






一、Lagent 介绍
简介
Agent智能体简单来说就是给LLM提供查询工具,让他可以通过这些工具来完成特定任务。毕竟,如果你直接问llm某个任务该怎么做,那llm一般会返回一堆废话,让你去做这做那,而Agent就是让llm来执行这些看似废话的逻辑推理,并通过提供的查询接口等来完成特定任务。
Lagent 是一个轻量级开源智能体框架,旨在让用户可以高效地构建基于大语言模型的智能体。同时它也提供了一些典型工具以增强大语言模型的能力。
Lagent 目前已经支持了包括 AutoGPT、ReAct 等在内的多个经典智能体范式,也支持了如下工具:
- Arxiv 搜索
- Bing 地图
- Google 学术搜索
- Google 搜索
- 交互式 IPython 解释器
- IPython 解释器
- PPT
- Python 解释器
其基本结构如下所示:
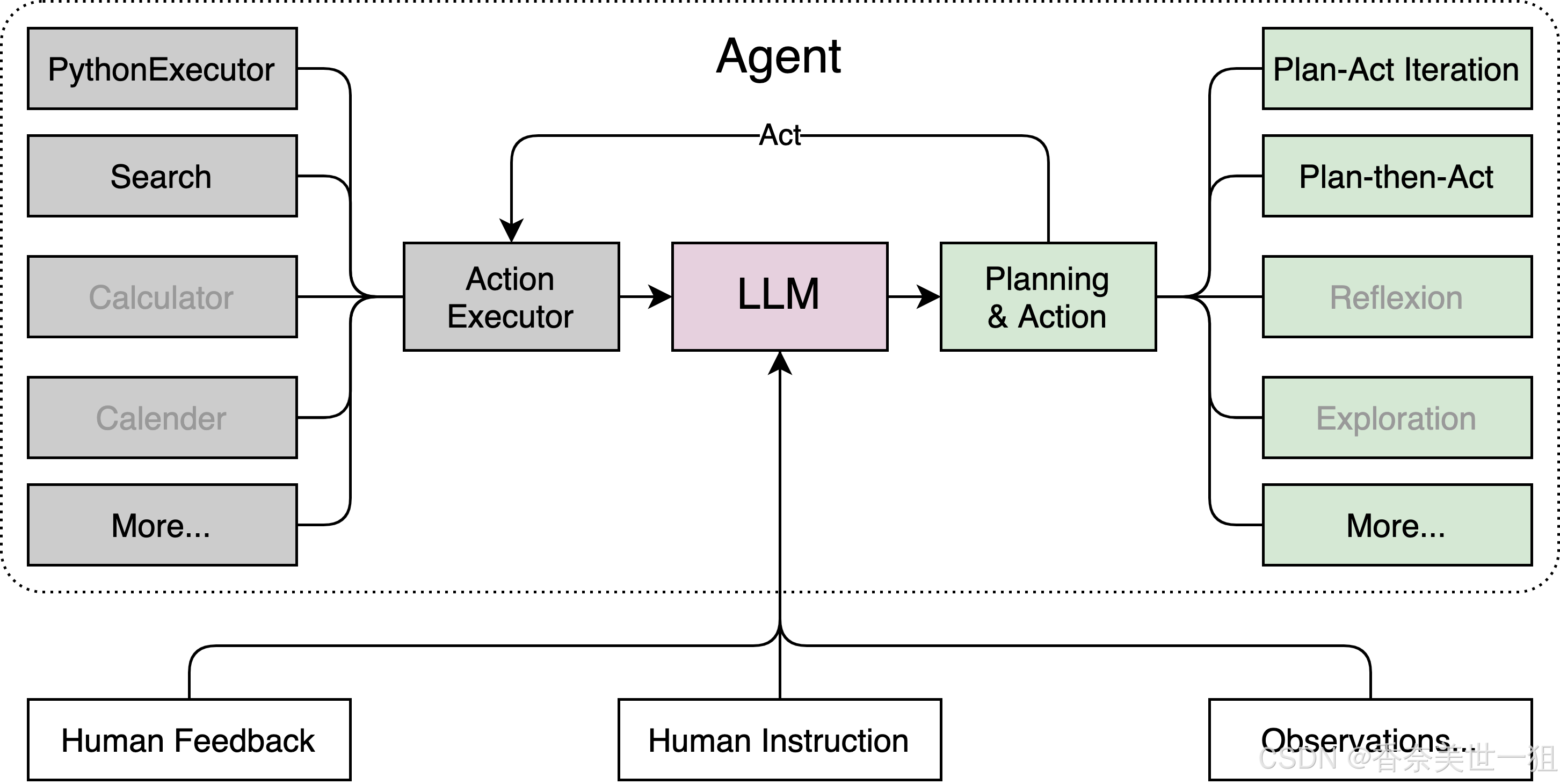
常见工具调用能力范式
通用智能体范式
这种范式强调模型无需依赖特定的特殊标记(special token)来定义工具调用的参数边界。模型依靠其强大的指令跟随与推理能力,在指定的system prompt框架下,根据任务需求自动生成响应。这种方式让模型在推理过程中能更灵活地适应多种任务,不需要对Tokenizer进行特殊设计。
优势:
- 灵活适应不同任务,无需设计和维护复杂的标记系统。
- 适合快速迭代,降低微调和部署的复杂性。
- 更易与多模态输入(如文本和图像)结合,扩展模型的通用性。
劣势:
- 由于没有明确标记,调用工具时的错误难以捕捉和纠正。
- 在复杂任务中,模型生成可能不够精准,导致工具调用的准确性下降。
(1)ReAct:将模型的推理分为Reason和Action两个步骤,并让它们交替执行,直到得到最终结果:
- Reason:生成分析步骤,解释当前任务的上下文或状态,帮助模型理解下一步行动的逻辑依据。
- Action:基于Reason的结果,生成具体的工具调用请求(如查询搜索引擎、调用API、数据库检索等),将模型的推理转化为行动。
(2)ReWoo:全称为Reason without Observation,是在ReAct范式基础上进行改进的Agent架构,针对多工具调用的复杂性与冗余性提供了一种高效的解决方案。相比于ReAct中的交替推理和行动,ReWoo直接生成一次性使用的完整工具链,减少了不必要的Token消耗和执行时间。同时,由于工具调用的规划与执行解耦,这一范式在模型微调时不需要实际调用工具即可完成。
- Planner:用户输入的问题或任务首先传递给Planner,Planner将其分解为多个逻辑上相关的计划。每个计划包含推理部分(Reason)以及工具调用和参数(Execution)。Task List按顺序列出所有需要执行的任务链。
- Worker:每个Worker根据Task List中的子任务,调用指定工具并返回结果。所有Worker之间通过共享状态保持任务执行的连续性。
- Solver阶段:Worker完成任务后,将所有结果同步到Solver。Solver会对这些结果进行整合,并生成最终的答案或解决方案返回给用户。
模型特化智能体范式
在这种范式下,模型的工具调用必须通过特定的special token明确标记。如InternLM2使用<|action_start|>和<|action_end|>来定义调用边界。这些标记通常与模型的Tokenizer深度集成,确保在执行特定任务时,能够准确捕捉调用信息并执行。
优势:
- 特定标记明确工具调用的起止点,提高了调用的准确性。
- 有助于模型在部署过程中避免误调用,增强系统的可控性。
- 提高对复杂调用链的支持,适合复杂任务的场景。
劣势:
- 需要对Tokenizer和模型架构进行定制,增加开发和维护成本。
- 调用流程固定,降低了模型的灵活性,难以适应快速变化的任务。
(1)InternLM2案例分析: 工具调用使用了如<|plugin|>、<|interpreter|>、<|action_start|>和<|action_end|>等特殊标记,确保每个调用都符合指定的格式。模型在执行任务时,依靠这些标记与系统紧密协作,保障任务的精准执行。文档链接:InternLM-Chat Agent
二、Lagent 实战,创建自己的Agent
1.配置
# 创建环境
conda create -n lagent python=3.10 -y
# 激活环境
conda activate lagent
# 安装 torch
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖包
pip install termcolor==2.4.0
pip install streamlit==1.39.0
pip install class_registry==2.1.2
pip install datasets==3.1.0安装Lagent
# 创建目录以存放代码
mkdir -p /root/agent_camp4
cd /root/agent_camp4
git clone https://github.com/InternLM/lagent.git
cd lagent && git checkout e304e5d && pip install -e . && cd ..
pip install griffe==0.48.02.Lagent框架中Agent的使用
创建py脚本
conda activate lagent
cd /root/agent_camp4/lagent/examples
