






yolov8模型训练
环境下载
安装好anaconda后>Environments>create>创建新的虚拟环境,并附名>Channels输入镜像源>点击绿色按钮,打开终端Open Terminal
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple pip config set install.trusted-host pypi.tuna.tsinghua.edu.cn pip install yolo pip install ultralytics pip install labelimg # 标注工具 pip install ncnn
终端输入
yolo进行验证训练检测模型:训练一个 YOLOv8 检测模型,使用 yolo train 命令,指定数据、模型文件、训练轮数和初始学习率: yolo train data=coco8.yaml model=yolov8n.pt epochs=10 lr0=0.01 预测视频:使用一个预训练的分割模型对 YouTube 视频进行预测,指定图像大小: yolo predict model=yolov8n-seg.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320 验证模型:对一个预训练的检测模型进行验证,设置批次大小和图像大小: yolo val model=yolov8n.pt data=coco8.yaml batch=1 imgsz=640 导出模型:将 YOLOv8 分类模型导出为 ONNX 格式,指定图像大小: yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128 数据集探索:使用 Ultralytics Explorer API 浏览数据集,支持语义搜索和 SQL 查询: yolo explorer data=data.yaml model=yolov8n.pt 实时摄像头推理:使用 Streamlit 启动一个实时摄像头推理界面: yolo streamlit-predict 特殊命令, 用于查看帮助、检查、版本等信息: yolo help yolo checks yolo version
新建训练目录
新建文件夹yolotrain/
images/
test/ 测试文件夹
train/ 训练文件夹
val/ 验证文件夹
将准备好的图片放到 images/train 文件夹,下面并且复制一份到 images/val 和 images/test两个文件夹
labels/
-
train/ -
val/
存放标注的数据
标注数据
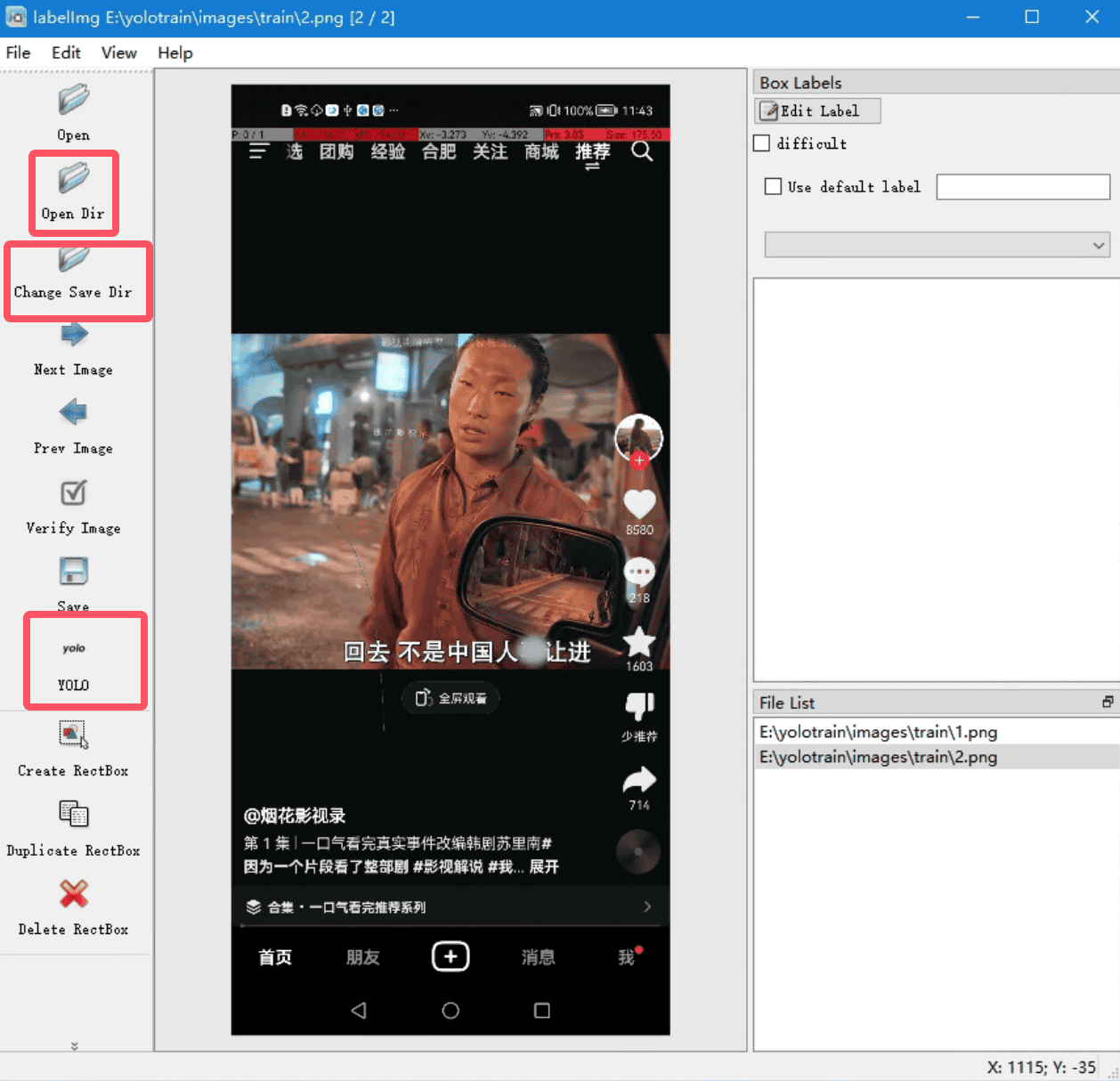
cmd输入labelimg
点击 Open Dir 按钮,选择到你的 images/train 文件夹即可,例如 E:/yolotest/images/train
点击 Change Save Dir 按钮,选择到你的 labels/train 文件夹即可,例如 E:/yolotest/labels/train
点击Save 下面的格式按钮,调整到 YOLO 格式的模式即可,请看下图
下面开始标注数据
例: 某音 点赞 评论 按钮
在图片上右键菜单,选择 Create RectBox 选项,或者点击左侧的 Create RectBox
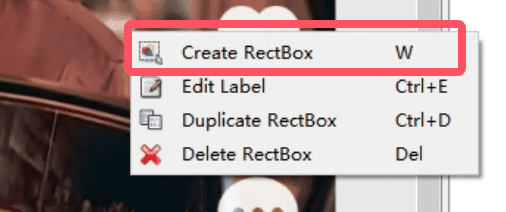
在 点赞 图片区域拉出选框,输入分类名称,点击ok保存
在 评论 图片区域拉出选框,输入分类名称,点击ok保存
第一个图片标注完成后,点击左侧的 Save 按钮保存,然后点击 Next Image 切换标注下一张图片
