







目录
五、PyTorch分布式训练架构图(ASCII版+详细说明)
7.3 动态通信压缩(梯度稀疏/量化,需第三方库如FairScale)
获取源码?私信?关注?点赞?收藏? 👍+✏️+⭐️+🙇———————————————
引言:AI大模型时代下的分布式新挑战
2024年以来,大语言模型(LLM)、多模态模型(VLM)、超大规模图神经网络(GNN)等持续爆发,将分布式训练推向前所未有的技术高地。GPU算力虽已指数级提升,但超百亿乃至万亿级参数模型的训练和推理,对单机极限、通信架构、调度弹性提出了新挑战。如何用PyTorch高效、稳定、可扩展地解决大规模分布式训练的瓶颈,成为业界关注焦点。
一、PyTorch分布式训练核心创新机制详解
1.1 DDP通信并发与自动依赖处理
DDP的“通信-计算重叠”机制
PyTorch DDP的核心亮点在于通信与计算的自动重叠。在反向传播时,每个参数梯度计算完毕即异步发起All-Reduce,而不是等待所有参数都ready。这一机制基于autograd计算图的钩子注册和调度,极大提升了带宽利用率与整体吞吐。
- 创新点:极细粒度的“参数就绪即通信”,而非粗粒度的“全部就绪后一次性同步”,减少等待与阻塞。
- 实际效果:复杂模型如ViT、BERT大大缩短通信开销,训练速度提升20%-30%。
动态Bucket策略
PyTorch支持动态Bucket机制,将小参数自动合并,减少All-Reduce调用次数,进一步优化网络利用率。Bucket大小可根据带宽、模型结构、GPU数量自适应调整。
- 创新点:自适应bucket划分,兼顾通信批量和并发度,避免小梯度频繁同步导致的带宽浪费。
- 工程落地:高带宽环境可适当放大bucket,低带宽/丢包场景适当缩小。
1.2 弹性分布式与断点恢复
Elastic Training机制
PyTorch Elastic框架(torch.distributed.elastic)支持节点动态增减、Worker自动故障恢复,无需用户干预即可保持训练进度。适用于云原生集群、异构资源池等弹性资源环境,是大模型训练的“保险带”。
- 创新点:节点“热插拔”和“冷恢复”,极大提升训练稳定性和资源利用效率。
- 典型场景:Kubernetes/Slurm等调度器下,支持作业自动迁移和弹性扩缩。
断点一致性恢复
PyTorch新版本支持分布式状态一致性的断点恢复,包括模型权重、优化器状态、分布式通信上下文等。保证异常中断后精准续训,无精度损失。
二、分布式训练的创新工程实践
2.1 “深浅混合”并行:数据、模型、管道分层协同
2.1.1 张量并行与流水线并行
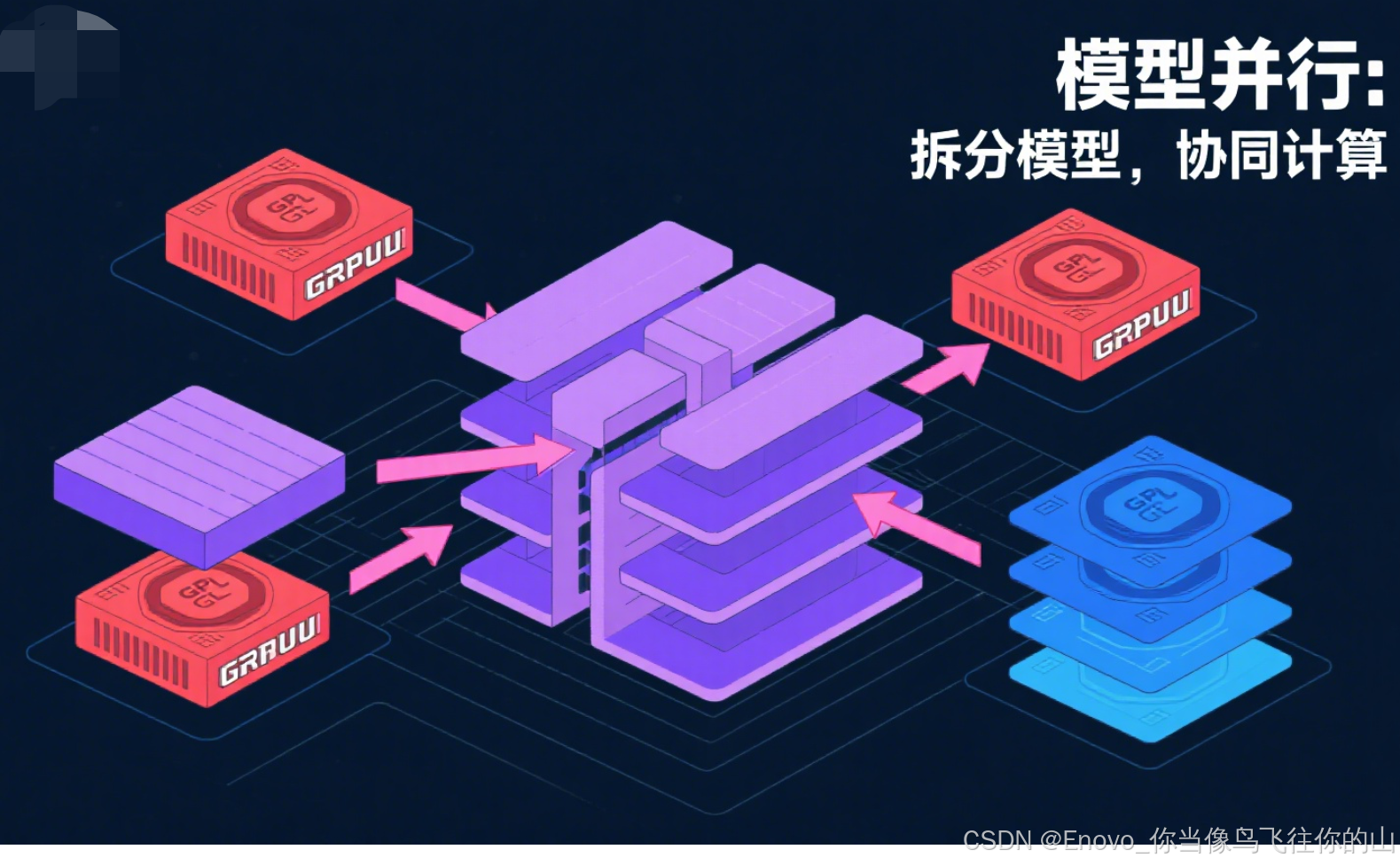
