







目录
1.set(name, value, ex=None, px=None, nx=False, xx=False)
3. psetex(name, time_ms, value)
4. mset(*args, **kwargs) (批量设置值)
9.bitcount(key, start=None, end=None)
12.incrbyfloat(self, name, amount=1.0)
11.hincrby(name, key, amount=1)
12.hincrbyfloat(name, key, amount=1.0)
13.hscan(name, cursor=0, match=None, count=None)
14.hscan_iter(name, match=None, count=None)
4.linsert(name, where, refvalue, value))
13.brpoplpush(src, dst, timeout=0)
4.sdiffstore(dest, keys, *args)
6.sinterstore(dest, keys, *args)
14.sunionstore(dest,keys, *args)
15.sscan(name, cursor=0, match=None, count=None)
16.sscan_iter(name, match=None, count=None)
1.zadd(name, {*args, **kwargs})
4.zincrby(name, amount, value)
5.r.zrange(name,start,end,desc=False, withscores=False, score_cast_func=float)
8.zremrangebyrank(name, min, max)
9.zremrangebyscore(name, min, max)
11.zinterstore(dest, keys, aggregate=None)
12.zunionstore(dest, keys, aggregate=None)
13.zscan(name,cursor=0,match=None,count=None,score_cast_func=float)
zscan_iter(name,match=None,count=None,score_cast_func=float)
什么是API?
API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。
Python如何与Redis交互
Redis的数据类型总述
Redis支持五种数据类型:
string(字符串),hash(哈希),list(列表),set(集合),zset(sorted set:有序集合)。
| String | set、setex、psetex、mset、mget、getset、getrange、setrange、setbit、getbit、bitcount、bittop、strlen、incr、incrfloat、decr、append |
| Hash | hset、hmset、hmget、hgetall、hlen、hkeys、hvals、hexists、hdel、hincrby、hincrbyfloat、hscan、hscan_iter |
| List | lpush、rpush、lpushx、rpushx、linsert、lset、lrem、lpop、ltrim、lindex、rpoplpush、 brpoplpush、blpop |
| Set | sadd、scard、smembers、sdiff、sdiffstore、sinter、sinterstore、sunion、sismember、smove、spop |
| Zset | zadd、zcard、zrange、zcount、zincraby、zrank、zrem、zremrangebyrank、zscore |
以下测试均使用python与redis交互,可参考文章:https://blog.youkuaiyun.com/m0_64139004/article/details/127716915
| 类型 | 特性 | 场景 |
|---|---|---|
| String | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | -- |
| Hash | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List | 增删快,提供了操作某一段元素的API | 最新消息排行等功能(比如朋友圈的时间线);消息队列 |
| Set | 添加、删除,查找的复杂度都是O(1) 为集合提供了求交集、并集、差集等操作 | 1、共同好友;2、利用唯一性,统计访问网站的所有独立ip;3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted set | 数据插入集合时,已经进行天然排序 | 1、排行榜;2、带权重的消息队列 |
String类型
1.set(name, value, ex=None, px=None, nx=False, xx=False)
——在Redis中设置值,不存在则创建,存在则修改
get()——获取值
参数说明:
①ex,过期时间(秒) (ex过期时间(秒) 这里是10秒,10秒后,键food的值就变成None)
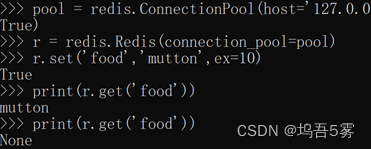
②px,过期时间(毫秒) 同理
③nx,如果设置为True,则只有name不存在时,当前set操作才执行
![]()

