






一、DQN的不足
DQN的动作选择和Q值评估都是基于目标网络,导致最大化操作会偏向高估某些动作的Q值。(也就是Q值过估计)
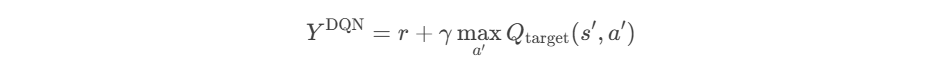
而DDQN则打算将动作选择和Q值评估分离:
利用主网络负责动作选择;
目标网络负责Q值评估。

二、流程:
1.初始化主网络和目标网络
2.经验回放 存储转移样本:将每个交互的转移样本 (s,a,r,s′,done) 存入回放缓冲区。
随机采样:训练时从小批量历史数据中随机采样,打破数据相关性。
在根据当前状态选择完动作之后,对当前状态的最大 Q 值进行指数移动平均(EMA)平滑;将离散动作索引 action 转换为环境所需的连续动作值,在环境中执行连续动作,获取下一步信息;将当前经验(状态转移)存入经验回放缓冲区。更新当前状态为下一步状态,继续交互;累计当前回合的总奖励;当经验回放缓冲区是否已积累足够数据时,从缓冲区中随机采样一批经验;将采样数据组织成字典,供智能体更新使用;利用采样的经验数据更新智能体的 Q 网络。
在step函数中,与DQN算法不一样的区别是,DDQN需要用到的是连续的动作区间。而DQN算法直接使用的动作(不管连续还是离散)
#dis_to_con 函数的作用是 将离散的整数动作值,线性映射到连续动作空间的范围。具体来说,它通过简单的归一化和缩放操作,将离散的整数动作转换为与环境兼容的连续动作值。
def dis_to_con(discrete_action, env, action_dim): # 离散动作转回连续的函数
action_lowbound = env.action_space.low[0] # 连续动作的最小值
action_upbound = env.action_space.high[0] # 连续动作的最大值
return action_lowbound + (discrete_action /
(action_dim - 1)) * (action_upbound -
action_lowbound)
至于如何更新网络
数据转换与张量准备;计算当前 Q 值;计算目标 Q 值;计算 TD 目标;计算损失函数;反向传播与优化;目标网络更新
3.动作选择:使用 主网络 选择下一状态 s′的最优动作:
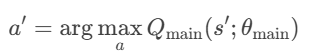
Q值评估:使用 目标网络 计算所选动作a′ 的Q值:
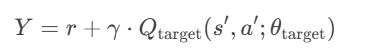
终止状态处理:若s′是终止状态(done=True),则Y=r。
# DQN的目标Q值计算
next_q_values = target_net(next_states)
max_next_q_values = next_q_values.max(dim=1)[0] # 直接用目标网络选择最大值
target_q = rewards + (1 - dones) * gamma * max_next_q_values
# DDQN的目标Q值计算
next_actions = online_net(next_states).argmax(dim=1, keepdim=True) # 主网络选动作
next_q_values = target_net(next_states)
max_next_q_values = next_q_values.gather(1, next_actions).squeeze() .detach()# 目标网络取值
target_q = rewards + (1 - dones) * gamma * max_next_q_values
-
主网络参数更新
计算当前Q值:主网络对当前状态 s 和动作a 的预测值:
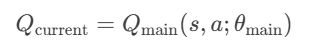
损失函数:均方误差(MSE)损失:
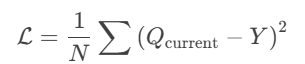
5.目标网络参数同步
每隔C 步将主网络的参数复制到目标网络。A[初始化主网络和目标网络] --> B[与环境交互收集样本]
B --> C[存入经验回放池]
C --> D[采样小批量数据]
D --> E[主网络选择动作a’]
E --> F[目标网络计算目标Q值]
F --> G[计算损失并更新主网络]
G --> H[定期同步目标网络]
H --> B
三、代码("初学强化学习"的代码会报错)
#DDQN.py
import random
import gymnasium as gym
import numpy as np
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import rl_utils
from tqdm import tqdm
#gymnasium版本
class Qnet(torch.nn.Module):
''' 只有一层隐藏层的Q网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
class DQN:
''' DQN算法,包括Double DQN '''
def __init__(self,
state_dim,
hidden_dim,
action_dim,
learning_rate,
gamma,
epsilon,
target_update,
device,
dqn_type='VanillaDQN'):
self.action_dim = action_dim
self.q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device)
self.target_q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device)
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma
self.epsilon = epsilon
self.target_update = target_update
self.count = 0
self.dqn_type = dqn_type
self.device = device
def take_action(self, state):
