






目录
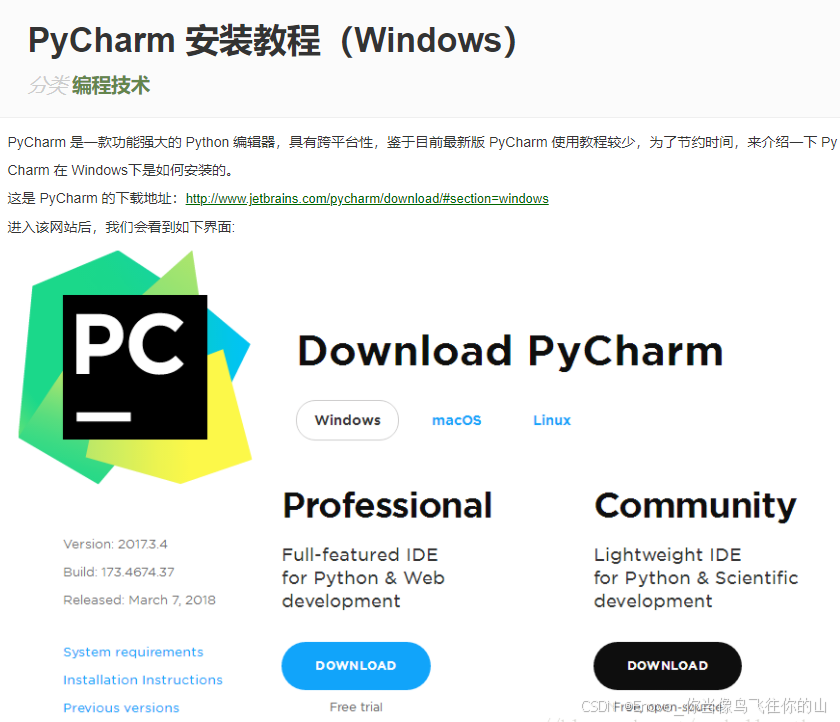
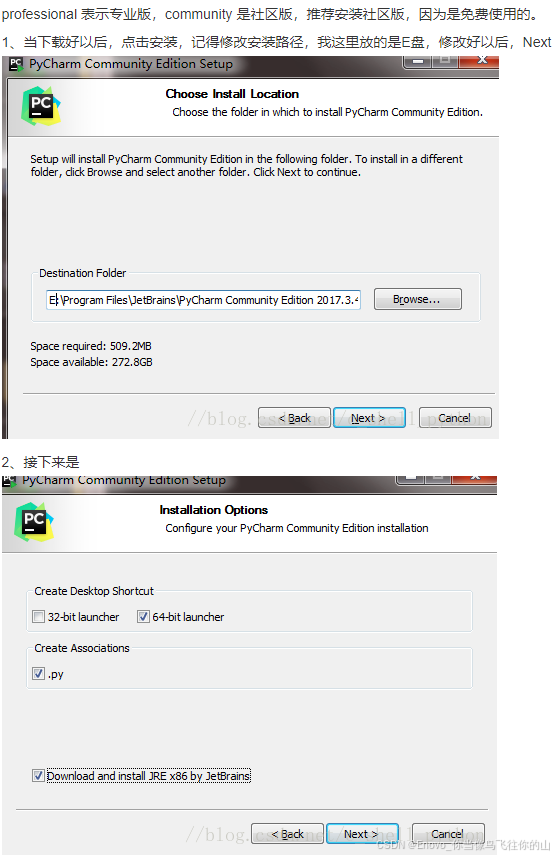
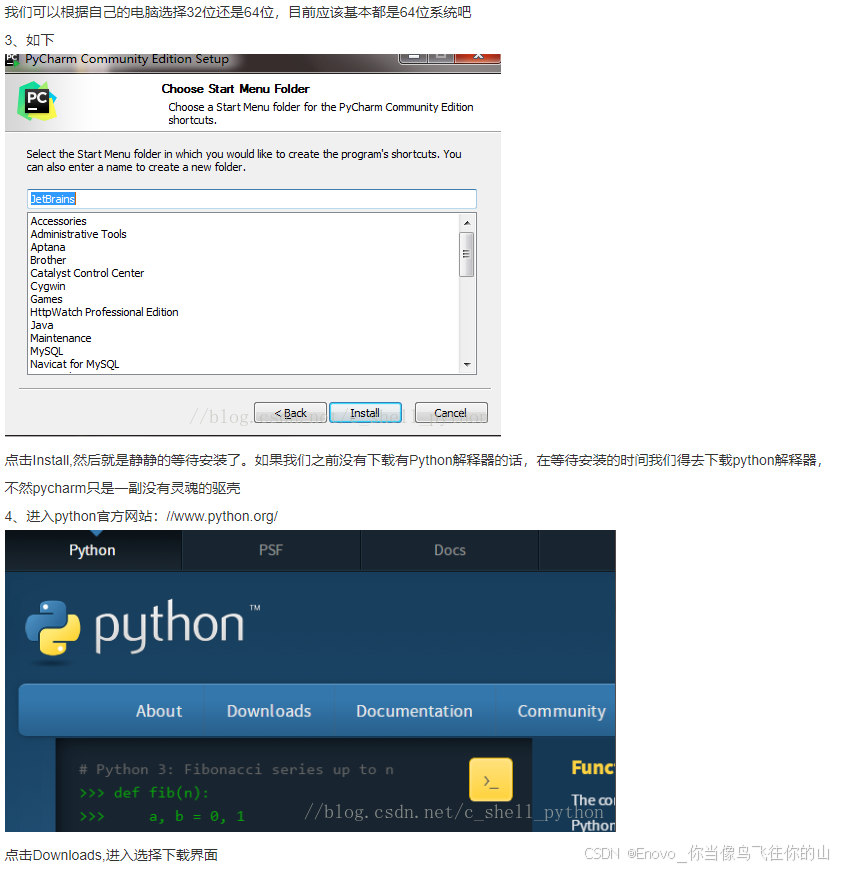
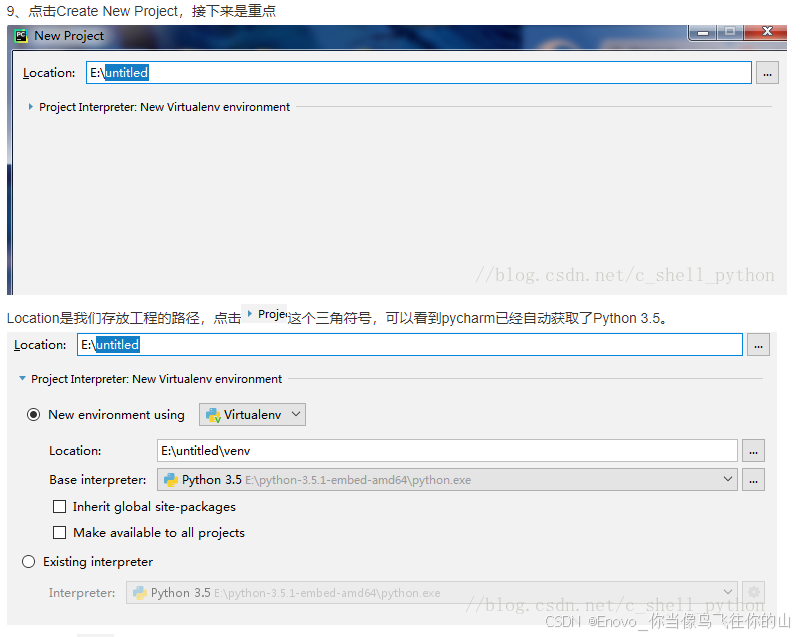