(# 如果键fruit已经存在,那么输出是True;如果键fruit不存在,输出是None)
④xx,如果设置为True,则只有name存在时,当前set操作才执行(与nx正好相反)
⑤setnx(name, value),设置值,只有name不存在时,执行设置操作(添加)
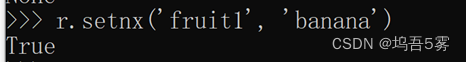
2.setex(name,time,value)
设置值:value
参数:time,过期时间(数字秒 或 timedelta对象)
import redis
import time
pool = redis.ConnectionPool(host='127.0.0.1', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.setex("fruit", 5, "apple")
time.sleep(5)
print(r.get('fruit')) # 5秒后,取值就从apple变成None
3. psetex(name, time_ms, value)
参数:time_ms,过期时间(数字毫秒 或 timedelta对象)
r.psetex("fruit1", 5000, "orange")
time.sleep(5)
print(r.get('fruit1')) # 5000毫秒后,取值就从orange变成None
4. mset(*args, **kwargs) (批量设置值)
mget(keys, *args)(批量获取值)
r.mset({'k1': 'v1', 'k2': 'v2'})
r.mset(k1="v1", k2="v2") # 这里k1 和k2 不能带引号 一次设置对个键值对
print(r.mget("k1", "k2")) # 一次取出多个键对应的值
print(r.mget("k1"))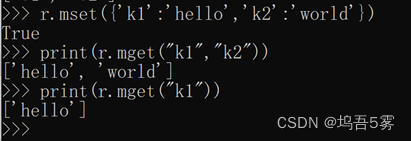
5.getset(name, value)
设置新值并获取原来的值
print(r.getset("food", "barbecue")) # 设置的新值是barbecue 设置前的值是beef16.getrange(key, start, end)
获取子序列(根据字节获取,非字符)
参数:
name,Redis 的 name
start,起始位置(字节)
end,结束位置(字节)
如: # “君惜大大” ,0-3表示 “君”
r.set("cn_name", "君惜大大") # 汉字
print(r.getrange("cn_name", 0, 2))
# 取索引号是0-2 前3位的字节 君 切片操作 (一个汉字3个字节 1个字母一个字节 每个字节8bit)
print(r.getrange("cn_name", 0, -1)) # 取所有的字节 君惜大大 切片操作
r.set("en_name","junxi") # 字母
print(r.getrange("en_name", 0, 2))
# 取索引号是0-2 前3位的字节 jun 切片操作 (一个汉字3个字节 1个字母一个字节 每个字节8bit)
print(r.getrange("en_name", 0, -1)) # 取所有的字节 junxi 切片操作
7.setbit(name, offset, value)
对name对应值的二进制表示的位进行操作
参数:
name,redis的name
offset,位的索引(将值变换成二进制后再进行索引)
value,值只能是 1 或 0
注:如果在Redis中有一个对应: n1 = "foo",那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
# 扩展,转换二进制表示:
source = "张三"
source = "foo"
for i in source:
num = ord(i)
print bin(num).replace('b','')特别的,如果source是汉字 "张三"怎么办?
答:对于utf-8,每一个汉字占 3 个字节,那么 "张三" 则有 6个字节
对于汉字,for循环时候会按照 字节 迭代,那么在迭代时,将每一个字节转换 十进制数,然后再将十进制数转换成二进制
8.getbit(name, offset)
获取name对应的值的二进制表示中的某位的值 (0或1)
print(r.getbit("foo1", 0)) # 0 foo1 对应的二进制 4个字节 32位 第0位是0还是19.bitcount(key, start=None, end=None)
获取name对应的值的二进制表示中 1 的个数
参数:
key,Redis的name
start 字节起始位置
end,字节结束位置
print(r.get("foo")) # goo1 01100111
print(r.bitcount("foo",0,1)) # 11 表示前2个字节中,1出现的个数10.strlen(name)
返回name对应值的字节长度(一个汉字3个字节)
print(r.strlen("foo")) # 4 'goo1'的长度是411.incr(self, name, amount=1)
自增 name对应的值,当name不存在时,则创建name=amount,否则,自增。
参数:
name,Redis的name
amount,自增数(必须是整数)
注:同incrby
r.set("foo", 123)
print(r.mget("foo", "foo1", "foo2", "k1", "k2"))
r.incr("foo", amount=1)
print(r.mget("foo", "foo1", "foo2", "k1", "k2"))应用场景 – 页面点击数
假定我们对一系列页面需要记录点击次数。例如论坛的每个帖子都要记录点击次数,而点击次数比回帖的次数的多得多。如果使用关系数据库来存储点击,可能存在大量的行级锁争用。所以,点击数的增加使用redis的INCR命令最好不过了。
①当redis服务器启动时,可以从关系数据库读入点击数的初始值(12306这个页面被访问了34634次)
r.set("visit:12306:totals", 34634)
print(r.get("visit:12306:totals"))
②每当有一个页面点击,则使用INCR增加点击数即可。
r.incr("visit:12306:totals")
r.incr("visit:12306:totals")
③页面载入的时候则可直接获取这个值
print(r.get("visit:12306:totals"))
12.incrbyfloat(self, name, amount=1.0)
自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
参数:
name,Redis的name
amount,自增数(浮点型)
r.set("foo1", "123.0")
r.set("foo2", "221.0")
print(r.mget("foo1", "foo2"))
r.incrbyfloat("foo1", amount=2.0)
r.incrbyfloat("foo2", amount=3.0)
print(r.mget("foo1", "foo2"))13.decr(self, name, amount=1)
自减 name对应的值,当name不存在时,则创建name=amount,否则,自减。
参数:
name,Redis的name
amount,自减数(整数)
r.decr("foo4", amount=3) # 递减3
r.decr("foo1", amount=1) # 递减1
print(r.mget("foo1", "foo4"))14.append(key, value)
在redis name对应的值后面追加内容
参数:
key, redis的name
value, 要追加的字符串
r.append("name", "haha") # 在name对应的值junxi后面追加字符串haha
print(r.mget("name"))Hash类型
1.hset(name, key, value)
参数:
name,对应的hash中设置一个键值对(不存在,则创建;否则,修改)
key,name对应的hash中的key
value,name对应的hash中的value
注:hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)

