






json转mmdetection中Maskrcnn训练的coco格式
1.使用labelme标注数据,此时图片和标注的json文件在一个文件夹中
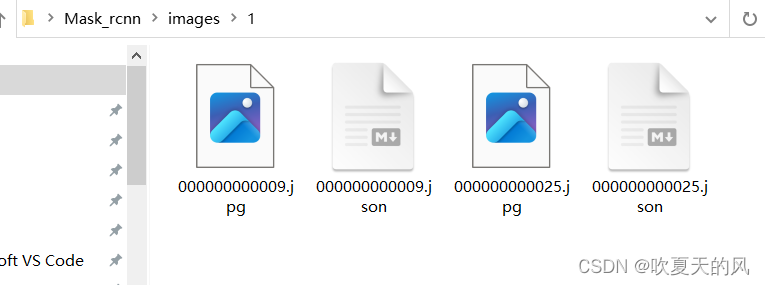
2.将代码中path改为标注完成的文件夹,并修改保存路径
train_num:为训练集所占总数据的比例
test_num:为测试集所占的比例
val_num:为验证集所占的比例
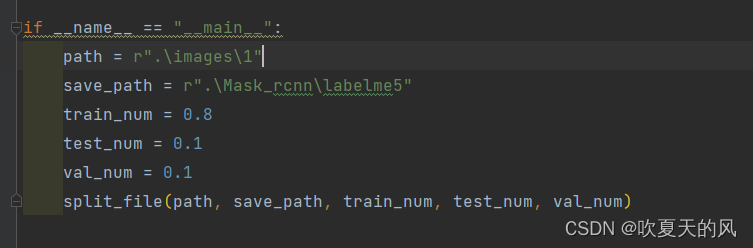
3运行即可,结果如下图,同时脚本同级目录下回存在一个“label_yjy.txt”,里面包含了数据中所有的标签,可自行检查
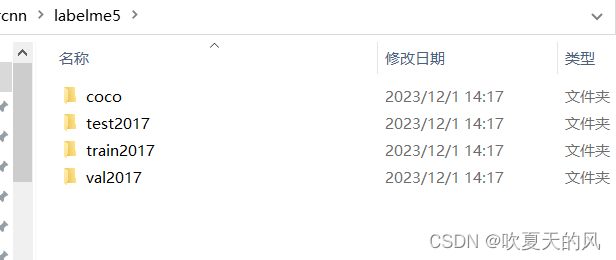


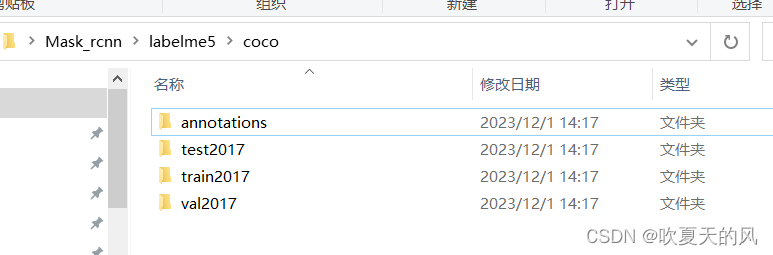
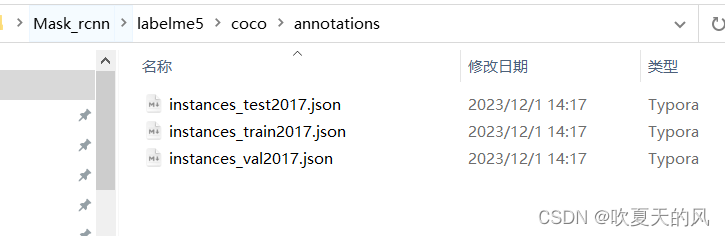
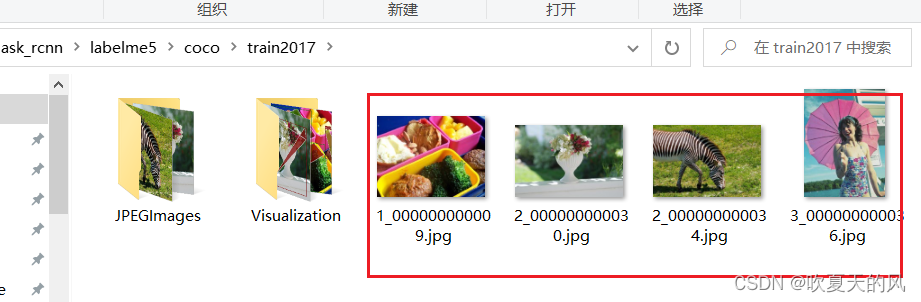
5.只需要使用coco数据集即可,annotations中的数据为所有图片包含的信息,其他文件夹中的数据只有一级目录下的图片会用到,“JPEGImages”和“Visualization(可视化)”文件夹在训练中不会用到,可以删掉
# !/usr/bin/env python
# -*-coding:utf-8 -*-
"""
# File :
# Time :2023/11/30 10:04
# Author :YJY
# version :python 3.7
# Description:用于将标注好的labelme数据集转为coco用于mmdetection 中mask_rcnn训练
"""
# !/usr/bin/python
# -*- coding: utf-8 -*-
import os
import random
import shutil
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import pycocotools.mask
import imgviz
import numpy as np
import labelme
def write_txt(label_list):
ori_list = ["__ignore__","_background_"]
with open('label_yjy.txt', 'w') as file:
for label in (ori_list + label_list):
file.write('%s\n' % label)
def convert_coco(input_dir,output_dir):
labels = "label_yjy.txt"
noviz = False
key = osp.basename(input_dir)
if osp.exists(output_dir):
print("Output directory already exists:", output_dir)
sys.exit(1)
os.makedirs(output_dir)
os.makedirs(osp.join(output_dir, "JPEGImages"))
if not noviz:
os.makedirs(osp.join(output_dir, "Visualization"))
print("Creating dataset:", output_dir)
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[dict(url=None, id=0, name=None, )],
images=[
# license, url, file_name, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
class_name_to_id = {}
for i, line in enumerate(open(labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
if class_id == -1:
assert class_name == "__ignore__"
continue
class_name_to_id[class_name] = class_id
data["categories"].append(
dict(supercategory=None, id=class_id, name=class_name, )
)
anno_dir = osp.join(osp.dirname(output_dir), "annotations")
os.makedirs(anno_dir,exist_ok=True)
out_ann_file = osp.join(anno_dir , "instances_%s.json"%(key))
label_files = glob.glob(osp.join(input_dir, "*.json"))
