






 本文介绍了一项日志库性能优化项目,通过引入多线程和环形缓冲区,分离日志生产者和消费者,以及使用宏定义优化条件判断,提高系统性能。同时,文章探讨了如何重定向输出和设置时间戳,以适应不同场景和解决之前的问题。
本文介绍了一项日志库性能优化项目,通过引入多线程和环形缓冲区,分离日志生产者和消费者,以及使用宏定义优化条件判断,提高系统性能。同时,文章探讨了如何重定向输出和设置时间戳,以适应不同场景和解决之前的问题。
1.背景
刚接手的项目,因为之前设计的日志库性能过低,要求在接口不变的情况下对性能进行优化,并支持多线程
原功能 : 按下ctrl + / 可将日志系统暂时关闭(再次按下恢复),可以设置日志是否打印到文件还是控制台,支持跨平台
原日志库接口如下:
日志系统初始化:
void Journal::InitJournal(bool console, bool file, u_int8_t grade);日志使用方式 :
void LogPrintf(grade, fmt, para...);日志析构方式:
void LogClose();等级为:
INFO < WARM < ERROR原设计方案为
//1. 定义Journal日志空间
namespace Journal {
constexpr u_int8_t INFO = 0;
constexpr u_int8_t WARM = 1;
constexpr u_int8_t ERROR = 2;
void InitJournal(bool console, bool file, u_int8_t grade);
void LogClose();
}
//2. 定义支持格式化解析及等级设置的打印函数,因为会使用到不定参数技术(即一个函数输入的参数数量不固定),所以该函数采用宏实现,该宏函数会直接将数据进行解析并将解析结果通过fopen或printf进行输出
#define LogPrintf(grade, fmt, para...) \
...\
std::printf("\033[1;40;37m[INFO: (%s) %s:%d] : " fmt "\033[0m\n", __FUNCTION__, __FILE__, __LINE__, ##para); \
...\
std::fprintf(Journal::LogFile, "[INFO: (%s) %s:%d] : " fmt "\n", __FUNCTION__, __FILE__, __LINE__, ##para); \
...\
性能过慢原因分析:
1. LogPrintf函数由于需要判断是否为文件保存模式以及日志的等级,没有针对常用日志等级进行分支优化,没有对文件刷进行优化(数据写一次刷一次)且较复杂的条件判断及会造成程序阻塞的IO处理事件较多,故性能十分低下,不适合嵌入式项目使用
2. 新方案设计
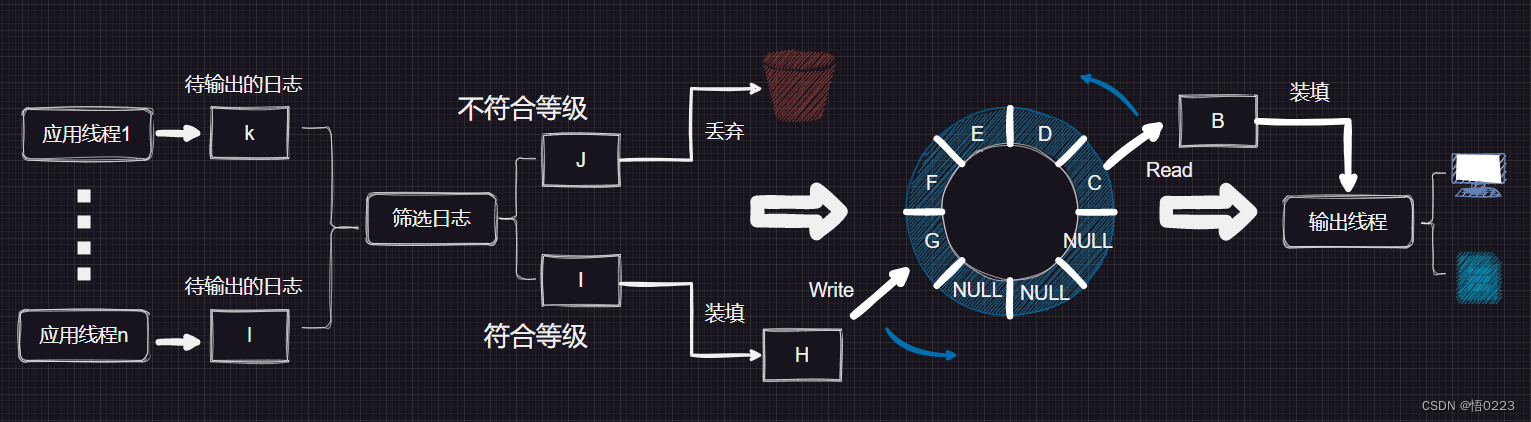
该系统分为日志生产者模块,环形缓冲区,日志消费者模块。
a.日志生产者模块