2.hmset(name, mapping)
参数:
name,在name对应的hash中批量设置键值对
mapping,字典,如:{‘k1’:‘v1’, ‘k2’: ‘v2’}
如:r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
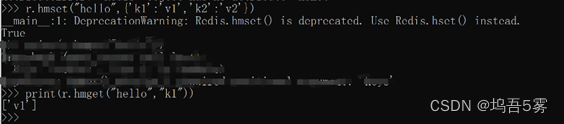
3.hget(name,key)
在name对应的hash中获取根据key获取value
4.hmget(name, keys, *args)
在name对应的hash中获取多个key的值
参数:
name,reids对应的name
keys,要获取key集合,如:[‘k1’, ‘k2’, ‘k3’]
*args,要获取的key,如:k1,k2,k3
如:r.mget('xx', ['k1', 'k2'])
或:print r.hmget('xx', 'k1', 'k2')
5.hgetall(name)
获取name对应hash的所有键值
6.hlen(name)
获取name对应的hash中键值对的个数
7.hkeys(name)
获取name对应的hash中所有的key的值
8.hvals(name)
获取name对应的hash中所有的value的值
9.hexists(name, key)
检查name对应的hash是否存在当前传入的key
10.hdel(name,*keys)
将name对应的hash中指定key的键值对删除
11.hincrby(name, key, amount=1)
自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:
name,redis中的name
key, hash对应的key
amount,自增数(整数)
12.hincrbyfloat(name, key, amount=1.0)
自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:
name,redis中的name
key, hash对应的key
amount,自增数(浮点数)
13.hscan(name, cursor=0, match=None, count=None)
增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
参数:
name,redis的name
cursor,游标(基于游标分批取获取数据)
match,匹配指定key,默认None 表示所有的key
count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 如:
第一次:cursor1, data1 = r.hscan(‘xx’, cursor=0, match=None, count=None)
第二次:cursor2, data1 = r.hscan(‘xx’, cursor=cursor1, match=None, count=None)
…
直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
14.hscan_iter(name, match=None, count=None)
利用yield封装hscan创建生成器,实现分批去redis中获取数据
参数:
match,匹配指定key,默认None 表示所有的key
count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
如:
for item in r.hscan_iter(‘xx’):
print(item)List类型
1.lpush(name,values)
在name对应的list中添加元素,每个新的元素都添加到列表的最左边
如:r.lpush('oo', 11,22,33) # 保存顺序为: 33,22,11
rpush(name, values) # 表示从右边插入数据
2.lpushx(name,value)
在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
rpushx(name, value) 表示从右向左操作
3.llen(name)
name对应的list元素的个数
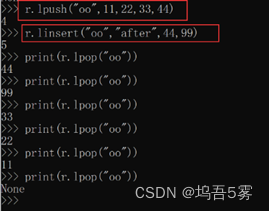
4.linsert(name, where, refvalue, value))
在name对应的列表的某一个值前或后插入一个新值
参数:
name,redis的name
where,BEFORE或AFTER
refvalue,标杆值,即:在它前后插入数据
value,要插入的数据

