






目录
1、基本查询
MySQL从数据表中查询数据的基本语句为SELECT语句,SELECT语句的基本格式是:
SELECT
{ *| <字段列表> }
[
FROM <表1>,<表2>...
[WHERE <表达式>
[GROUP BY <group by definition>]
[HAVING <expression> [{operator> <expression>}...]
[ORDER BY <order by definition>]
[LIMIT [<offset>,] <row count>]
]
SELECT [字段1,字段2,...,字段n]
FROM [表或视图]
WHERE [查询条件];其中,各条句子的含义如下:
{*|<字段列表>}包含星号通配符和字段列表,表示查询的字段。其中,字段列表至少包含一个字段名称,如果要查询多个字段,多个字段之间用逗号隔开,最后一个字段不加逗号。
FROM <表1>,<表2>...,表1和表2表示查询数据的来源,可以是单个或者多个。
WHERE 子句是可选项,如果选择该项,将限定查询行必须满足的查询条件。
GROUP BY<字段>,该子句告诉MySQL如何显示查询出来的数据,并按照指定的字段分组。
HAVING过滤分组,GROUP BY可以和HAVING一起限定显示记录所满足的条件,只有满足条件的分组才会被显示。
[ORDER BY<字段>],该子句告诉MySQL按什么样的顺序显示查询出来的数据,可以进行的排序有升序(ASC),降序(DESC)。
[LIMIT<offset>,]<row count>],该子句告诉MySQL每次显示查询出来的数据条数。
(LIMIT [位置偏移量,]行数)
2、单表查询
(1)查询所有字段
在SELECT语句中使用星号(*)通配符查询所有字段
SELECT查询记录最简单的形式是从一个表中检索所有记录,实现的方法是使用星号(*)通配符指定查询所有列的名称,语法格式如下:
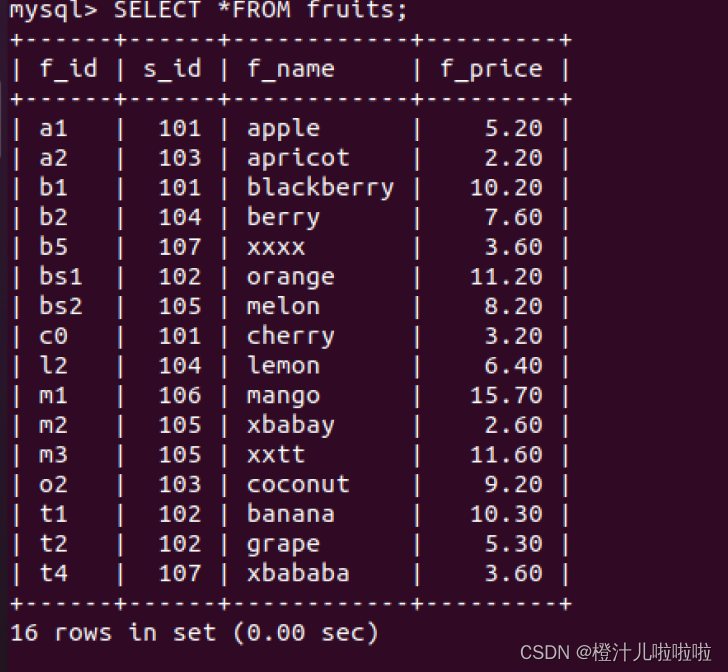
SELECT *FROM 表名;
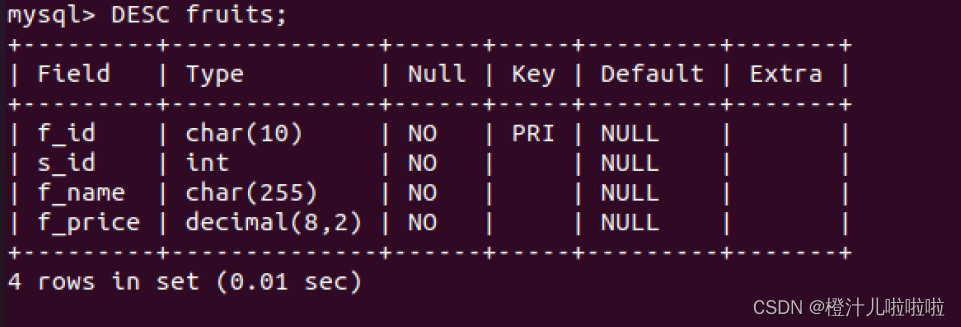
当然也可以用所有字段代替*(所有字段可用DESC命令查看表的结构:DESC 表名)
例1:
(2)查询指定字段
1)查询单个字段
查询表中的某一个字段,语法格式为:
SELECT 列名 FROM 表名;
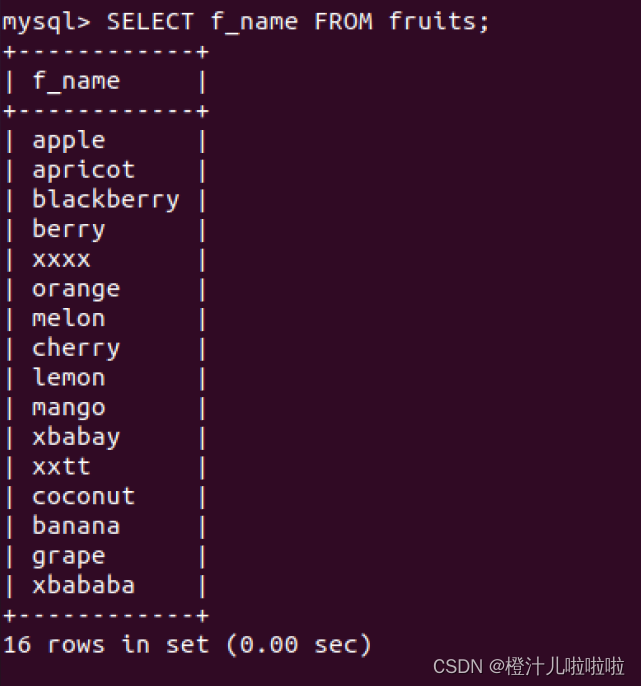
例2:查询fruits表中f_name列中所有的水果名称,SQL语句如下:
2)查询多个字段
查询多个字段的语法如下:
SELECT 字段1,字段2,...,字段名n FROM 表名;
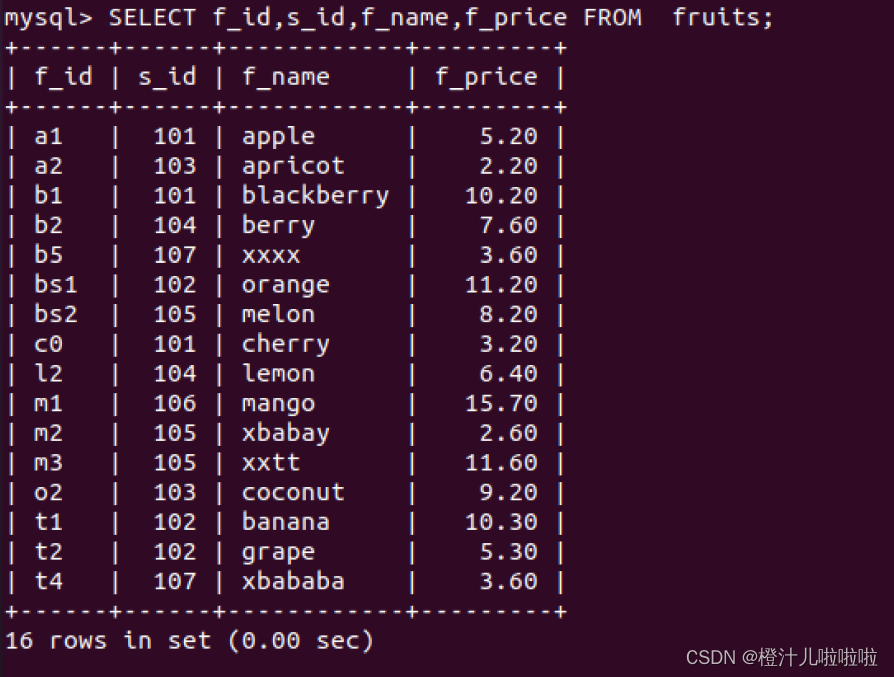
例3:从fruits表中获取f_name和f_price两列,SQL语句如下:
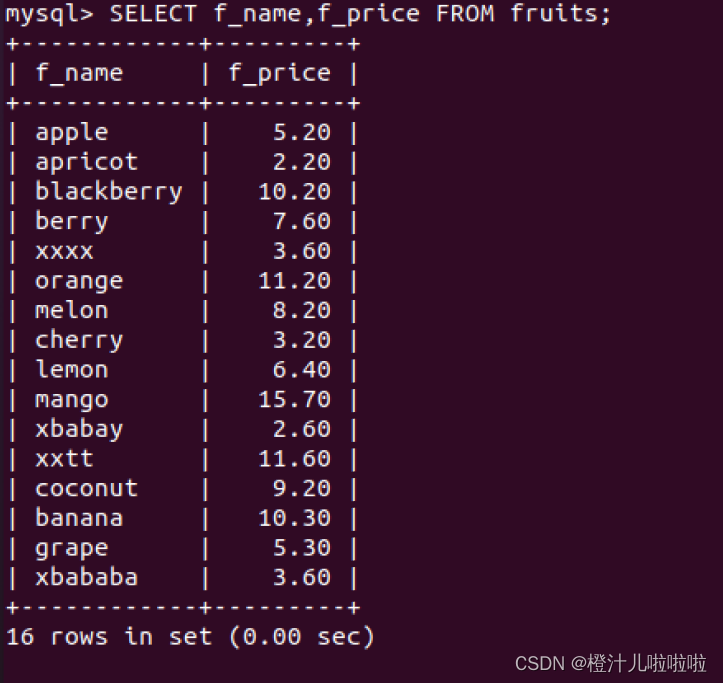
MySQL中的SQL语句是不区分大小写的,因此SELECT和select的作用是相同的,但是,许多开发人员习惯将关键字大写,数据列和表名小写,应该养成这样一个良好的编程习惯,这样写出来的代码更容易阅读和维护。
(3)查询指定记录
在SELECT语句中,通过WHERE字句可以对数据进行过滤,语法格式为:
SELECT 字段名1,字段名2,...,字段名n
FROM 表名
WHERE 查询条件
WHERE条件判断符
| 操作符 | 说明 |
| = | 相等 |
| <>,!= | 不相等 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| BETWEEN | 位于两值之间 |
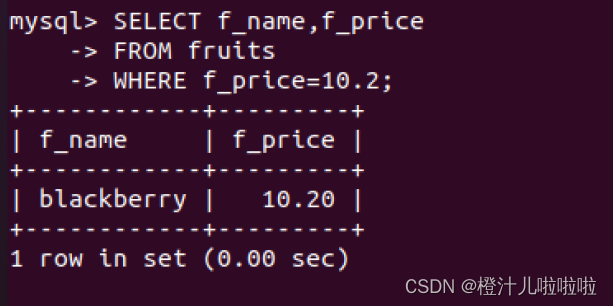
例4:查询价格位10.2元的水果的名称
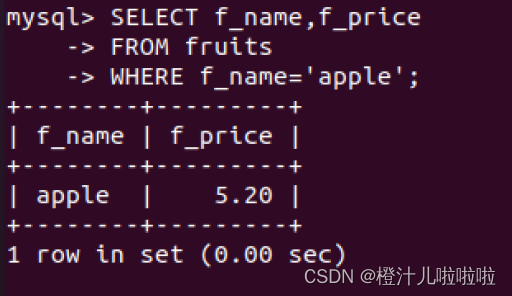
例5:查找名称为“apple”的水果的价格
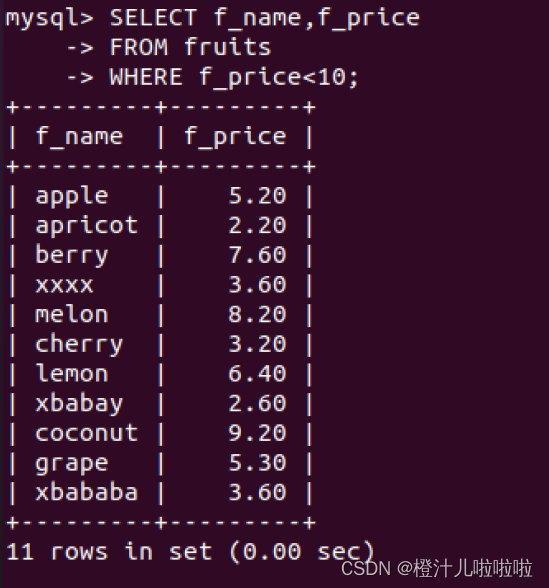
例6:查询价格小于10的水果的名称
(4)带IN关键字的查询
IN操作符用来查询满足指定范围内的条件的记录,使用IN操作符,将所有检索条件用括号括起来,检索条件之间用逗号分隔开,只要满足条件范围内的一个值即为匹配项
例7:查询s_id为101和102的记录,SQL语句如下:
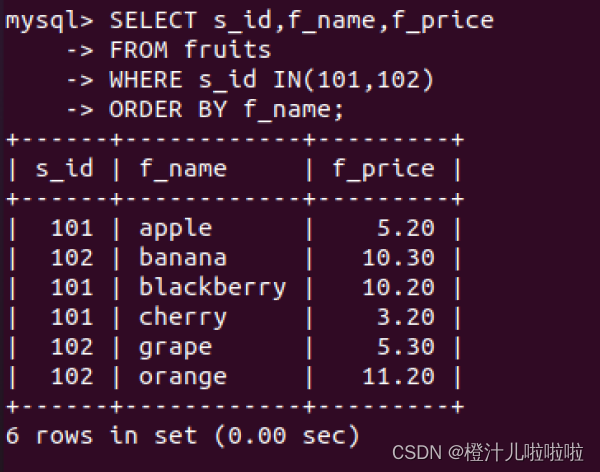
使用NOT来检索不在条件范围内的记录
例8:查询所有s_id不等于101也不等于102的记录,SQL语句如下:
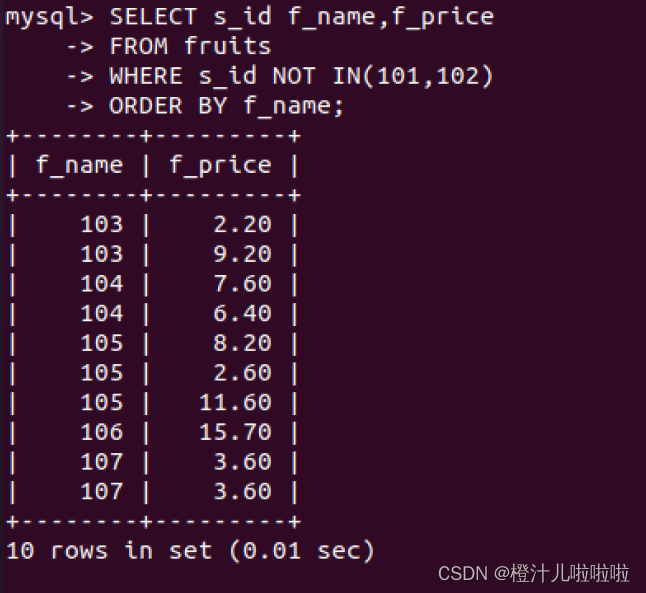
(5)带BETWEEN AND的范围查询
BETWEEN AND用来查询某个范围内的值
例9:查询价格在在2.00元到10.20元之间的水果名称和价格
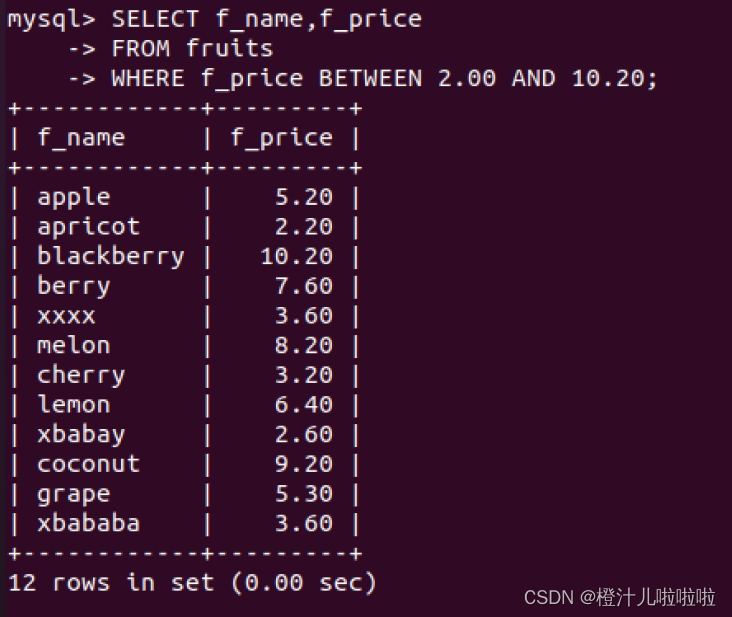
BETWEEN AND匹配范围内的所有值,包括开始值和结束值
BETWEEN AND操作符前可以加关键字NOT,表示指定范围之外的值
例10:查询价格在2.00元到10.20元之外的水果名称和价格
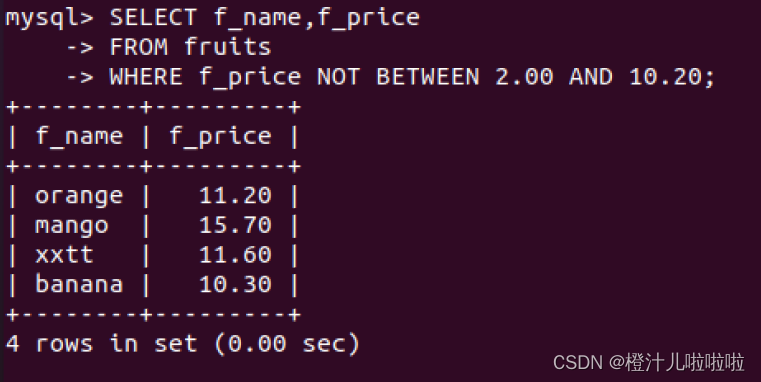
(6)带LIKE的字符匹配查询
我们要查找所有包含字符“ge”的水果名称,需要使用通配符进行匹配查找
通配符是一种在SQL的WHERE条件字句中拥有特殊意思的字符,SQL语句中支持多种通配符,可以和LIKE一起使用的通配符有‘%’和‘_’。
1)百分号通配符‘%’
百分号通配符‘%’,匹配任意长度的字符,甚至包括零字符
例11:查找所有以‘b’字符开头的水果
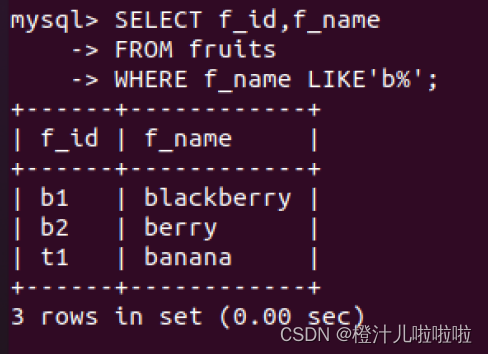
在搜索匹配时通配符‘%’可以放在不同的位置
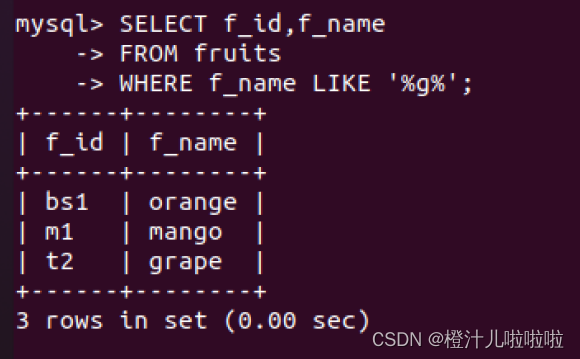
例12:在fruits表中,查询f_name中包含字母‘g’的记录
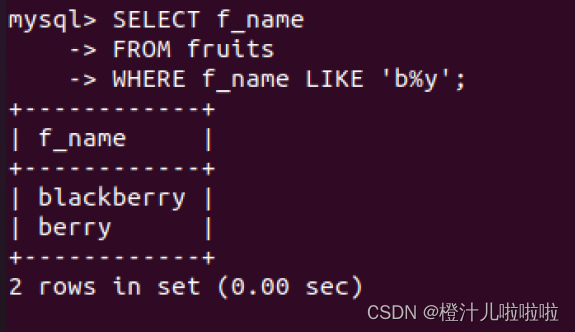
例13:在fruits表中,查询f_name中以‘b’开头并以‘y’结果的水果的名称
2)下划线通配符‘_’
下划线通配符‘_’,一次只能匹配任意一个字符
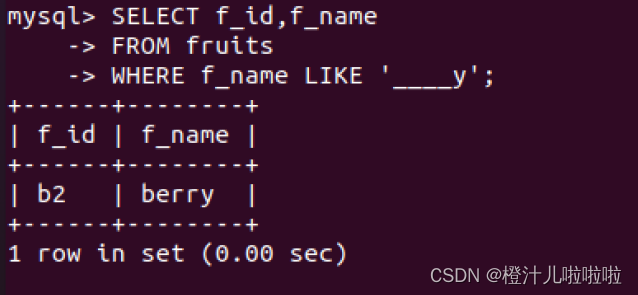
例14:在fruits表中,查询以字母‘y’结尾,且‘y’前面只有4个字母的记录
注意,单引号里面是4个_
(7)查询空值