各个功能型线程将待输出的日志根据事先设置好的日志等级进行筛选,将符合日志等级的日志信息装填入环形缓冲区。
b. 环形缓冲区
将生产者模块生成的日志信息经由环形缓冲区一次拷贝发送到日志消费者模块,同时做好线程互斥处理。
c.日志消费者模块
对从缓冲区获取的日志进行样式设置,输出到文件或者终端。
3.各个模块的具体设计
a. 设置日志系统配置参数
将日志等级及文件保存开关通过宏实现,以此来减少内存消耗,以及在不同的日志等级设置针对性的性能优化
/**
* 是否保存日志到文件
*/
#define PRINT_TO_FILE
/**
* 日志等级设置
*/
#define DEBUG_INFO
// #define DEBUG_WARN
// #define DEBUG_ERROR由于日志等级使用宏实现,故在DEBUG_ERROR等级时需要将DEBUG_INFO及DEBUG_WARM取消定义,在DEBUG_WARM时需要将DEBUG_INFO取消定义并定义DEBUG_ERROR,而在DEBUG_INFO等级时,需要同时定义DEBUG_ERROR及DEBUG_WARM,具体实现如下
/**
* @brief this section is used to configure the log level macro
*
*/
//======================================
#ifdef DEBUG_ERROR
#undef DEBUG_INFO
#undef DEBUG_WARN
#endif // DEBUG_ERROR
#ifdef DEBUG_WARN
#undef DEBUG_INFO
#endif // DEBUG_WARN
#ifdef DEBUG_WARN
#define DEBUG_ERROR
#endif // DEBUG_WARN
#ifdef DEBUG_INFO
#define DEBUG_WARN
#define DEBUG_ERROR
#endif // DEBUG_INFO
//======================================b. 在不同的日志等级生成不同的函数
#ifdef DEBUG_INFO
#define LogPrintf(grade, fmt, para...) \
do \
{ \
if (grade >= Journal::INFO) \
{ \
... \
} \
} while (0);
#else
#ifdef DEBUG_WARN
#define LogPrintf(grade, fmt, para...) \
do \
{ \
if (grade >= Journal::WARM) \
{ \
... \
} \
} while (0);
#else
#ifdef DEBUG_ERROR
#define LogPrintf(grade, fmt, para...) \
do \
{ \
if (grade == Journal::ERROR) \
{ \
... \
} \
} while (0);
#endif // DEBUG_ERROR