图标标注保存后,会在 labels/train 文件夹存储了标注的数据,classes.txt内容就是分类名称,其他的是和图片相同的名称的txt标注文件
将 labels/train 文件夹数据复制到 labels/val 文件夹,验证模型的时候使用
训练模型
在 yolotrain 文件下新建一个训练的配置文件,例如文件名称叫 aixin.yaml,使用记事本打开,填写内容如下
path: E:/yolotrain # 训练的根目录 train: images/train val: images/val test: images/test nc: 2 # 分类 names: ["aixin","pinglun"] # 类名,名称的顺序不要写错会影响训练结果# yaml文件 path: D:\Pydemo\yolotrain # 训练的根目录 train: images/train # 训练集图像文件夹 val: images/val # 验证集图像文件夹 test: images/test # 测试集图像文件夹(可选) nc: 1 # 分类数 names: ["object"] # 类名,更具描述性的名称 # 添加训练参数 train: batch_size: 16 # 根据您的GPU内存调整 epochs: 20 optimizer: Adam # 或SGD lr0: 0.01 # 初始学习率 lrf: 0.1 # 学习率衰减因子 augment: hflip: 0.5 # 水平翻转概率 vflip: 0.5 # 垂直翻转概率 rotate: 10 # 旋转角度 scale: [0.9, 1.1] # 缩放因子 translate: 0.1 # 平移因子
开始训练
在cmd(必须为虚拟环境终端)窗口,输入 d:/ 回车,在输入 cd /Pydemo/脚本/yolov8/yolotrain
训练命令,下面两个任选一个,截图参数看ultralytics官网
yolo detect train data=D:/Pydemo/脚本/yolov8/yolotrain/douyin.yaml model=D:/Pydemo/脚本/yolov8/yolotrain/yolov8s.pt imgsz=640yolo detect train data=D:/Pydemo/脚本/yolov8/yolotrain/douyin.yaml model=D:/Pydemo/脚本/yolov8/yolotrain/yolov8s.pt epochs=20 imgsz=640 # epochs训练次数import torch from ultralytics import YOLO #---------- #from ultralytics import YOLO #model = YOLO("yolov8n.yaml") # 这里以yolov8n的配置文件为例,可根据实际需求选择不同配置 #model.train(data="your_data.yaml", epochs=100) # 指定训练数据配置文件及训练轮数 #---------- #from ultralytics import YOLO #model = YOLO("model.pt") # 这里假设已经下载好的预训练模型文件名为model.pt #---------- # 检查GPU是否可用 if torch.cuda.is_available(): print("GPU is available for training.") else: print("GPU is not available. Training will be done on CPU.") # 不加载预训练模型,直接初始化一个新的YOLOv8模型 model = YOLO() # 修改这里,将模型转移到GPU(如果可用) if torch.cuda.is_available(): model = model.cuda() # 设置训练参数 args = { "data": "D:/Pydemo/脚本/yolov8/yolotrain/douyin.yaml", "imgsz": 640 } # 执行训练 results = model.train(**args)import torch from ultralytics import YOLO # 检查GPU是否可用 if torch.cuda.is_available(): print("GPU is available for training.") else: print("GPU is not available. Training will be done on CPU.") # 不加载预训练模型,直接初始化一个新的YOLOv8模型 model = YOLO() # 将模型转移到GPU(如果可用) if torch.cuda.is_available(): model = model.cuda() # 设置训练参数 args = { "data": "F:\\yolotrain\\bisai.yaml", "epochs": 20, "imgsz": 640 } # 假设这里有一个数据加载器 train_loader 用于加载训练数据 for batch in train_loader: # 将输入数据转移到GPU if torch.cuda.is_available(): input_data, labels = batch input_data = input_data.cuda() labels = labels.cuda() # 执行训练步骤 results = model.train(**args)
这个时候系统会下载yolov8s.pt的基础训练文件,如果下载失败,直接本章节的开头,直接下载demo文件,然后解压复制 yolov8s.pt 到 D:/Pydemo/脚本/yolov8/yolotrain/
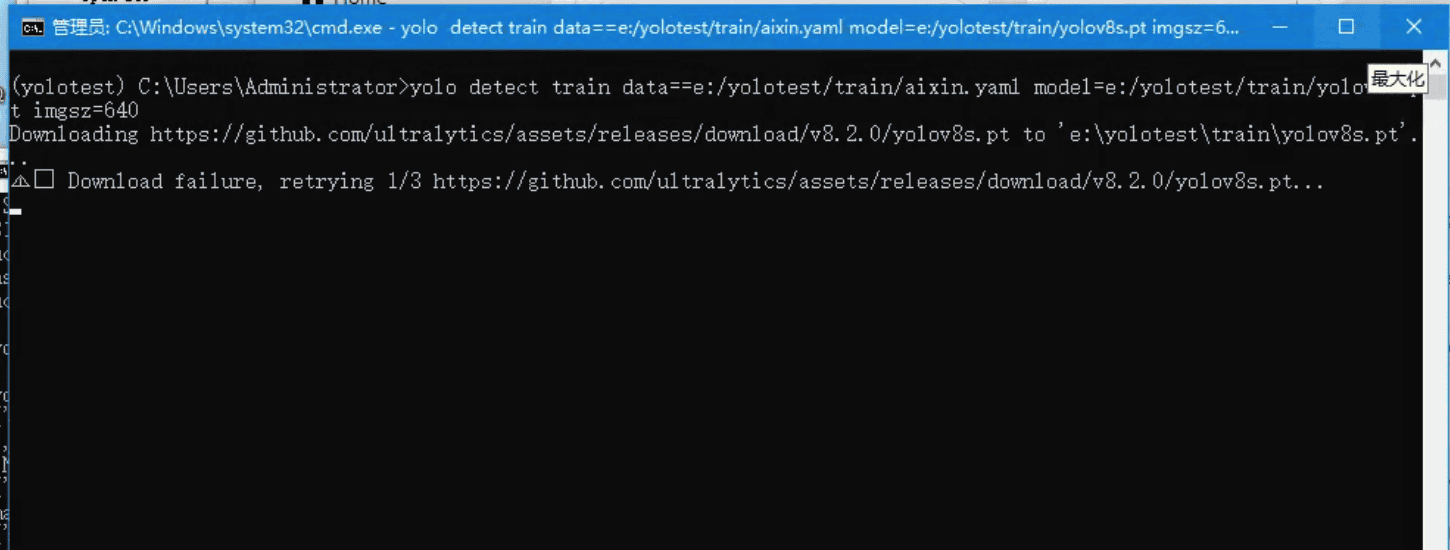
环境配置成功,一切无误,开始训练中
训练完毕,注意这里的 Results saved后面的路径是动态的,截图中是在 runs/detect/train文件夹下,就是E:/yolotrain文件夹下
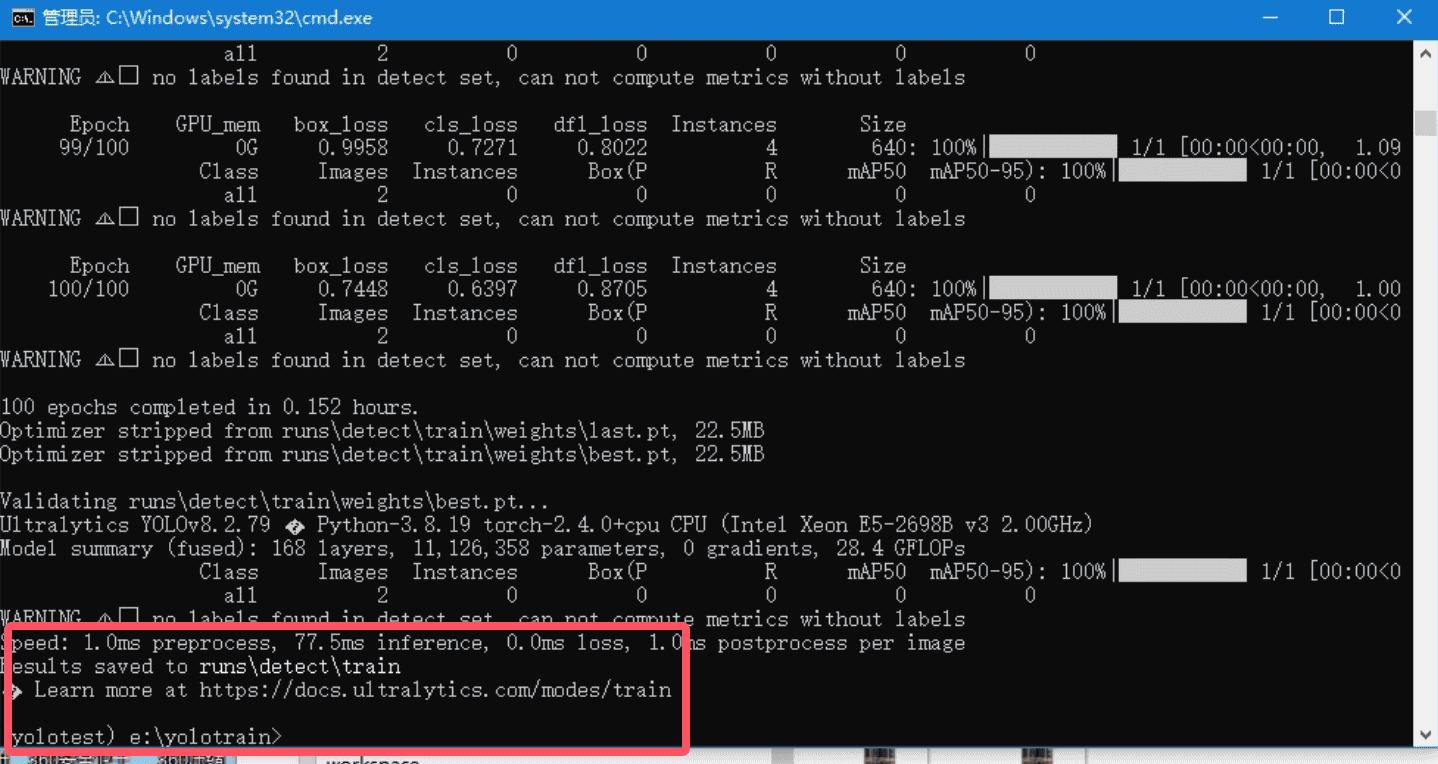
在训练完成的目录中可以找到 best.pt 的训练模型以及训练中被标记和选中目标的图片结果集
验证模型
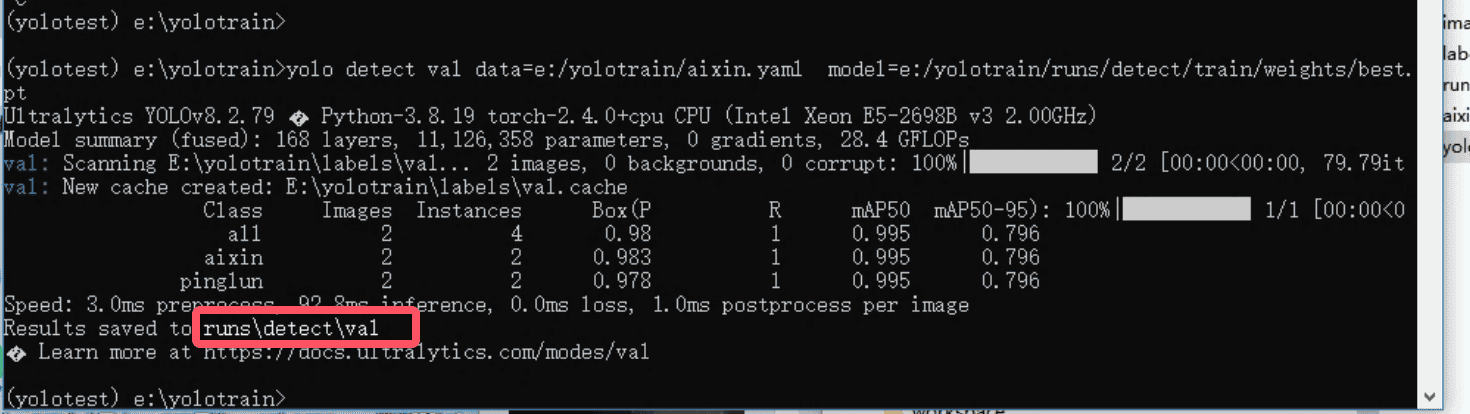
训练完成后,可以对图片进行验证
cmd控制台输入命令
model 参数代表是 需要验证的模型
data 代表检测的配置
yolo detect val data=D:/Pydemo/脚本/yolov8/yolotrain/douyin.yaml model=D:/Pydemo/脚本/yolov8/yolotrain/runs/detect/train/weights/best.pt预测结果
输入下面的命令预测如下名为insert的图片
yolo predict model=runs/detect/train/weights/best.pt source=insert.jpg //yolo detect train data=D:\Pydemo\脚本\比赛\yolotrain\sll.yaml model=D:\Pydemo\脚本\比赛\yolotrain\yolov8n.pt epochs=20 imgsz=320 batch=4 optimizer=SGD lr0=0.01 lrf=0.1 //yolo detect val data=D:\Pydemo\脚本\比赛\yolotrain\sll.yaml