







文章目录
977. 有序数组的平方
题目链接
解题思路:
排序:
- 先将每个数组元素进行平方,平方后进行排序!
时间复杂度:O(log(n))
空间复杂度:O(n)
实现代码:
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
int n = nums.size();
for (int i=0; i < n; i ++) {
nums[i] = nums[i] * nums[i];
}
sort(nums.begin(), nums.end());
return nums;
}
};
双指针:
- 题目给定的是升序数组。含有负数的升序数组!
- 那么以正负为分界线。负数部分平方后,从左往右是降序下降。正数部分从右往左是也是降序的。则呈现的趋势如下图:
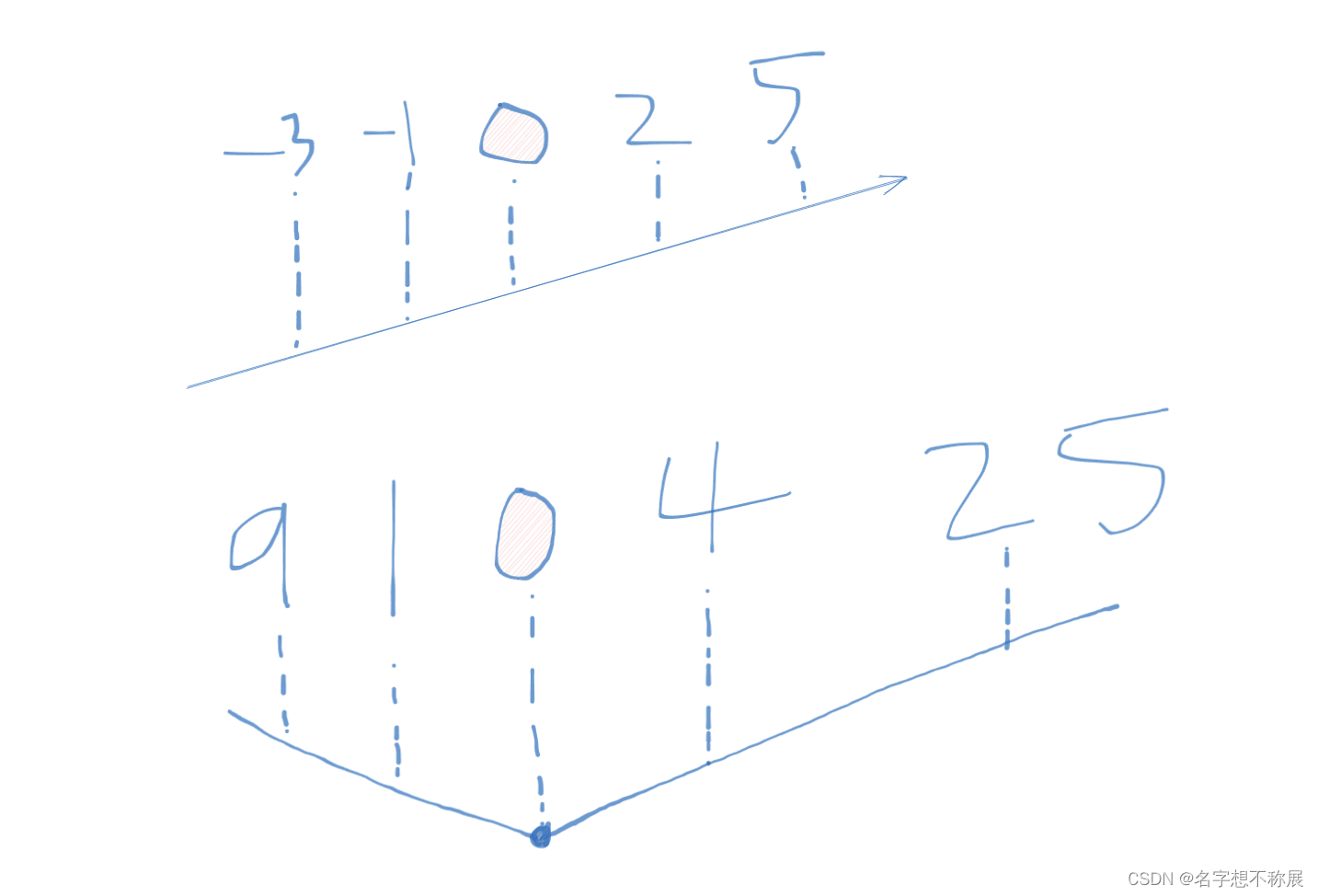
- 所以说目的是,将负数部分给合理地安插在右边的正数里面!关键是将左边的降序部分与右边的降序部分进行比较大小。
- 那么如何进行比较呢?可以定义一个新的数组,重新构建数组!然后首尾两个指针。当比较到0这个点的时候,就停止,因为0右边的部分已经是升序了,没必要再比了。所以在比较之前还需要找到正负数的分界线!