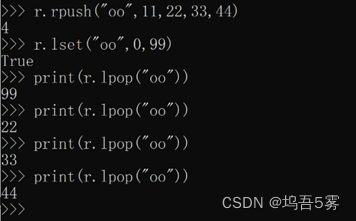
5.r.lset(name, index, value)
对name对应的list中的某一个索引位置重新赋值
参数:
name,redis的name
index,list的索引位置
value,要设置的值
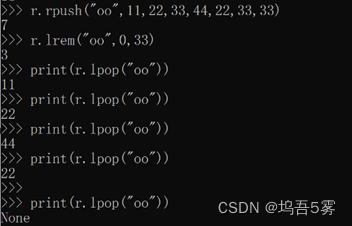
6.r.lrem(name, num,value)
在name对应的list中删除指定的值
参数:
name,redis的name
num,num=0,删除列表中所有的指定值;num = 2,从前到后,删除2个; num = -2,从后向前,删除2个;
value,要删除的值
7.lpop(name)
在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
rpop(name) 表示从右向左操作

8.lindex(name, index)
在name对应的列表中根据索引获取列表元素

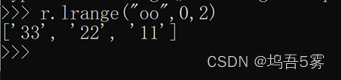
9.lrange(name, start, end)
在name对应的列表分片获取数据
参数:
name,redis的name
start,索引的起始位置
end,索引结束位置
10.ltrim(name, start, end)
在name对应的列表中移除没有在start-end索引之间的值
参数:
name,redis的name
start,索引的起始位置
end,索引结束位置

11.rpoplpush(src, dst)
从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
参数:
src,要取数据的列表的name
dst,要添加数据的列表的name

12.blpop(src, dst, timeout=0)
将多个列表排列,按照从左到右去pop对应列表的元素
参数:
src,取出并要移除元素的列表对应的name
dst,要插入元素的列表对应的name
timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
r.brpop(src,dst,timeout) 从右向左获取数据
13.brpoplpush(src, dst, timeout=0)
从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:
src,取出并要移除元素的列表对应的name
dst,要插入元素的列表对应的name
timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
Set类型
1.sadd(name,values)
name对应的集合中添加元素
2.scard(name)
获取name对应的集合中元素个数
3.sdiff(keys, *args)
在第一个name对应的集合中且不在其他name对应的集合的元素集合

4.sdiffstore(dest, keys, *args)
获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中

5.sinter(keys, *args)
获取多一个name对应集合的交集
6.sinterstore(dest, keys, *args)
获取多一个name对应集合的交集,再将其加入到dest对应的集合中

7.sismember(name, value)
检查value是否是name对应的集合的成员
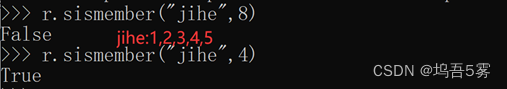
8.smembers(name)
获取name对应的集合的所有成员