model=D:\Pydemo\脚本\比赛\yolotrain\yolov8n.pt conf=0.5 //yolo detect predict model=D:\Pydemo\脚本\比赛\yolotrain\runs\detect\train5\weights\best.pt source=D:\Pydemo\脚本\DS\train\class_0 conf=0.5 // 其他图片 //yolo predict model=D:\Pydemo\脚本\比赛\yolotrain\runs\detect\train5\weights\best.pt source=D:\Pydemo\脚本\DS\train\class_3\3_2.png //yolo predict model=D:\Pydemo\脚本\比赛\yolotrain\runs\detect\train5\weights\best.pt source=D:\Pydemo\脚本\DS\train\class_25\25_1.png
验证结果,这里的 Results saved后面的路径是动态的,请到对应的文件下查看图片标注结果runs/detect/val runs\detect\train
导出模型
将训练好的pt文件导出为
ncnn文件,交给EC的函数调用
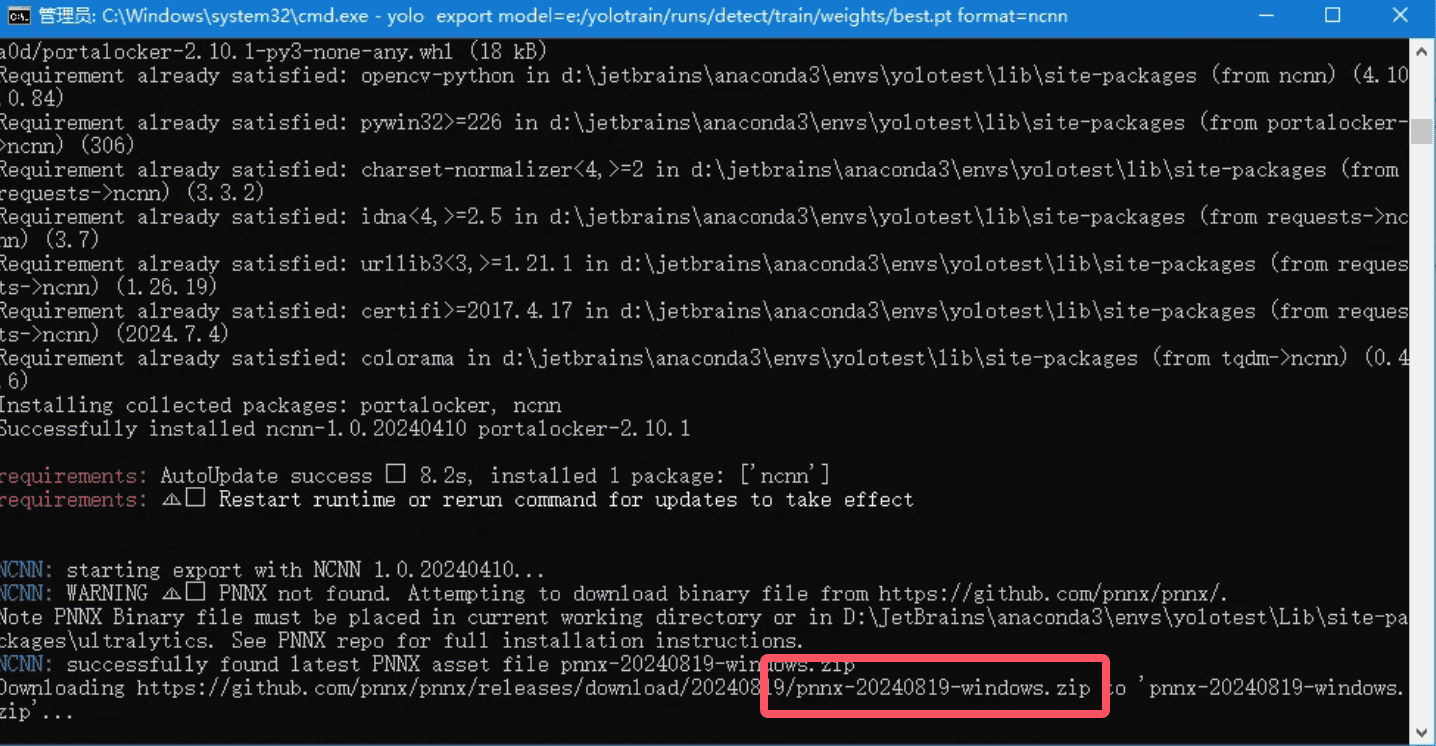
cmd控制台输入命令
model 参数代表要转换的模型
(yolov8_test) D:\Pydemo\脚本\yolov8\yolotrain\runs\detect\train\weights> yolo export model=./best.pt format=ncnn导出模型的时候要下载
pnnx组件,这里可以直接本章节的开头,直接下载demo文件,然后解压复制文件到D:/yolotrain/pnnx-20240819-windows.zip
如果名字不是
pnnx-20240819-windows.zip,请修改和报错红框截图一样的文件名称即可,或者直接去复制下载地址手动下载pnnx组件
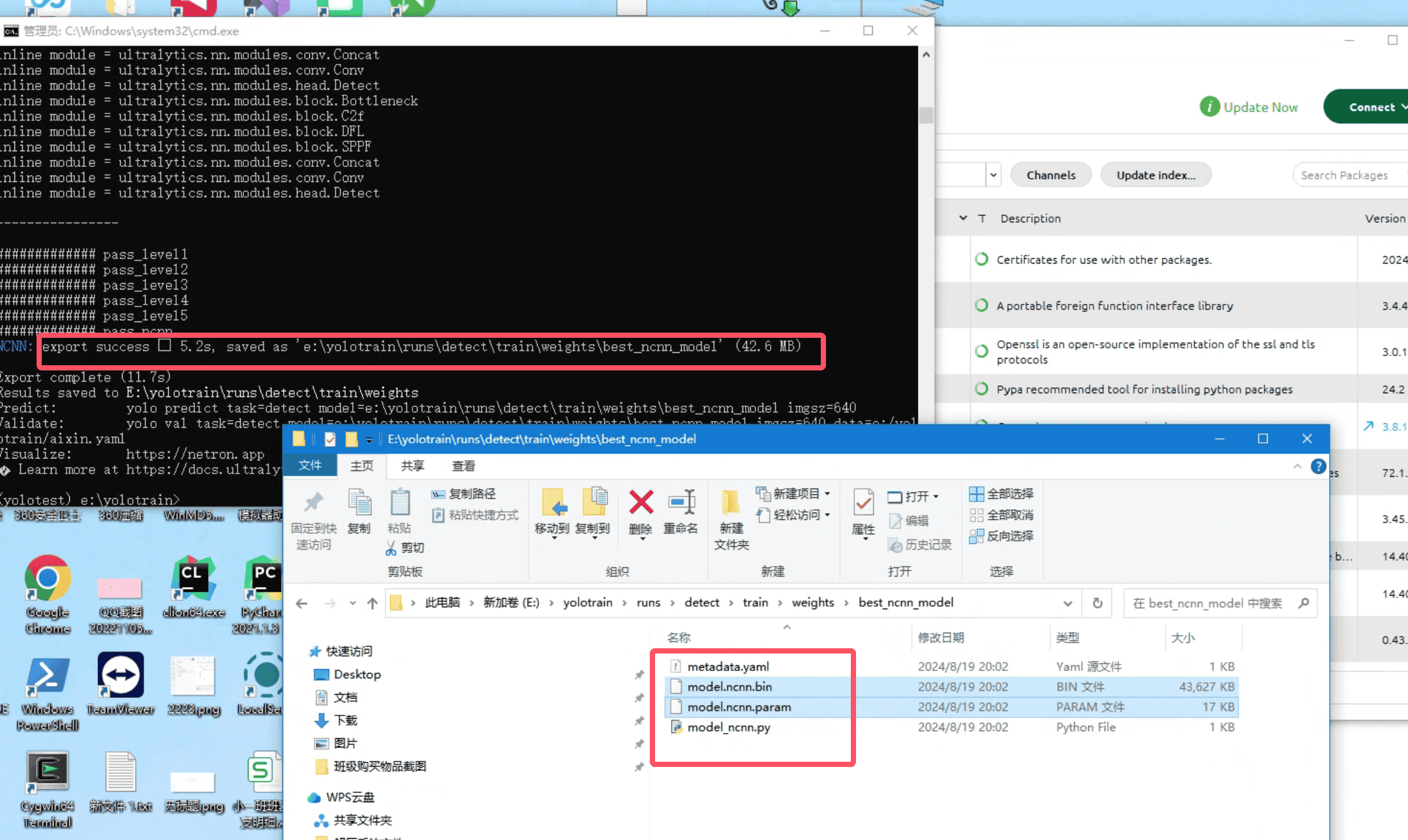
导出成功结果可以看到
export success后面的路径,进入结果文件夹,可以找到model.ncnn.param和model.ncnn.bin两个文件,这个两个放到手机sdcard,就可以给程序调用D:/Pydemo/脚本/yolov8/yolotrain/runs/detect/train/weights/best_ncnn_model/model.ncnn.bin .../model.ncnn.param
函数调用
将训练好的模型放到手机
/sdcard/根目录即可,也可以是其他目录,然后给程序调用具体如何使用请看YOLOV8函数模块
function main() { // 初始化YOLO实例 let yolov8s = yolov8Api.newYolov8(); // 初始化配置选项 let config = yolov8s.getDefaultConfig("yolov8s-640", 640, 0.25, 0.35, "ALL", 0, [ "dianzan", "pinglun", "shoucang" ]) logd("config : " + JSON.stringify(config)) // 初始化 训练过的模型 let paramPath = "model.ncnn.param"; let binPath = "model.ncnn.bin"; let inted = yolov8s.initYoloModel(config, paramPath, binPath); if (inted) { logd("初始化yolov8s成功"); } else { logd("初始化yolov8s失败: " + yolov8s.getErrorMsg()); return; } let bitmap = image.readBitmap("/img/1.png"); let result = yolov8s.detectBitmap(bitmap, []); // 这个带参数的代表只过滤pinglun的分类数据 //let result = yolov8s.detectBitmap(bitmap, ["pinglun"]); if (result == null || result == "") { logd("yolov8s 无结果: " + yolov8s.getErrorMsg()); } else { logd("yolov8s 结果: " + result); } if (bitmap != null) { // 回收图片 bitmap.recycle(); } // 在需要的时候释放,不要用一次释放一次 yolov8s.release(); } main();# adb/scrcpy_adb.py import scrcpy from adbutils import adb import cv2 as cv import time class ScrcpyADB: def __init__(self): devices = adb.device_list() # 取到adb连接到电脑上的设备 client = scrcpy.Client(device=devices[0]) # 创建scrcpy.Client实例,用于与第一个设备惊醒交互 adb.connect("127.0.0.1:5555") # 链接adb端口 print(devices, client) # 打印设备列表和客户端信息 client.add_listener(scrcpy.EVENT_FRAME, self.on_frame) # 客户端添加帧事件监听器on_frame,用于处理从设备接收到的帧 client.start(threaded=True) # 启动客户端,使其在后台线程中运行 self.client = client def on_frame(self, frame: cv.Mat): # cv.Mat对象视频流中的一帧图像 # 当接收到新的帧时,使用OpenCV的imshow函数显示这个帧 if frame is not None: cv.namedWindow('frame', cv.WINDOW_NORMAL) cv.imshow('frame', frame) # 将当前帧显示在名为frame的窗口中 cv.waitKey(1) # 使程序等待1毫秒 def touch_start(self, x: int or float, y: int or float): # 模拟触摸开始事件 self.client.control.touch(int(x), int(y), scrcpy.ACTION_DOWN) def touch_move(self, x: int or float, y: int or float): # 移动 self.client.control.touch(int(x), int(y), scrcpy.ACTION_DOWN) def touch_end(self, x: int or float, y: int or float): # 结束 self.client.control.touch(int(x), int(y), scrcpy.ACTION_UP) def tap(self, x: int or float, y: int or float): # 简单点击事件 self.touch_start(x, y) time.sleep(0.01) self.touch_end(x, y) if __name__ == '__main__': sadb = ScrcpyADB() time.sleep(5)