- 首指针和尾指针指向的元素进行两两比较,将较大的元素放入新数组的末尾,因为是从正负部分的最大值开始比较,所以说就只能逆序放置。
- 假如左指针指向的元素比右指针指向的元素大,则将该元素放入位置后,左指针+1移动,然后右指针不动,等待与下一个左指针的元素比较,看看谁更大!
实现代码:
class Solution {
public:
vector<int> sortedSquares(vector<int>& nums) {
int n = nums.size();
for(int i=0; i < n; i ++) {
nums[i] = nums[i] * nums[i];
}
vector<int> ans(n);
int l=0, r = n-1;
while (l < r)
{
if (nums[l] > nums[r]) {
n --;
ans[n] = nums[l];
l ++;
}
else {
n --;
ans[n] = nums[r];
r --;
}
}
ans[0] = nums[r];
return ans;
}
};
class Solution(object):
def sortedSquares(self, nums):
l, r, k = 0, len(nums)-1, len(nums) - 1
res = [float('inf')] * len(nums) # 提前定义列表,存放结果
while l <= r:
if nums[l] ** 2 <= nums[r] ** 2:
res[k] = nums[r] ** 2
r -= 1
else :
res[k] = nums[l] ** 2
l += 1
k -= 1
return res
res = [float('inf')] * len(nums) # 提前定义列表,存放结果
该代码解析:
这行代码是在 Python 中创建了一个列表,列表的长度等于 nums 列表的长度,而列表中的每个元素都被初始化为 float(‘inf’)。
这里,float(‘inf’) 是 Python 中的特殊值,表示正无穷大。通常,我们在需要将一个值初始化为非常大的值时,会使用 float(‘inf’)。
[float(‘inf’)] * len(nums) 是列表解析的一种形式,它会创建一个新的列表,其中包含 len(nums) 个 float(‘inf’)。
所以,res = [float(‘inf’)] * len(nums) 创建了一个新的列表 res,长度与 nums 相同,所有元素都为正无穷大。
这样的数据结构通常用在动态规划等算法中,当你需要一个大的初值,然后在后续的计算中通过比较和替换,逐渐找到最小值或最优解。
该列表 res 中的所有元素都被初始化为 float(‘inf’),所以它们的数据类型都是浮点数(float)。在 Python 中,float(‘inf’) 创建的是一个正无穷大的浮点数。因此,列表 res 是一个由浮点数组成的列表。
遇到的问题:
- 双指针代码并没有寻找正负数的分界线,而是直接以
while(l < r)作为终止,但是当l==r时,意味着指向同一个元素,但由于终止了,并没有进入循环,所以在循环弹出后,还需要将这个元素赋值给新数组的第一个位置。
题目总结:
- 双指针可以将对称性转化为单调性。
209. 长度最小的子数组
题目链接
解题思路:
前缀和:自己的
- 求出前缀和数组。
- 然后枚举长度,从小到大枚举不同长度下的所有连续子数组的和值,是否满足条件,一旦有满足条件的,马上
break即可!
时间复杂度:O(n^2)
空间复杂度:O(n)
实现代码:
超时!