空值一般表示数据未知,不使用或将在以后添加数据
在SELECT语句中使用IS NULL字句,可以查询某字段内容为空记录
首先在数据库中创建数据表customers,并插入数据
CREATE TABLE customers
(
c_id int NOT NULL AUTO_INCREMENT,
c_name char(50) NOT NULL,
c_address char(50) NULL,
c_city char(50) NULL,
c_zip char(10) NULL,
c_contact char(50) NULL,
c_email char(255) NULL,
PRIMARY KEY (c_id)
);INSERT INTO customers(c_id, c_name, c_address, c_city,
c_zip, c_contact, c_email)
VALUES(10001, 'RedHook', '200 Street ', 'Tianjin',
'300000', 'LiMing', 'LMing@163.com'),
(10002, 'Stars', '333 Fromage Lane',
'Dalian', '116000', 'Zhangbo','Jerry@hotmail.com'),
(10003, 'Netbhood', '1 Sunny Place', 'Qingdao', '266000',
'LuoCong', NULL),
(10004, 'JOTO', '829 Riverside Drive', 'Haikou',
'570000', 'YangShan', 'sam@hotmail.com');例15:查询customers表中c_email为空的记录c_id,c_name和c_email字段值
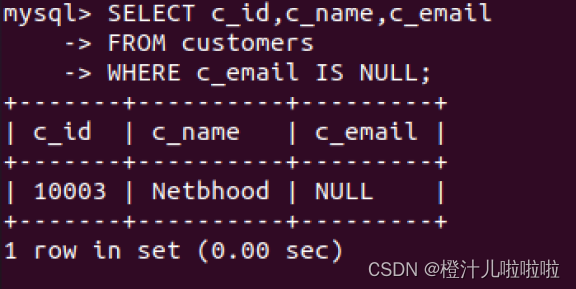
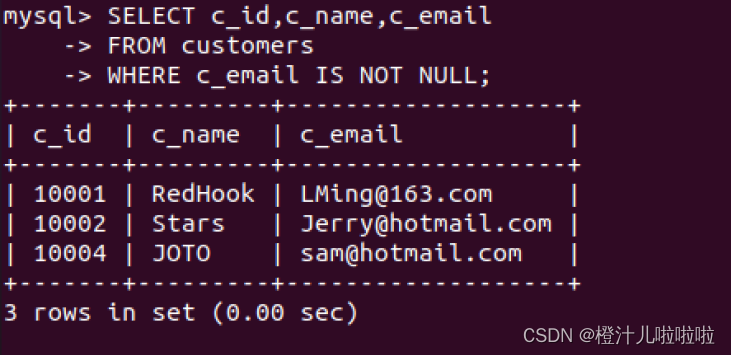
与IS NULL相反的是NOT NULL,该关键字查找字段不为空的记录。
例16:查询customers表中c_email不为空的记录c_id,c_name和c_email字段值
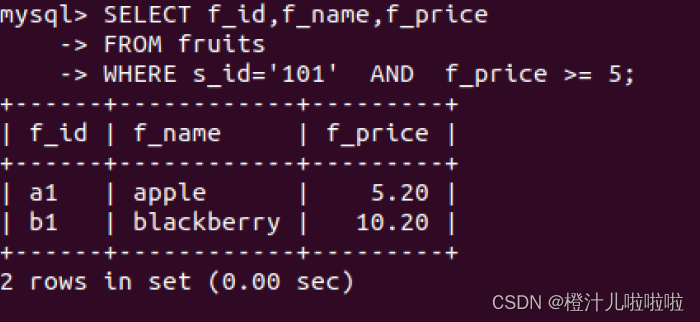
(8)带AND的多条件查询
在使用SELECT查询时,可以增加查询的限制条件,这样可以使查询的结果更加精确
例17:在fruits表中查询s_id=101并且f_price大于等于5的水果id,价格和名称
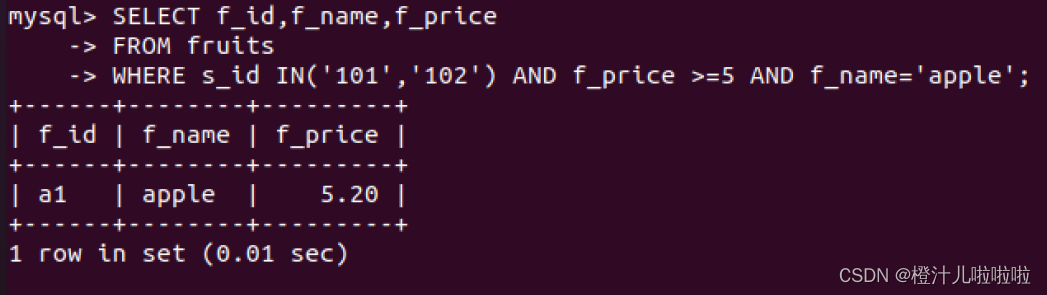
例18:在fruits表中查询s_id=101或者102,并且f_price大于等于5,f_name='apple'的水果价格和名称
(9)带OR的多条件查询
与AND相反,在WHERE声明中使用OR操作符,表示只需要满足其中一个条件的记录即可
OR也可以连接两个甚至多个查询条件,多个条件表达式之间用OR分开
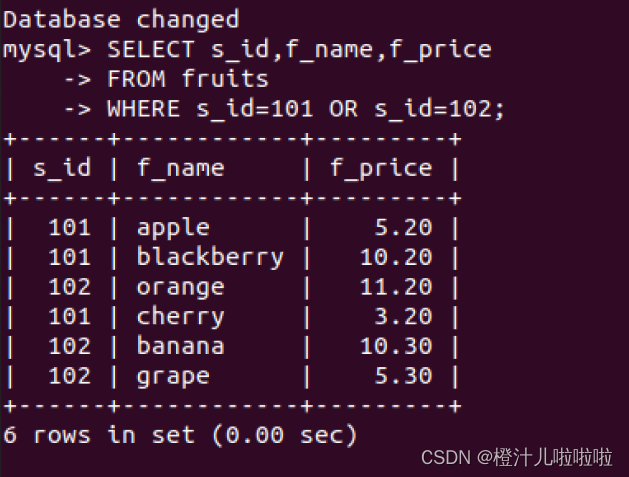
例19:查询s_id=101或者s_id=102的水果供应商的f_price和f_name
也可以使用IN操作符实现与OR相同的功能
例20:查询s_id=101或者s_id=102的水果供应商的f_price和f_name
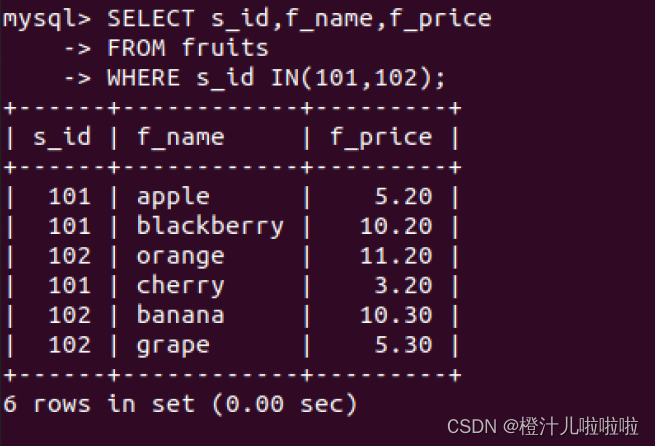
在这里可以看到,OR操作符和IN操作符使用后的结果是一样的,它们可以实现相同的功能,但是使用IN操作符使得检索语句更加简洁明了,并且IN执行的速度要快于OR,更重要的是,使用IN操作符可以执行更加复杂的嵌套查询。
OR可以和AND一起使用,但是在使用时要注意两者的优先级,由于AND的优先级高于OR,因此先对AND两边的操作数进行操作,再与OR中的操作数结合。
(10)查询结果不重复
可以使用DISTINCT关键字指示MySQL消除重复的记录值,语法格式为:
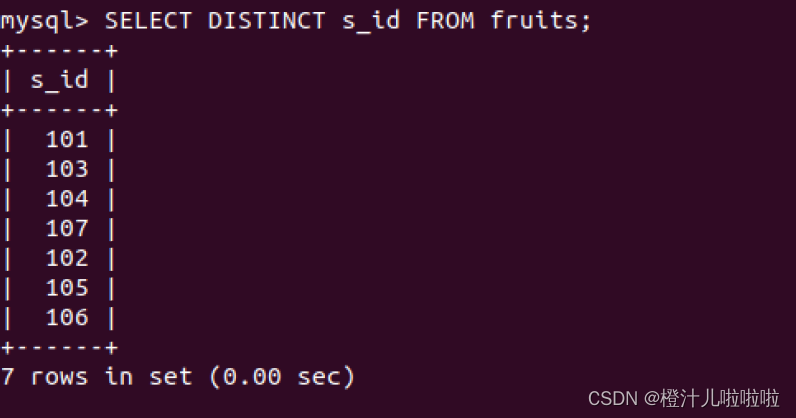
SELECT DISTINCT 字段名 FROM 表名;例21:查询fruits表中s_id字段的值,返回s_id字段值且不得重复
(11)对查询结果排序
1)单列排序
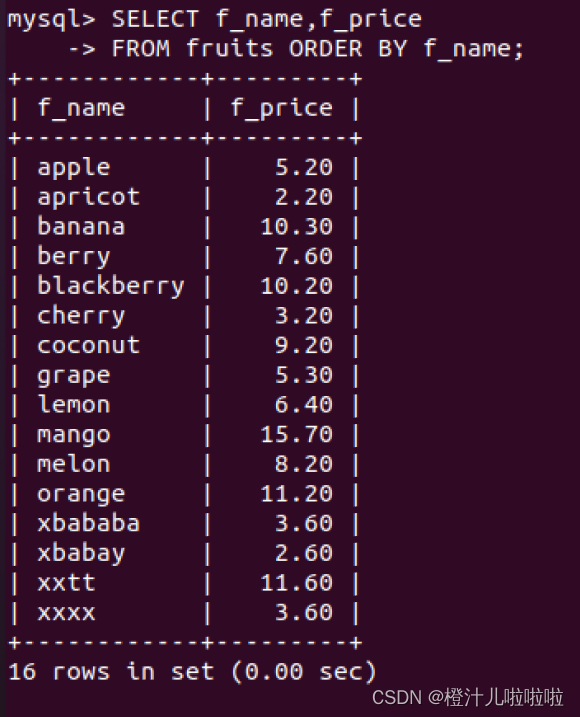
例22:查询fruits表的f_name字段值,并对其进行排序
2)多列排序
例23:查询fruits表的f_name字段和f_price字段,先按f_name排序,再按f_price排序
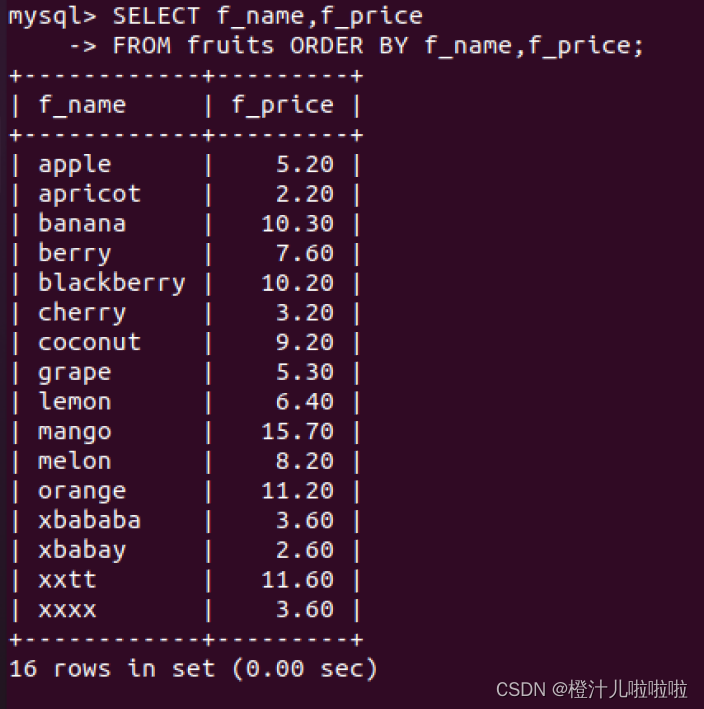
在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
3)指定排序方向
默认情况下,查询数据按字母升序进行排序(A~Z),但数据的排序并不仅限于此,还可以使用ORDER BY对查询结果进行降序排序(Z~A),这可以通过关键字DESC实现。
例24:查询fruits表的f_name字段和f_price字段,对结果按f_price降序方式排列
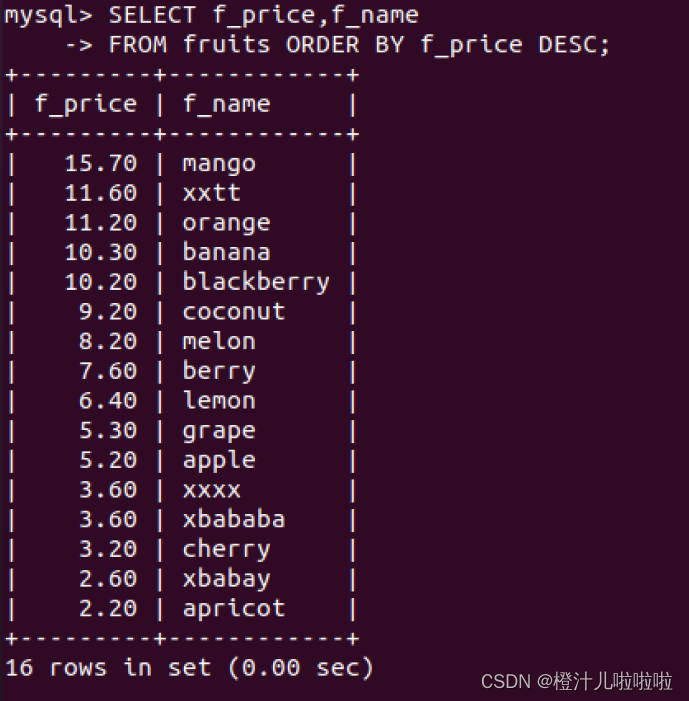
与DESC相反的是ASC(升序),将字段列中的数据按字母表顺序升序排列,实际上,在排序的时候ASC是默认的排序方式,所以加与不加都可以;
也可以对多列进行不同的顺序排列,如下:
例25:查询fruits表,先按f_price降序排列,再按f_name升序排列
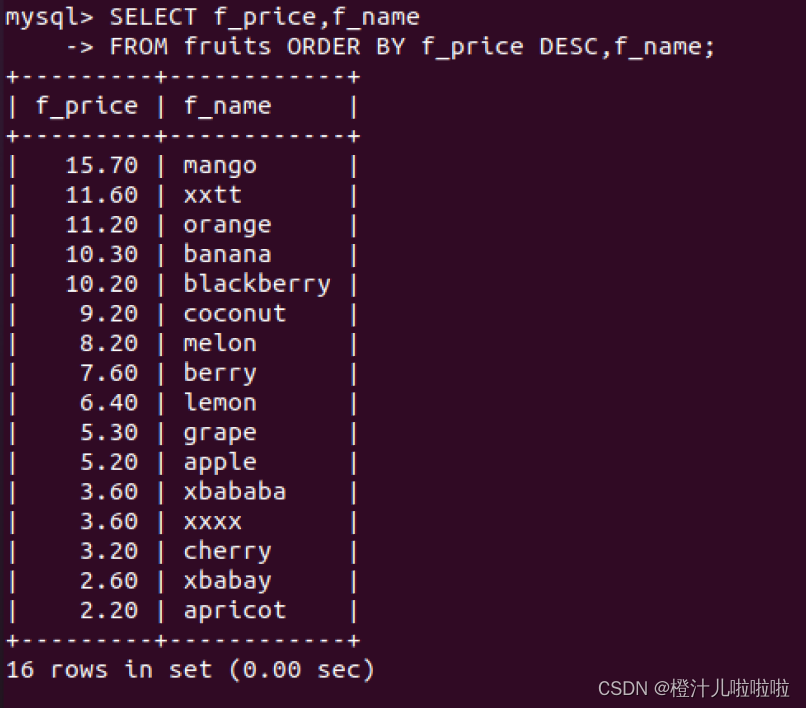
DESC排序方式只应用到直接位于其前面的字段上,由结果可以看出
DESC关键字只对其前面的列进行降序排列,在这里只对f_price排序,而并没有对f_name进行排序,因此,f_price按降序排列,而f_name列仍按升序排列。如果要对多列都进行降序排列,必须要在每一列的列名后面加DESC关键字。
(12)分组查询
分组查询是对数据按照某个或多个字段进行分组。MySQL中使用GROUP BY关键字对数据进行分组,基本语法形式为:
[GROUP BY 字段] [HAVING <条件表达式>]字段值为进行分组时所依据发列名称:HAVING<条件表达式>指定满足表达式限定条件的结果将被显示。
1)创建分组
GROUP BY关键字通常和集合函数一起使用,比如MAX(),MIN(),COUNT(),SUM(),AVG()
例如,要返回每个水果供应商提供的水果种类,这时就要在分组过程中用到COUNT()函数,把数据分为多个逻辑组,并对每个组进行集合计算。
例26:根据s_id对fruits表中的数据进行分组,SQL语句如下:
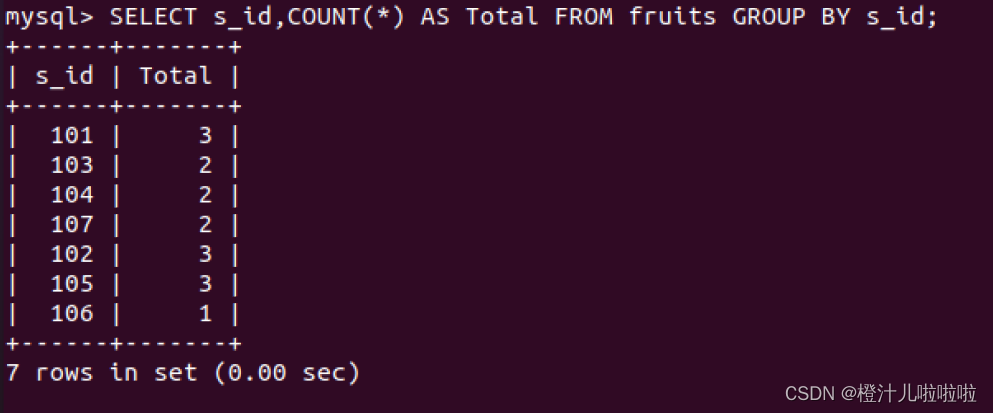
如果要查看每个供应商提供的水果的种类名称,改怎么办呢?可以在GROUP BY字句中使用GROUP_CONCAT()函数,将每个分组中各个字段的值显示出来。
例27:根据s_id对fruits表中的数据进行分组,将每个供应商的水果名称显示出来
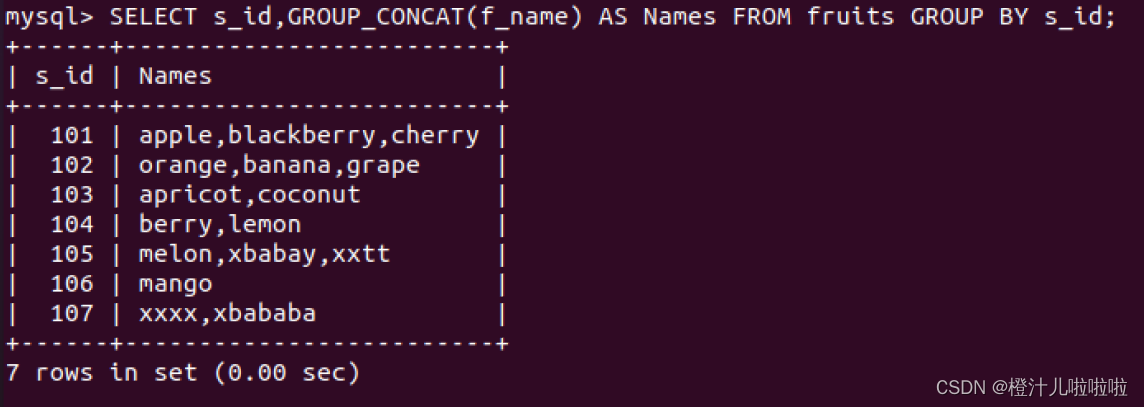
由结果可以看到,GROUP_CONCAT()函数将每个分组中的名称显示出来了,其名称的个数与COUNT()函数计算出来的相同。
2)使用HAVING过滤分组
GROUP BY可以和HAVING一起限定显示记录所满足的条件,只有满足条件的分组才会被显示。
例28:根据s_id对fruits表中的数据进行分组,并显示水果种类大于1的分组信息
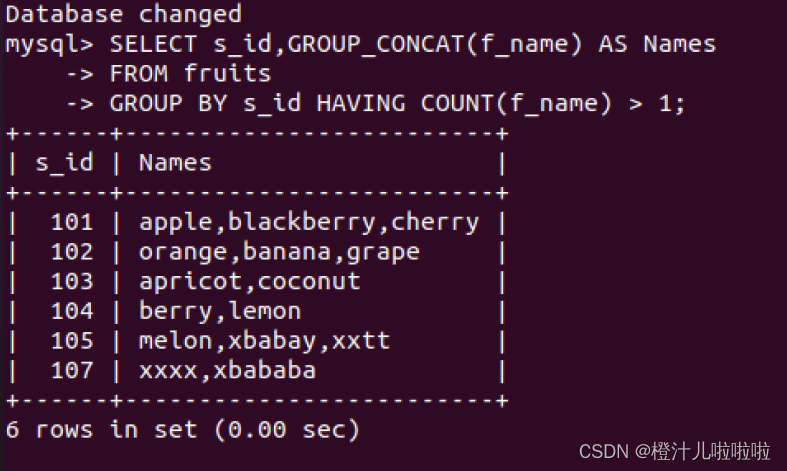
注意:GROUP_CONCAT和(f_name)中间不能有空格,有空格就会报错;COUNT(f_name)也是同样的,中间不能有空格。
注意,不能使用where,因为GROUP BY在where的后面使用;
HAVING关键字与WHERE关键字都是用来过滤数据的,两者有什么区别呢?其中重要的一点是,HAVING在数据分组之后进行过滤来选择分组,而HAVING在分组之前来选择记录。另外,WHERE排序的记录不再包括在分组中。
3)在GROUP BY字句中使用WITH ROLLUP
使用WITH ROLLUP关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量
例29:根据s_id对fruits表中的数据进行分组,并显示记录数量,SQL语句如下:
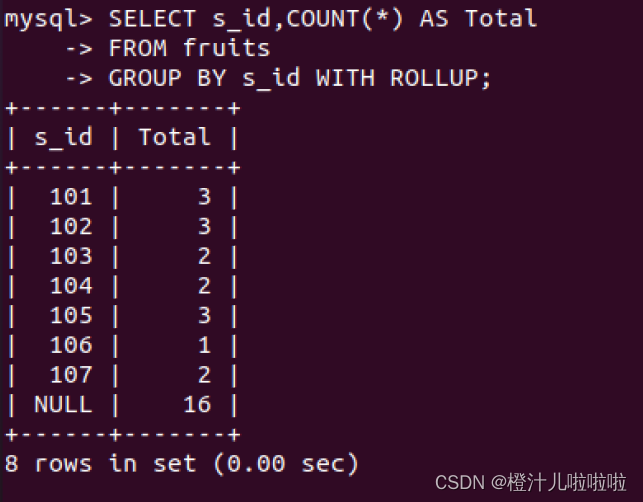
4)GROUP BY和ORDER BY一起使用
某些情况下需要对分组进行排序,在前面的介绍中,ORDER BY用来对查询的记录排序,如果和GROUP BY一起使用可以完成对分组的排序
为了演示效果,首先创建数据表,并插入数据:
CREATE TABLE orderitems
(
o_num int NOT NULL,
o_item int NOT NULL,
f_id char(10) NOT NULL,
quantity int NOT NULL,
item_price decimal(8,2) NOT NULL,
PRIMARY KEY (o_num,o_item)
);INSERT INTO orderitems(o_num,o_item,f_id,quantity,item_price)
VALUES(30001,1,'a1',10,5.2),
(30001,2,'b2',3,7.6),
(30001,3,'bs1',5,11.2),
(30001,4,'bs2',15,9.2),
(30002,1,'b3',2,20.0),
(30003,1,'c0',100,10),
(30004,1,'o2',50,2.50),
(30005,1,'c0',5,10),
(30005,2,'b1',10,8.99),
(30005,3,'a2',10,2.2),
(30005,4,'m1',5,14.99);例31:查询订单价格大于100的订单号和总订单价格
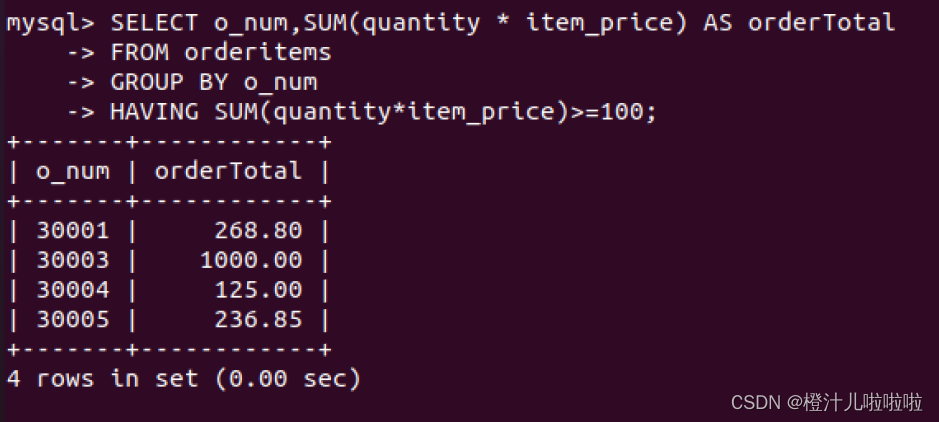
可以看到,返回的结果中orderTotal列的总订单价格并没有按照一定顺序显示,接下来使用ORDER BY关键字按总订单价格排序显示结果
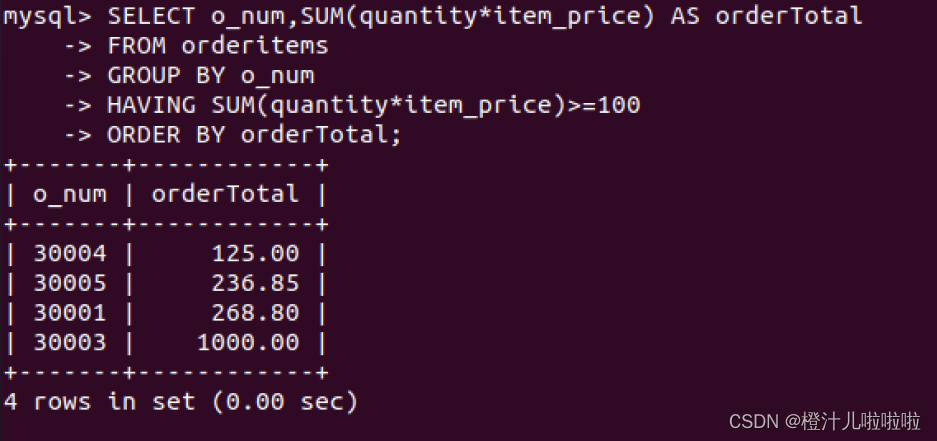
由结果可以看到,GROUP BY字句按订单号对数据进行分组,SUM()函数便可以返回总订单价格,HAVING字句对分组数据进行过滤,使得只返回总价格大于100的订单,最后使用ORDER BY字句排序输出。
注意:当使用ROLLUP时,不能同时使用ORDER BY 字句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
(13)使用LIMIT限制查询结果的数量
SELECT返回所有匹配的行,有可能是表中所有的行,若仅仅需要返回第一行或者前几行,可使用LIMIT关键字,基本语法格式如下:
LIMIT [位置偏移量,行数]第一个“位置偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是1,以此类推);第二个参数“行数”指示返回的记录条数。
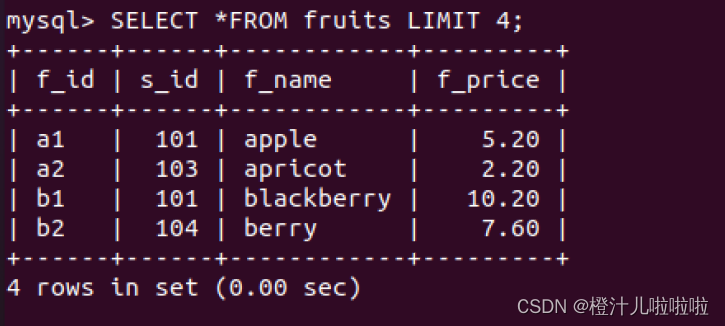
例32:显示fruits表查询结果的前4行
例33:在fruits表中,使用LIMIT字句,返回从第5个开始的行数长度为3的记录
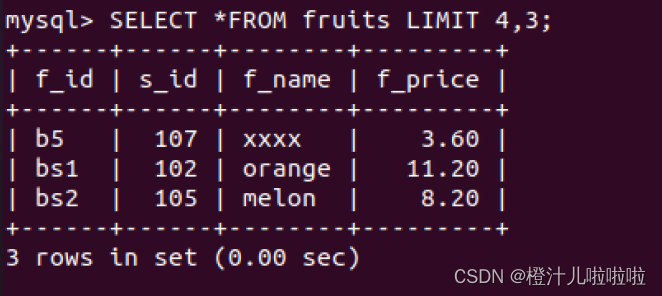
所以,带一个参数的LIMIT指定从查询结果的首行开始,唯一的参数表示返回的行数,即“LIMIT n”与“LIMIT 0,n”等价,带两个参数的LIMIT可以返回从任何一个位置开始的指定的行数。
返回第一行时,位置偏移量是0。因此,“LIMIT 1,1”将返回第二行,而不是第一行。
注意:MySQL 8.0中可以使用“LIMIT 4 OFFSET 3”,意思是获取从第4条记录开始后面的3条记录,和“LIMIT 3,4”返回的结果相同。
3、使用集合函数查询
有时候并不需要返回实际表中的数据,而只是对数据进行总结。MySQL提供一些查询功能,可以对获取的数据进行分析和报告,这些函数的功能有:计算数据表中记录行数的总和,计算某个字段下数据的总和,以及计算表中某个字段下的最大值,最小值或者平均值。
这些聚合函数的名称和作用如下表所示:
| 函数 | 作用 |
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值的和 |
(1)COUNT()函数
COUNT()函数统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数,其使用方法有两种:
COUNT(*)计算表中总的行数,不管某列是否有数值或者为空值;
COUNT(字段名)计算指定列下总的行数,计算时将忽略空值的行。
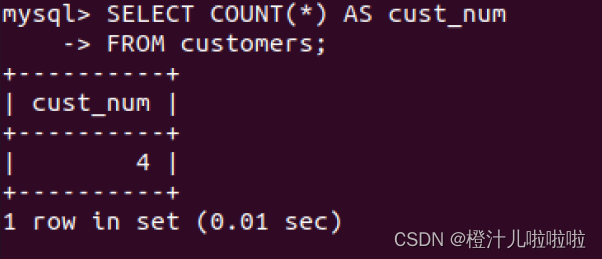
例34:查询customers表中总的行数,SQL语句如下:
例35:查询customers表中有电子邮箱的顾客的总数
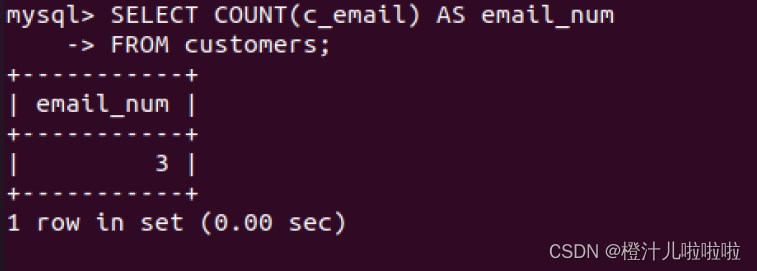