9.smove(src, dst, value)
将某个成员从一个集合中移动到另外一个集合
src:要移走元素的集合
dst:要将元素移到该集合;
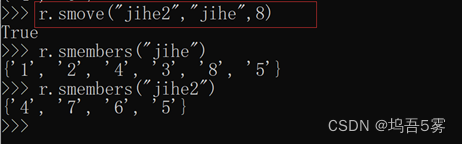
10.spop(name)
从集合的右侧(尾部)移除一个成员,并将其返回
11.srandmember(name, numbers)
从name对应的集合中随机获取 numbers 个元素
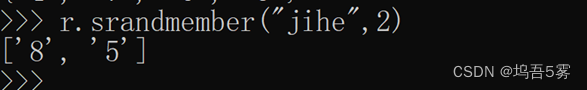
12.srem(name, values)
在name对应的集合中删除某些值
13.sunion(keys, *args)
获取多一个name对应的集合的并集
14.sunionstore(dest,keys, *args)
获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
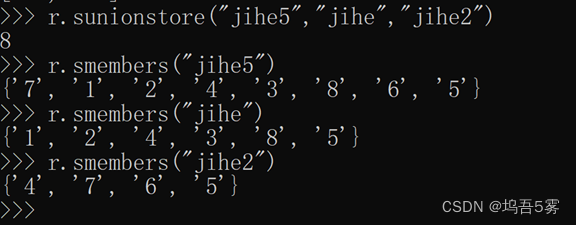
15.sscan(name, cursor=0, match=None, count=None)
16.sscan_iter(name, match=None, count=None)
与String的操作相同,用于增量迭代分批获取元素,避免内存消耗太大
Zset类型
1.zadd(name, {*args, **kwargs})
在name对应的有序集合中添加元素
![]()
2.zcard(name)
获取name对应的有序集合元素的数量

3.zcount(name, min, max)
获取name对应的有序集合中分数 在 [min,max] 之间的个数

4.zincrby(name, amount, value)
官方文档:https://redis.io/commands/zincrby/
解释文档:Zset-zincrby - 红雨520 - 博客园
勿踩坑:Redis zset的zadd()和zincrby()踩坑记录_XerCis的博客-优快云博客_zincrby和zadd
其中name为有序集合名,amount为数值,value为键名
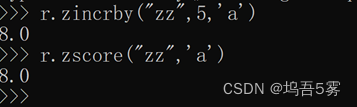 a原本值为3,加3+5=8.0
a原本值为3,加3+5=8.0
5.r.zrange(name,start,end,desc=False, withscores=False, score_cast_func=float)
按照索引范围获取name对应的有序集合的元素
参数:
name,redis的name
start,有序集合索引起始位置(非分数)
end,有序集合索引结束位置(非分数)
desc,排序规则,默认按照分数从小到大排序
withscores,是否获取元素的分数,默认只获取元素的值
score_cast_func,对分数进行数据转换的函数
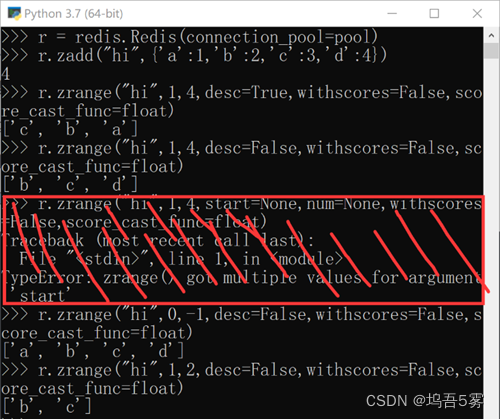
start\end是列表中元素的角标,如0代表第一位,-1代表最后一位.
6.zrank(name, value)
获取某个值在 name对应的有序集合中的排行(从 0 开始)
 hi:[a:1,b:2,c:3,d:4]
hi:[a:1,b:2,c:3,d:4]
更多:zrevrank(name, value),从大到小排序
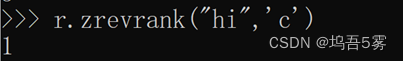
7.zrem(name, values)
删除name对应的有序集合中值是values的成员
 r.zrem(“hi”,’a’,’c’)删除的是a和c而不是a-c之间的内容
r.zrem(“hi”,’a’,’c’)删除的是a和c而不是a-c之间的内容
8.zremrangebyrank(name, min, max)
根据排行范围删除