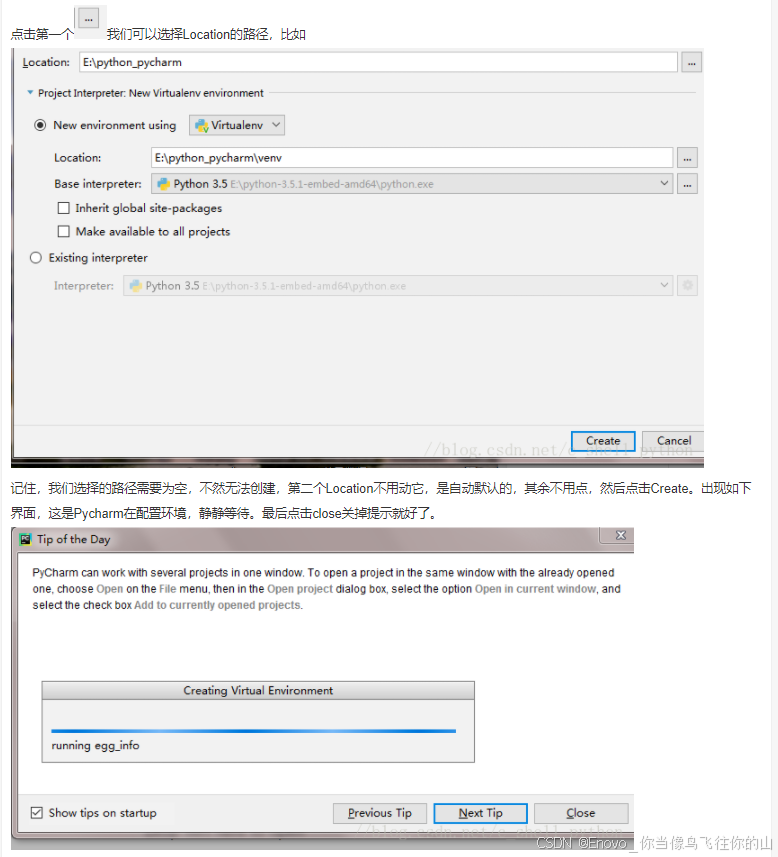
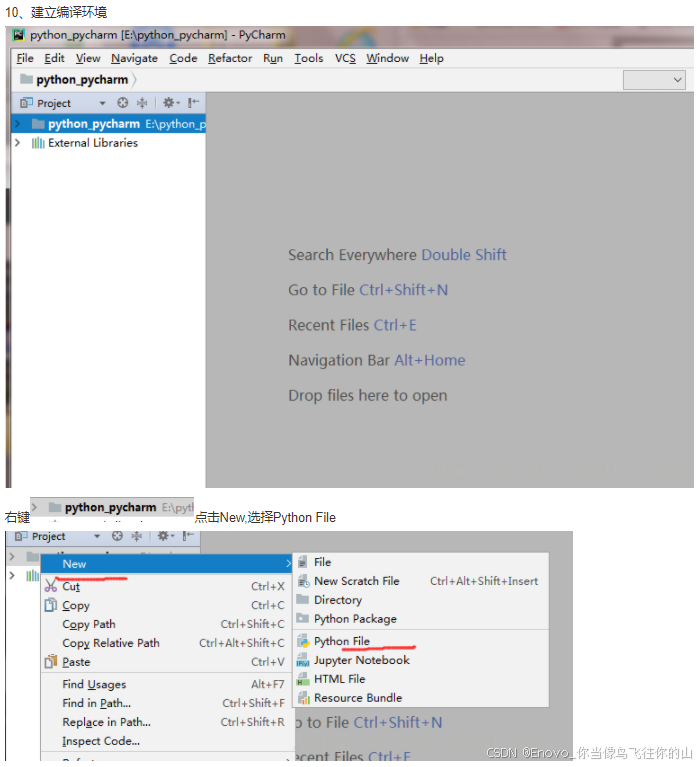
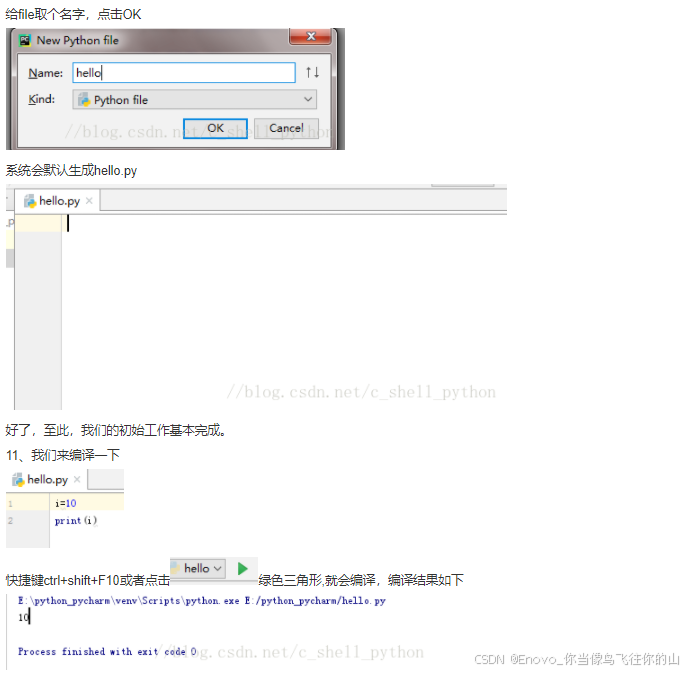
实验一 环境安装,pycharm,jupyter notebook
实验一 环境安装,pycharm,jupyter notebook
实验二 Numpy基本操作
【实验内容】
伴随着我们步入机器学习的大门的脚步声,第一关的Boss出现在我们面前,它给我们带来了一堆杂乱的数据,我们需要对其进行处理,完成下文实验内容,尽快进入下一关!