由查询结果可以看到,表中5个customer只有3个由email,customer的email为空值NULL的记录没有被COUNT()函数计算。
两个例子中不同的数值说明了**两种方式在计算总数的时候对待NULL值的方式不同:指定列的值为空的行被COUNT()函数忽略;如果不指定列,而在COUNT()函数中使用星号,则所有记录都不忽略。
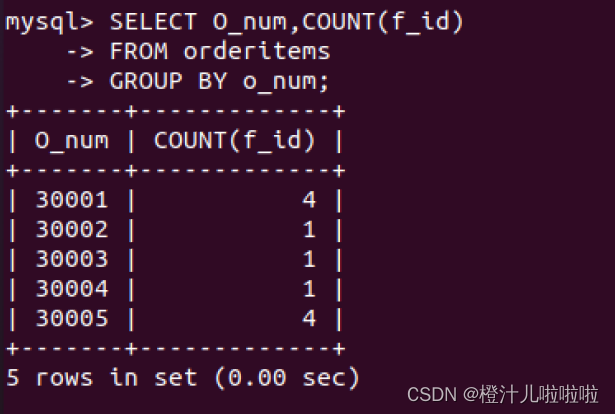
例36:在orderitems表中,使用COUNT()函数统计不同订单号中订购的水果种类
(2)SUM()函数
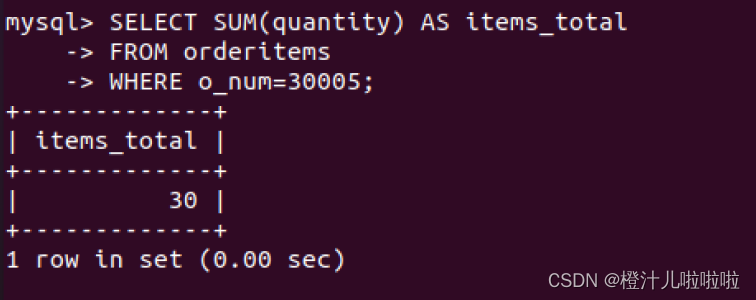
例37:在orderitems表中查询30005号订单一共购买的水果总量
SUM()可以和GROUP BY一起使用,来计算每个分组的总和。
例38:在orderitems表中,使用SUM()函数统计不同订单号中订购的水果总量
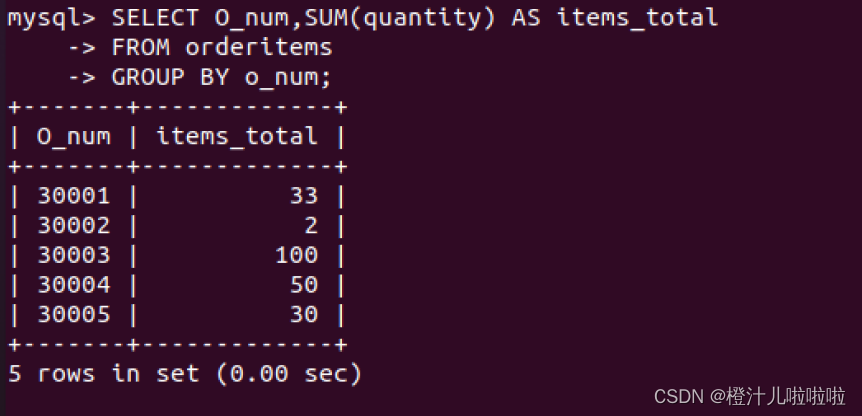
由查询结果可以看到,GROUP BY按照订单号o_num进行分组,SUM()函数计算每个分组中订购的水果的总量
注意:SUM()函数在计算时,忽略列值为NULL的行。
(3)AVG()函数
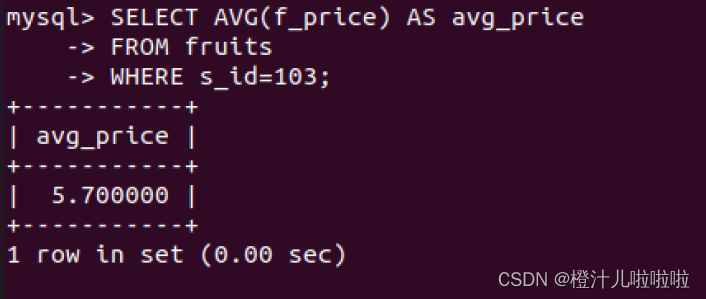
例39:在fruits表中,查询s_id=103的供应商的水果价格的平均值
AVG()可以与GROUP BY一起使用,来计算每个分组的平均值
例40:在fruits表中,查询每一个供应商的水果价格的平均值
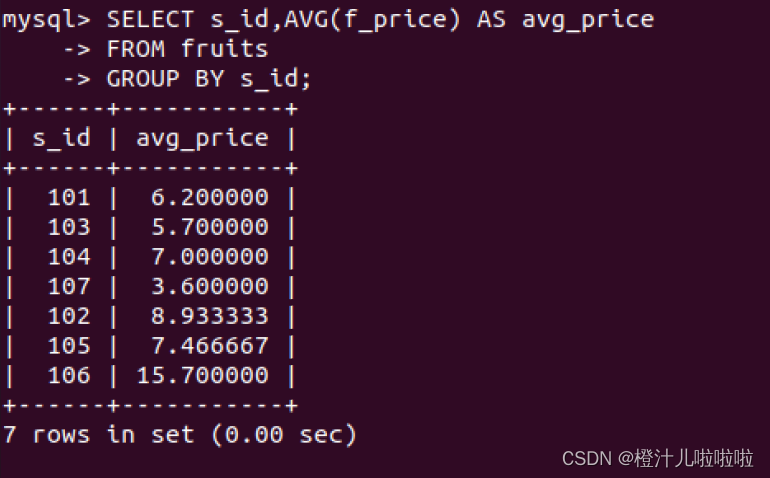
GROUP BY 关键字根据s_id字段对记录进行分组,然后计算出每个分组的平均值,这种分组求平均值的方法非常有用,例如,求不同班级学生成绩的平均值,求不同部门工人的平均工资,求各地的年平均气温等。
注意:AVG()函数使用时,其参数为要计算的列名称,如果要得到多个列的多个平均值,则需要在每一列上使用AVG()函数
(4)MAX()函数
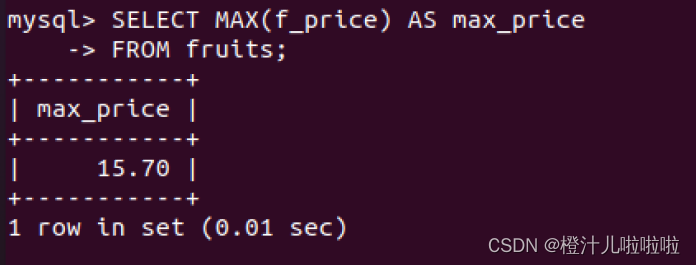
例41:在fruits表中查找市场上价格最高的水果值
例42:在fruits表中查找不同供应商提供的价格最高的水果值
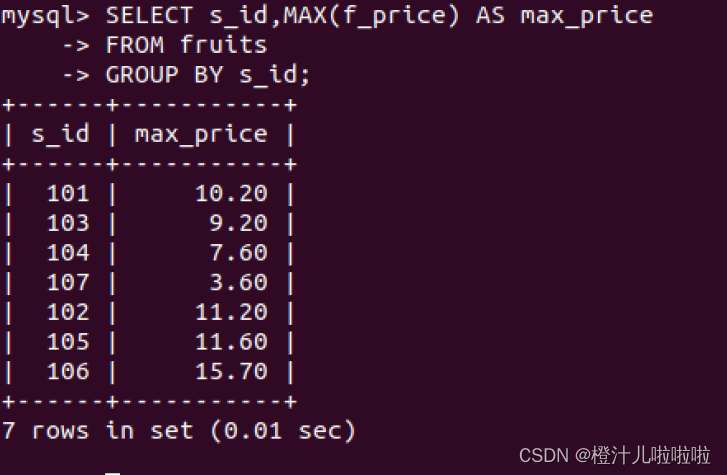
MAX()函数不仅适用于查找数值类型,也可应用于字符类型
例43:在fruits表中查找f_name的最大值
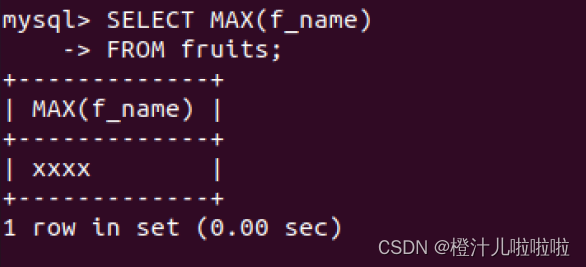
由结果可以看到,MAX()函数可以对字母进行大小判断,并返回最大的字符或者字符串值
注意:MAX()函数除了用来找出最大的列值或者日期值之外,还可以返回任意列中的最大值,包括返回字符类型的最大值。在对字符类型数据进行比较时,按照字符的ASCII码值大小进行比较,从a~z,a的ASCII码值最小,z的最大。在比较时,先比较第一个字母,如果相等,继续比较下一个字符,一直到两个字符不相等或者字符结束为止。例如,‘b’于‘t’比较时,‘t'为最大值;“bcd”与“bca”比较时,“bcd”为最大值。
(5)MIN()函数
例44:在fruits表中查找市场上价格最低的水果值
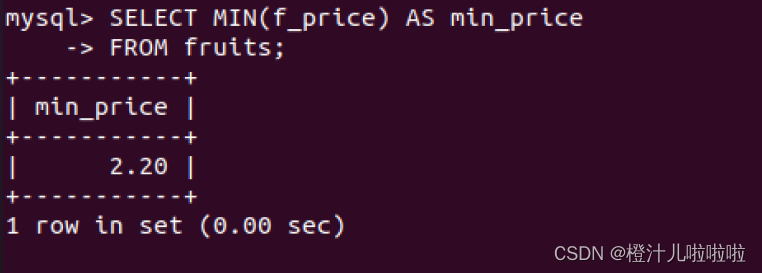
MIN()也可以和GROUP BY关键字一起使用,求出每个分组中的最小值
例45:在fruits表中查找不同供应商提供的价格最低的水果值
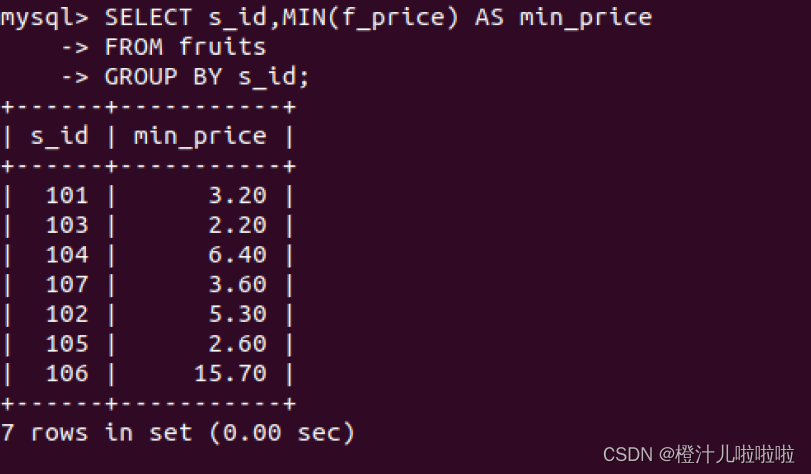
MIN()函数与MAX()函数类似,不仅适用于查找数值类型,也可应用于字符类型;
4、连接查询
连接是关系型数据库模型的主要特点;连接查询是关系数据库中最主要的查询,主要包括内连接,外连接等。通过连接运算可以实现多个表查询,在关系数据库管理系统中,表建立时各数据之间的关系不必确定,常把一个实体的所有信息存放在一个表中。当查询数据时,通过连接操作查询出存放在多个表中的不同实体的信息。当两个或多个表中存在相同意义的字段时,便可以通过这些字段对不同的表进行连接查询。
首先需要创建表suppliers并插入数据:
CREATE TABLE suppliers
(
s_id int NOT NULL AUTO_INCREMENT,
s_name char(50) NOT NULL,
s_city char(50) NULL,
s_zip char(10) NULL,
s_call CHAR(50) NOT NULL,
PRIMARY KEY(s_id)
);INSERT INTO suppliers(s_id,s_name,s_city,s_zip,s_call)
VALUES(101,'FastFruit Inc','Tianjin','300000','48075'),
(102,'LT Supplies','Chongqing','400000','44333'),
(103,'ACME','Shanghai','200000','90046'),
(104,'FNK Inc','Zhongshan','528437','11111'),
(105,'Good Set','Taiyuang','030000','22222'),
(106,'Just Eat Ours','Beijing','010','45678'),
(107,'DK Inc','Zhengzhou','450000','33332');(1)内连接查询
在内连接查询中,只有满足条件的记录才能出现在结果关系中。
例46:在fruits表和suppliers表之间使用内连接查询
查询之前,查看两个表的结构
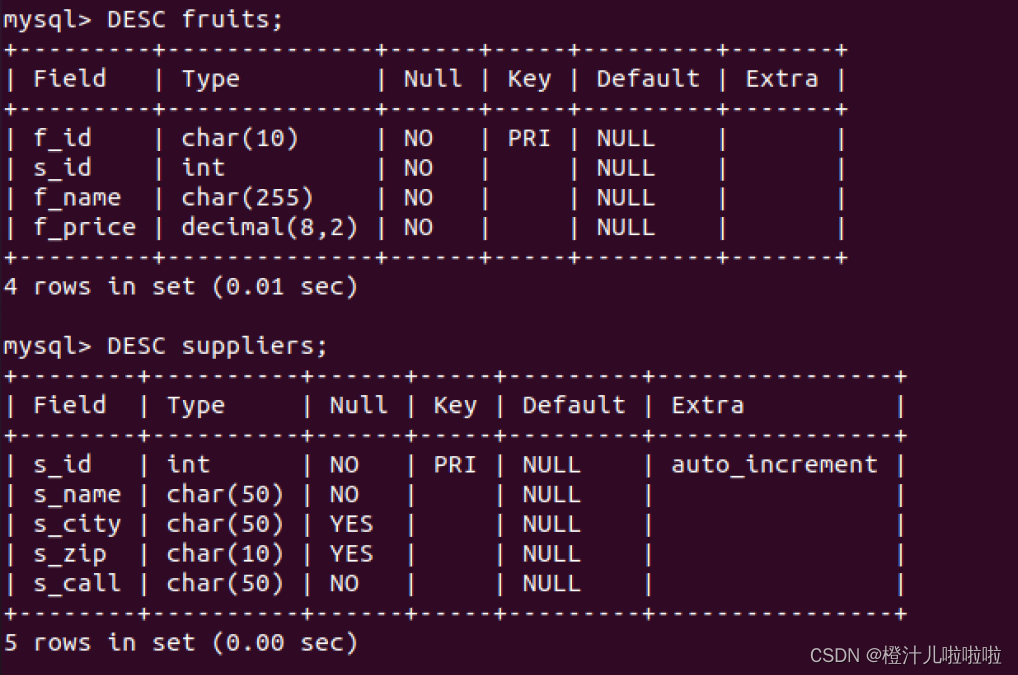
由结果可以看到,fruits表和suppliers表中都有相同数据类型的字段s_id,两个表通过s_id字段进行练习,接下来从fruits表中查询f_name,f_price字段,从suppliers表中查询s_id,s_name。
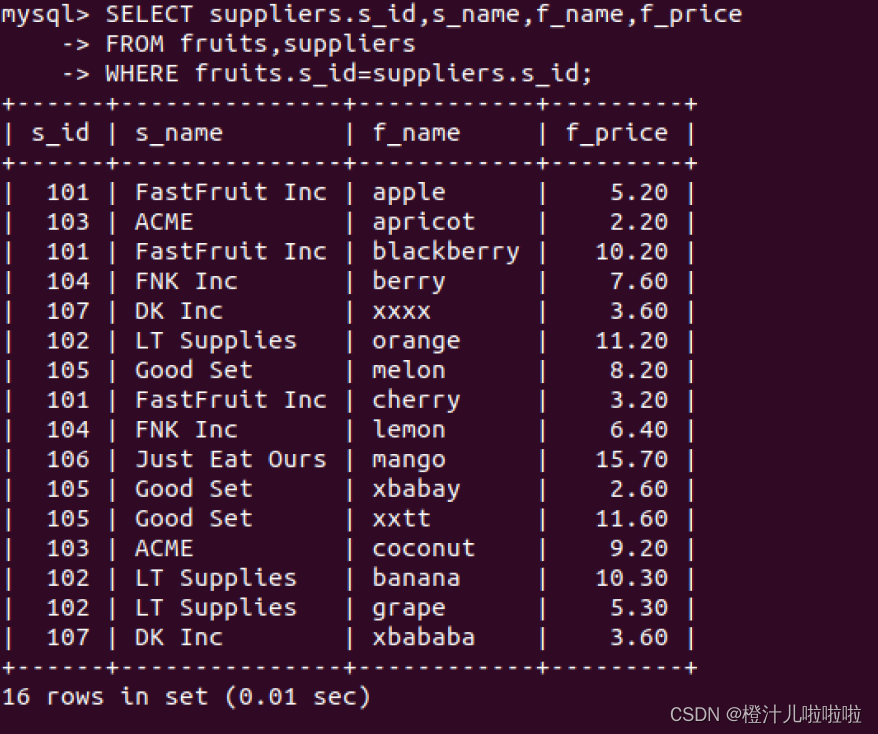
在这里,SELECT语句与前面所介绍的一个最大的差别是:SELECT后面指定的列分别属于两个不同的表,同时FROM字句列出了两个表fruits和suppliers。WHERE字句在这里作为过滤条件,指明只有两个表中s_id字段值相等的时候才符合连接查询的条件。
注意:因此fruits表和suppliers表中有相同的字段s_id,因此在比较的时候完全限定表名(格式为“表名.列名”),如果只给出s_id,MySQL将不知道指的是哪一个,并返回错误信息。