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int n = nums.size();
vector<int> s(n, 0); //初始长度为n,初值=0;
s[0] = nums[0];
for (int i=1; i < n; i ++) {
s[i] = s[i-1] + nums[i];
}
//枚举不同长度下的所有子数组:
for (int len=1; len <= n; len ++) {
for (int l=0; l + len - 1 < n; l ++) {
int r = l + len - 1;
if (l == 0) {
if (s[r] >= target) {
return r - l + 1;
}
}
else {
if (s[r] - s[l-1] >= target) {
return r - l + 1;
}
}
}
}
return 0;
}
};
滑动窗口:别人的
前缀和超时的原因在于:外层循环负责枚举长度,内层循环负责枚举该长度下的所有子数组。从而存在不必要的比较。
一般数据范围为 1e5,则只能采用 O(n) 的解法。
且题目规定了是连续的子数组,故可以采用两个指针保证子数组连续。
我们可以设置一个窗口去滑动,即左右指针:
- 由于给定的元素均为正数,所以当区间内增加元素的时候,区间和必然增大。反之减小。
- 而每增加一个元素,我们都要判断当前区间和是否比目标值大,若大的话,则记录当前数组的长度,即右指针 - 左指针 + 1 = 区间长度。然后就没必要继续增加元素了,因为我们是要寻找一个长度最短的,若当前加入的元素足够大,那么我们缩进左边的指针,那么也有可能使得区间和 > 目标值,为了最优解所以要试一试。当缩进左边区间的长度后,发现却小于了目标值,此时应该停止,继续移动右指针,增添元素。直到满足条件为止,循环步骤2。
实现代码:
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int n = nums.size();
long long sum=0;
int len = 1e5+10;
bool flag = false;
for (int r=0, l=0; r < n; r ++)
{
sum += nums[r]; //每次r移动一位,然后就加上该位!
while (sum >= target)//判断新加入的数有没有影响区间的性质!
{
sum -= nums[l];
len = min (len, r-l+1);
l ++;
if (!flag) flag = true;
}
}
if (flag) return len;
else return 0;
}
};
class Solution {
public:
int minSubArrayLen(int target, vector<int>& nums) {
int n = nums.size();
int l = 0, r = 0;
int sum = 0;
int res = 1000010;
while (r < n)
{
sum += nums[r];
while (sum >= target) {
res = min(res, r - l + 1);
sum -= nums[l ++];
}
r ++;
}
if (res == 1000010) return 0;
else return res;
}
};
遇到的问题:
前缀和解法里面,当求区间和的时候对于左边界要进行一次特别判断!特殊处理!
题目总结:
滑动窗口的本质是双指针。
双指针还可以用来解决区间和问题。
但本题也属于单调队列的问题,所以可以将单调队列 ≈ 滑动窗口 ≈ 双指针。
59.螺旋矩阵II
题目链接
解题思路:
偏移量版本:自己的
- 由题目可知,每次是移动一个格子的,所以说我们可以设置偏移量数组,然后利用偏移量每次移动一个格子。
- 又因为当移动到边界的时候,需要拐弯,边界的情况如下:四种越界的情况 + 该位置已经有元素了,所以需要拐弯!
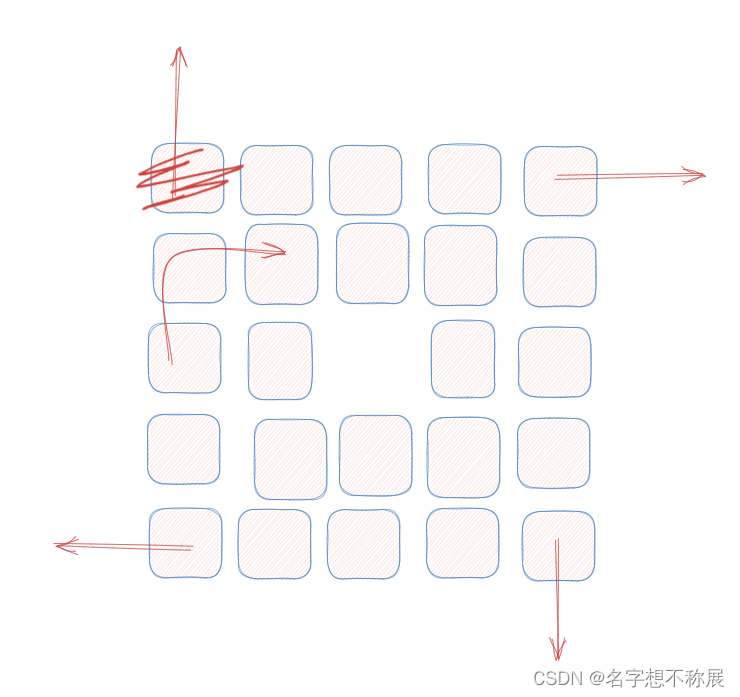
- 所以说每次走完一步,我们都需要求出下一步,从而判断下一步是否越界,下一步越界的话,我们就需要提前调整我们的方向,使得下一次再叠加偏移量的时候能够顺利拐弯!
