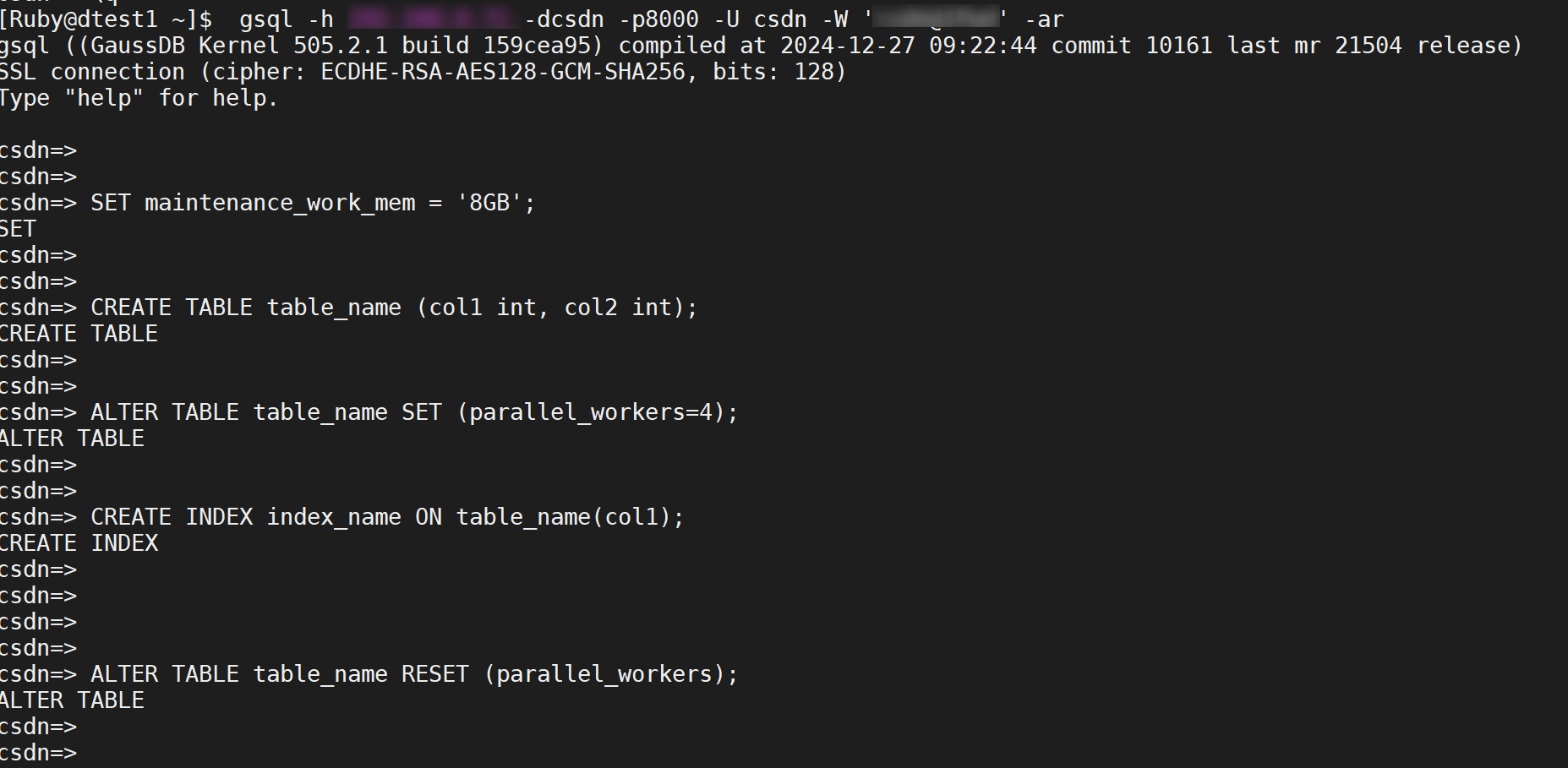
步骤1:根据实际情况调整maintenance_work_mem参数该大小。
[Ruby@dtest1 ~]$ gsql -h xxx.xxx.x.71 -dcsdn -p8000 -U xxx -W '*******' -ar
gsql ((GaussDB Kernel 505.2.1 build 159cea95) compiled at 2024-12-27 09:22:44 commit 10161 last mr 21504 release)
SSL connection (cipher: ECDHE-RSA-AES128-GCM-SHA256, bits: 128)
Type "help" for help.
csdn=>
csdn=>
csdn=> SET maintenance_work_mem = '8GB';
SET
csdn=>
csdn=>
步骤2:创建测试表
gaussdb=# CREATE TABLE table_name (col1 int, col2 int);
步骤3:修改表创建索引的线程数量,需根据实际情况修改线程数。
ALTER TABLE table_name SET (parallel_workers=4);
步骤4:创建索引
CREATE INDEX index_name ON table_name(col1);
步骤5:重置该表的parallel_workers参数
ALTER TABLE table_name RESET (parallel_workers);
执行结果:
3 批注
GaussDB支持并行创建索引技术,以提高创建索引的效率。

















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