下面的内连接查询语句返回与前面完全相同的结果。
例47:在fruits表和suppliers表之间,使用INNER JOIN语法进行内连接查询
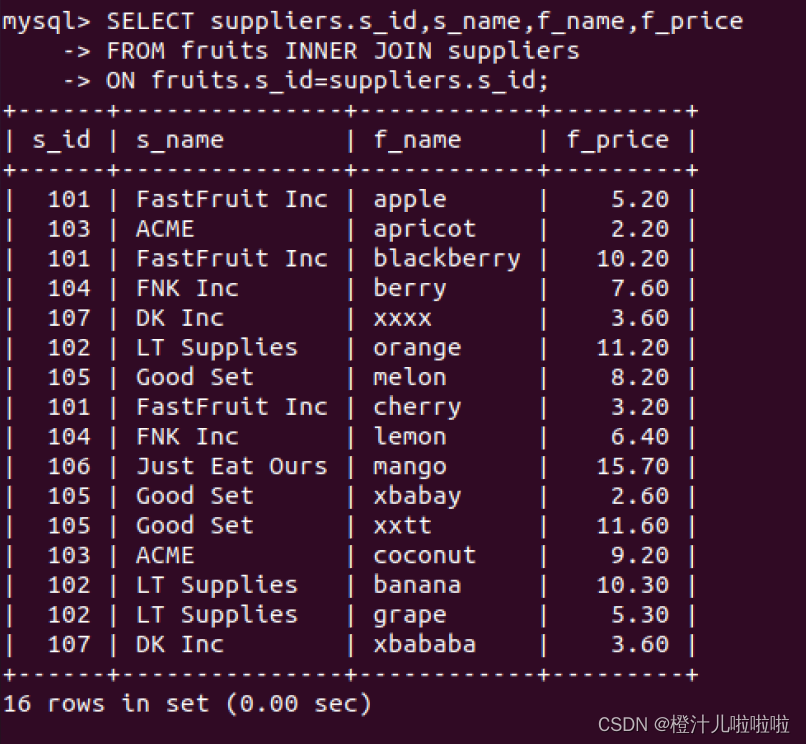
在这里的查询语句中,两个表之间的关系通过INNER JOIN指定,使用这种语法的时候,连接的条件使用ON字句而不是WHERE,ON和WHERE后面指定的条件相同。
注意:使用WHERE字句定义连接条件比较简单明了,而INNER JOIN语法是ANSI SQL的标准规范,使用INNER JOIN连接语法能够确保不会忘记连接条件,而且WHERE字句在某些时候会影响查询的性能。
如果在一个连接查询中,涉及的两个表都是同一个,这种查询称为自连接查询。自连接是一种特殊的内连接,它是指相互连接的表在物理上为同一张表,但可以在逻辑上分为两张表。
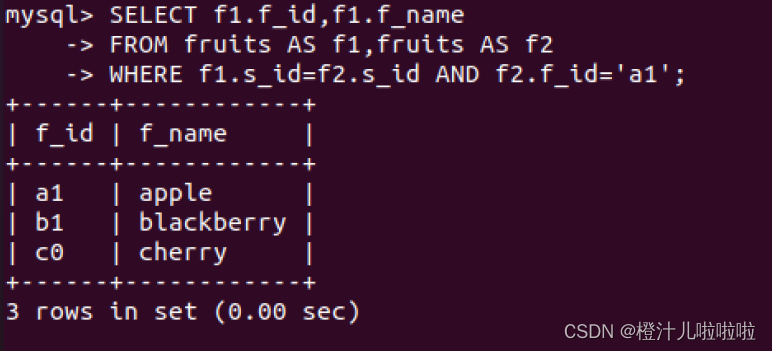
例48:查询f_id='a1'的水果供应商提供的水果种类
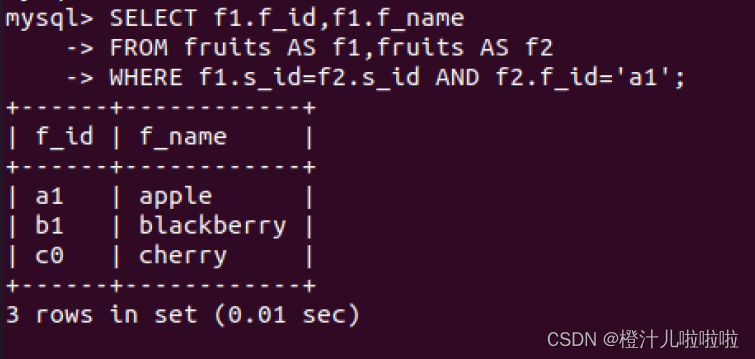
此处查询的两个表是相同的表,为了防止产生二义性,对表使用了别名,fruits表第一次出现的别名为f1,第二次出现的别名为f2,使用SELECT语句返回列表时明确支出返回以f1为前缀的列的全名,WHERE连接两个表,并按照第2个表的f_id对数据进行过滤,返回所需数据。
(2)外连接查询
外连接查询将查询多个表中相关联的行,内连接时,返回查询结果集合中仅是符合查询条件和连接条件的行。有时候需要包含没有关联的行中数据,即返回查询结果集合中不仅包含符合连接条件的行,还包含左表(左外连接或左连接),右表(右外连接或右连接)或两个边接表(全外连接)中的所有数据行。
外连接分为左外连接或左连接和右外连接或右连接;
LEFT JOIN(左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。
RIGHT JOIN(右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。
首先建立表orders,并插入数据:
CREATE TABLE orders
(
o_num int NOT NULL AUTO_INCREMENT,
o_date datetime NOT NULL,
c_id int NOT NULL,
PRIMARY KEY (o_num)
);INSERT INTO orders(o_num,o_date,c_id)
VALUES(30001,'2008-09-01',10001),
(30002,'2008-09-12',10003),
(30003,'2008-09-30',10004),
(30004,'2008-10-03',10005),
(30005,'2008-10-08',10001);1)LEFT JOIN左连接
左连接的结果包括LEFT OUTER字句中指定的左表的所有行,而不仅仅是连接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果行中,右表的所有选择列表均为空值。
例49:在customers表和orders表中,查询所有客户,包括没有订单的客户
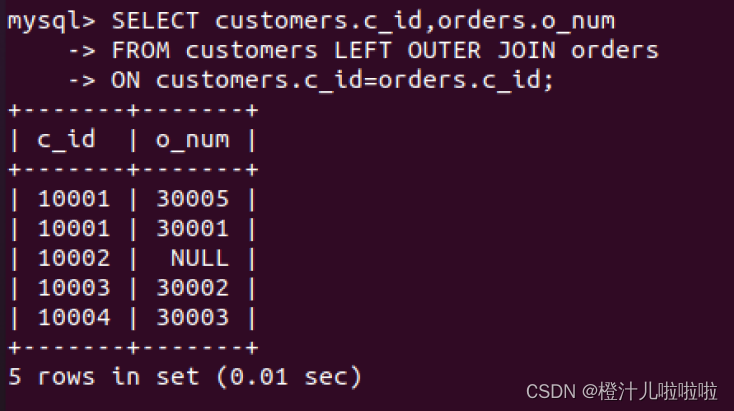
结果显示了5条记录,ID等于10002的客户目前并没有下订单,所以对应的orders表中并没有该客户的订单信息,所以该条记录只取出了customers表中相应的值,而从orders表中取出的值为空值NULL。

2)RIGHT JOIN右连接
右连接是左连接的反向连接,将返回右表的所有行,如果右表的某行在左表中没有匹配行,左表将返回空值。
例50:在customers表和orders表中,查询所有订单,包括没有客户的订单
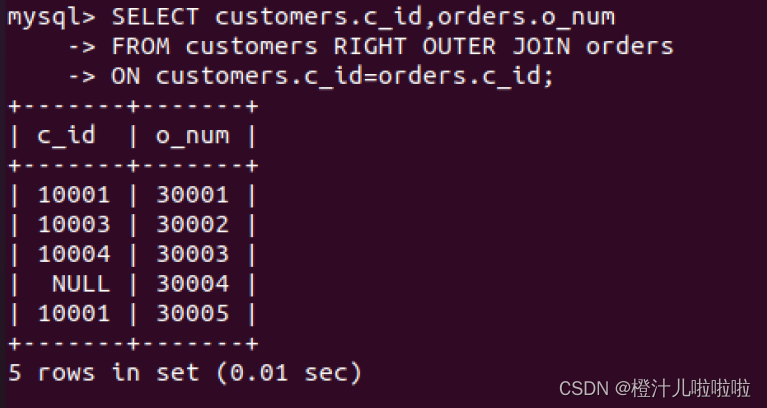
结果显示了5条记录,订单号等于30004的订单的客户可能由于某种原因取消了该订单,对应的customers表中并没有该客户的信息,所以该条记录只取出了orders表中相应的值,而从customers表中取出的值为空值NULL。

内连接,左连接,右连接图示:
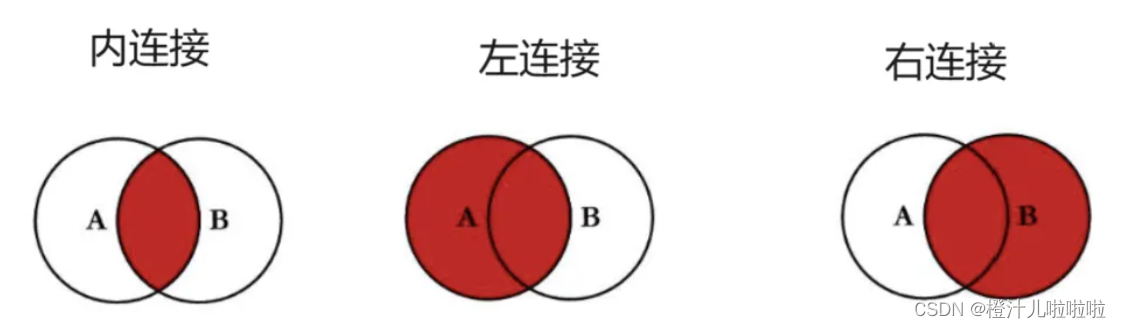
左连接(LEFT JOIN 或 LEFT OUTER JOIN)和右连接(RIGHT JOIN 或 RIGHT OUTER JOIN)在SQL中用于结合两个或多个表的数据,但它们之间存在明显的区别。
左连接和右连接之间的主要区别:
1、保留的行
LEFT JOIN(左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。
RIGHT JOIN(右连接):返回包括右表中的所有记录和左表中连接字段相等的记录。
2、使用场景
在实际应用中,左连接比右连接更为常见。这主要是因为左连接更直观的反映了“主表”与“详情表”之间的关系。
右连接在某些特定场景下可能有用,但通常不如左连接直观。在某些数据库设计或查询需求中,可能需要使用右连接,但这种情况相对较少。
3、可替代性
虽然左连接和右连接在功能上是不同的,但你可以通过调整查询的结构和表的顺序来用左连接替代右连接,反之亦然。例如,如果你有一个右连接查询,你可以通过交换两个表的顺序并使用左连接来得到相同的结果。
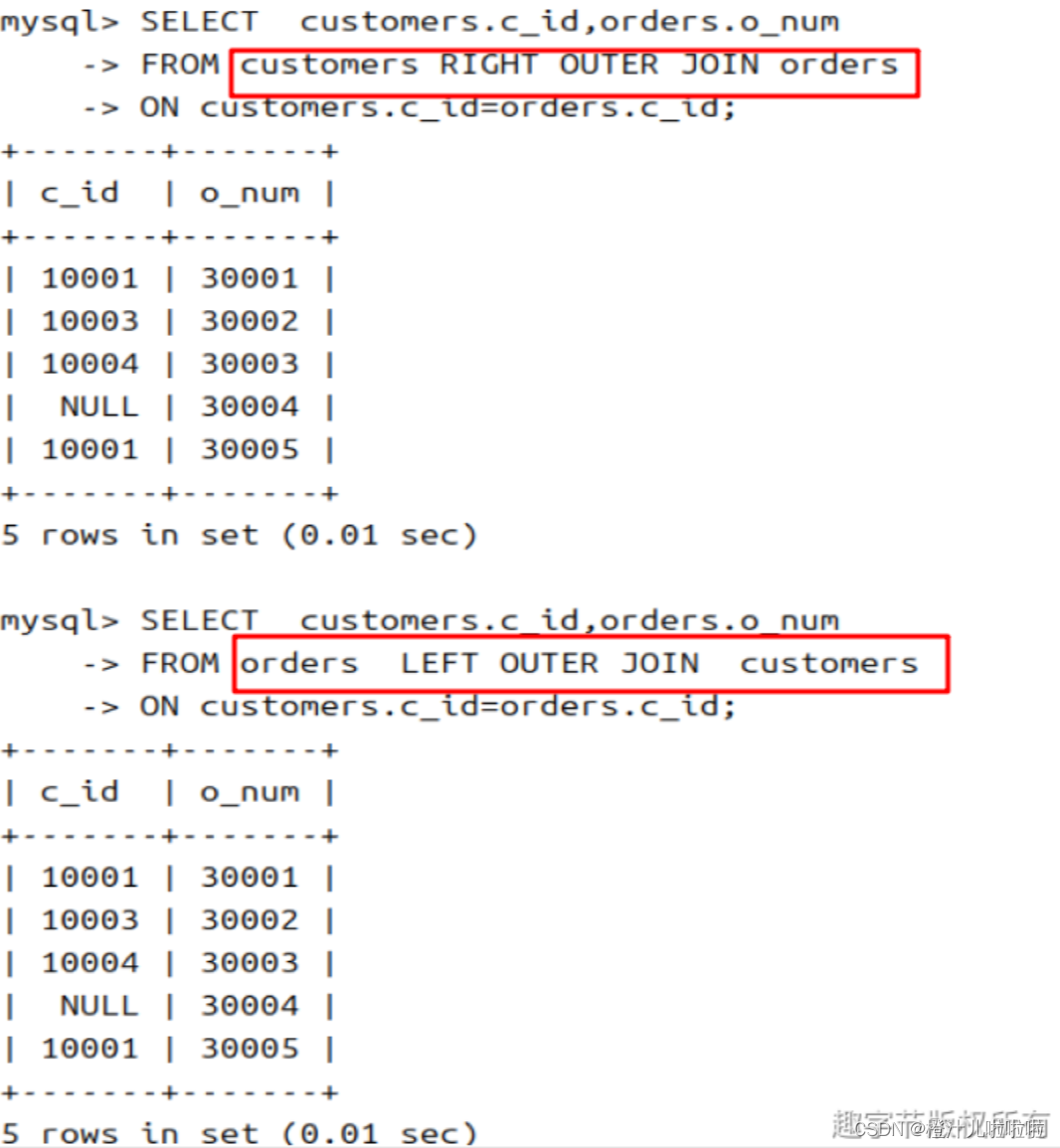
例如:
SELECT customers.c_id,orders.o_num
FROM customers RIGHT OUTER JOIN orders
ON customers.c_id=orders.c_id;
改为:
SELECT customers.c_id,orders.o_num
FROM orders LEFT OUTER JOIN customers
ON customers.c_id=orders.c_id;
我们把右连接换为左连接,然后把表的顺序倒一下,发现结果是一样的,结果如下:
(3)复合条件连接查询
复合条件连接查询是在连接查询的过程中,通过添加过滤条件限制查询的结果,使查询的结果更加准确。
例51:在customers表和orders表中,使用INNER JOIN语法查询customers表中ID为10001的客户的订单信息
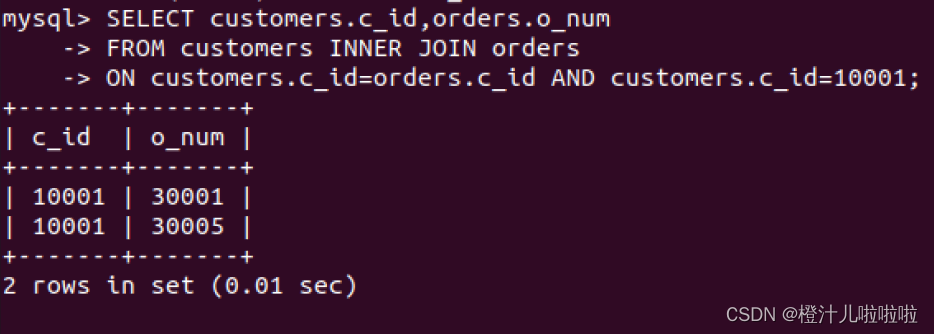