- 注意:偏移量数组的顺序也是不能够随意设置的,因为题目要求是顺时针,所以拐弯的顺序也要按照顺时针的顺序进行!
- 如何改变偏移量数组的方向呢?首先就是4个方向,从顺时针开始:每次碰壁就拐弯,依次为:右、下、左、上、右、、、不难看出是一个循环!
- 而偏移量数组的方向取决于下标
dx[index],dy[index]来决定的。所以说要改变偏移量数组的方向就要改变偏移量数组的下标。由于dx[], dy[]数组只有四个元素,本质是因为只有4个方向,所以说是在4个方向里面依次切换!即:0、1、2、3、0,,, - 如下是我们的偏移量数组的代码:那么不难看出 下标0:向右走;下标1:向下走,依次类推,那么我们可以通过循环取余的方式来改变方向啊!使得我们在:0、1、2、3、0、1…这四个方向之间不断循环!
int dx[] = {0, -1, 0, 1};
int dy[] = {1, 0, -1, 0};
- 出口:由于我们每次放置的元素是从1开始递增1的,那么可以推导得到最后放置的元素是 n * n,那么我们便借此为终止条件,当放置的元素 >
n * n的时候,即为终止!
实现代码:
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
int d = 1; //d 和 dx dy必须打好配合!想想为什么d=1,和dx、dy为什么要如此规定
vector<vector<int>> res (n, vector<int>(n, 0));
int m = n * n; //最终的元素!
int cnt = 1;
int x=0, y=0;
while (cnt <= m) // 放置出口!
{
res[x][y] = cnt ++;
int a = dx[d] + x, b = dy[d] + y;
if (a < 0 || b < 0 || a >= n || b >= n || res[a][b])
{
d = (d+1) % 4; //改变方向!
x = x + dx[d];
y = y + dy[d];
}
else {
x = a;
y = b;
}
}
return res;
}
};
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>>res(n, vector<int>(n, 0)); //答案数组!
int m = n*n;
int x=0, y=0, d=1; //起始坐标为 (0, 0)两点!
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