touch agent_api_web_demo.py
export token='your API-key'import copy
import os
from typing import List
import streamlit as st
from lagent.actions import ArxivSearch
from lagent.prompts.parsers import PluginParser
from lagent.agents.stream import INTERPRETER_CN, META_CN, PLUGIN_CN, AgentForInternLM, get_plugin_prompt
from lagent.llms import GPTAPI
class SessionState:
"""管理会话状态的类。"""
def init_state(self):
"""初始化会话状态变量。"""
st.session_state['assistant'] = [] # 助手消息历史
st.session_state['user'] = [] # 用户消息历史
# 初始化插件列表
action_list = [
ArxivSearch(),
]
st.session_state['plugin_map'] = {action.name: action for action in action_list}
st.session_state['model_map'] = {} # 存储模型实例
st.session_state['model_selected'] = None # 当前选定模型
st.session_state['plugin_actions'] = set() # 当前激活插件
st.session_state['history'] = [] # 聊天历史
st.session_state['api_base'] = None # 初始化API base地址
def clear_state(self):
"""清除当前会话状态。"""
st.session_state['assistant'] = []
st.session_state['user'] = []
st.session_state['model_selected'] = None
class StreamlitUI:
"""管理 Streamlit 界面的类。"""
def __init__(self, session_state: SessionState):
self.session_state = session_state
self.plugin_action = [] # 当前选定的插件
# 初始化提示词
self.meta_prompt = META_CN
self.plugin_prompt = PLUGIN_CN
self.init_streamlit()
def init_streamlit(self):
"""初始化 Streamlit 的 UI 设置。"""
st.set_page_config(
layout='wide',
page_title='lagent-web',
page_icon='./docs/imgs/lagent_icon.png'
)
st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow')
def setup_sidebar(self):
"""设置侧边栏,选择模型和插件。"""
# 模型名称和 API Base 输入框
model_name = st.sidebar.text_input('模型名称:', value='internlm2.5-latest')
# ================================== 硅基流动的API ==================================
# 注意,如果采用硅基流动API,模型名称需要更改为:internlm/internlm2_5-7b-chat 或者 internlm/internlm2_5-20b-chat
# api_base = st.sidebar.text_input(
# 'API Base 地址:', value='https://api.siliconflow.cn/v1/chat/completions'
# )
# ================================== 浦语官方的API ==================================
api_base = st.sidebar.text_input(
'API Base 地址:', value='https://internlm-chat.intern-ai.org.cn/puyu/api/v1/chat/completions'
)
# ==================================================================================
# 插件选择
plugin_name = st.sidebar.multiselect(
'插件选择',
options=list(st.session_state['plugin_map'].keys()),
default=[],
)
# 根据选择的插件生成插件操作列表
self.plugin_action = [st.session_state['plugin_map'][name] for name in plugin_name]
# 动态生成插件提示
if self.plugin_action:
self.plugin_prompt = get_plugin_prompt(self.plugin_action)
# 清空对话按钮
if st.sidebar.button('清空对话', key='clear'):
self.session_state.clear_state()
return model_name, api_base, self.plugin_action
def initialize_chatbot(self, model_name, api_base, plugin_action):
"""初始化 GPTAPI 实例作为 chatbot。"""
token = os.getenv("token")
if not token:
st.error("未检测到环境变量 `token`,请设置环境变量,例如 `export token='your_token_here'` 后重新运行 X﹏X")
st.stop() # 停止运行应用
# 创建完整的 meta_prompt,保留原始结构并动态插入侧边栏配置
meta_prompt = [
{"role": "system", "content": self.meta_prompt, "api_role": "system"},
{"role": "user", "content": "", "api_role": "user"},
{"role": "assistant", "content": self.plugin_prompt, "api_role": "assistant"},
{"role": "environment", "content": "", "api_role": "environment"}
]
api_model = GPTAPI(
model_type=model_name,
api_base=api_base,
key=token, # 从环境变量中获取授权令牌
meta_template=meta_prompt,
max_new_tokens=512,
temperature=0.8,
top_p=0.9
)
return api_model
def render_user(self, prompt: str):
"""渲染用户输入内容。"""
with st.chat_message('user'):
st.markdown(prompt)
def render_assistant(self, agent_return):
"""渲染助手响应内容。"""
with st.chat_message('assistant'):
content = getattr(agent_return, "content", str(agent_return))
st.markdown(content if isinstance(content, str) else str(content))
def main():
"""主函数,运行 Streamlit 应用。"""
if 'ui' not in st.session_state:
session_state = SessionState()
session_state.init_state()
st.session_state['ui'] = StreamlitUI(session_state)
else:
st.set_page_config(
layout='wide',
page_title='lagent-web',
page_icon='./docs/imgs/lagent_icon.png'
)
st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow')
# 设置侧边栏并获取模型和插件信息
model_name, api_base, plugin_action = st.session_state['ui'].setup_sidebar()
plugins = [dict(type=f"lagent.actions.{plugin.__class__.__name__}") for plugin in plugin_action]
if (
'chatbot' not in st.session_state or
model_name != st.session_state['chatbot'].model_type or
'last_plugin_action' not in st.session_state or
plugin_action != st.session_state['last_plugin_action'] or
api_base != st.session_state['api_base']
):
# 更新 Chatbot
st.session_state['chatbot'] = st.session_state['ui'].initialize_chatbot(model_name, api_base, plugin_action)
st.session_state['last_plugin_action'] = plugin_action # 更新插件状态
st.session_state['api_base'] = api_base # 更新 API Base 地址
# 初始化 AgentForInternLM
st.session_state['agent'] = AgentForInternLM(
llm=st.session_state['chatbot'],
plugins=plugins,
output_format=dict(
