






DeepSeek-R1:通过强化学习增强大语言模型推理能力的完整解析

目录
- 研究背景与核心贡献
- 方法详解
- DeepSeek-R1-Zero:纯强化学习的突破
- DeepSeek-R1:多阶段训练的优化路径
- 知识蒸馏:小模型的逆袭
- 公式解析与背景知识
- GRPO算法详解
- 关键数学概念补充
- 实验结果与指标解读
- 创新点与局限性
- 反思:小白读者的十大疑问
- 总结与未来展望

一、研究背景与核心贡献
1.1 研究背景
近年来,大型语言模型(LLMs)在推理任务(如数学、编程、科学问题)上的表现持续提升,但传统方法通常依赖监督微调(SFT)和大规模标注数据。然而,SFT存在标注成本高、泛化能力受限等问题。为此,DeepSeek团队提出了一种基于强化学习(Reinforcement Learning, RL)的新范式,通过模型的“自进化”提升推理能力。
1.2 核心贡献
-
DeepSeek-R1-Zero
- 无需监督数据:首次通过纯RL训练提升推理能力,模型自主发展出反思、验证等行为。
- 奖励设计:结合准确性奖励(答案正确性)和格式奖励(输出结构规范)。
-
DeepSeek-R1
- 冷启动与多阶段训练:通过少量高质量数据初始化模型,结合RL和SFT优化性能与可读性。
- 全场景对齐:引入语言一致性奖励,解决语言混合问题。
-
知识蒸馏
- 经济高效:将大模型的推理能力迁移到小模型,性能超越直接RL训练的同规模模型。
-
算法创新
- GRPO(Group Relative Policy Optimization):改进的RL算法,降低训练成本。
二、方法详解
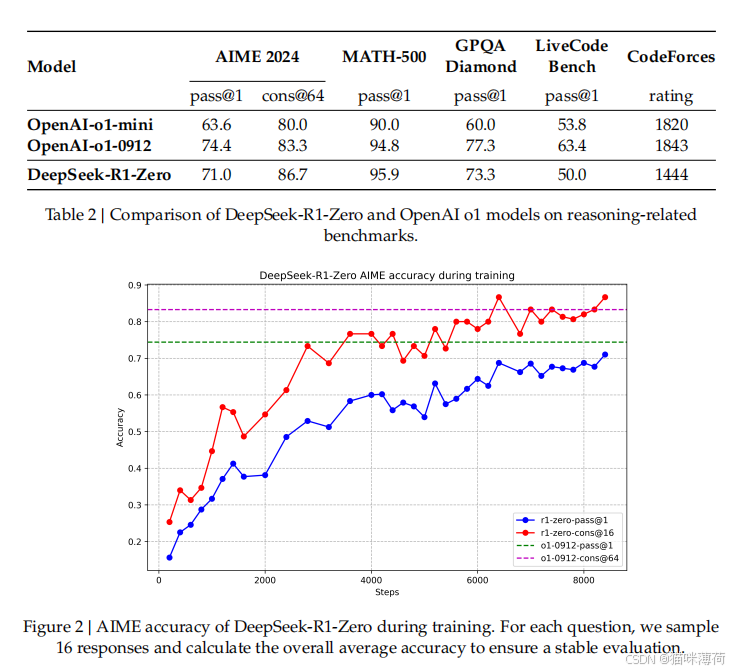
2.1 DeepSeek-R1-Zero:纯强化学习的突破
训练流程
- 基础模型:使用DeepSeek-V3-Base作为起点。
- 奖励设计:
- 准确性奖励:基于规则判断答案正确性(如数学问题验证)。
- 格式奖励:强制模型在
<think>和<answer>标签内输出。
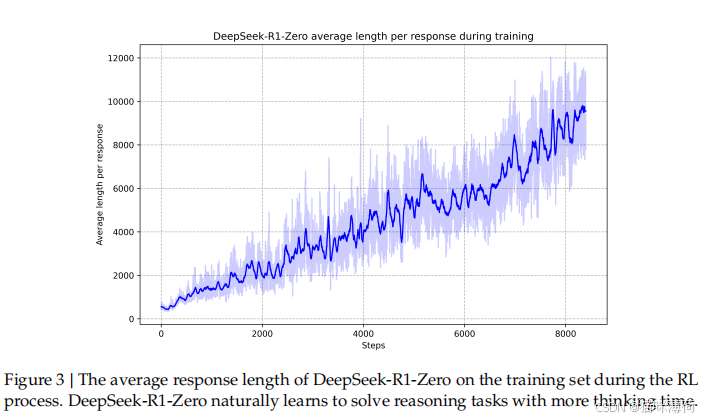
- 自进化过程:模型通过RL自主学习生成长链式思考(CoT),逐步提升复杂问题解决能力。
示例模板
用户:解方程 $\sqrt{a - \sqrt{a + x}} = x$
助手:<think>
首先平方两边:$a - \sqrt{a + x} = x^2$ → $\sqrt{a + x} = a - x^2$
再次平方:$a + x = (a - x^2)^2$ → 展开整理得到四次方程...