for (int i=1; i <= m; i ++) //依次放置1~m这m个数!
{
res[x][y] = i; //放置i这个数!
int a = dx[d] + x, b = dy[d] + y;
if (a < 0 || a >= n || b < 0 || b >= n || res[a][b])
{
d = (d+1) % 4;
a = dx[d] + x, b = dy[d] + y;
}
x = a, y = b;
}
return res;
}
};
找规律:别人的
- 若n为奇数的话,则生成的螺旋矩阵中,其中心格子必然未处理,且是最后一个处理的格子,所以只有当除该中心格子外的格子填补完后,最后单独填补该格子。
- 若n为偶数的话,则不会产生中间的格子,而是完整的 n/2 圈。反之亦然,奇数情况下,所需要填补的圈数也是 n / 2 圈,只不过默认向下取整,最后再单独填补中心格子。何为一圈:如下图所示:
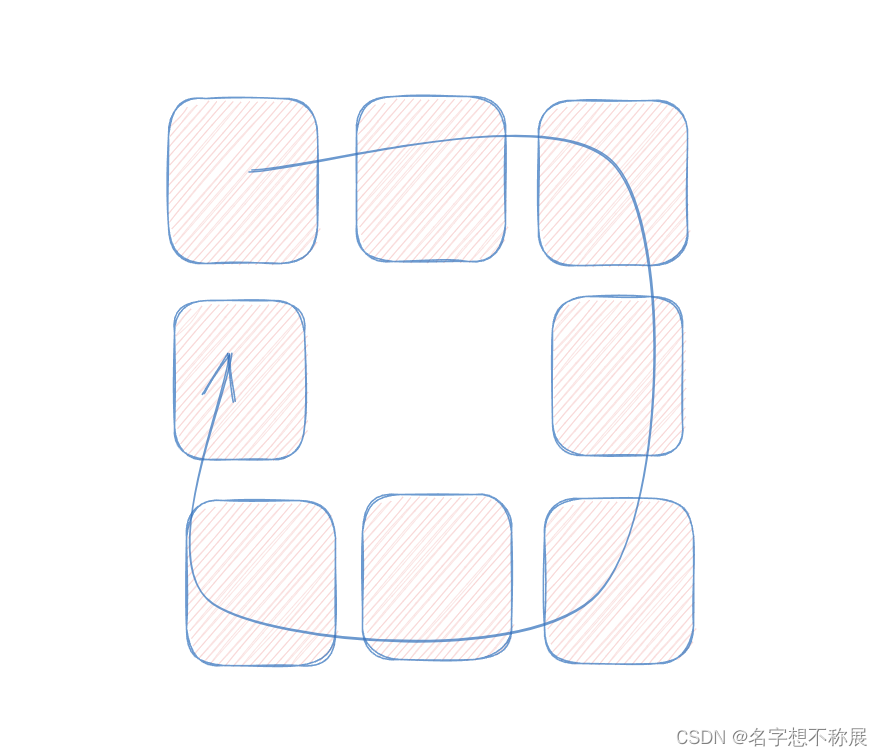
- 所以首先要计算所需要的圈数。若是奇数的话,还应该计算中间格子的坐标,即为:(n/2, n/2);
- 然后不难发现当有多圈的时候,多圈的填补其实是独立的,但规律是通用的!即都是从左上角开始的!所以说循环 n / 2圈,每次找准每圈的左上角即可!
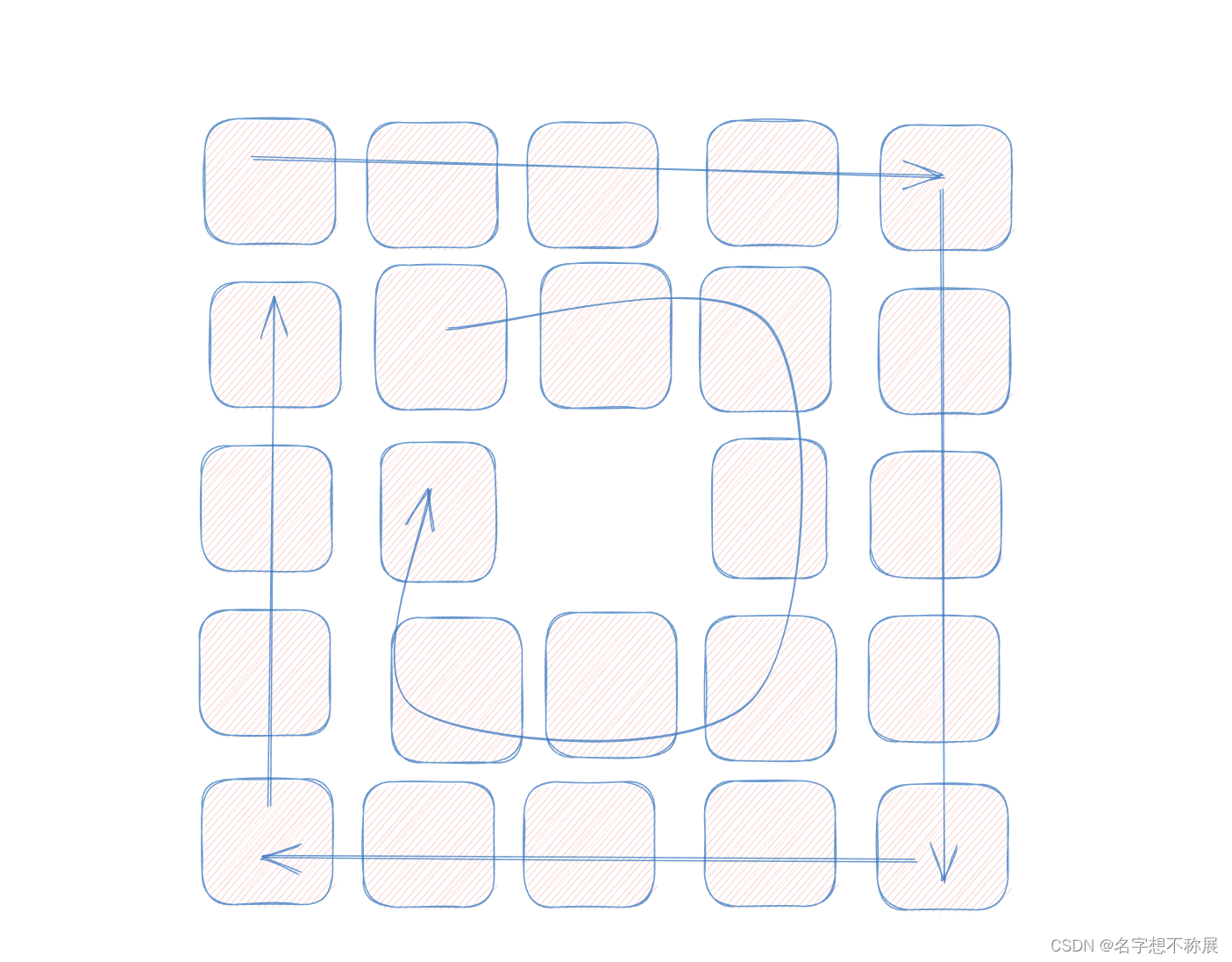
- 我们按边来进行填补,对于每条边的填补,都必须规定一样,因为填补的操作是同样的规律。我们采取左闭右开进行填补每条边,即每条边的起点要填补,但是不填补这条边的终点,终点是下一条边的起点,再填补!最后必然可以完好无损地填补完成。
- 维护左闭右开的填补方式:引入一个变量 offset,每条边的长度均为n,那么在最外圈的时候,offset = 1,当填补的时候,若直接从起点循环到 n的话,则会填补终点,若是循环到 n - offset 的话,则会避开终点。为什么不直接设置 n - 1呢?而要弄成一个变量 offset 呢?还有次外圈啊,当你循环次外圈的时候,若还是 n - 1的话,则会使得次外圈的边,的终点,被填补,所以说明:offset 这个变量值应该随着圈数的递减而递增!
实现代码:
class Solution {
public:
vector<vector<int>> generateMatrix(int n) {
vector<vector<int>> res(n, vector<int>(n, 0));