type=PluginParser,
template=PLUGIN_CN,
prompt=get_plugin_prompt(plugin_action)
)
)
# 清空对话历史
st.session_state['session_history'] = []
if 'agent' not in st.session_state:
st.session_state['agent'] = None
agent = st.session_state['agent']
for prompt, agent_return in zip(st.session_state['user'], st.session_state['assistant']):
st.session_state['ui'].render_user(prompt)
st.session_state['ui'].render_assistant(agent_return)
# 处理用户输入
if user_input := st.chat_input(''):
st.session_state['ui'].render_user(user_input)
# 调用模型时确保侧边栏的系统提示词和插件提示词生效
res = agent(user_input, session_id=0)
st.session_state['ui'].render_assistant(res)
# 更新会话状态
st.session_state['user'].append(user_input)
st.session_state['assistant'].append(copy.deepcopy(res))
st.session_state['last_status'] = None
if __name__ == '__main__':
main()
运行streamlit run agent_api_web_demo.py
结果如下:
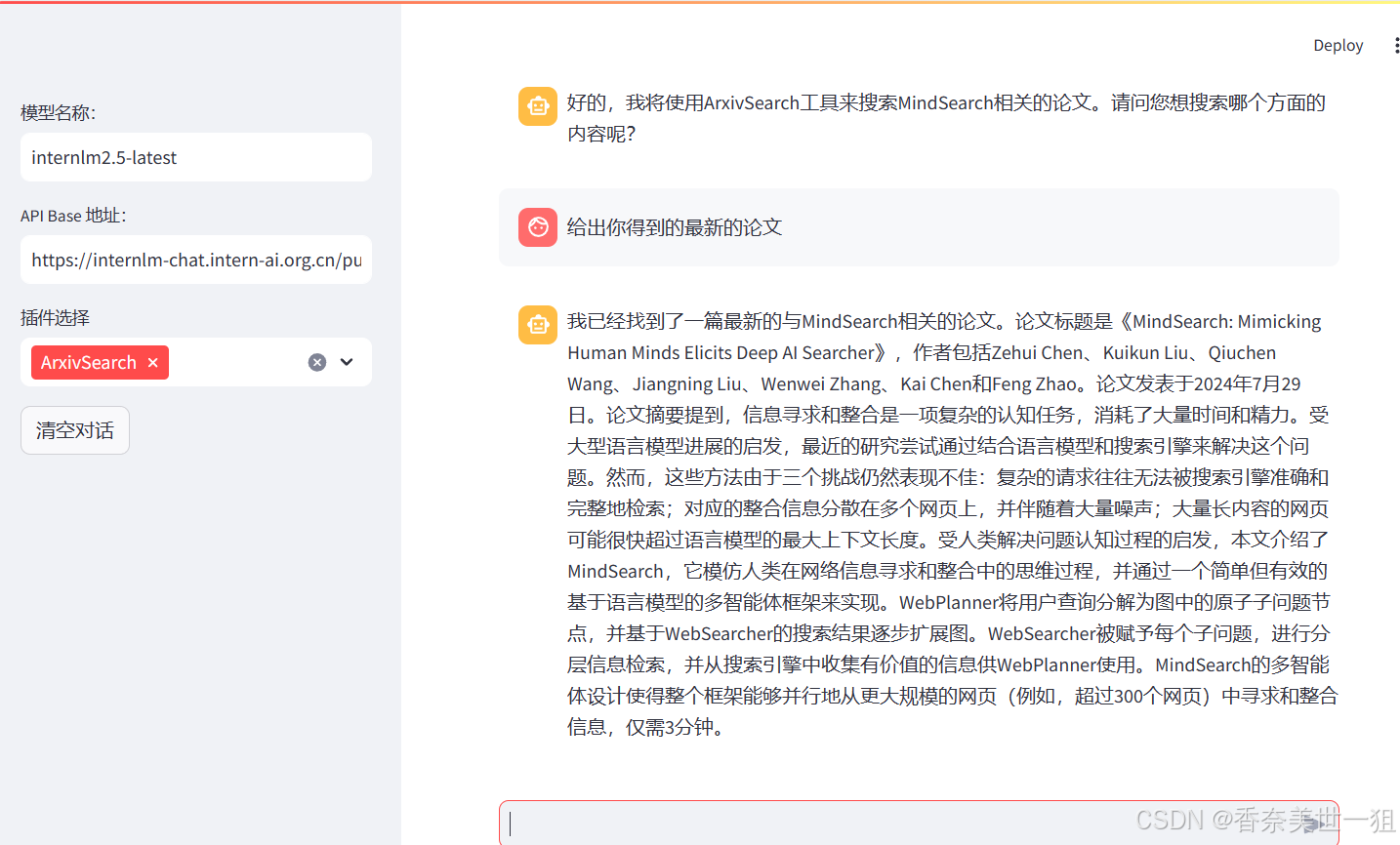
使用Arxiv插件
进阶:制作一个属于自己的Agent
方法:使用 Lagent 自定义工具主要分为以下3步:
(1)继承 BaseAction 类
(2)实现简单工具的 run 方法;或者实现工具包内每个子工具的功能
(3)简单工具的 run 方法可选被 tool_api 装饰;工具包内每个子工具的功能都需要被 tool_api 装饰
首先,为了使用和风天气的 API 服务,你需要获取一个 API Key。请按以下步骤操作:
(1)访问 和风天气 API 文档(需要注册账号)。
(2)点击页面右上角的“控制台”。
(3)在控制台中,点击左侧的“项目管理”,然后点击右上角“创建项目”。
(4)输入项目名称(可以使用“Lagent”),选择免费订阅,并在凭据设置中创建新的凭据。
(5)创建后,回到“项目管理”页面,找到你的 API Key 并复制保存。
获取到API Key后,回到开发机创建一个天气查询的接口
conda activate lagent
cd /root/agent_camp4/lagent/lagent/actions
touch weather_query.py
export weather_token='Your_KEY'py脚本内容
import os
import requests
from lagent.actions.base_action import BaseAction, tool_api
from lagent.schema import ActionReturn, ActionStatusCode
class WeatherQuery(BaseAction):
def __init__(self):
super().__init__()
self.api_key = os.getenv("weather_token")
print(self.api_key)
if not self.api_key:
raise EnvironmentError("未找到环境变量 'token'。请设置你的和风天气 API Key 到 'weather_token' 环境变量中,比如export weather_token='xxx' ")
@tool_api
def run(self, location: str) -> dict:
"""
查询实时天气信息。
Args:
location (str): 要查询的地点名称、LocationID 或经纬度坐标(如 "101010100" 或 "116.41,39.92")。
Returns:
dict: 包含天气信息的字典
* location: 地点名称
* weather: 天气状况
* temperature: 当前温度
* wind_direction: 风向
* wind_speed: 风速(公里/小时)
* humidity: 相对湿度(%)
* report_time: 数据报告时间
"""
try:
# 如果 location 不是坐标格式(例如 "116.41,39.92"),则调用 GeoAPI 获取 LocationID
if not ("," in location and location.replace(",", "").replace(".", "").isdigit()):
# 使用 GeoAPI 获取 LocationID
geo_url = f"https://geoapi.qweather.com/v2/city/lookup?location={location}&key={self.api_key}"