for image_id, filename in enumerate(label_files):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(output_dir, "JPEGImages", base + ".jpg")
out_img_file_mm = osp.join(output_dir, base + ".jpg")
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
imgviz.io.imsave(out_img_file_mm, img)
data["images"].append(
dict(
license=0,
url=None,
file_name=base + ".jpg",
height=img.shape[0],
width=img.shape[1],
date_captured=None,
id=image_id,
)
)
masks = {} # for area
segmentations = collections.defaultdict(list) # for segmentation
for shape in label_file.shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
shape_type = shape.get("shape_type", "polygon")
mask = labelme.utils.shape_to_mask(
img.shape[:2], points, shape_type
)
if group_id is None:
group_id = uuid.uuid1()
instance = (label, group_id)
if instance in masks:
masks[instance] = masks[instance] | mask
else:
masks[instance] = mask
if shape_type == "rectangle":
(x1, y1), (x2, y2) = points
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [x1, y1, x2, y1, x2, y2, x1, y2]
if shape_type == "circle":
(x1, y1), (x2, y2) = points
r = np.linalg.norm([x2 - x1, y2 - y1])
# r(1-cos(a/2))<x, a=2*pi/N => N>pi/arccos(1-x/r)
# x: tolerance of the gap between the arc and the line segment
n_points_circle = max(int(np.pi / np.arccos(1 - 1 / r)), 12)
i = np.arange(n_points_circle)
x = x1 + r * np.sin(2 * np.pi / n_points_circle * i)
y = y1 + r * np.cos(2 * np.pi / n_points_circle * i)
points = np.stack((x, y), axis=1).flatten().tolist()
else:
points = np.asarray(points).flatten().tolist()
segmentations[instance].append(points)
segmentations = dict(segmentations)
for instance, mask in masks.items():
cls_name, group_id = instance
if cls_name not in class_name_to_id:
continue
cls_id = class_name_to_id[cls_name]
mask = np.asfortranarray(mask.astype(np.uint8))
mask = pycocotools.mask.encode(mask)
area = float(pycocotools.mask.area(mask))
bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
data["annotations"].append(
dict(
id=len(data["annotations"]),
image_id=image_id,
category_id=cls_id,
segmentation=segmentations[instance],
area=area,
bbox=bbox,
iscrowd=0,
)
)
if not noviz:
viz = img
if masks:
listdata_labels = []
listdata_captions = []
listdata_masks = []