#endif // DEBUG_WARN
#endif // DEBUG_INFO
通过这种方式,即可实现在不同的日志等级下针对不同等级的日志进行针对性优化
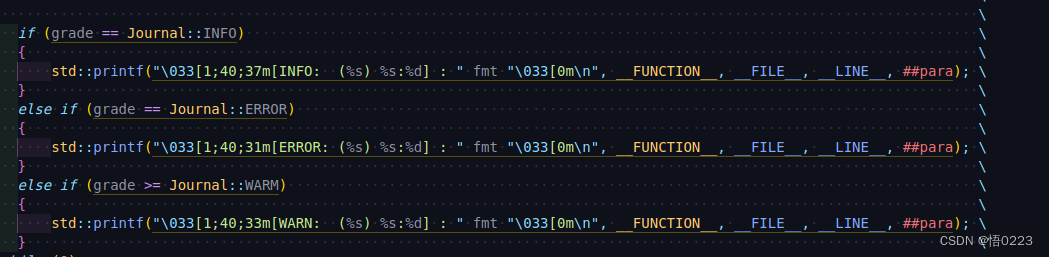
如同,本项目使用的日志,INFO的数据量最大,ERROR次之,WARM最小,所以按照该顺序进行排序
c. printf重定向输出
总所周知printf是将数据打印到终端,而fprintf是将数据打印到指定文件。两者之间看似没什么关系,但深度分析这个问题,在linux平台下一切皆文件,终端也是被设备树定义为了文件,printf应该是将数据打印到某个虚拟文件,然后系统调用驱动实现打印效果,那我们是否能fprintf的文件指定到printf所指向的文件,从而实现我们自己的printf,验证如下
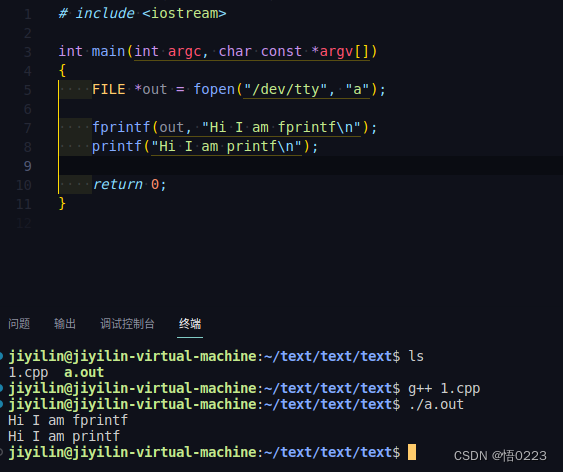
由验证结果,我们可以明确一个问题,printf就是特殊的已经指定好输出文件的fprintf,那如果我们把printf指向的文件重定向为某个具体的文件,那是否就可以将printf及std::cout打印到我们自定义的文件,验证如下:
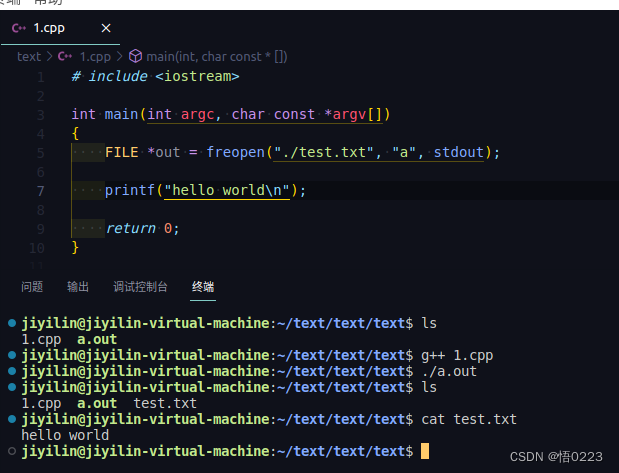
由此我们实现了重定向printf函数的目标
ps. 如果将printf重定向到了自定义文件,请在打印后调用std::endl进行刷新,否则数据可能无法及时写入文件
d. c++如何通过chrono库获取本地时间
c++11提供了一个chrono时间库,为我们提供了较为方便的时间处理接口
std::chrono::system_clock::to_time_t()可以为我们获取到此时的时间戳。(因为时间戳从1900年1月1日进行计算,所以在使用时应将传化后的年份加1900获取真实的年份,同时时间戳月份计算从0开始,为了符合大众习惯,需要将其加1)
localtime可以将时间戳转化为日常交流的时间单位。
std::stringstream可以向系统申请一个io流,方便开发者将字符串与其他数据类型进行拼接,并流式输出为字符串。
在printf函数进行数值格式输出时,只需在解析字符串进行设置即可,但在std::cout函数这种流式函数处理时数值格式设置较为复杂,本系统采用std::setw()函数用于设置数值整数位数,使用std::setfill设置整数位数不足补全字符
为了减少拷贝次数,这里就不将stringstream的数据流式输出了,采用stringstream::str()函数直接赋值给std::cout进行输出
time_t time_now = std::chrono::system_clock::to_time_t(std::chrono::system_clock::now());
auto clock = localtime(&time_now);
std::stringstream stream_time;
stream_time << "start time : [" << clock->tm_year + 0X76C << "-"