结果显示,在连接查询时指定查询客户ID为10001的订单信息,添加了过滤条件之后返回的结果将会变少,因此返回结果只有两条记录。
使用连接查询,并对查询的结果进行排序。
例52:在fruits表和suppliers表之间,使用INNER JOIN语法进行内连接查询,并对查询结果排序
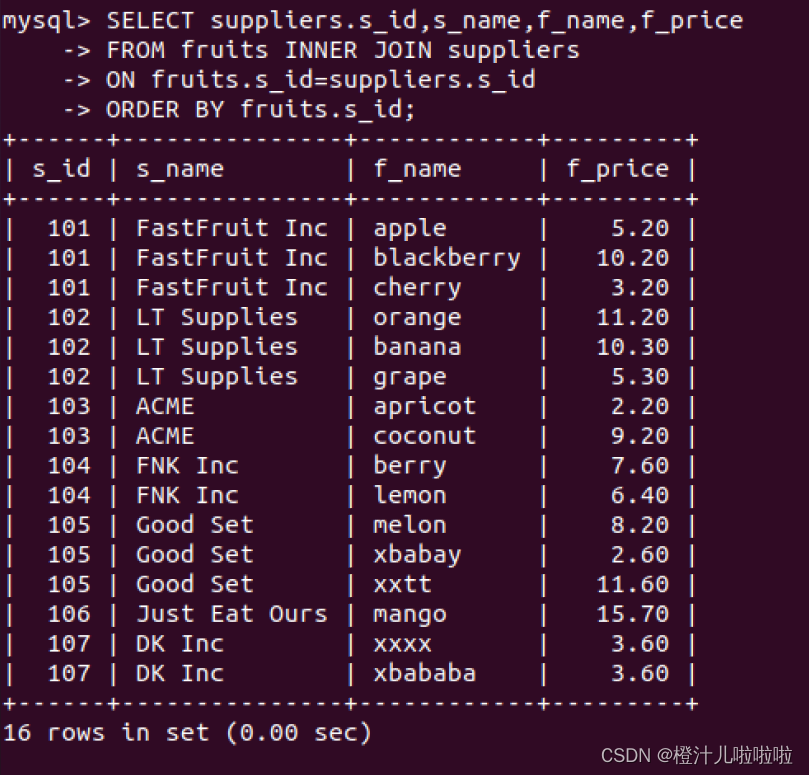
由结果可以看到,内连接查询的结果按照suppliers.s_id字段进行了升序排序。
5、子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从MySQL4.1开始引入,在SELECT子句中先计算子查询,子查询结果作为外层另一个查询的过滤条件,查询可以基于一个表或者多个表。
子查询中常用的操作符由有ANY(SOME),ALL,IN,EXISTS。子查询可以添加到SELECT,UPDATE和DELETE语句中 ,而且可以进行多层嵌套。子查询中也可以使用比较运算符,如"<" "<=" ">" ">=" "!="等。
(1)带ANY,SOME关键字的子查询
ANY和SOME关键字是同义词,表示满足其中任一条件,它们允许创建一个表达式对子查询的返回值列表进行比较,只要满足内层子查询中的任何一个比较条件,就返回一个结果作为外层查询的条件。
下面定义两个表tbl1和tbl2,并插入数据
CREATE table tbl1(num1 INT NOT NULL);
CREATE table tbl2(num2 INT NOT NULL);
INSERT INTO tbl1 values(1),(5),(13),(27);
INSERT INTO tbl2 values(6),(14),(11),(20);ANY关键字接在一个比较操作符的后面,表示若与子查询返回的任何值比较为TURE,则返回TRUE
例53:返回tbl2表的所有num2列,然后将tbl1中的num1的值与之进行比较,只要大于num2的任何1个值,即为符合查询条件的结果
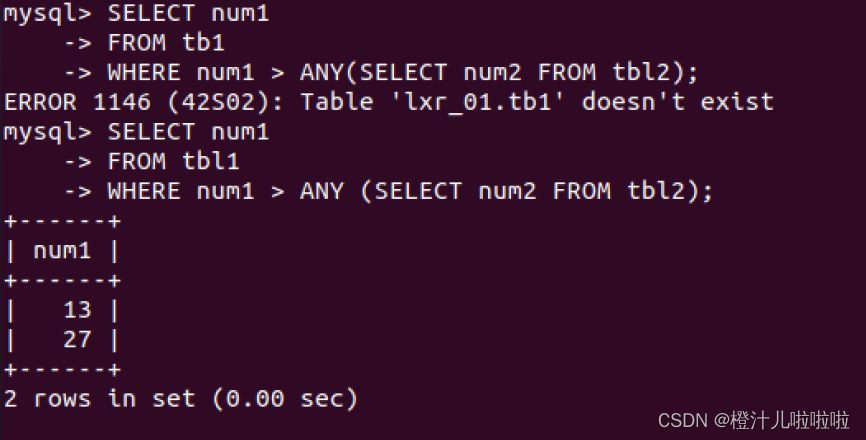
在子查询中,返回的是tbl2表的所有num2列结果(6,14,11,20),然后将tbl1中的num1列的值与之进行比较,只要大于num2列的任意一个数即为符合条件的结果。
(2)带ALL关键字的子查询
ALL关键字与ANY和SOME不同,使用ALL时需要同时满足所有内层查询的条件,例如,修改前面的例子,用ALL关键字替换ANY。
ALL关键字接在一个比较操作符的后面,表示与子查询返回的所有值比较为TURE,则返回TURE
例54:返回tbl1表中比tbl2表num2列所有值都大的值
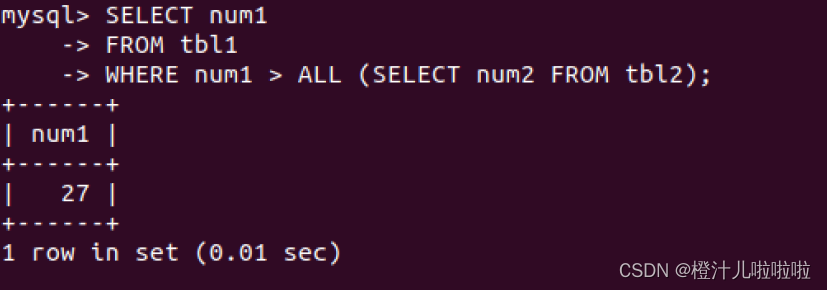
在子查询中,返回的是tbl2表的所有num2列结果(6,14,11,20),然后将tbl1中的num1列的值与之进行比较,大于所有num2列值的num1值只有27,因此返回结果为27。
(3)带EXISTS关键字的子查询
EXISTS关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断它是否返回行,如果至少返回一行,那么EXISTS的结果为ture,此时外曾查询语句将进行查询:如果子查询没有返回任何行,那么EXISTS返回的结果为false,此时外层语句将不进行查询。
例55:查询suppliers表中是否存在s_id=107的供应商,如果存在,则查询fruits表中的记录
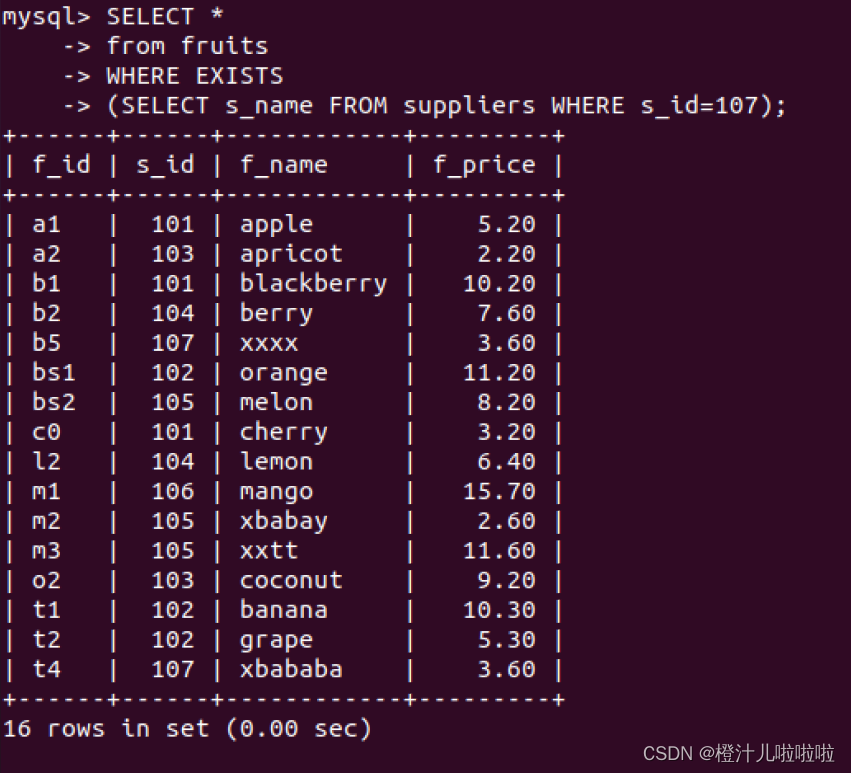
EXISTS关键字可以和条件表达式一起使用
例56:查询suppliers表中是否存在s_id=107的供应商,如果存在,则查询fruits表中的f_price大于10.20的记录
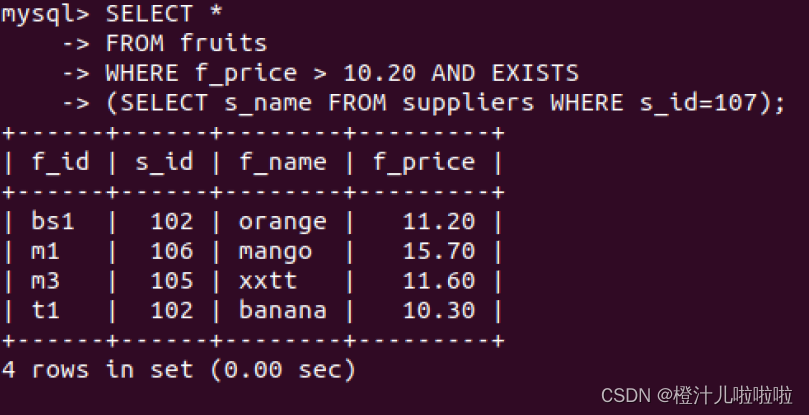
注意,内层查询结果为ture才去执行外层的查询语句
NOT EXISTS与EXISTS使用方法相同,返回的结果相反。子查询如果至少返回一行,那么NOT EXISTS的结果为false,此时外层查询语句将不进行查询。如果子查询没有返回任何行,那么NOT EXISTS返回的结果为true,此时外层语句将进行查询。
例57:查询suppliers表中是否存在s_id=107的供应商,如果不存在则查询fruits表中的记录
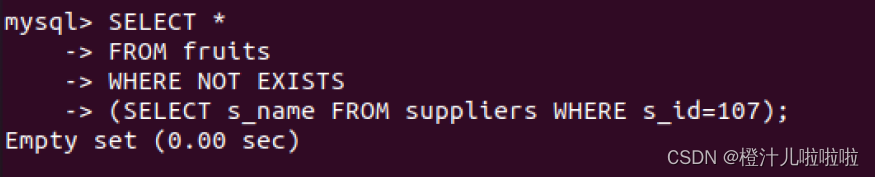
查询语句SELECT s_name FROM suppliers WHERE s_id=107,对suppliers表进行查询返回了一条记录,NOT EXISTS表达式返回false,外层表达式接收false,将不再查询fruits表中的记录。
注意:EXISTS和NOT EXISTS的结果只取决于是否会返回行,而不却决于这些行的内容,所以这个子查询输入列表通常是无关紧要的。
(4)带IN关键字的子查询
IN关键字进行子查询时,内层查询语句仅仅返回一个数据列,这个数据列例的值将提供给外层查询语句进行比较操作。
例58:在orderitems表中查询f_id为c0的订单号,并根据订单号查询具有订单号的客户c_id
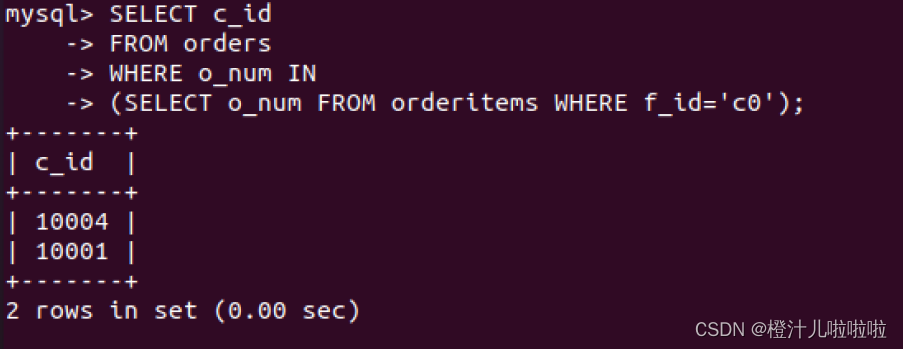
这个例子说明在处理SELECT语句的时候,MySQL实际上执行了两个操作过程,即先执行了内层子查询,再执行外层查询,内层子查询的结果作为外部查询的比较条件
SELECT语句中可以使用NOT IN关键字,其作用与IN正好相反
例59:与前一个例子类似,但是在SELECT语句中使用NOT IN关键字
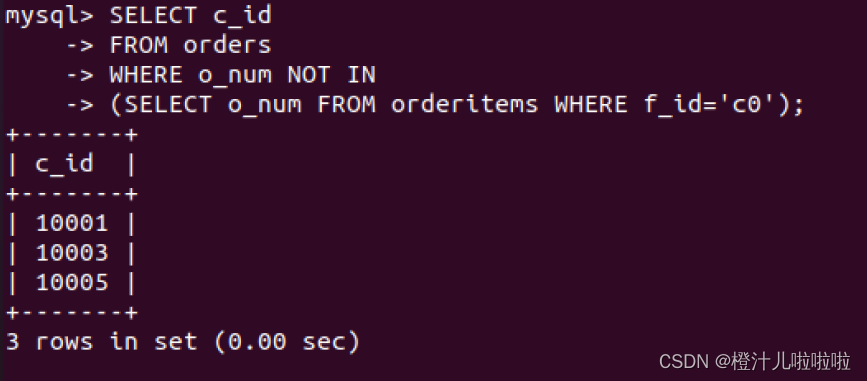
注意:子查询的功能也可以通过连接查询完成,但是子查询使得MySQL代码更容易阅读和编写。
(5)带比较运算符的子查询
在前面介绍的带ANY,ALL关键字的子查询时使用了“>”比较运算符,子查询时还可以使用其他的比较运算符,如“<” “<=” “=” “>=” “!=”等。
例60:在suppliers表中查询s_city等于“Tianjin”的供应商s_id,然后在fruits表中查询所有该供应商提供的水果的种类
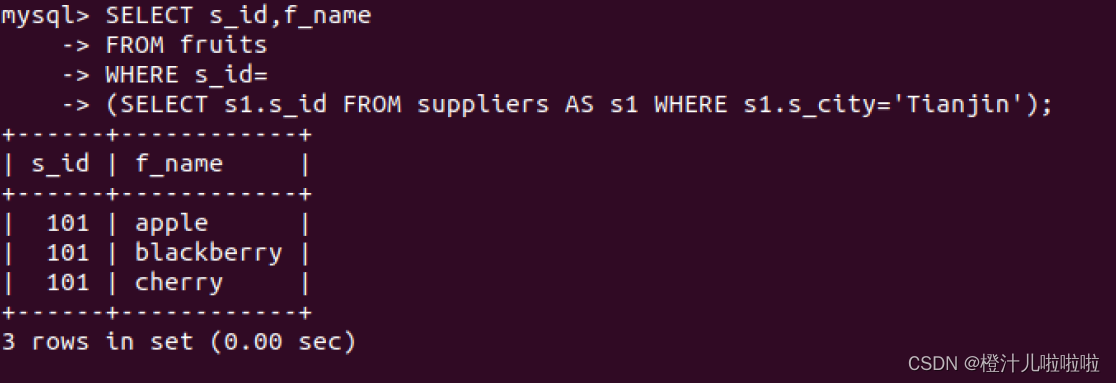
不起别名也可以
例61:在suppliers表中查询s_city等于“Tianjin”的供应商s_id,然后在fruits表中查询所有非该供应商提供的水果的种类
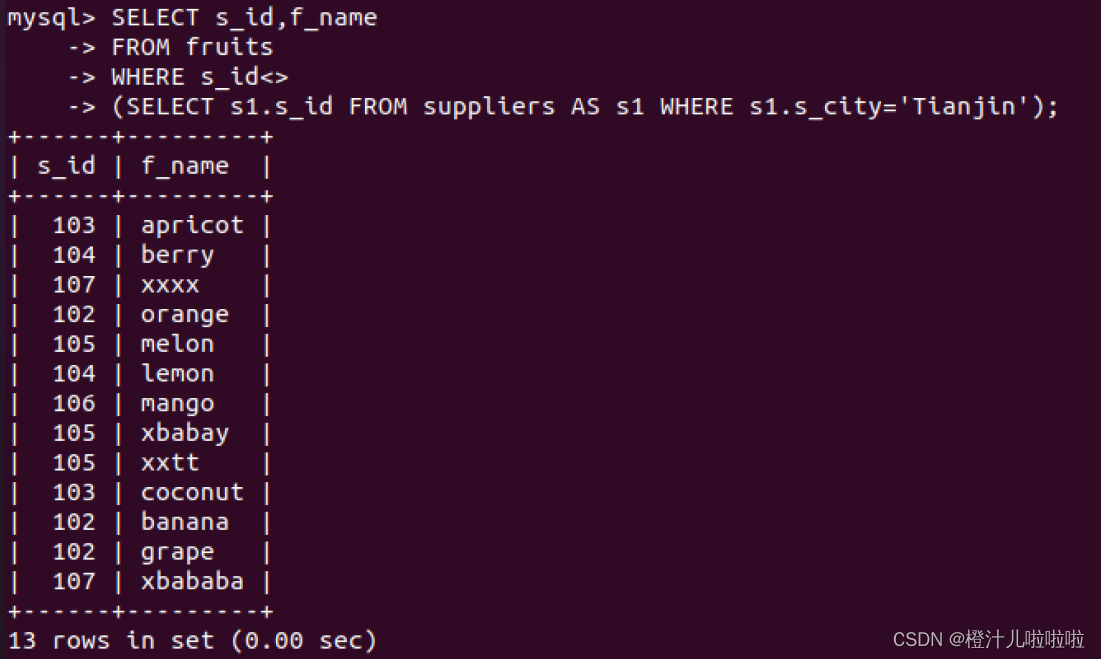
该嵌套查询执行过程与前面相同,在这里使用了不等于<>运算符,因此返回的结果和前面正好相反。