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.from_numpy(state).float().to(self.device)
#state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def max_q_value(self, state):
#state = torch.tensor([state], dtype=torch.float).to(self.device)
state = torch.from_numpy(state).float().to(self.device)
return self.q_net(state).max().item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions) # Q值
# 下个状态的最大Q值
if self.dqn_type == 'DoubleDQN': # DQN与Double DQN的区别
max_action = self.q_net(next_states).max(1)[1].view(-1, 1)
max_next_q_values = self.target_q_net(next_states).gather(1, max_action)
else: # DQN的情况
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones) # TD误差目标
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数
self.optimizer.zero_grad() # PyTorch中默认梯度会累积,这里需要显式将梯度置为0
dqn_loss.backward() # 反向传播更新参数
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict()) # 更新目标网络
self.count += 1
def dis_to_con(discrete_action, env, action_dim): # 离散动作转回连续的函数
action_lowbound = env.action_space.low[0] # 连续动作的最小值
action_upbound = env.action_space.high[0] # 连续动作的最大值
return action_lowbound + (discrete_action /
(action_dim - 1)) * (action_upbound -
action_lowbound)
def train_DQN(agent, env, num_episodes, replay_buffer, minimal_size,
batch_size):
return_list = []
max_q_value_list = []
max_q_value = 0
for i in range(10):
#print(i)
with tqdm(total=int(num_episodes / 10),desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state,_ = env.reset()
done = False
while not done:
action = agent.take_action(state)
max_q_value = agent.max_q_value(state) * 0.005 + max_q_value * 0.995 # 平滑处理
max_q_value_list.append(max_q_value) # 保存每个状态的最大Q值
#print("max_q_value",max_q_value)
action_continuous = dis_to_con(action, env,agent.action_dim)
#next_state, reward, done, _ ,_= env.step([action_continuous])
next_state, reward, terminated, truncated, _ = env.step([action_continuous])
done = terminated or truncated
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'dones': b_d
}
agent.update(transition_dict)
#print(done)
return_list.append(episode_return)
#print(11)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({'episode':'%d' % (num_episodes / 10 * i + i_episode + 1),'return':'%.3f' % np.mean(return_list[-10:])})
#print('Episode: %d' % i_episode)
pbar.update(1)
return return_list, max_q_value_list
lr = 1e-2
num_episodes = 500
hidden_dim = 128
gamma = 0.98
epsilon = 0.01
target_update = 10
buffer_size = 10000
minimal_size = 500
batch_size = 64
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
print(device)
env_name = 'Pendulum-v1'
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = 11 # 将连续动作分成11个离散动作