geo_response = requests.get(geo_url)
geo_data = geo_response.json()
if geo_data.get("code") != "200" or not geo_data.get("location"):
raise Exception(f"GeoAPI 返回错误码:{geo_data.get('code')} 或未找到位置")
location = geo_data["location"][0]["id"]
# 构建天气查询的 API 请求 URL
weather_url = f"https://devapi.qweather.com/v7/weather/now?location={location}&key={self.api_key}"
response = requests.get(weather_url)
data = response.json()
# 检查 API 响应码
if data.get("code") != "200":
raise Exception(f"Weather API 返回错误码:{data.get('code')}")
# 解析和组织天气信息
weather_info = {
"location": location,
"weather": data["now"]["text"],
"temperature": data["now"]["temp"] + "°C",
"wind_direction": data["now"]["windDir"],
"wind_speed": data["now"]["windSpeed"] + " km/h",
"humidity": data["now"]["humidity"] + "%",
"report_time": data["updateTime"]
}
return {"result": weather_info}
except Exception as exc:
return ActionReturn(
errmsg=f"WeatherQuery 异常:{exc}",
state=ActionStatusCode.HTTP_ERROR
)其中,WeatherQuery 类继承自 BaseAction,这是 Lagent 的基础工具类,提供了工具的框架逻辑。tool_api 是一个装饰器,用于标记工具中具体执行逻辑的函数,使得 Lagent 智能体能够调用该方法执行任务。run 方法是工具的主要逻辑入口,通常会根据输入参数完成一项任务并返回结果。
在具体函数实现上,利用GeoAPI 获取 LocationID,当用户输入的 location 不是经纬度坐标格式(如 116.41,39.92),则使用和风天气的 GeoAPI 将位置名转换为 LocationID,并通过 Weather API 获取目标位置的实时天气数据。最后,解析返回的 JSON 数据,并格式化为结构化字典:
在/root/agent_camp4/lagent/lagent/actions/__init__.py中加入下面的代码,用以初始化WeatherQuery方法:
from .weather_query import WeatherQuery
__all__ = [
'BaseAction', 'ActionExecutor', 'AsyncActionExecutor', 'InvalidAction',
'FinishAction', 'NoAction', 'BINGMap', 'AsyncBINGMap', 'ArxivSearch',
'AsyncArxivSearch', 'GoogleSearch', 'AsyncGoogleSearch', 'GoogleScholar',
'AsyncGoogleScholar', 'IPythonInterpreter', 'AsyncIPythonInterpreter',
'IPythonInteractive', 'AsyncIPythonInteractive',
'IPythonInteractiveManager', 'PythonInterpreter', 'AsyncPythonInterpreter',
'PPT', 'AsyncPPT', 'WebBrowser', 'AsyncWebBrowser', 'BaseParser',
'JsonParser', 'TupleParser', 'tool_api', 'WeatherQuery' # 这里
]记得Ctrl+S保存
接下来,我们将修改 Web Demo 脚本来集成自定义的 WeatherQuery 插件。
打开agent_api_web_demo.py, 修改内容如下,目的是将该工具注册进大模型的插件列表中,使得其可以知道。
- from lagent.actions import ArxivSearch
+ from lagent.actions import ArxivSearch, WeatherQuery
- # 初始化插件列表
- action_list = [
- ArxivSearch(),
- ]
+ action_list = [
+ ArxivSearch(),
+ WeatherQuery(),
+ ]再次启动lagent
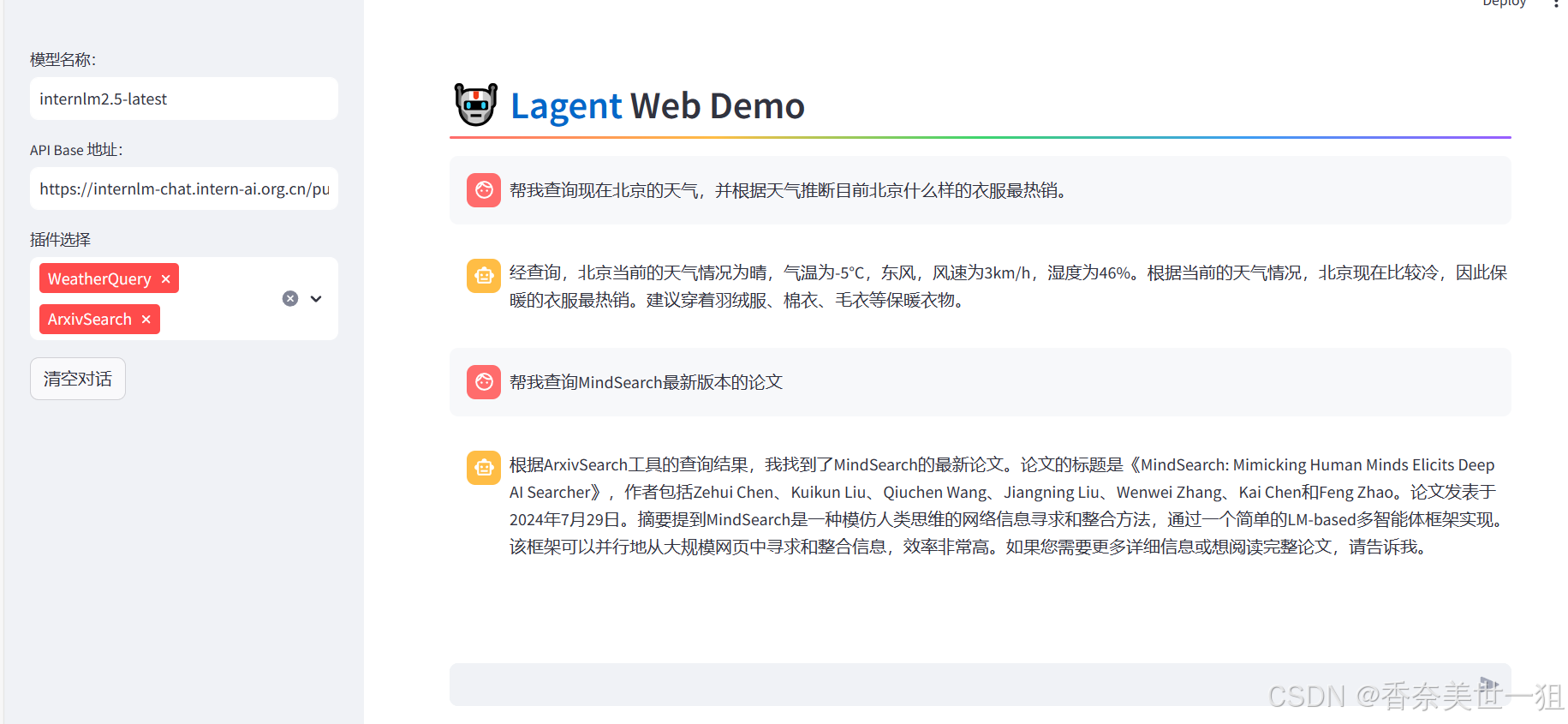
使用查询接口成果,并且llm根据天气给出了他自己的建议,比较符合一个智能体了。
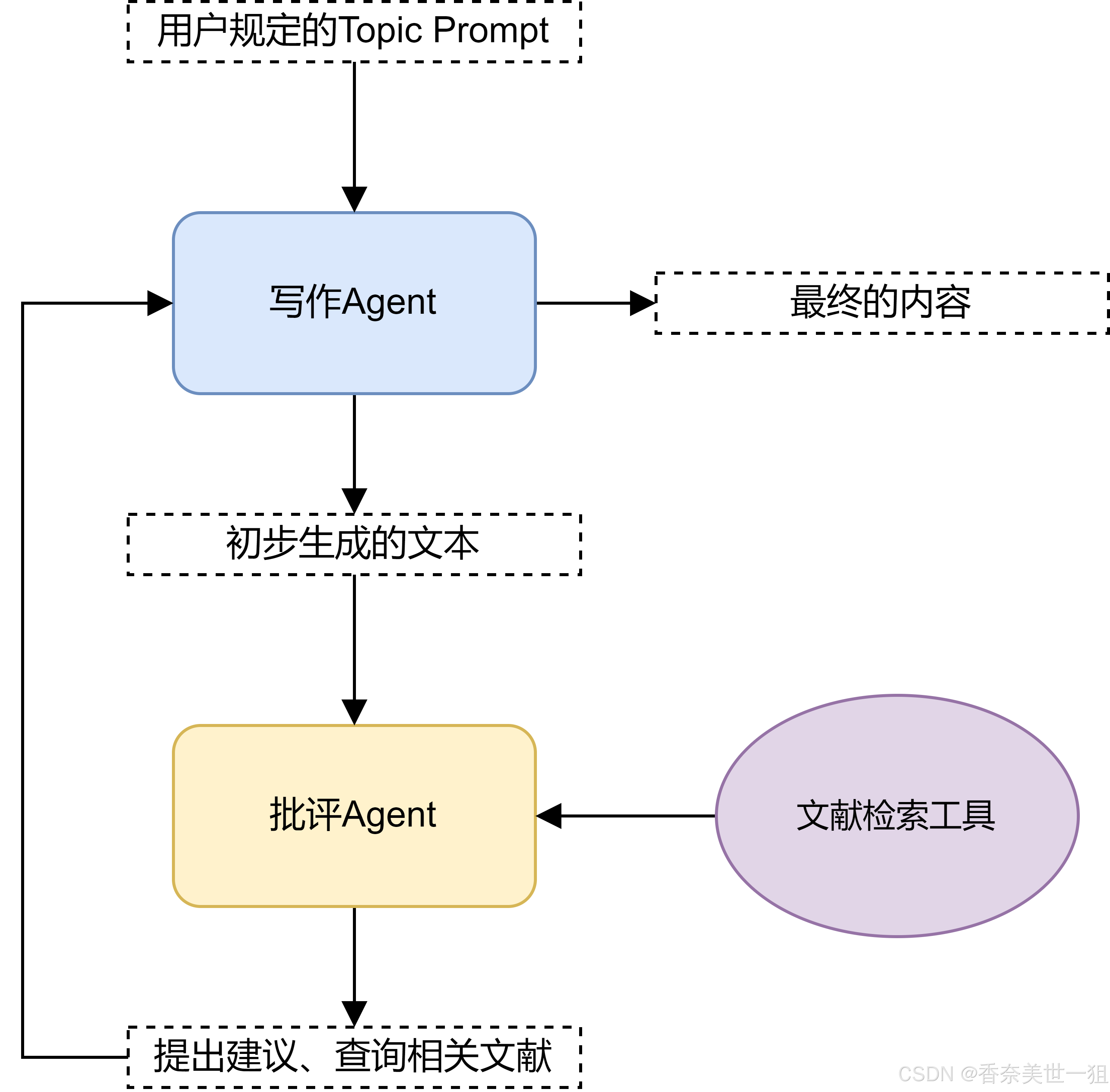
三、Lagent 实战,Multi-Agents博客写作系统的搭建