6、合并查询结果
利用UNION关键字,可以给出多条SELECT语句,并将他们的结果组合成单个结果集。合并时,两个表对应的列数必须相同。各个SELECT语句之间使用UNION或UNION ALL关键字分隔。UNION不使用关键字ALL,执行的时候删除重复的记录,所有返回的行都是唯一的;使用关键字ALL的作用是不删除重复行也不对结果进行自动排序。
合并结果集在数据库查询中非常有用,尤其是在处理多表查询或需要对多个查询结果进行组合时。合并结果可以做到:数据整合,简化查询逻辑,提高性能,灵活性和可扩展性。
需要注意的是,合并结果集时,被合并的两个结果的列数、列类型必须相同。如果列类型不相同,可以通过SELECT关键字去筛选需要的列,以确保合并操作的正确性。
基本语法格式如下:
SELECT column,...FROM table1
UNION [ALL]
SELECT column,...FROM table2注意:这个语法更适用于不同表。
例62:查询所有价格小于9的水果的的信息,查询s_id等于101和103所有水果的信息,适用UNION连接查询结果。
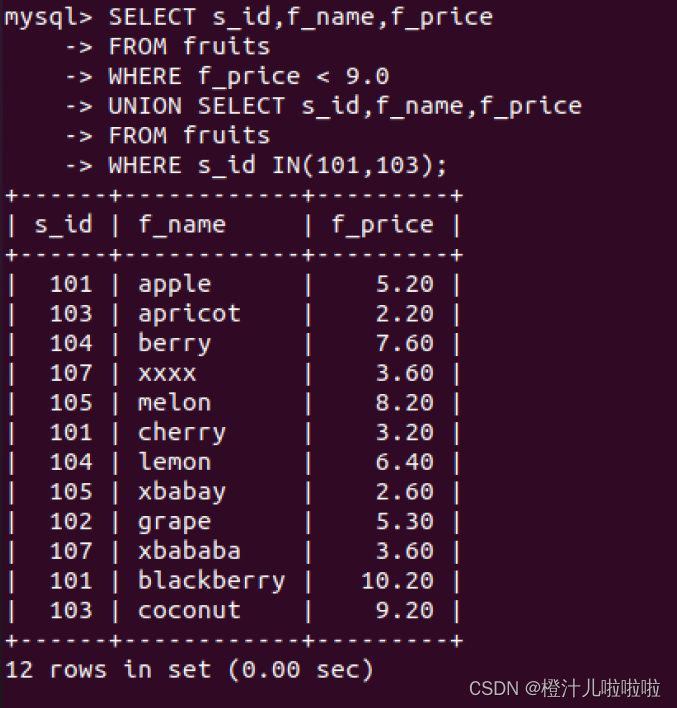
其实,UNION将多个SELECT语句的结果组合成一个结果集合,可以分开查看每个SELECT语句的结果
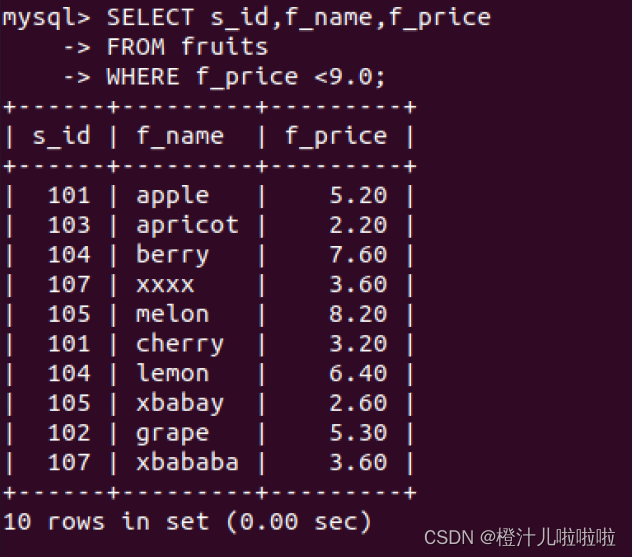
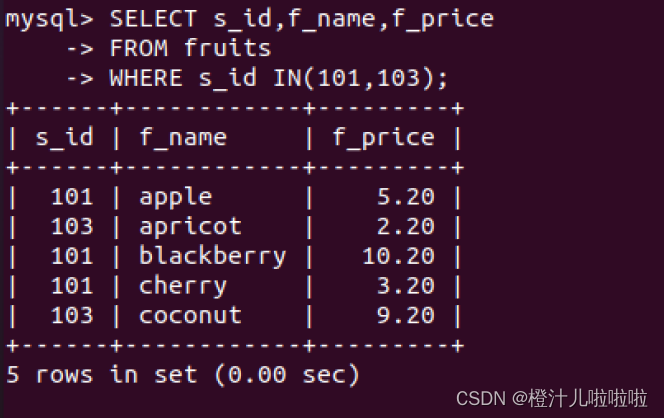
使用UNION ALL包含重复的行,在前面的例子中,分开查询时,两个返回结果中有相同的记录。UNION从查询结果集中自动去除了重复的行,如果要返回所有匹配行,而不进行删除,可以适用UNION ALL。
例63:查询所有价格小于9的水果的信息,查询s_id等于101和103的所有水果的信息,使用UNION ALL连接查询结果
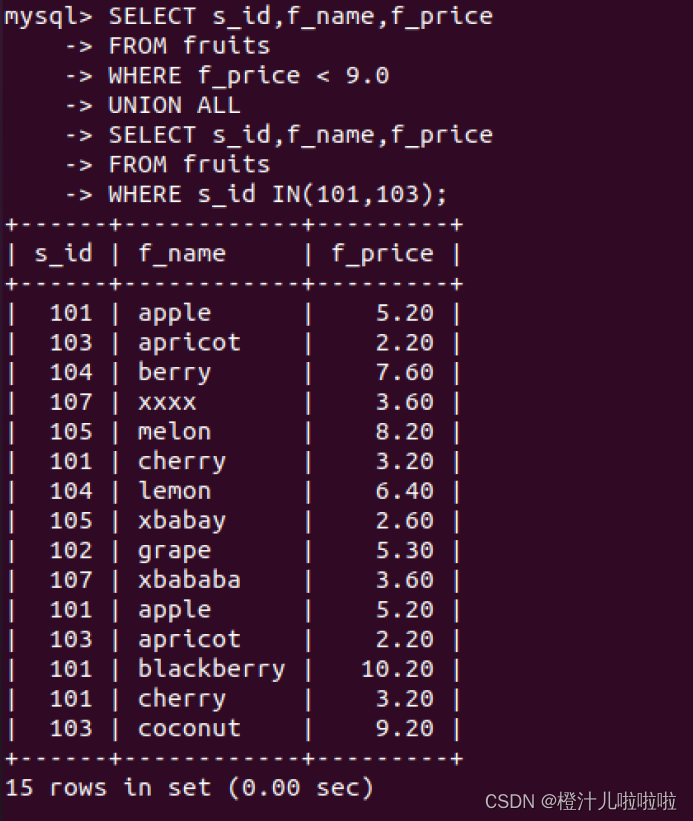
由结果可以看到,这里总的记录数等于两条SELECT语句的记录数之和,连接查询结果并没有取出重复的行。
注意:UNION和UNION ALL的区别:使用UNION ALL的功能时不删除重复行,加上ALL关键字语句执行时所需要的资源少,所以尽可能地使用它,因此知道有重复行,但是想保留这些行,确定查询结果中不会有重复数据或者不需要去掉重复数据的时候,应当使用UNION ALL以提高查询效率。
在大部分情况下,UNION ALL的效率要高于UNION。这是因为UNION在进行表连接后会筛选掉重复的记录,这个过程涉及到排序运算和删除重复记录的操作,相对较为耗时。而UNION ALL只是简单地将两个结果合并后就返回,不会进行去重和排序操作,因此执行速度更快。
总之,在选择使用UNION还是UNION ALL时,应总和考虑业务需求、数据特点以及性能要求等因素,以选择最合适的操作符。
7、为表和字段取别名
在前面介绍分组查询,集合函数查询和嵌套子查询章节中,其实我们有的地方已经使用了AS关键字为查询结果中的某一列指定一个特定的名字,在内连接查询时,则对相同的表fruits分别指定两个不同的名字,这里可以为字段或者表取一个别名,在查询时,使用别名替代其指定的内容。
下面介绍如何为字段和表创建别名以及如何使用别名。
(1)为表取别名
当表名字很长或者执行一些特殊查询时,为了方便操作或者需要多次使用相同的表时,可以为表指定别名,用这个别名替代原来的名称。为表取别名的基本语法格式为:
表名 [AS] 表别名“表名”为数据库中存储的数据表的名称,“表别名”为查询时指定的表的新名称。AS关键字为可选参数。
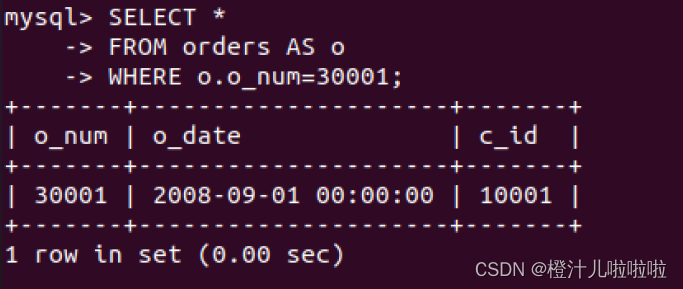
例64:为orders表取别名o,查询30001订单的下单日期
例65:为customers和orders表分别取别名,并进行连接查询(左连接)
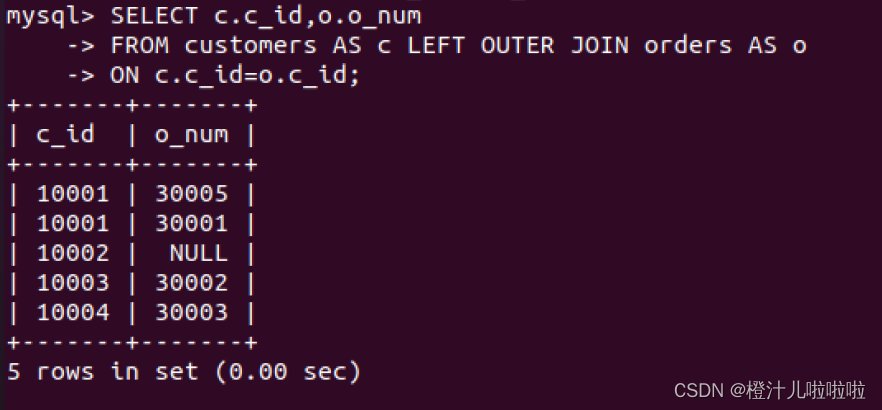
由结果看到,MySQL可以同时为多个表取别名,而且表别名可以放在不同的位置,如WHERE子句,SELECT列表,ON子句以及ORDER BY子句等。
在前面介绍内连接查询时指出自连接是一种特殊的内连接,在连接查询中的两个表都是同一个表,其查询语句如下:
在这里,如果不使用表别名,MySQL将不知道引用的是哪个fruits表实例,这是表别名一个非常有用的地方。
在为表取别名时,要保证不能与数据库中其他表的名称冲突。
(2)为字段取别名
在使用SELECT语句显示查询结果时,MySQL会显示每个SELECT后面指定的输出列,在有些情况下,显示的列的名称会很长或者名称不够直观,MySQL可以指定别名,替换字段或表达式。
为字段取别名的基本语法格式为:
列名 [AS] 列别名“列名”为表中字段定义的名称,“列别名”为字段新的名称,AS关键字为可选参数。
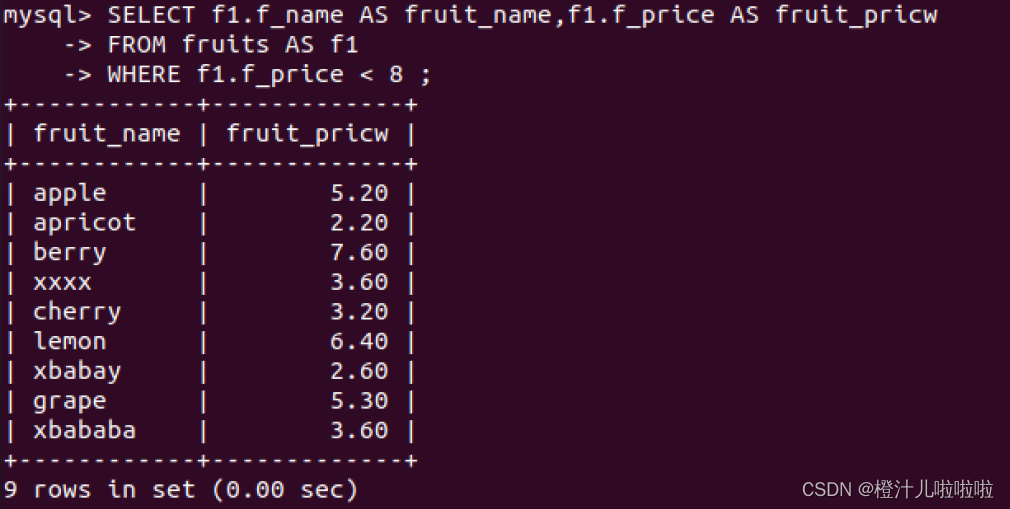
例66:查询fruits表中,为f_name取别名fruit_name,f_price取别名fruits,为fruits表取别名f1,查询表中f_price<8的水果的名称
也可以为SELECT子句中的计算字段取别名,例如,对使用COUNT聚合函数或者CONCAT等系统函数执行的结果字段取别名。
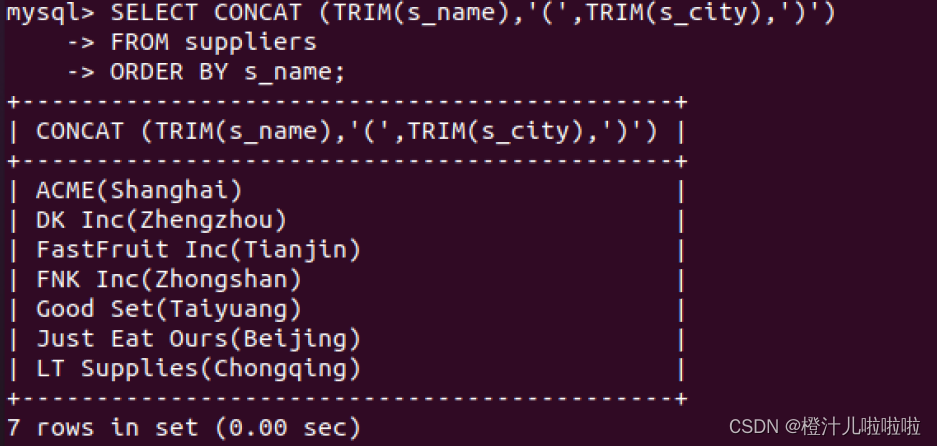
例67:查询suppliers表中字段s_name和s_city,使用CONCAT函数连接这两个字段值,并取列别名为suppliers_title
如果没有对连接后的值取别名,其显示列名称将会不够直观
由结果可以看到,显示结果的列名称为SELECT子句后面的计算字段,实际上计算之后的列是没有名字的,这样的结果让人很不容易理解。 如果为字段取一个别名,将会使结果清晰。
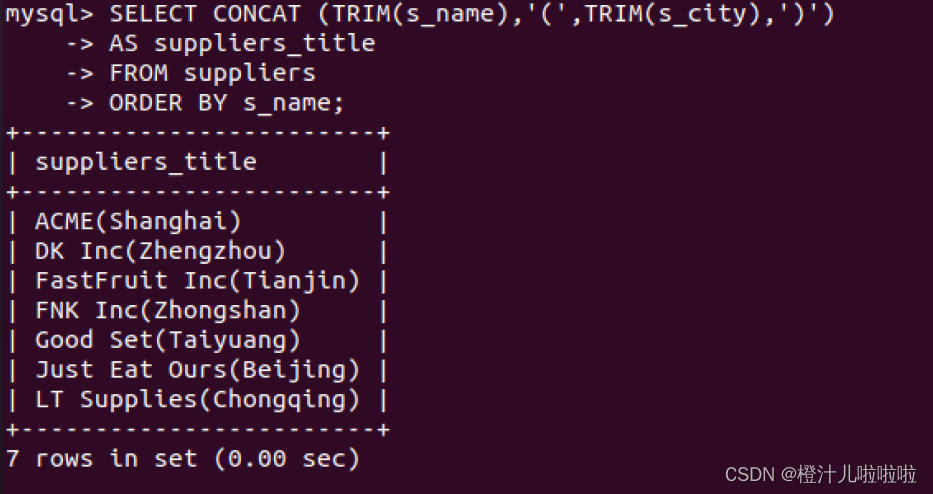
由结果可以看到,SELECT子句计算字段值之后增加了AS suppliers_title,它指示MySQL为计算字段创建了一个别名suppliers_title,显示结果为指定的列别名,这样就增强了查询结果的可能性。
注意:表别名只在执行查询的时候使用,并不在返回结果中显示;而列别名定义之后,将返回给客户端,显示的结果字段为字段列的别名。
8、使用正则表达式查询
正则表达式通常被用来检索或替换那些符合某个模式的文本内容,根据指定的匹配模式匹配文本中符合要求的特殊字符串。例如,从一个文本文件中提取电话号码,查找一篇文章中重复的单词或者替换用户输入的某些敏感词语等,这些地方都可以使用正则表达式。正则表达式强大而且灵活,可以应用于非常复杂的查询。