for (cnm, gid), msk in masks.items():
if cnm in class_name_to_id:
listdata_labels.append(class_name_to_id[cnm])
listdata_captions.append(cnm)
listdata_masks.append(msk)
listdata = zip(listdata_labels, listdata_captions, listdata_masks)
labels, captions, masks = zip(*listdata)
viz = imgviz.instances2rgb(
image=img,
labels=labels,
masks=masks,
captions=captions,
font_size=15,
line_width=2,
)
out_viz_file = osp.join(
output_dir, "Visualization", base + ".jpg"
)
imgviz.io.imsave(out_viz_file, viz)
with open(out_ann_file, "w") as f:
json.dump(data, f)
def split_file(path, save_path, train_num, test_num, val_num):
json_list = []
label_list = []
for root, dirs, filenames in os.walk(path):
for filename in filenames:
if filename.endswith('.json'):
json_path = os.path.join(root, filename)
json_list.append(json_path)
with open(json_path, 'r') as file:
data = json.load(file)
for data_shape in data["shapes"]:
img_label = data_shape["label"]
label_list.append(img_label)
label_list = list(set(label_list))
print(label_list)
write_txt(label_list)
random.shuffle(json_list)
train_sum = int(len(json_list) * train_num)
val_sum = int(len(json_list) * (train_num + val_num))
test_sum = int(len(json_list) * (train_num + val_num + test_num))
train_jsons = json_list[:train_sum]
val_jsons = json_list[train_sum:val_sum]
test_jsons = json_list[val_sum: test_sum]
sets = {'train2017': train_jsons, 'val2017': val_jsons, 'test2017': test_jsons}
for key, value in sets.items():
file_save_path = os.path.join(save_path, key)
os.makedirs(file_save_path, exist_ok=True)
for json_path in value:
img_path = json_path.replace(".json",".jpg")
shutil.copy(img_path, file_save_path)
shutil.copy(json_path, file_save_path)
convert_coco(file_save_path, os.path.join(save_path,"coco",key))
if __name__ == "__main__":
path = r".\images\1"
save_path = r".\Mask_rcnn\labelme5"
train_num = 0.8
test_num = 0.1
val_num = 0.1
split_file(path, save_path, train_num, test_num, val_num)
转为yolov5-7.0训练的txt格式
参考大佬:https://blog.youkuaiyun.com/m0_47452894/article/details/128632120
转换前:
转换后:
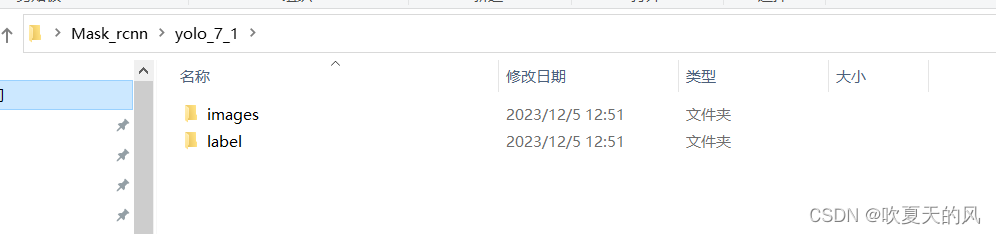
同时代码会输出标签即序号,复制到yaml文件中即可

# !/usr/bin/env python
# -*-coding:utf-8 -*-
"""