9.zremrangebyscore(name, min, max)
根据分数范围删除

10.zscore(name, value)
获取name对应有序集合中 value 对应的分数

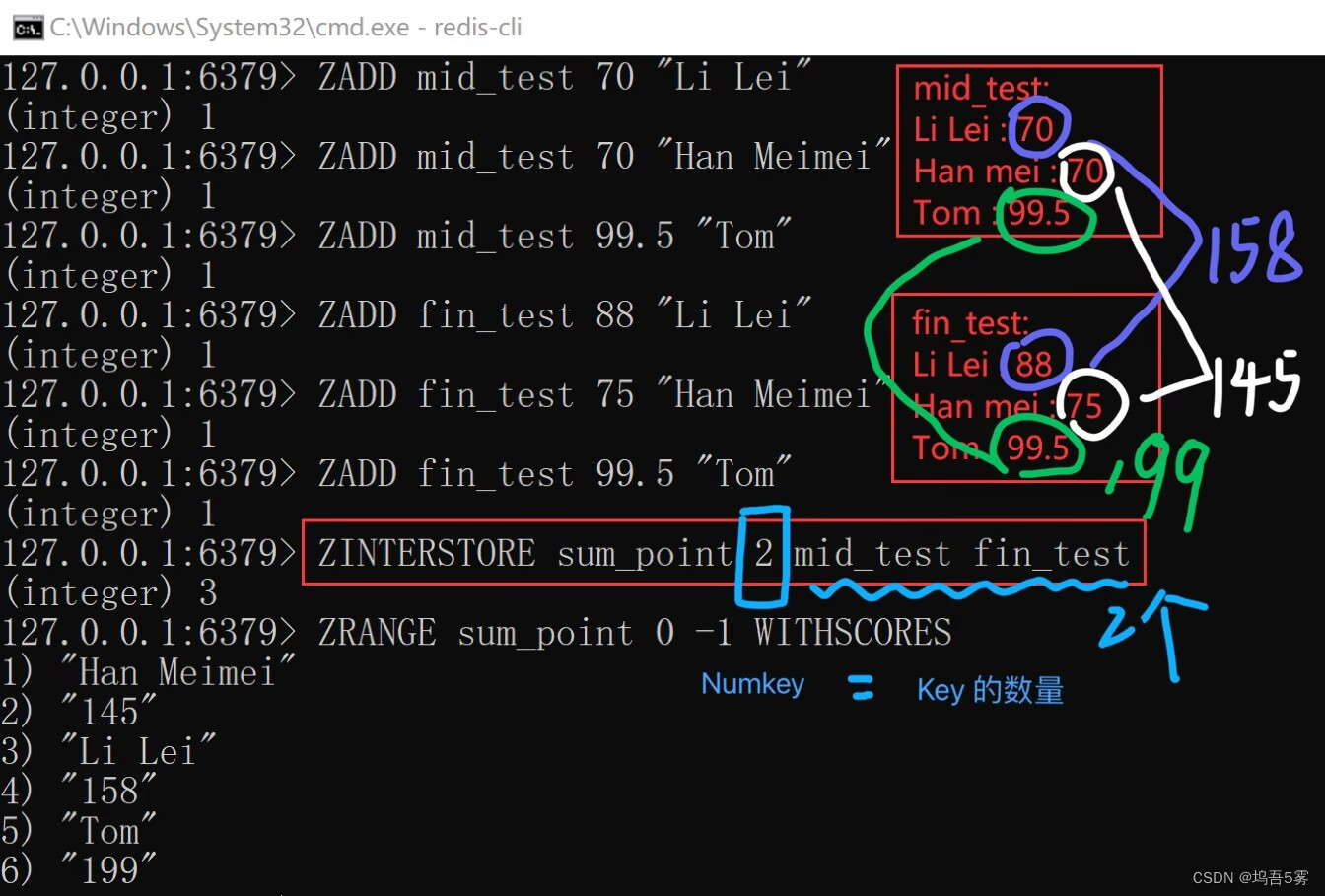
11.zinterstore(dest, keys, aggregate=None)
------------------------python中不知如何使用?
获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
aggregate的值为: SUM MIN MAX
12.zunionstore(dest, keys, aggregate=None)
获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作
aggregate的值为: SUM MIN MAX
13.zscan(name,cursor=0,match=None,count=None,score_cast_func=float)
zscan_iter(name,match=None,count=None,score_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