MySQL中使用REGEXP关键字指定正则表达式的字符匹配模式,下图列出了REGEXP操作符中常用字符匹配列表。
(regexp通常是regular expression(正则表达式)的缩写)
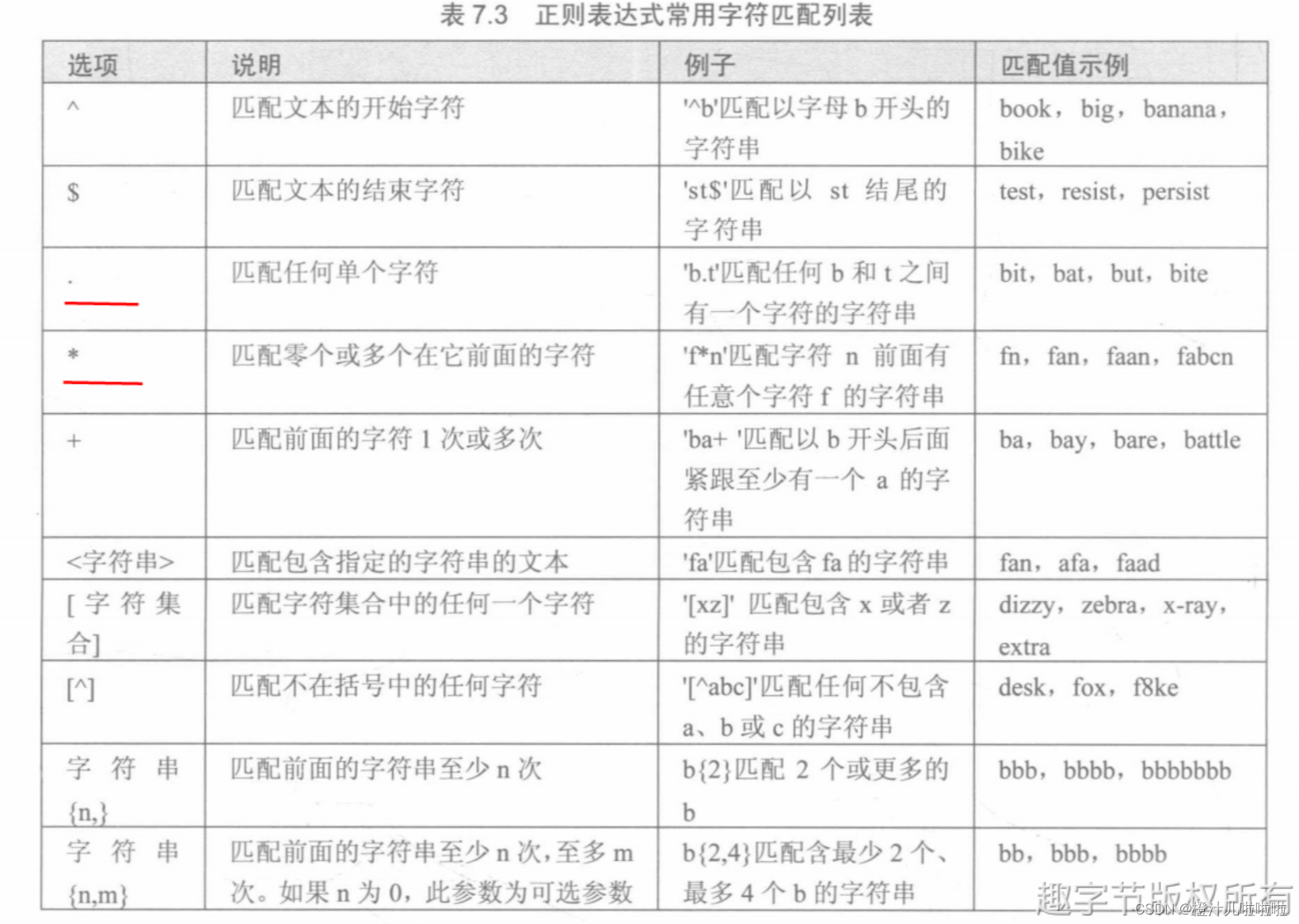
下面将介绍在MySQL中如何使用正则表达式
(1)查询以特定字符或字符串开头的记录
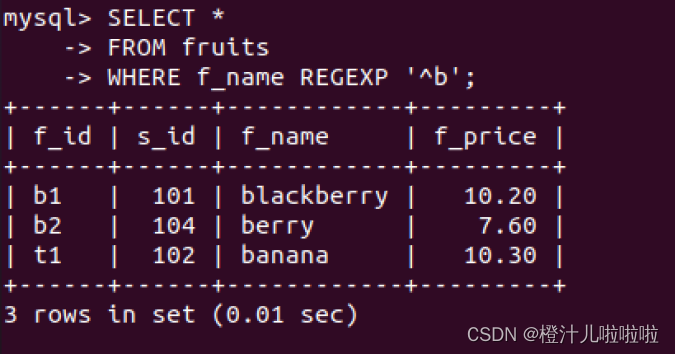
字符'^' 匹配以特定字符或者字符串开头的文本
例68:在fruits表中,查询f_name字段以字母‘b’开头的记录
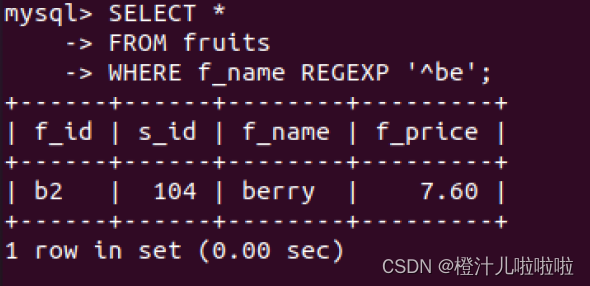
例69:在fruits表中,查询f_name字段以“be”开头的记录
(2)查询以特定字符或字符串结尾的记录
字符 '$' 匹配以特定字符或者字符串结尾的文本
例70:在fruits表中,查询f_name字段以字母‘y’结尾的记录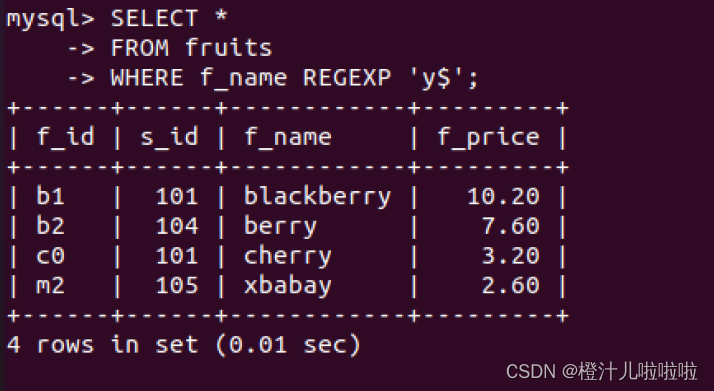
例71:在fruits表中,查询f_name字段以字符串"rry"结尾的记录
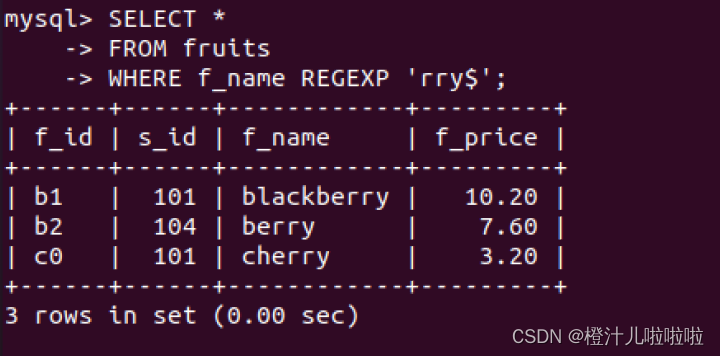
(3)用符号"."来替代字符串中的任意一个字符
字符'.'匹配任意一个字符
例72:在fruits表中,查询f_name字段值包含字母'a'与'g'且两个字母之间只有一个字母的记录
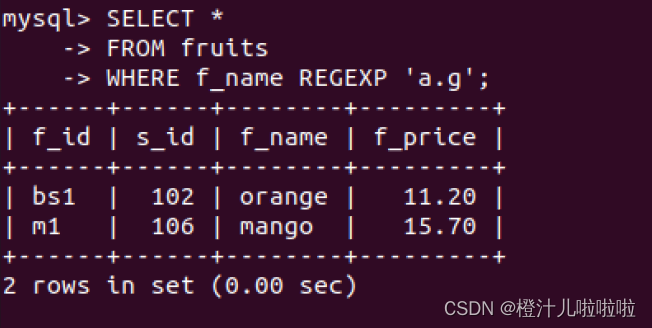
由结果可以看出,'a.g'指定匹配字符中要有字母a和g,且两个字母之间包含单个字符,并不限定匹配的字符的位置和所在查询字符串的总长度。
(4)使用"*"和"+"来匹配多个字符
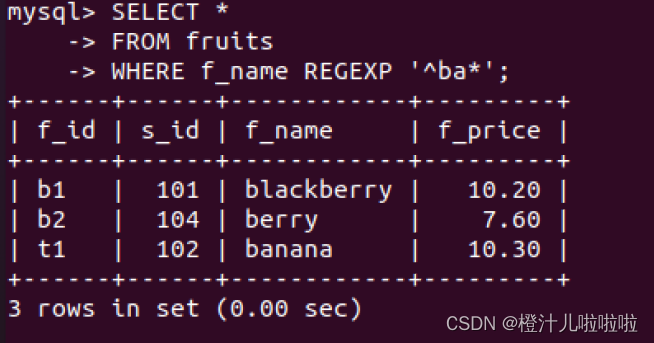
**星号''匹配前面的字符任意多次,包括0次,加号'+'匹配前面的字符至少一次
例73:在fruits表中,查询f_name字段值以字母'b'开头且'b'后面出现字母'a'的记录
例74:在fruits表中,查询f_name字段值以字母'b'开头且'b'后面出现字母'a'至少一次的记录
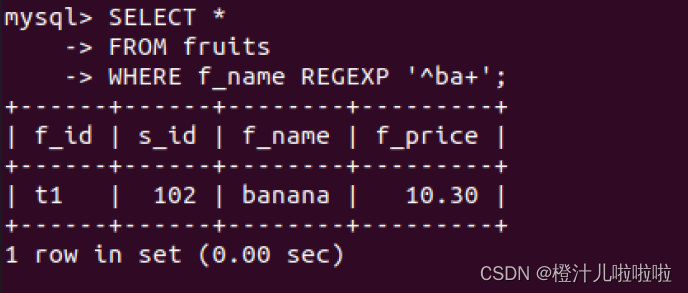
'a+'匹配字母'a'至少一次,只有banana满足条件。
注意:在正则表达式ba*中,a*表示"a"可以出现零次或多次。这意味着这个正则表达式会匹配以"b"开头,后面跟着任意数量(包括零个)的"a"的字符串。因此,它不仅可以匹配"ba"、"baa"、"baaa"等,还可以匹配仅包含"b"的字符串。
正则表达式^ba+和^ba*的主要区别在于它们对后面"a"字符出现次数的要求不同:^ba+要求至少有一个"a",而^ba*则允许没有"a"。
(5)匹配指定字符串
正则表达式可以匹配指定字符串,只要这个字符串在查询文本中即可,如果要匹配多个字符串,多个字符串之间使用分隔符'|'隔开。
例75:在fruits表中,查询f_name字段值包含字符串"on"或者"ap"的记录
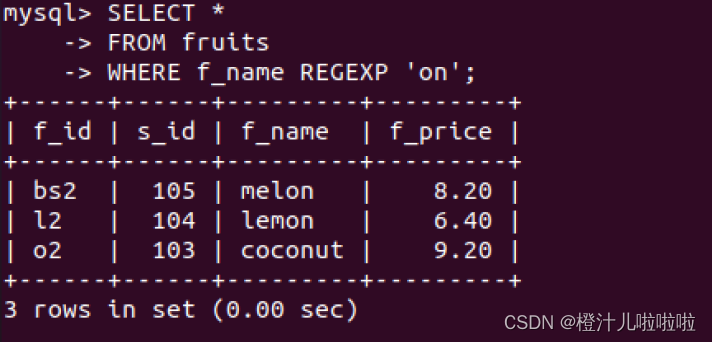
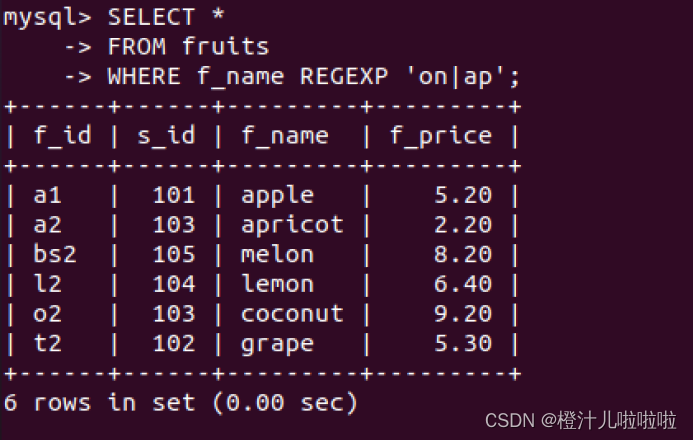
例76:在fruits表中,查询f_name字段值包含字符串"on"或者'"ap"的记录
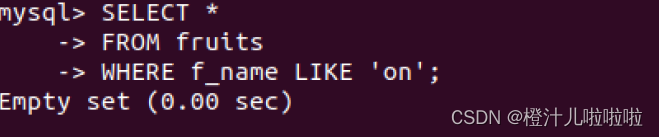
之前介绍过,LIKE运算符也可以匹配指定的字符串,但于REGEXP不同,LIKE匹配的字符串如果在文本中就出现,则找不到它,相应的行也不会返回。REGEXP在文本内进行匹配,如果被匹配的字符串在本文中出现,REGEXP将会找到它,相应的行也会被返回,对比结果如下面的例子所示。
例77:在fruits表中,使用LIKE运算符查询f_name字段值为"on"的记录
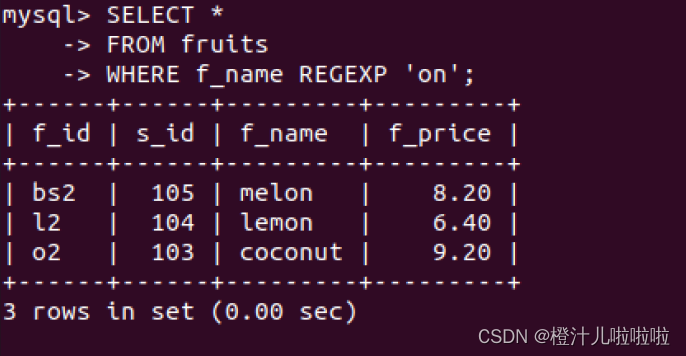
LIKE和REGEXP在数据库查询中主要用于模式匹配,它们之间的区别如下:
LIKE函数适用于简单的通配符匹配。它的语法相对简单,主要依赖于通配符。
REGEXP函数的语法则更加复杂,需要用户熟悉正则表达式的语法和规则。
综上所述,LIKE和REGEXP在数据库查询中各有其应用场景。对于简单的模式匹配和需要利用索引优化的查询,LIKE函数可能更合适。而对于需要执行复杂模式匹配的情况,REGEXP函数则提供了更强大的功能。
(6)匹配指定字符串中的任意一个
方括号“[]”指定一个字符集合,只匹配其中任意一个字符,即为所查找的文本。
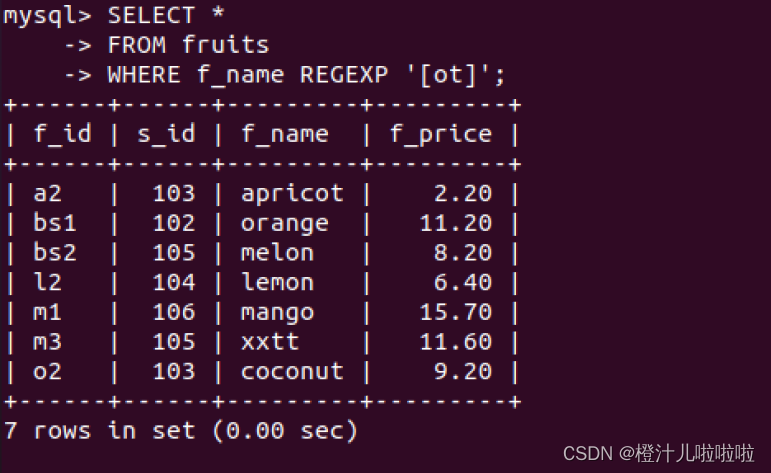
例78:在fruits表中,查询f_name字段值包含字母'o'或者't'的记录
方括号"[]"还可以指定数值集合。
例79:在fruits表中,查询s_id字段中包含4,5或者6的记录
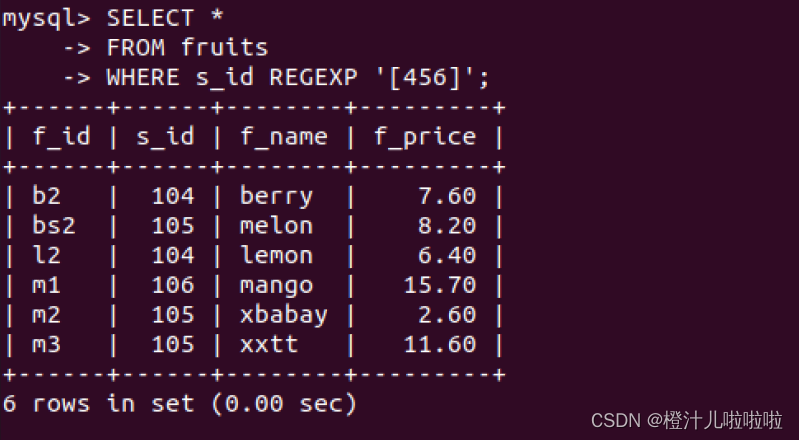
在查询结果中,s_id字段值中只要有3个数字中的1个即为匹配记录字段
匹配集合"[456]"也可以写成"[4-6]",即指定集合区间。例如,"[a-z]"表示集合区间为a~z的字母,"[0~9]"表示集合区间为所有数字。
(7)匹配指定字符以外的字符
"[^字符集合]"匹配不在指定集合中的任意字符注意:
例80:在fruits表中,查询f_id字段中包含字母a~e和数字1-2以外字符的记录
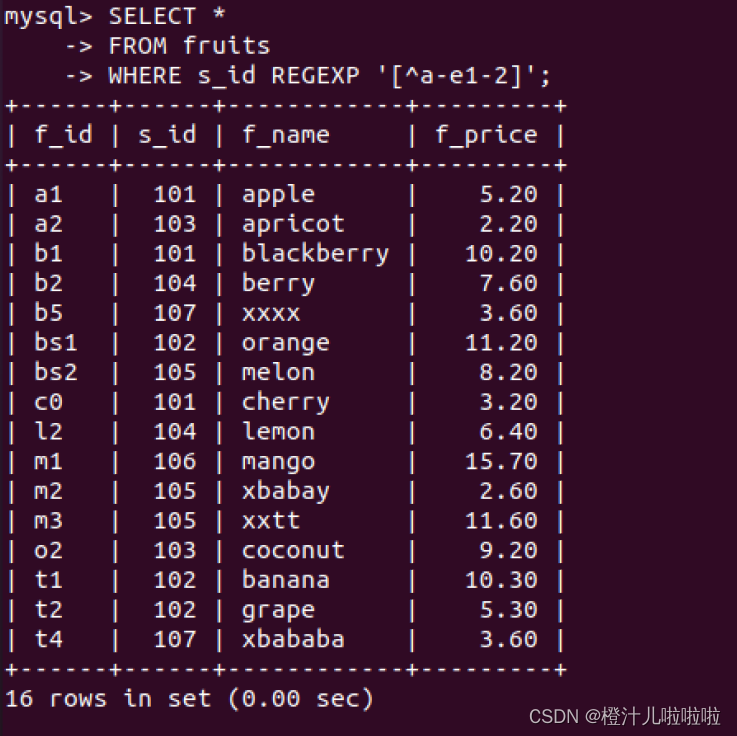
返回记录中的f_id字段值中包含指定字母和数字以外的值,如s,m,o,t等,这些字母均不在a~e与1~2之间,满足匹配条件。
(8)使用{n,}或者{n,m}来指定字符串连续出现的次数
“字符串{n,}”表示至少匹配n次前面的字符;“字符串{n,m}”表示匹配前面的字符串不少于n次,不多于m次。例如,a{2,}表示字母a连续出现至少2次,也可以大于2次;a{2,4}表示字母a连续出现最少2次,最多不能超过4次。
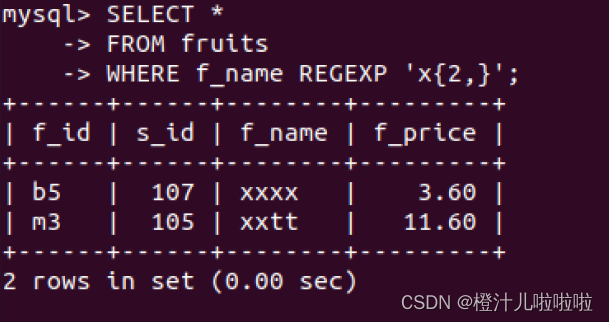
例81:在fruits表中,查询f_name字段值出现字母'x'至少2次的记录
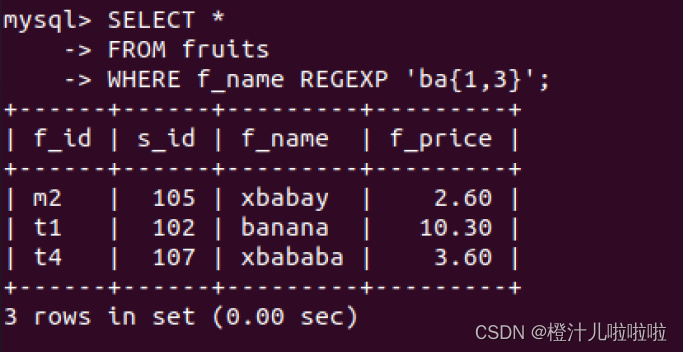
例82:在fruits表中,查询f_name字段值出现字符串"ba"最少1次,最多3次的记录

















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