<< std::setw(0X02) << std::setfill('0') << clock->tm_mon + 0X01 << "-"
<< std::setw(0x02) << std::setfill('0') << clock->tm_mday << " "
<< std::setw(0x02) << std::setfill('0') << clock->tm_hour << ":"
<< std::setw(0x02) << std::setfill('0') << clock->tm_min << ":"
<< std::setw(0x02) << std::setfill('0') << clock->tm_sec << "]";
std::cout << stream_time.str() << std::endl;e. 输出样式设置
为了测试的时候方便查看日系情况,本系统将不采取默认终端样式表
std::printf("\033[1;40;37m[INFO: (%s) %s:%d] : " fmt "\033[0m\n", __FUNCTION__, __FILE__, __LINE__, ##para); “\033[...m”格式字符,用于标识采用用户设置样式表打印的起点(在文件中无法解析这个格式字符,当数据需要输出到文件时,应将这个格式字符去掉)
"\033[0m"格式字符,用于标识采用用户设置样式表打印的终点(在文件中无法解析这个格式字符,当数据需要输出到文件时,应将这个格式字符去掉)
__FUNCTION__ 该宏将返回一个字符串,內容为该行代码所在的函数名
__FILE__该宏将返回一个字符串,內容为该行代码所在的文件名
__LINE__该宏将返回一个数值,內容为该行代码所在文件的行数
f. 宏函数多参数模板
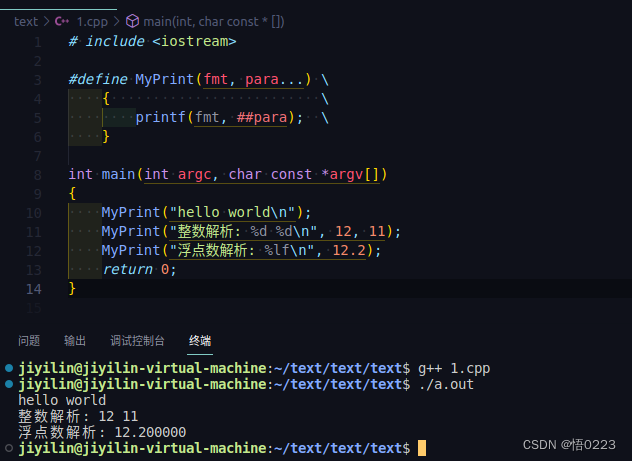
在书写宏函数时,若需要换行编写,应在宏函数除最后一行外每行的末尾放至‘\’符号,用于告诉预编译器将这上下两行合在一起处理
若宏函数需要输入不定数量、不定类型的形参,则应在宏函数定义时以“任意变量名称...”的格式进行定义,并在使用时采用##变量名格式
g. 环形缓冲区
请查看我上一期文章
4. 新方案分析
优点
将日志生产者及日志消费者分离,使得主程序无需等待日志输出。
通过宏定义处理,将条件判断提前到了程序预处理阶段,从汇编层面提升了程序运行速度。
针对不同等级的日志出现的频率做了判断顺序的优化。
将待输出的日志,全部送到缓冲区,再一条一条取出,解决了多线程并发问题。
通过重定向stdout指针,使得所有的输出都能保存到日志文件,方便后期debug,避免了之前因有部分日志在库内部打印,导致无法记录到文件的问题。
缺点
日志系统在运行时还存在较多的冗余判断,可以再做处理
现环形缓冲区为一次拷贝类型缓冲区,后期可优化为零拷贝

















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