pc端函数调用
pip install onnx
pip install onnxruntime
# 模型转Onnx
from ultralytics import YOLO
model = YOLO("D:\\Pydemo\\脚本\\yolov8\\yolotrain\\runs\\detect\\train\\weights\\best.pt")
model.export(format="onnx", imgsz=[640,640], opset=12)
import scrcpy
from adbutils import adb
import cv2 as cv
import time
import onnxruntime as ort
import numpy as np
import onnx
class ScrcpyADB:
def __init__(self):
self.frame = None
devices = adb.device_list()
client = scrcpy.Client(device=devices[0])
adb.connect("127.0.0.1:5555")
print(devices, client)
client.add_listener(scrcpy.EVENT_FRAME, self.on_frame)
client.start(threaded=True)
self.client = client
self.ort_session = self.load_onnx_model("best.onnx") # 加载ONNX模型
def load_onnx_model(self, model_path):
# 加载ONNX模型并创建推理会话
onnx_model = onnx.load(model_path)
onnx.checker.check_model(onnx_model)
ort_session = ort.InferenceSession(model_path)
# 打印模型的输入节点名称
print("Model input names:", ort_session.get_inputs()[0].name)
return ort_session
def process_outputs(self, outputs):
boxes = outputs[0] # 假设边界框是输出的第一个元素
detected_boxes = [] # 用于存储检测到的边界框坐标
for box in boxes:
# ... 省略其他代码 ...
if box.size >= 4:
x_min = int(box[0][0]) # 访问第一个元素的第一个值
y_min = int(box[1][0]) # 访问第二个元素的第一个值
x_max = int(box[2][0]) # 访问第三个元素的第一个值
y_max = int(box[3][0]) # 访问第四个元素的第一个值
detected_boxes.append((x_min, y_min, x_max, y_max))
print(f"Detected object at: x_min: {x_min}, y_min: {y_min}, x_max: {x_max}, y_max: {y_max}")
cv.rectangle(self.frame, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2)
else:
print("Box does not contain enough values for coordinates.")
