







原文:https://learnopencv.com/automatic-document-scanner-using-opencv/ PS:作者的代码有些简略而且有点问题,完全复制下来无法正常运行
目的:将左侧这种倾斜的文档自动转换为右侧正向文档
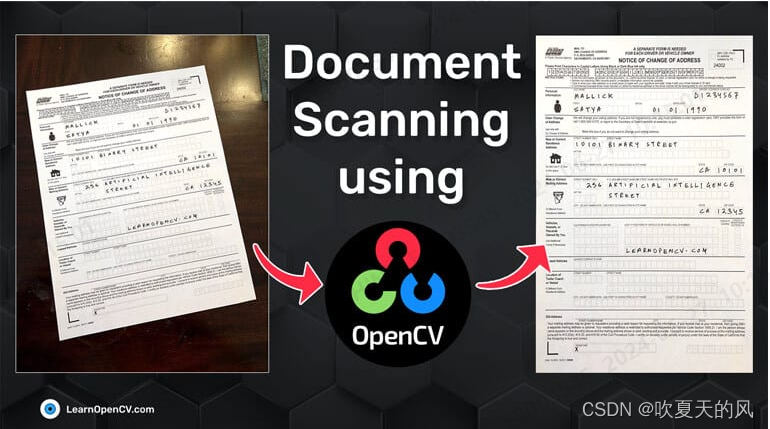
主要使用到了以下技术:
1.Morphological Operation 形态学操作
2.Edge Detection 边缘检测
3.Contour Detection 轮廓检测
4.Homography 单应性
5.GrabCut 图像分割
6.Perspective Transform 透视变换
OK,开始
1.导入图片,并进行形态学操作,屏蔽噪声
oriImg = cv2.imread("test.jpg") #原始图片路径
kernel = np.ones((5,5),np.uint8) #闭运算内核
img = cv2.morphologyEx(oriImg , cv2.MORPH_CLOSE, kernel, iterations=3)
"""
* `oriImg`: 输入图像。这通常是一个二值图像,但在某些情况下,它也可以是一个灰度图像。
* `cv2.MORPH_CLOSE`: 这是你希望执行的形态学操作的类型。在这种情况下,它是闭合(closing)操作。
闭运算:先腐蚀,后膨胀,主要用于出去噪声,比如小孔。
PS:开运算先腐蚀,后膨胀,用于关闭前景物体内部的小孔,或物体上的小黑点
* `kernel`: 这是一个定义结构元素的数组。结构元素定义了形态学操作的形状和大小。常见的结构元素包括方形、圆形、十字形等。`kernel`的大小和形状会影响形态学操作的效果。
* `iterations=3`: 这指定了形态学操作的迭代次数。在这里,膨胀和腐蚀操作都会重复3次。增加迭代次数可以增强形态学操作的效果,但也可能导致图像过度失真。
"""
2.使用grabCut进行前后背景分离,如果你分割的效果不好,可以增加grabCut函数的次数
mask = np.zeros(img.shape[:2], np.uint8) # 创建一个跟图像大小一样的全黑图像,用于前层背景
bgdModel = np.zeros((1, 65), np.float64) # grabCut参数
fgdModel = np.zeros((1, 65), np.float64) # grabCut参数
rect = (20, 20, img.shape[1] - 20, img.shape[0] - 20) # 区分前景背景,一般取图像周围一圈20像素为背景,所以这里rect为前景
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, 5, cv2.GC_INIT_WITH_RECT) # 区分前景背景
"""
img:输入图像,应该是8位单通道图像(灰度图)或8位3通道图像(彩色图)。对于彩色图像,函数会将其转换为 HSV 色彩空间。
mask:这是一个与输入图像大小相同的矩阵,用于存储分割信息。这个矩阵的每个元素可以是以下四个值之一:
GC_BGD --> 定义为明显的背景像素 0
GC_FGD --> 定义为明显的前景像素 1
GC_PR_BGD --> 定义为可能的背景像素 2
GC_PR_FGD --> 定义为可能的前景像素 3
rect:这是一个包含前景对象(你想分割出来的对象)的矩形框的坐标。它是一个四元组,格式为 (x, y, w, h),其中 (x, y) 是矩形左上角的坐标,w 是矩形的宽度,h 是矩形的高度。
bgdModel 和 fgdModel:这两个是输出数组,它们保存了背景模型和前景模型的内部数据。这些模型在函数内部被更新,并用于下一次迭代。通常,你不需要直接访问或修改这些数据。它们的尺寸应该是 65 * (1 + number of channels in img),其中 number of channels 是输入图像中的通道数(对于灰度图像是1,对于彩色图像是3)。
iterCount:迭代次数。这决定了算法将运行多少次迭代来尝试改进分割结果。增加这个值可能会改善分割的准确性,但也会增加计算时间。
mode:这个参数决定了函数的初始模式。在大多数情况下,你会使用 cv2.GC_INIT_WITH_RECT,它表示初始分割将由用户提供的矩形决定。
"""
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8') #背景的位置设置为0,前景的位置设置为1
img = img * mask2[:, :, np.newaxis]
#np.newaxis作用是增加一个维度,因为原始img是3维,我们创建的Mask是2维,
# 这里的作用是将原图与我们的Mask相乘,因为Mask 背景为0,前景为1,所以相乘后,原图背景变为黑,前景不变
3.使用canny进行边缘检测
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #转换为灰度图
gray = cv2.GaussianBlur(gray, (11, 11), 0) #高斯模糊,去除噪声
# Edge Detection.
canny = cv2.Canny(gray, 0, 200) #边缘检测
canny = cv2.dilate(canny, cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))) #对检测到边缘继续宁膨胀,方便更好的找到轮廓
# Blank canvas.
con = np.zeros_like(img) #再创建一个全黑图像,
# Finding contours for the detected edges.
contours, hierarchy = cv2.findContours(canny, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE) #找到轮廓
# Keeping only the largest detected contour.
page = sorted(contours, key=cv2.contourArea, reverse=True)[:5] #对前五个检测到的论轮廓按面积进行排序,因为可能右很多轮廓,这里取前5个,其实本例中这种明显的取第一个就行
con = cv2.drawContours(con, page, -1, (0, 255, 255), 3 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









