






前言:记录爬虫过程,不然每次都忘记,又得重新搜。任务是爬取关于延迟退休的评论,并用nltk库进行情感分析。
一、找一个B站视频,F12开发者模式,点击network,复制一条评论搜索
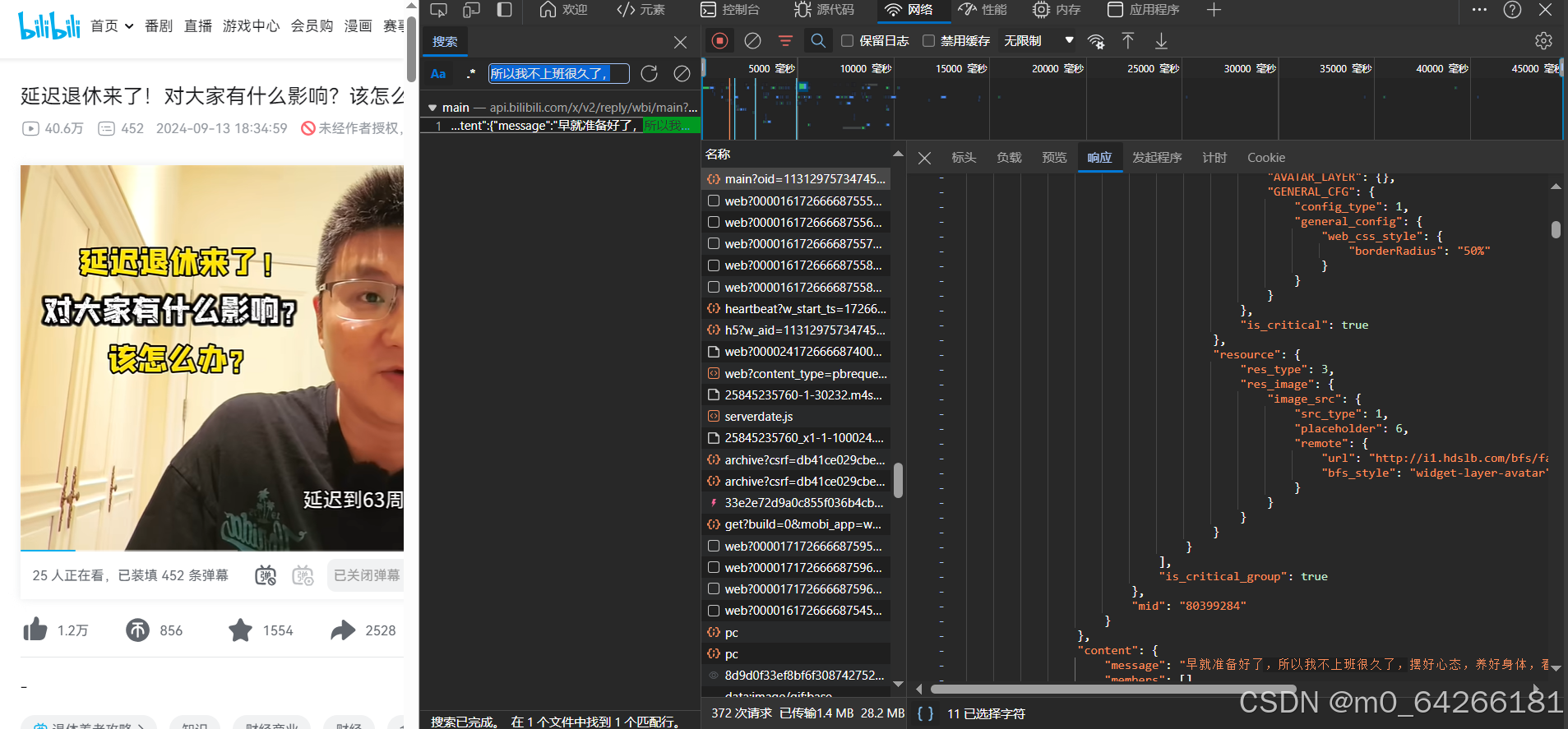
二、点击标头,把请求头信息填写完整
headers = {
# 用户身份信息
'cookie':'',
# 防盗链
'referer': 'https://www.bilibili.com/video/BV1Dy4ZeGE65/?spm_id_fl.click&vd_source=9eb85705d55b0619897671ea4e9a511a',
# 浏览器基本信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'
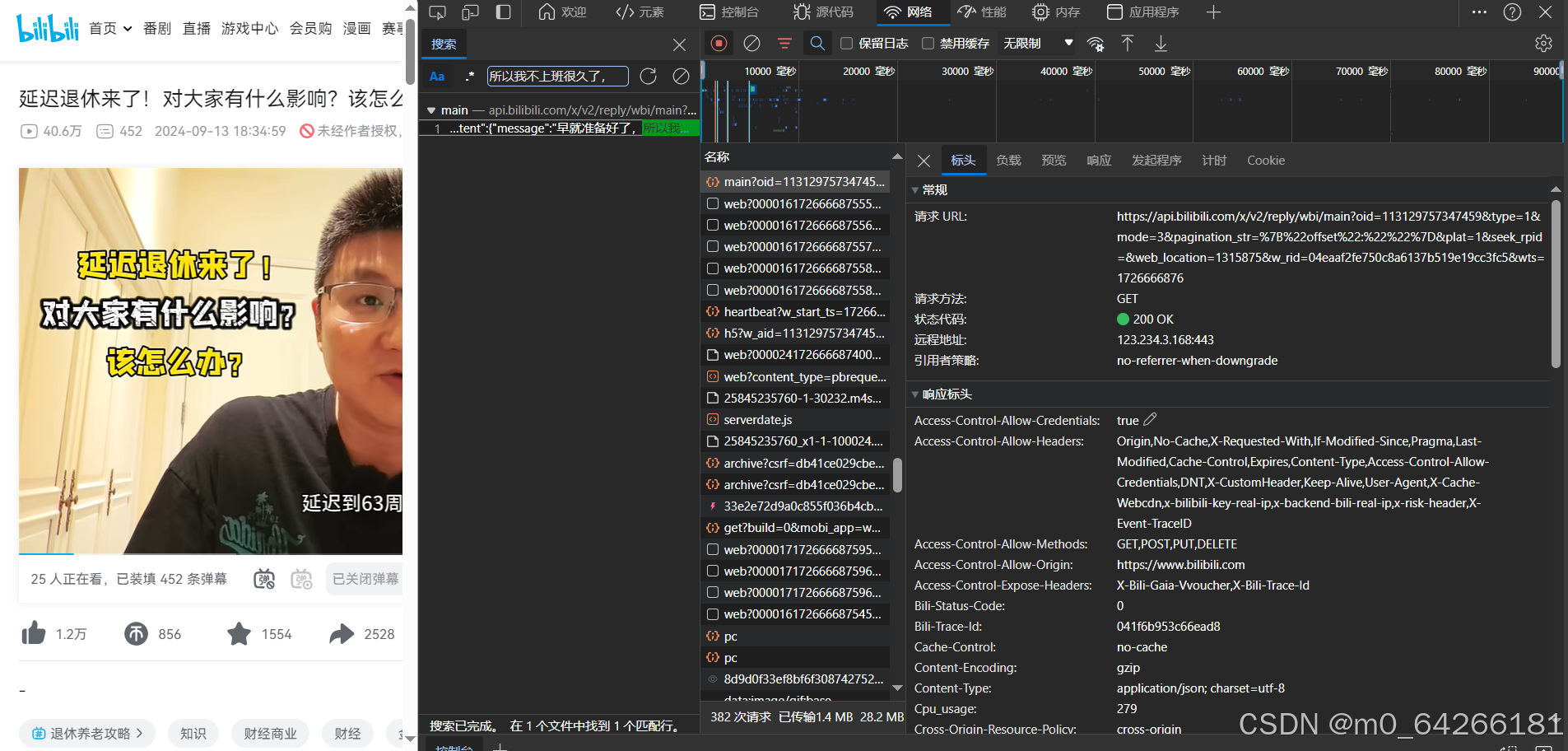
}三、双击图中链接,得到JSON数据,把网址复制到url中

