










 在使用Spark3.1.1版本从Hive3.1.2获取数据时,遇到HadoopDFSClient的连接超时错误。问题可能与网络连接、配置或资源限制有关。代码示例中尝试设置`dfs.client.use.datanode.hostname`为`true`来使用域名访问,但仍然出现错误。
在使用Spark3.1.1版本从Hive3.1.2获取数据时,遇到HadoopDFSClient的连接超时错误。问题可能与网络连接、配置或资源限制有关。代码示例中尝试设置`dfs.client.use.datanode.hostname`为`true`来使用域名访问,但仍然出现错误。
环境
hive3.1.2
hadoop3.1.3
saprk3.1.1
报错
26748 [Executor task launch worker for task 0.0 in stage 0.0 (TID 0)] WARN org.apache.hadoop.hdfs.client.impl.BlockReaderFactory - I/O error constructing remote block reader.
java.net.ConnectException: Connection timed out: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.hdfs.DFSClient.newConnectedPeer(DFSClient.java:2939)
at org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.nextTcpPeer(BlockReaderFactory.java:821)
at org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.getRemoteBlockReaderFromTcp(BlockReaderFactory.java:746)
at org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.build(BlockReaderFactory.java:379)
at org.apache.hadoop.hdfs.DFSInputStream.getBlockReader(DFSInputStream.java:644)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:575)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:757)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:829)
at java.io.DataInputStream.read(DataInputStream.java:149)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.fillBuffer(UncompressedSplitLineReader.java:62)
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:218)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:176)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.readLine(UncompressedSplitLineReader.java:94)
at org.apache.hadoop.mapred.LineRecordReader.skipUtfByteOrderMark(LineRecordReader.java:215)
at org.apache.hadoop.mapred.LineRecordReader.next(LineRecordReader.java:253)
at org.apache.hadoop.mapred.LineRecordReader.next(LineRecordReader.java:48)
at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:312)
at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:243)
at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:755)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:345)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
26751 [Executor task launch worker for task 0.0 in stage 0.0 (TID 0)] WARN org.apache.hadoop.hdfs.DFSClient - Failed to connect to /192.168.3.55:9866 for file /user/hive/warehouse/ods.db/student/student.txt for block BP-24793988-192.168.3.55-1663646169451:blk_1073742303_1479, add to deadNodes and continue.
java.net.ConnectException: Connection timed out: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.hdfs.DFSClient.newConnectedPeer(DFSClient.java:2939)
at org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.nextTcpPeer(BlockReaderFactory.java:821)
at org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.getRemoteBlockReaderFromTcp(BlockReaderFactory.java:746)
at org.apache.hadoop.hdfs.client.impl.BlockReaderFactory.build(BlockReaderFactory.java:379)
at org.apache.hadoop.hdfs.DFSInputStream.getBlockReader(DFSInputStream.java:644)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:575)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:757)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:829)
at java.io.DataInputStream.read(DataInputStream.java:149)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.fillBuffer(UncompressedSplitLineReader.java:62)
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:218)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:176)
at org.apache.hadoop.mapreduce.lib.input.UncompressedSplitLineReader.readLine(UncompressedSplitLineReader.java:94)
at org.apache.hadoop.mapred.LineRecordReader.skipUtfByteOrderMark(LineRecordReader.java:215)
at org.apache.hadoop.mapred.LineRecordReader.next(LineRecordReader.java:253)
at org.apache.hadoop.mapred.LineRecordReader.next(LineRecordReader.java:48)
at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:312)
at org.apache.spark.rdd.HadoopRDD$$anon$1.getNext(HadoopRDD.scala:243)
at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:755)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:345)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:898)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:898)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:373)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:337)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:131)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
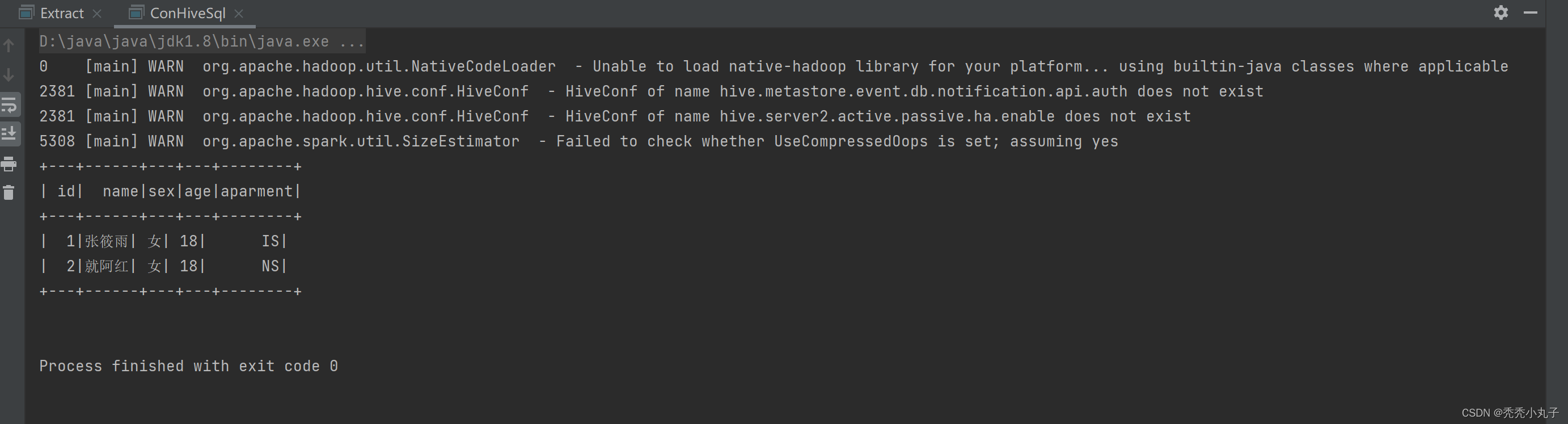
完整代码
package Four
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object ConHiveSql {
def main(args: Array[String]): Unit = {
val con=new SparkConf().setMaster("local[*]").setAppName("con").set("spark.testing.memory","2147480000")
System.setProperty("HADOOP_USER_NAME","root")
val conh=SparkSession.builder()
.config("hive.metastore.uris","thrift://192.168.23.60:9083")
.config("spark.sql.warehouse","hdfs://192.168.23.60:9000//user/hive/warehouse/")
.config("dfs.client.use.datanode.hostname", "true")//将默认的IP访问改为域名访问的形式
.config(con)
// configuration.set("dfs.client.use.datanode.hostname", "true")
.enableHiveSupport().getOrCreate()
// conh.sql("use ods").show()
conh.sql("select * from ods.student").show()
}
}

将默认的IP访问改为域名访问的形式
(27条消息) 使用idea, sparksql读取hive中的数据_idea spark读取hive数据_xiaolin_xinji的博客-优快云博客

















 1374
1374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