int stx = 0, sty = 0;
int cnt=1;
int loop = n / 2; //圈数
int mid = n/2; //矩阵的中间位置,针对奇数矩阵而言
int offset = 1; //左闭右开,使得每条边的最右边的那个点
int i, j;
while (loop --)
{
i = stx;
j = sty;
//上行从左往右:
for ( ; j < n - offset; j ++) {
res[stx][j] = cnt ++;
}
//右列从上往下:
for ( ; i < n-offset; i ++) {
res[i][j] = cnt ++;
}
//下行从右往左:
for ( ; j > sty; j --) {
res[i][j] = cnt ++;
}
//左列从下往上:
for ( ; i > stx; i --) {
res[i][j] = cnt ++;
}
//找准下一圈的左上角的坐标,实际上就是找到对角线的点!
// 第二圈开始的时候,起始位置要各自加1, 例如:第一圈起始位置是(0, 0),第二圈起始位置是(1, 1)
stx ++;
sty ++;
// offset 控制每一圈里每一条边遍历的长度
offset ++;
}
if (n % 2 != 0) {
res[mid][mid] = cnt;
}
return res;
}
};
遇见的问题:
多注意细节!
找规律!
vector<vector<int>> res (n, vector<int>(n, 0));
这行代码是在 C++ 中声明和初始化一个二维向量(实际上是一个矩阵)。
vector<vector> res 是声明一个向量,其中每个元素也是一个向量,该元素向量的数据类型是整型(int)。
(n, vector(n, 0)) 是初始化这个二维向量。这里,n 是二维向量的行数和列数,vector(n, 0) 是声明并初始化一个大小为 n 的向量,其中每个元素的初始值都是 0。
因此,vector<vector> res (n, vector(n, 0)); 的意思是声明并初始化一个 nxn 的二维向量,其中每个元素的初始值都是 0。
(n, vector(n, 0):n行,每行都是一个大小为n的初值为0的vector向量!
//d 和 dx dy必须打好配合!想想为什么d=1,和dx、dy为什么要如此规定
题目总结:
多画图,规律题!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