url = 'https://api.bilibili.com/x/v2/reply/wbi/main?oid=113129757347459&type=1&mode=3&pagination_str=%7B%22offset%22:%22%22%7D&plat=1&seek_rpid=&web_location=1315875&w_rid=9d347338206a16120f9a3c326f9a77cb&wts=1726648963'
# 1.发送请求
response = requests.get(url=url, headers=headers)
# print(response.text) # 得到网页的源代码四、写入文件, 再从文件中读取JSON(以前爬学校网站,因为调试,爬取过于频繁,被封IP了。所以习惯爬到了就写入文件,调试时候就读文件)
可以把txt文本用JSON在线工具给规范格式,再把txt文件丢给AI,让AI完成提取JSON的编码。如果不规范格式直接丢给AI,AI大概率实现不了。
# 2.打印网页数据
# print(response.text)
with open('output.txt', 'w', encoding='utf-8') as f:
f.write(response.text)
# 打开并读取JSON文件
with open('output.txt', 'r', encoding='utf-8') as file:
data = json.load(file)
comments = data.get('data', {}).get('replies', [])
messages = [comment.get('content', {}).get('message', '') for comment in comments]
messagesList = []
# 打印所有提取的消息
for message in messages:
messagesList.append(message)五、计算情感得分
sia = SentimentIntensityAnalyzer()
for comment in messagesList:
sentiment_scores = sia.polarity_scores(comment)
print(f"评论:{comment}")
print(f"情感分数:{sentiment_scores}")
print("----------")完整代码
#encoding=utf-8
import json
import requests
from nltk.sentiment import SentimentIntensityAnalyzer
# 请求头
headers = {
# 用户身份信息
'cookie':'',
# 防盗链
'referer': 'https://www.bilibili.com/video/BV1Dy4ZeGE65/?spm_id_fl.click&vd_source=9eb85705d55b0619897671ea4e9a511a',
# 浏览器基本信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36 Edg/121.0.0.0'
}
url = 'https://api.bilibili.com/x/v2/reply/wbi/main?oid=113129757347459&type=1&mode=3&pagination_str=%7B%22offset%22:%22%22%7D&plat=1&seek_rpid=&web_location=1315875&w_rid=9d347338206a16120f9a3c326f9a77cb&wts=1726648963'
# 1.发送请求
response = requests.get(url=url, headers=headers)
# 2.打印网页数据
# print(response.text)
with open('output.txt', 'w', encoding='utf-8') as f:
f.write(response.text)
# 打开并读取JSON文件
with open('output.txt', 'r', encoding='utf-8') as file:
data = json.load(file)
comments = data.get('data', {}).get('replies', [])
messages = [comment.get('content', {}).get('message', '') for comment in comments]
messagesList = []
# 打印所有提取的消息
for message in messages:
messagesList.append(message)
# print(messagesList)
# nltk.download('vader_lexicon')
sia = SentimentIntensityAnalyzer()
for comment in messagesList:
sentiment_scores = sia.polarity_scores(comment)
print(f"评论:{comment}")
print(f"情感分数:{sentiment_scores}")
print("----------")

















 2621
2621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