我们来使用 Lagent 来构建一个多智能体系统 (Multi-Agent System),展示如何协调不同的智能代理完成内容生成和优化的任务。我们的多智能体系统由两个主要代理组成:
(1)内容生成代理:负责根据用户的主题提示生成一篇结构化、专业的文章或报告。
(2)批评优化代理:负责审阅生成的内容,指出不足,推荐合适的文献,使文章更加完善。
Multi-Agents博客写作系统的流程图如下:
首先,创建一个新的 Python 文件 multi_agents_api_web_demo.py,并进入 lagent 环境:
conda activate lagent
cd /root/agent_camp4/lagent/examples
touch multi_agents_api_web_demo.py将下面的代码填入multi_agents_api_web_demo.py:
import os
import asyncio
import json
import re
import requests
import streamlit as st
from lagent.agents import Agent
from lagent.prompts.parsers import PluginParser
from lagent.agents.stream import PLUGIN_CN, get_plugin_prompt
from lagent.schema import AgentMessage
from lagent.actions import ArxivSearch
from lagent.hooks import Hook
from lagent.llms import GPTAPI
YOUR_TOKEN_HERE = os.getenv("token")
if not YOUR_TOKEN_HERE:
raise EnvironmentError("未找到环境变量 'token',请设置后再运行程序。")
# Hook类,用于对消息添加前缀
class PrefixedMessageHook(Hook):
def __init__(self, prefix, senders=None):
"""
初始化Hook
:param prefix: 消息前缀
:param senders: 指定发送者列表
"""
self.prefix = prefix
self.senders = senders or []
def before_agent(self, agent, messages, session_id):
"""
在代理处理消息前修改消息内容
:param agent: 当前代理
:param messages: 消息列表
:param session_id: 会话ID
"""
for message in messages:
if message.sender in self.senders:
message.content = self.prefix + message.content
class AsyncBlogger:
"""博客生成类,整合写作者和批评者。"""
def __init__(self, model_type, api_base, writer_prompt, critic_prompt, critic_prefix='', max_turn=2):
"""
初始化博客生成器
:param model_type: 模型类型
:param api_base: API 基地址
:param writer_prompt: 写作者提示词
:param critic_prompt: 批评者提示词
:param critic_prefix: 批评消息前缀
:param max_turn: 最大轮次
"""
self.model_type = model_type
self.api_base = api_base
self.llm = GPTAPI(
model_type=model_type,
api_base=api_base,
key=YOUR_TOKEN_HERE,
max_new_tokens=4096,
)
self.plugins = [dict(type='lagent.actions.ArxivSearch')]
self.writer = Agent(
self.llm,
writer_prompt,
name='写作者',
output_format=dict(
type=PluginParser,
template=PLUGIN_CN,
prompt=get_plugin_prompt(self.plugins)
)
)
self.critic = Agent(
self.llm,
critic_prompt,
name='批评者',
hooks=[PrefixedMessageHook(critic_prefix, ['写作者'])]
)
self.max_turn = max_turn
async def forward(self, message: AgentMessage, update_placeholder):
"""
执行多阶段博客生成流程
:param message: 初始消息
:param update_placeholder: Streamlit占位符
:return: 最终优化的博客内容
"""
step1_placeholder = update_placeholder.container()
step2_placeholder = update_placeholder.container()