# random.seed(0)
# np.random.seed(0)
# env.reset(seed=0)
# torch.manual_seed(0)
# replay_buffer = rl_utils.ReplayBuffer(buffer_size)
# agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
# target_update, device)
#
# return_list, max_q_value_list = train_DQN(agent, env, num_episodes,
# replay_buffer, minimal_size,
# batch_size)
#
# episodes_list = list(range(len(return_list)))
# mv_return = rl_utils.moving_average(return_list, 5)
# plt.plot(episodes_list, mv_return)
# plt.xlabel('Episodes')
# plt.ylabel('Returns')
# plt.title('DQN on {}'.format(env_name))
# plt.show()
#
# frames_list = list(range(len(max_q_value_list)))
# plt.plot(frames_list, max_q_value_list)
# plt.axhline(0, c='orange', ls='--')
# plt.axhline(10, c='red', ls='--')
# plt.xlabel('Frames')
# plt.ylabel('Q value')
# plt.title('DQN on {}'.format(env_name))
# plt.show()
random.seed(0)
np.random.seed(0)
env.reset(seed=0)
#env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device, 'DoubleDQN')
return_list, max_q_value_list = train_DQN(agent, env, num_episodes,
replay_buffer, minimal_size,
batch_size)
episodes_list = list(range(len(return_list)))
mv_return = rl_utils.moving_average(return_list, 5)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Double DQN on {}'.format(env_name))
plt.show()
frames_list = list(range(len(max_q_value_list)))
plt.plot(frames_list, max_q_value_list)
plt.axhline(0, c='orange', ls='--')
plt.axhline(10, c='red', ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('Double DQN on {}'.format(env_name))
plt.show()
#rl_utils.py
from tqdm import tqdm
import numpy as np
import torch
import collections
import random
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def add(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
transitions = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*transitions)
return np.array(state), action, reward, np.array(next_state), done
def size(self):
return len(self.buffer)
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size - 1, 2)
begin = np.cumsum(a[:window_size - 1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
def train_on_policy_agent(env, agent, num_episodes):
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}
state, _ = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _, _ = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
def train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size):
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state, _ = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _, _ = env.step(action)
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {'states': b_s, 'actions': b_a, 'next_states': b_ns, 'rewards': b_r,
'dones': b_d}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
结果:
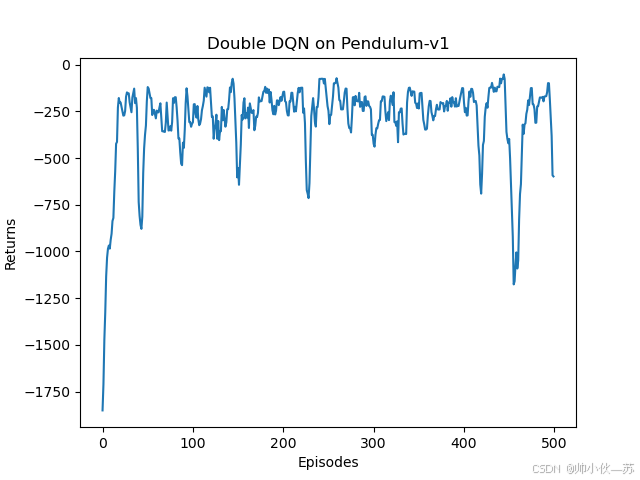
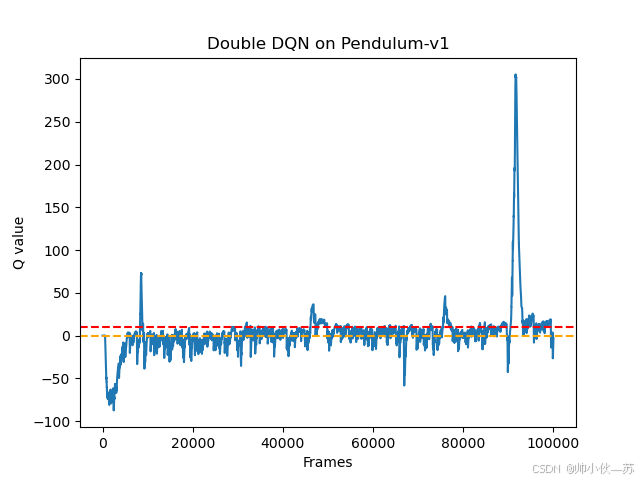
我随便调的参数,能运行就行。

















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