return detected_boxes # 确保返回 detected_boxes 列表
def on_frame(self, frame):
if frame is not None:
self.frame = frame.copy()
cv.namedWindow('frame', cv.WINDOW_NORMAL)
cv.imshow('frame', frame)
cv.waitKey(1)
detected_boxes = self.infer_onnx_model(self.frame) # 使用副本进行推理并获取边界框
if detected_boxes is not None: # 确保 detected_boxes 不是 None
for box in detected_boxes:
x_min, y_min, x_max, y_max = box
center_x = (x_min + x_max) // 2
center_y = (y_min + y_max) // 2
print(f"Tapping at: x: {center_x}, y: {center_y}")
self.tap(center_x, center_y)
cv.imshow('frame with boxes', self.frame)
def infer_onnx_model(self, frame):
# 预处理帧数据,准备输入模型
input_data = self.preprocess_frame(frame)
# 确保输入字典的键与模型的输入节点名称一致
input_feed = {"images": input_data} # 假设模型的输入节点名称是'images'
outputs = self.ort_session.run(None, input_feed)
# 处理模型输出
self.process_outputs(outputs)
# 确保 process_outputs 方法返回 detected_boxes 列表
return self.process_outputs(outputs)
def preprocess_frame(self, frame):
# 将帧数据转换为模型所需的输入格式
frame = np.array(frame, dtype=np.float32)
frame = cv.resize(frame, (640, 640)) # 调整图像尺寸为640x640
frame = (frame / 255.0) * 2.0 - 1.0 # 归一化
frame = frame.transpose((2, 0, 1)) # 从HWC转换为CHW
frame = np.expand_dims(frame, axis=0) # 添加批次维度
return frame
def touch_start(self, x: int or float, y: int or float): # 模拟触摸开始事件
self.client.control.touch(int(x), int(y), scrcpy.ACTION_DOWN)
def touch_move(self, x: int or float, y: int or float): # 移动
self.client.control.touch(int(x), int(y), scrcpy.ACTION_DOWN)
def touch_end(self, x: int or float, y: int or float): # 结束
self.client.control.touch(int(x), int(y), scrcpy.ACTION_UP)
def tap(self, x: int or float, y: int or float): # 简单点击事件
self.touch_start(x, y)
time.sleep(0.01)
self.touch_end(x, y)
if __name__ == '__main__':
sadb = ScrcpyADB()
time.sleep(5)cpu转GPU
对于 PyTorch:
-
确保您的环境中安装了
PyTorch的CUDA版本 -
将模型和输入数据转移到
GPU上
model = model.cuda() # 将模型转移到 GPU input_data = input_data.cuda() # 将数据转移到 GPU
对于 ONNX Runtime:
-
确保您的环境中安装了
ONNX Runtime GPU版本 -
在创建推理会话时指定使用
GPU
ort_session = ort.InferenceSession("model.onnx", providers=['CUDAExecutionProvider'])
Yolov8Util.getDefaultConfig获取yolov8默认配置
适配EC 10.15.0+
@param model_name 模型名称 默认写 yolov8s-640 即可
@param input_size yolov8训练时候的imgsz参数,默认写640即可
@param input_size 检测框系数,默认写0.25即可
@param iou_thr 输出系数,,默认写0.35 即可
@param bind_cpu 是否绑定CPU,选项为ALL,BIG,LITTLE 三个,默认写ALL
@param use_vulkan_compute 是否启用硬件加速,1是,0否,默认写0 即可
@param obj_names JSON数组,训练的时候分类名称例如 ["star","common","face"]
@return JSON数据