step3_placeholder = update_placeholder.container()
# 第一步:生成初始内容
step1_placeholder.markdown("**Step 1: 生成初始内容...**")
message = self.writer(message)
if message.content:
step1_placeholder.markdown(f"**生成的初始内容**:\n\n{message.content}")
else:
step1_placeholder.markdown("**生成的初始内容为空,请检查生成逻辑。**")
# 第二步:批评者提供反馈
step2_placeholder.markdown("**Step 2: 批评者正在提供反馈和文献推荐...**")
message = self.critic(message)
if message.content:
# 解析批评者反馈
suggestions = re.search(r"1\. 批评建议:\n(.*?)2\. 推荐的关键词:", message.content, re.S)
keywords = re.search(r"2\. 推荐的关键词:\n- (.*)", message.content)
feedback = suggestions.group(1).strip() if suggestions else "未提供批评建议"
keywords = keywords.group(1).strip() if keywords else "未提供关键词"
# Arxiv 文献查询
arxiv_search = ArxivSearch()
arxiv_results = arxiv_search.get_arxiv_article_information(keywords)
# 显示批评内容和文献推荐
message.content = f"**批评建议**:\n{feedback}\n\n**推荐的文献**:\n{arxiv_results}"
step2_placeholder.markdown(f"**批评和文献推荐**:\n\n{message.content}")
else:
step2_placeholder.markdown("**批评内容为空,请检查批评逻辑。**")
# 第三步:写作者根据反馈优化内容
step3_placeholder.markdown("**Step 3: 根据反馈改进内容...**")
improvement_prompt = AgentMessage(
sender="critic",
content=(
f"根据以下批评建议和推荐文献对内容进行改进:\n\n"
f"批评建议:\n{feedback}\n\n"
f"推荐文献:\n{arxiv_results}\n\n"
f"请优化初始内容,使其更加清晰、丰富,并符合专业水准。"
),
)
message = self.writer(improvement_prompt)
if message.content:
step3_placeholder.markdown(f"**最终优化的博客内容**:\n\n{message.content}")
else:
step3_placeholder.markdown("**最终优化的博客内容为空,请检查生成逻辑。**")
return message
def setup_sidebar():
"""设置侧边栏,选择模型。"""
model_name = st.sidebar.text_input('模型名称:', value='internlm2.5-latest')
api_base = st.sidebar.text_input(
'API Base 地址:', value='https://internlm-chat.intern-ai.org.cn/puyu/api/v1/chat/completions'
)
return model_name, api_base
def main():
"""
主函数:构建Streamlit界面并处理用户交互
"""
st.set_page_config(layout='wide', page_title='Lagent Web Demo', page_icon='🤖')
st.title("多代理博客优化助手")
model_type, api_base = setup_sidebar()
topic = st.text_input('输入一个话题:', 'Self-Supervised Learning')
generate_button = st.button('生成博客内容')
if (
'blogger' not in st.session_state or
st.session_state['model_type'] != model_type or
st.session_state['api_base'] != api_base
):
st.session_state['blogger'] = AsyncBlogger(
model_type=model_type,
api_base=api_base,
writer_prompt="你是一位优秀的AI内容写作者,请撰写一篇有吸引力且信息丰富的博客内容。",
critic_prompt="""
作为一位严谨的批评者,请给出建设性的批评和改进建议,并基于相关主题使用已有的工具推荐一些参考文献,推荐的关键词应该是英语形式,简洁且切题。
请按照以下格式提供反馈:
1. 批评建议:
- (具体建议)
2. 推荐的关键词:
- (关键词1, 关键词2, ...)
