







 这篇博客介绍了如何使用Python计算二值图像的Dice相似系数,并批量处理100张图片,输出每张图片及平均Dice值,同时绘制Dice分布图。代码包括单张图片Dice值计算及批量计算,适用于医学图像分析或图像分割评估。
这篇博客介绍了如何使用Python计算二值图像的Dice相似系数,并批量处理100张图片,输出每张图片及平均Dice值,同时绘制Dice分布图。代码包括单张图片Dice值计算及批量计算,适用于医学图像分析或图像分割评估。
1.代码效果
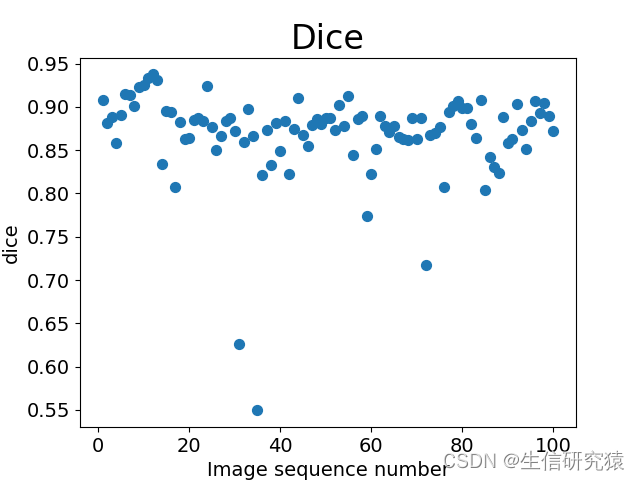
输出每张图片的Dice值及所有图片的Dice平均值,且最后生成一张Dice分布图:
以100张图片为例,横坐标是图片序号,纵坐标是每张图片的Dice值。
2.图片格式要求
1.模型生成的标记图片和正确的标记图片要求是严格的二值图片。如下图:
2.图片名称按序为:1.png 2.png 3.png...(图片格式可以在代码里改,如png,jpg等)

3.代码(计算单张图片的Dice值)
代码中white1,black1分别代表正确标记图片的白色像素点数和黑色像素点数,white2,black2分别代表模型生成结果的标记图片的白色像素点数和黑色像素点数。
size是两张图片的交集的像素点数,即重合部分区域。
# This is a sample Python script.
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
#from filecmp import cmp
import cv2
import operator
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
def img_input(img_path, label_path):
img = cv2.imread(img_path) # 使用 cv2 来打开图片
label = cv2.imread(label_path) # 使用 cv2 来打开图片
return (img, label)
def img_size(img):
white = 0
black = 0
list1 = [255, 255, 255]
list2 = [0,0,0]
for x in img:
for y in x:
if operator.eq(y.tolist(), list1)==True:#y.tolist():numpy类型转list类型,由[a b c]变成[a,b,c](多了逗号)
white = white + 1
elif operator.eq(y.tolist(), list2)==True:#在Python3中我们可以使用operator方法来比较两个list是否相等
black = black + 1
return (white,black)
def size_same(img,label):
size = 0
list = [255,255,255]
for x1,x2 in zip(img,label):
for y1,y2 in zip(x1,x2):
if operator.eq(y1.tolist(), y2.tolist()) & operator.eq(y1.tolist(), list):
size = size +1
return size
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
# print_hi('PyCharm')
img_path = "D:/myMark/2.png"
label_path = "D:/result/2.png"
img, label = img_input(img_path, label_path)
#print("img:", img, "label:", label)
#cv2.imshow("img", img)
#cv2.waitKey(0)
white1,black1 = img_size(img)
white2, black2 = img_size(label)
size = size_same(img,label)
dice = 2*size/(white1+white2)
print("white1:", white1, "black1:", black1)
print("white2:", white2, "black2:", black2)
print("same size:", size)
print("dice:", dice)4.代码(批量计算图片的Dice值)
注:本代码默认是100张图片,1.png-100.png,可以在代码中修改图片数量
# This is a sample Python script.
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
#from filecmp import cmp
import cv2
import operator
import matplotlib.pyplot as plt
def img_input(myMark_path, result_path):
myMark = cv2.imread(myMark_path) # 使用 cv2 来打开图片
result = cv2.imread(result_path) # 使用 cv2 来打开图片
return (myMark, result)
def img_size(img):
white = 0
black = 0
list1 = [255, 255, 255]
list2 = [0,0,0]
count = 0
c=0
for x in img:
for y in x:
count = count + 1
if operator.eq(y.tolist(), list1)==True:
white = white + 1
elif operator.eq(y.tolist(), list2)==True:
black = black + 1
else:
c=c+1
return (c,count, white,black)
def size_same(img1,img2):
size = 0
list = [255,255,255]
for x1,x2 in zip(img1,img2):
for y1,y2 in zip(x1,x2):
if operator.eq(y1.tolist(), y2.tolist()) & operator.eq(y1.tolist(), list):
size = size +1
return size
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
# print_hi('PyCharm')
myMark_path1 = "D:/myMark/"
result_path1 = "D:/result/"
i= 501
j=1
dicelist = []
for j in range(1, 101):
myMark_path = myMark_path1 + str(i) + ".png"
result_path = result_path1 + str(i) + ".png"
#print("------",myMark_path)
#print("------", result_path)
myMark, result = img_input(myMark_path, result_path)
# print("img:", img, "label:", label)
# cv2.imshow("img", img)
# cv2.waitKey(0)
c1,count1, white1, black1 = img_size(myMark)
c2,count2, white2, black2 = img_size(result)
size = size_same(myMark, result)
dice = 2 * size / (white1 + white2)
dicelist.append(dice)
#print("grey1:",c1,"conut1:",count1,"white1:", white1, "black1:", black1)
#print("grey2:",c2,"conut2:",count2,"white2:", white2, "black2:", black2)
#print("same size:", size)
#print("dice:", dice)
print(dice)
#print("dicelist:", dicelist)
i= i+1
x_values = range(1, 101)
y_values = dicelist
'''
scatter()
x:横坐标 y:纵坐标 s:点的尺寸
'''
plt.scatter(x_values, y_values, s=50)
# 设置图表标题并给坐标轴加上标签
plt.title('Dice', fontsize=24)
plt.xlabel('Image sequence number', fontsize=14)
plt.ylabel('dice', fontsize=14)
# 设置刻度标记的大小
plt.tick_params(axis='both', which='major', labelsize=14)
plt.show()
dicesum = 0
num = 0
for num in range(0, 100):
dicesum = dicesum + dicelist[num]
print("dicesum:",dicesum,"num:",num)
avg = dicesum/100
print("avg:",avg)

















 1565
1565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