Yolov8Util.initYoloModel初始化yolov8模型
具体如何生成
param和bin文件,请参考文件的yolo使用章节,通过yolo的pt转成ncnn的param、bin文件适配EC 10.15.0+
@param map 参数表 参考 getDefaultConfig函数获取默认的参数
@param paramPath param文件路径
@param binPath bin文件路径
@return boolean true代表成功 false代表失败
Yolov8Util.detectBitmap检测图片
检测图片
适配EC 10.15.0+
返回数据例如
[{"name":"heart","confidence":0.92,"left":957,"top":986,"right":1050,"bottom":1078}]name: 代表是分类,confidence:代表可信度,left,top,right,bottom代表结果坐标选框
@param bitmap 安卓的bitmap对象
@param obj_names JSON数组,不写代表不过滤,写了代表只取填写的分类
@return string 字符串数据
Yolov8Util.release插入数据
释放yolov8资源
适配EC 10.15.0+
@return boolean
释放函数在脚本结束的的时候释放,无需要每次使用都释放
Yolov8Util.getErrorMsg获取YOLOV8错误消息
获取YOLOV8错误消息
适配EC 10.15.0+
@return string 字符串
GPU
CONDA创建虚拟环境错误
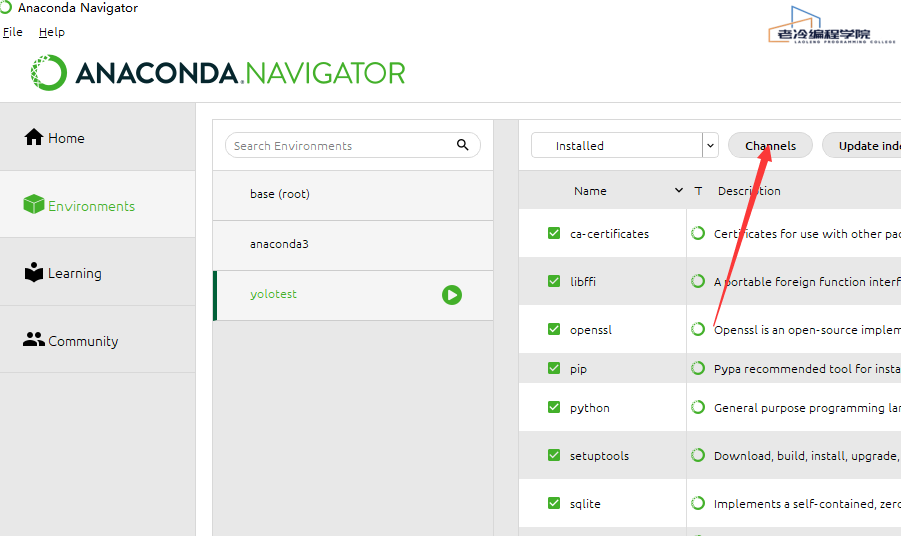
Anaconda创建虚拟环境create不能选择python版本,一般是网络问题导致的,可以切换到清华源
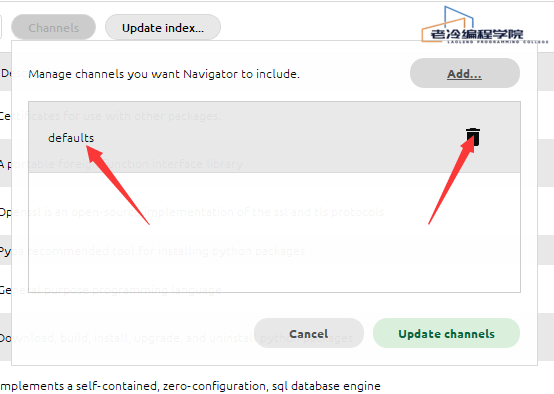
1.点channels
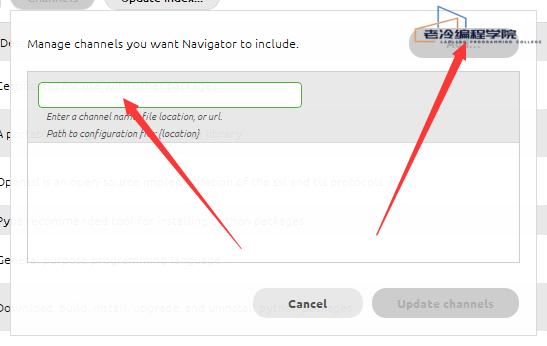
2.删除默认channel
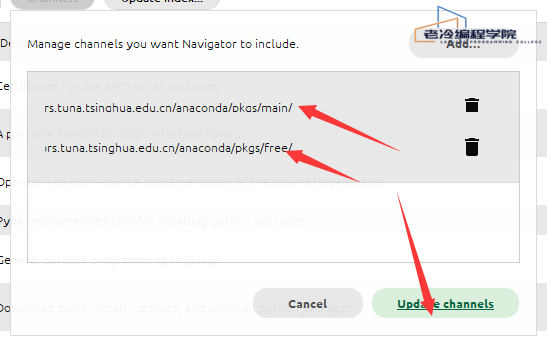
3.添加下方两个清华的channel 每添加一个回车确认配置,等待进度条加载完
https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
4.添加后,点击update channels
下载Arial.ttf错误
点我下载 Arial.ttf
放到
C:\Users\Administrator\AppData\Roaming\Ultralytics目录下,文件名称改为Arial.ttf,Administrator是你当前电脑的用户名
测试模型
安装 YOLOv8:可以通过 pip install ultralytics 命令进行安装,或者从官方 GitHub 仓库克隆代码并进行安装(git clone https://github.com/ultralytics/ultralytics,然后 cd ultralytics 并 pip install -e '.')
from ultralytics import YOLO
model = YOLO("model.pt") # 加载模型
model.to('cuda') # 如果有多个 GPU,可以指定 GPU 的编号,如 'cuda:0'、'cuda:1' 等# 单张图像验证
import cv2
image_path = "test_image.jpg"
image = cv2.imread(image_path)
results = model(image)# 批量图像验证
image_paths = ["image1.jpg", "image2.jpg", "image3.jpg"]
for path in image_paths:
image = cv2.imread(path)
results = model(image)
# 对每个图像的验证结果进行处理# 验证集验证
from ultralytics import YOLO
model = YOLO("model.pt")
model.val(data="validation_dataset_path.yaml") # 指定验证集的配置文件路径# 结果分析
metrics = model.val() # 返回一个包含各种验证指标的字典
map_value = metrics["metrics/mAP50-95(B)"]
print("mAP@0.5:0.95:", map_value)# 可视化结果
for result in results:
boxes = result.boxes
labels = result.names
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
conf = box.conf[0]
cls = box.cls[0]
label = labels[int(cls)]
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
cv2.putText(image, f"{label} {conf:.2f}", (int(x1), int(y1) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow("Result", image)
cv2.waitKey(0)
cv2.destroyAllWindows()


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