</think>
<answer>解的和为$\boxed{0}$</answer>
2.2 DeepSeek-R1:多阶段训练的优化路径
冷启动(Cold Start)
- 问题:DeepSeek-R1-Zero输出可读性差,语言混合严重。
- 解决方案:
- 收集数千条高质量CoT数据(包含详细步骤和总结)。
- 使用模板
|special_token| <reasoning_process> |special_token| <summary>规范输出。
四阶段训练
- 冷启动微调:初步提升模型的可读性。
- 推理导向RL:优化数学、编程等任务的性能。
- 拒绝采样与SFT:结合RL生成的数据和其他领域数据(写作、问答)进行微调。
- 全场景RL:引入帮助性和无害性奖励,全面对齐人类偏好。
2.3 知识蒸馏:小模型的逆袭
蒸馏流程
- 数据生成:使用DeepSeek-R1生成80万条高质量CoT数据。
- 监督微调:直接对Qwen、Llama等小模型进行训练。
效果对比
| 模型 | AIME 2024 (pass@1) | 参数量 |
|---|---|---|
| QwQ-32B-Preview | 50.0% | 32B |
| DeepSeek-R1-Distill-32B | 72.6% | 32B |
结论:蒸馏模型的性能显著优于直接RL训练的同规模模型。
三、公式解析与背景知识
3.1 GRPO算法详解
目标函数(公式1)
J GRPO ( θ ) = E [ 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , 1 − ε , 1 + ε ) A i ) − β D KL ( π θ ∥ π ref ) ) ] \mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E} \left[ \frac{1}{G} \sum_{i=1}^{G} \left( \min \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} A_i, \text{clip} \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}, 1-\varepsilon, 1+\varepsilon \right) A_i \right) - \beta \mathbb{D}_{\text{KL}} (\pi_{\theta} \parallel \pi_{\text{ref}}) \right) \right] JGRPO(θ)=E[G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∥πref))]
符号解释
- G G G:每组采样的输出数量(例如G=8)。
- π θ \pi_{\theta} πθ:待优化的当前策略。
- π θ old \pi_{\theta_{\text{old}}} πθold:旧策略(用于采样)。
- A i A_i Ai:优势函数(见公式3)。
- ε \varepsilon ε:剪切范围(防止策略突变,通常设为0.2)。
- β \beta β:KL散度惩罚项的权重。
-
D
KL
\mathbb{D}_{\text{KL}}
DKL:KL散度,约束策略与参考策略
π
ref
\pi_{\text{ref}}
πref的偏离。
优势函数(公式3)
A i = r i − mean ( { r 1 , r 2 , … , r G } ) std ( { r 1 , r 2 , … , r G } ) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \ldots, r_G\})}{\text{std}(\{r_1, r_2, \ldots, r_G\})} Ai=std({r1,r2,…,rG})ri−mean({r1,r2,…,rG})
- 归一化优势:通过组内奖励的均值和标准差调整,避免绝对值过大导致训练不稳定。
3.2 关键背景知识补充
KL散度(Kullback-Leibler Divergence)
- 定义:衡量两个概率分布
P
P
P和
Q
Q
Q的差异:
D KL ( P ∥ Q ) = ∑ x P ( x ) log P ( x ) Q ( x ) \mathbb{D}_{\text{KL}}(P \parallel Q) = \sum_x P(x) \log \frac{P(x)}{Q(x)} DKL(P∥Q)=x∑P(x)logQ(x)P(x) - 在RL中的作用:防止策略更新过快,保持与参考策略的相似性(如初始策略或人类偏好)。