# File : labelme2yolo.py
# Time :2023/12/5 10:06
# Author :YJY
# version :python 3.7
# Description:labelme标注完的语义分割数据转yolov5_7.0训练的txt格式
"""
import json
import os
import shutil
def labelme2yolov2Seg(jsonfilePath, resultDirPath):
"""
此函数用来将labelme软件标注好的数据集转换为yolov5_7.0sege中使用的数据集
:param jsonfilePath: labelme标注好的*.json文件所在文件夹
:param resultDirPath: 转换好后的*.txt保存文件夹
:param classList: 数据集中的类别标签
:return:
"""
resultDirPath = os.path.join(resultDirPath ,"label","train")
# 0.创建保存转换结果的文件夹
os.makedirs(resultDirPath,exist_ok=True)
# 1.获取目录下所有的labelme标注好的Json文件,存入列表中
jsonfileList = []
for root, dirs, filenames in os.walk(jsonfilePath):
for filename in filenames:
if filename.endswith('.json'):
jsonfileList.append(os.path.join(root, filename))
label_list = []
# 2.遍历json文件,进行转换
for jsonfile in jsonfileList:
# 3. 打开json文件
with open(jsonfile, "r") as f:
file_in = json.load(f)
# 4. 读取文件中记录的所有标注目标
shapes = file_in["shapes"]
# 5. 使用图像名称创建一个txt文件,用来保存数据
with open(resultDirPath + "\\" + jsonfile.split("\\")[-1].replace(".json", ".txt"), "w") as file_handle:
# 6. 遍历shapes中的每个目标的轮廓
for shape in shapes:
# 7.根据json中目标的类别标签,从classList中寻找类别的ID,然后写入txt文件中
label = shape['label']
if label in label_list:
label_index = label_list.index(label)
else:
label_index = len(label_list)
label_list.append(label)
print(label_index)
file_handle.writelines(str(label_index) + " ")
# 8. 遍历shape轮廓中的每个点,每个点要进行图像尺寸的缩放,即x/width, y/height
for point in shape["points"]:
x = point[0] / file_in["imageWidth"] # mask轮廓中一点的X坐标
y = point[1] / file_in["imageHeight"] # mask轮廓中一点的Y坐标
file_handle.writelines(str(x) + " " + str(y) + " ") # 写入mask轮廓点
# 9.每个物体一行数据,一个物体遍历完成后需要换行
file_handle.writelines("\n")
# 10.所有物体都遍历完,需要关闭文件
file_handle.close()
# 10.所有物体都遍历完,需要关闭文件
f.close()
img_path = jsonfile.replace(".json", ".jpg")
img_save_path = resultDirPath.replace("labels","images")
os.makedirs(img_save_path,exist_ok=True)
shutil.copy(img_path,img_save_path)
for i,label_yam in enumerate(label_list):
print(i,":",label_yam)
if __name__ == "__main__":
jsonfilePath = r"C:\Users\10047544\Desktop\Mask_rcnn\B7_MDL_已标注" # 要转换的json文件所在目录
resultDirPath = r"C:\Users\10047544\Desktop\Mask_rcnn\yolo_7" # 要生成的txt文件夹
labelme2yolov2Seg(jsonfilePath, resultDirPath)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