- 张量并行(Tensor Parallelism):将单个层的权重/激活划分到多卡,跨GPU并行操作,是突破超大模型单卡极限的利器。
- 流水线并行(Pipeline Parallelism):将模型分为多个stage,每个stage独立在一组GPU上,前向/反向以微型batch流动,实现流水线调度。
PyTorch社区项目如Megatron-LM、DeepSpeed、Colossal-AI均已支持。结合DDP实现深浅混合并行,兼顾模型超大与训练高效。
2.1.2 创新点
- 跨层异步调度:流水线并行+数据并行下,利用虚拟分组和异步调度,最大化GPU利用率。
- 显存复用:梯度检查点(Gradient Checkpointing)等技术,减少激活保存,支持更大批量。
2.2 非均匀集群与异构硬件调度
传统分布式假设节点、GPU均为同构,但现实环境往往“非均匀”——GPU型号、算力、带宽不一。PyTorch创新支持:
- Adaptive Load Balancing:根据算力动态分配数据/模型任务,避免慢节点拖垮整体进度。
- Shard-Aware调度:对模型分片、参数分布动态调整,提高异构环境利用率。
- 异构资源融合:如GPU+TPU、CPU+FPGA混合训练,未来将成为AI基础设施新方向。
2.3 通信压缩与智能同步
通信瓶颈已成为分布式训练极限。前沿优化包括:
- 梯度量化/稀疏同步:对梯度低比特量化、只同步重要参数(Top-k),大幅降低带宽需求。
- 异步通信与智能同步时机:高延迟环境下采用异步或延迟同步(如Local SGD),智能判定同步最佳时机,平衡收敛与吞吐。
2.4 分布式训练的能效优化
大模型训练“烧钱烧电”,绿色AI成刚需。PyTorch社区与业界合作,推动:
- 能耗感知调度:训练过程动态监测能耗,按需调整并行度与通信频率。
- 带宽与显存综合利用:合理分配通信与计算资源,避免低效拉满。
- 动态精度控制:训练早期用低精度(FP8等),收敛后自动切换高精度,兼顾速度与精度。
三、实际案例与创新落地
3.1 千卡级大模型训练案例剖析
以某互联网公司的千亿参数语言模型为例,采用PyTorch混合并行和弹性调度:
- 硬件环境:256台服务器,单机8卡NVLink直连,Infiniband高速网络。
- 并行策略:数据并行x8 + 张量并行x4 + 流水线并行x4,层内外协同。
- 训练优化:
- 动态调整bucket size,分阶段通信压缩;
- 微调阶段采用梯度累积,主干预训练采用混合精度;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1867
1867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