剪切(Clipping)
- 目的:限制策略更新的幅度,避免因单次更新过大导致模型崩溃。
- 操作:将策略比率 π θ π θ old \frac{\pi_{\theta}}{\pi_{\theta_{\text{old}}}} πθoldπθ限制在 [ 1 − ε , 1 + ε ] [1-\varepsilon, 1+\varepsilon] [1−ε,1+ε]区间内。
四、实验结果与指标解读
4.1 关键指标
- pass@1:单次采样的正确率(反映模型单次生成的质量)。
- cons@64:64次采样中通过多数投票达成共识的正确率(反映模型稳定性)。
- Elo评分:编程竞赛平台Codeforces的排名指标,分数越高表示模型表现越接近人类顶尖选手。
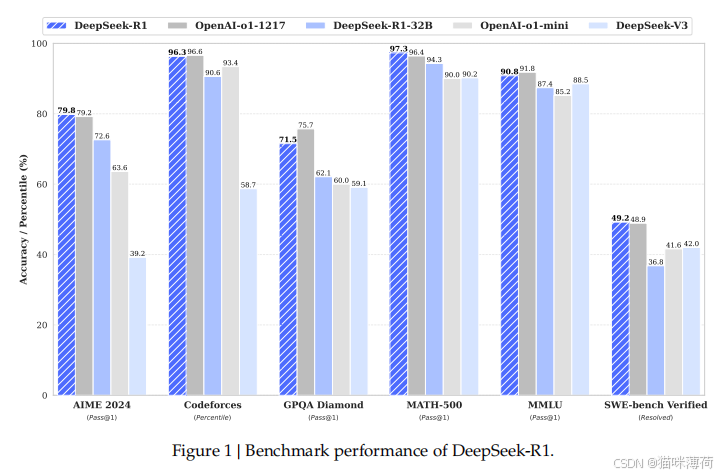
4.2 性能对比
| 模型 | AIME 2024 (pass@1) | MATH-500 (pass@1) | Codeforces Rating |
|---|---|---|---|
| DeepSeek-R1 | 79.8% | 97.3% | 2029(超越96.3%人类) |
| OpenAI-o1-1217 | 79.2% | 96.4% | 2061 |
| GPT-4o | 9.3% | 74.6% | 759 |
五、创新点与局限性
5.1 创新点
- 纯RL训练的可行性验证:首次证明无需监督数据,仅通过RL即可显著提升推理能力。
- 多阶段训练的通用性:冷启动数据 + RL + SFT的组合为行业提供高效框架。
- 经济高效的蒸馏技术:小模型通过蒸馏接近大模型性能,降低部署成本。
5.2 局限性
- 通用能力不足:在函数调用、多轮对话等任务上表现较弱。
- 语言混合问题:对非中英文查询可能混合语言。
- 工程任务优化:需结合异步评估提升训练效率。
六、反思:小白读者的十大疑问
1. 什么是强化学习(RL)?与传统监督学习有何不同?
- 答:RL通过试错和奖励机制学习策略,而非依赖标注数据。例如,模型通过生成答案并获得奖励反馈来优化自身。
2. GRPO算法中的“分组”有什么作用?
- 答:分组计算优势函数可减少对独立Critic模型的依赖,降低计算成本。
3. KL散度为什么要作为惩罚项?
- 答:防止策略更新偏离参考策略太远,保持训练稳定性。
4. 冷启动数据是如何收集的?
- 答:通过少量人工标注或模型生成(如DeepSeek-R1-Zero的输出)并进行后处理。
5. 为什么蒸馏模型比直接RL训练的小模型更好?
- 答:大模型已探索更优的推理模式,蒸馏可直接继承这些模式,而小模型自身RL可能陷入局部最优。
6. 公式中的剪切(clip)是如何工作的?
- 答:将策略更新幅度限制在 [ 1 − ε , 1 + ε ] [1-\varepsilon, 1+\varepsilon] [1−ε,1+ε]之间,防止单次更新过大破坏模型。
7. “自进化过程”具体指什么?
- 答:模型通过RL自主发展出反思、验证等复杂行为,无需人工干预。
8. Elo评分如何反映模型性能?
- 答:Elo评分基于模型在编程竞赛中解决问题的难度和正确率,分数越高表示竞争力越强。
9. 语言混合问题如何解决?
- 答:引入语言一致性奖励,强制模型在特定语言环境下生成内容。
10. 未来如何提升工程任务的表现?
- 答:增加软件工程相关的RL数据,或采用异步评估加速训练。
七、总结与未来展望
DeepSeek-R1系列模型通过强化学习和知识蒸馏,在推理任务上达到了行业领先水平。其核心创新在于:
- 纯RL训练验证了自进化推理的可能性;
- 多阶段训练平衡了性能与可读性;
- 蒸馏技术为小模型的高效部署提供了新思路。
未来,结合更复杂的任务场景和算法优化(如异步RL、多模态输入),DeepSeek-R1有望进一步推动AGI的发展。
参考文献与资源
- 论文地址:DeepSeek-R1 Paper
- 开源代码:DeepSeek-R1 GitHub
- 强化学习入门:OpenAI Spinning Up
(全文完)

















 3610
3610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