""",
critic_prefix="请批评以下内容,并提供改进建议:\n\n"
)
st.session_state['model_type'] = model_type
st.session_state['api_base'] = api_base
if generate_button:
update_placeholder = st.empty()
async def run_async_blogger():
message = AgentMessage(
sender='user',
content=f"请撰写一篇关于{topic}的博客文章,要求表达专业,生动有趣,并且易于理解。"
)
result = await st.session_state['blogger'].forward(message, update_placeholder)
return result
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(run_async_blogger())
if __name__ == '__main__':
main()运行streamlit run multi_agents_api_web_demo.py,启动Web服务 输入话题,比如Semi-Supervised Learning:
可以看到,Multi-Agents博客写作系统正在按照下面的3步骤,生成、批评和完善内容。
Step 1:写作者根据用户输入生成初稿。
Step 2:批评者对初稿进行评估,提供改进建议和文献推荐(通过关键词触发 Arxiv 文献搜索)。
Step 3:写作者根据批评意见对内容进行改进。
输入一个感兴趣的话题:
他会分步生成内容,然后修改
以下是最终生成内容
最终优化的博客内容:
自我监督学习:解锁人工智能的无限潜能
在人工智能的广阔天地中,自我监督学习(Self-Supervised Learning, SSL)无疑是最具革命性的技术之一。它不仅改变了我们对机器学习传统框架的理解,更为AI的未来开辟了无限可能。今天,让我们一起深入探索自我监督学习的奥秘,揭开它那神秘的面纱。
什么是自我监督学习?
在传统的监督学习中,我们需要大量的标注数据来训练模型。这些数据就像是老师,告诉模型什么是对的,什么是错的。然而,标注数据往往昂贵且耗时,限制了AI的应用范围。自我监督学习则不同,它让AI系统自己给自己“找乐子”,通过预测数据中的某些部分来学习,而无需昂贵的标注。
想象一下,你置身于一个全新的环境中,四周是未知的景象与声音。但你并没有感到恐慌,因为你有自我探索的能力。你通过观察、尝试,逐渐理解了周围的世界。自我监督学习就是让机器拥有这样的能力,它通过预测缺失的信息,如填补图像的某些部分,或预测视频中下一帧的内容,从而学会理解数据的深层结构。
自我监督学习的原理
自我监督学习的核心在于构造“自我监督”信号。这些信号是基于数据自身的特性,无需人工干预。例如,在图像处理中,模型可以通过预测图像中某些被遮挡的部分来学习;在自然语言处理中,模型可以通过预测一个句子中缺失的单词来学习语言的结构和语义。
图像处理:填补空白
想象一下,你有一张照片,但其中一部分被遮住了。现在,你的任务是预测被遮住的部分可能是什么。这听起来像是一个棘手的任务,但对一个机器学习模型来说,这正是自我监督学习的精髓所在。通过尝试填补图像中的空白,模型不仅学会了识别图像中的物体,还学会了理解这些物体在空间中的位置关系。
自然语言处理:预测下一个词
在自然语言处理领域,自我监督学习的应用同样广泛。想象一下,你正在阅读一段文字,但其中一个词被隐藏了。你的任务是根据上下文猜测这个词是什么。这种“掩码语言模型”不仅能够帮助模型理解语言的语法结构,还能让它学会预测和生成文本,从而在机器翻译、文本生成等任务中表现出色。
自我监督学习的应用
自我监督学习的应用范围非常广泛,从图像识别到自然语言处理,从语音识别到推荐系统,它正在逐步改变我们对AI的传统认知。
图像识别
在图像识别领域,自我监督学习使得模型能够在没有大量标注数据的情况下,依然能够学习到图像的深层特征。这不仅降低了数据收集的成本,还提高了模型的泛化能力。
自然语言处理
在自然语言处理领域,通过预测缺失的单词或句子,模型能够学习到语言的语法结构和语义信息,从而在机器翻译、文本生成等任务中取得突破性进展。
推荐系统
在推荐系统中,通过分析用户的行为模式,自我监督学习能够帮助模型更准确地预测用户的兴趣偏好,从而提供更加个性化的推荐服务。
面临的挑战与未来展望
尽管自我监督学习展现出了巨大的潜力,但它也面临着不少挑战。如何设计有效的自我监督信号,如何确保学习到的信息是具有泛化性的,而非仅仅是对训练数据的过拟合,这些都是研究人员正在努力解决的问题。
未来,随着算法的不断优化和计算资源的不断增长,自我监督学习有望在更多领域发挥其独特的优势,为人类社会带来更多的便利和创新。或许有一天,我们的AI伙伴将不再需要人类的干预,而是通过自我学习,成为我们生活中更加智能、更加贴心的伙伴。
结语
自我监督学习,就像是一把开启新世界的钥匙,它让AI的学习过程变得更加自主、高效。在这个充满无限可能的时代,让我们一起期待自我监督学习为AI带来的更多惊喜吧!随着研究的深入,我们有理由相信,自我监督学习将引领AI进入一个更加智能、更加自主的未来。让我们共同期待,自我监督学习如何继续书写AI领域的辉煌篇章。
推荐文献
尽管目前没有直接的ArXiv结果被找到,但自我监督学习领域的文献丰富多样。建议读者查阅以下几篇具有代表性的论文,以获得更深入的理解和最新的研究进展:
- "Unsupervised Learning of Visual Features by Contrasting Cluster Assignments" - 这篇论文介绍了通过对比聚类分配来学习视觉特征的方法,展示了自我监督学习在图像识别中的应用。
- "Masked Autoencoders Are Scalable Vision Learners" - 该研究探讨了掩码自编码器在视觉学习中的可扩展性,展示了自我监督学习在图像处理中的潜力。
- "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" - 尽管BERT是一个监督学习模型,但它展示了预训练技术在自然语言处理中的重要性,为自我监督学习提供了灵感。
通过这些文献,读者可以更全面地了解自我监督学习在各个领域的应用和最新进展。希望本文能够激发您对自我监督学习的兴趣,并鼓励您进一步探索这一激动人心的领域。

















 5572
5572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