1、下载安装jupyter notebook。
2、安装Numpy科学计算库。
3、掌握Numpy中的数组创建、切片索引、基本运算。
【实验目的】
1、掌握jupyter notebook的基本使用。
2、掌握numpy相关知识。
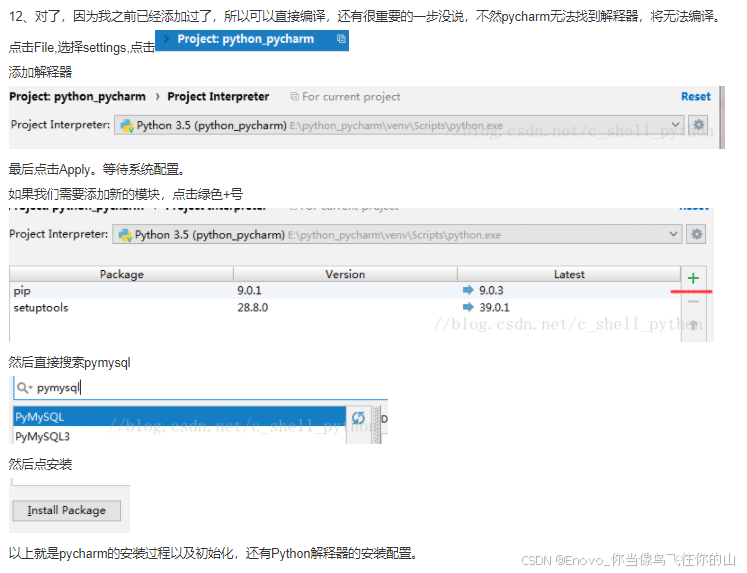
【实验步骤】
步骤1:安装jupyter notebook。
步骤2:安装numpy。
步骤3:使用numpy创建数组。
步骤4:掌握numpy切片操作。
步骤1:安装jupyter notebook。
注意1:请直接按默认路径创建项目,后续所需数据已经配置完成。
注意2:本系统已经装配好后续实验所需环境,您可以直接使用,请大展身手吧!
#在终端输入。
pip install notebook
#如果速度较慢可以挂载镜像源,如下:
pip install notebook -i http://pypi.mirrors.ustc.edu.cn/simple/
#测试使用jupyter notebook ,直接在终端输入,空格隔开。
Jupyter noteook进入jupyter notebook后我们可以创建一个ipynb文件,如下图:
步骤2:安装numpy。
#方法一,直接在终端输入。
pip install numpy
#方法二,在jupyter notebook中输入。
!pip install numpy准备工作已经做完下面就可以写代码了!
步骤3:使用numpy创建数组。
#导入numpy,通常我们把它重命名为np使用。
import numpy as np
#创建一维数组。
np.array([1,2,3])
import numpy as np
print(np.array([1,2,3]))输出:array([1, 2, 3])
#创建一个3*3的数组,并定义其数据类型为float32。
a = np.array([
[1,2,3],
[4,5,6],
[7,8,9],
],dtype=np.float32)
a输出:array([[1., 2., 3.]
[4., 5., 6.],
[7., 8., 9.], dtype=float32])
#查看创建的数组的维度、形状、尺寸、类型。
print('数组a的维度为:',a.ndim)
print('数组a的形状为:',a.shape)
print('数组a的尺寸为:',a.size)
print('数组a的类型为:',a.dtype)输出: 数组a的维度为: 2
数组a的形状为: (1, 3)
数组a的尺寸为: 3
数组a的类型为: float32
#创建全0和全1数组,其中shape可以指定其形状(行,列)。
np.zeros(shape=(2,4))输出:array([[0., 0., 0., 0.]
[0., 0., 0., 0.]])
np.ones(shape=(4,2))输出:array([[1., 1.]
[1., 1.],
[1., 1.],
[1., 1.]])
#创建连续值的数组,前者表示[1,9),后者表示在前者的基础上隔2个数取一位。
np.arange(1,9)输出:array([1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(1,9,2)输出:array([1, 3, 5, 7])
#创建随机数。
np.random.rand(2,2)输出:array([[0.6590129 , 0.68697198],
[0.1630133 , 0.59577548]])
np.random.randint(-100,100,size=(2,2))输出:array([[ 50, -100],
[ 83, 47]])
步骤4:掌握numpy切片操作。
#切片是以索引来拆分,在列表中索引都是以0开始计算,倘若冒号左右没有值则代表到边界位。
a = np.arange(1,11)
print('a为: ', a)
print('a[-3:]为: ', a[-3:]) #取出最后3位
print('a[2:6]为: ', a[2:6])输出:a为: [ 1 2 3 4 5 6 7 8 9 10]
a[-3:]为: [ 8 9 10]
a[2:6]为: [3 4 5 6]
#隔一定的步长取值。
print(a[:2])
print(a[::2]) #每隔2个数开始取值。输出:[1 2]
[1 3 5 7 9]
#多维数组中的切片操作。
a = np.array([
[1,2,3,4],
[5,6,7,8],
[9,0,1,2],
])
a输出:array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 0, 1, 2]])
a[:,:-1] #取出前3列数据。输出:array([[1, 2, 3],
[5, 6, 7],
[9, 0, 1]])
a[1,1] #取出位于(1,1)位置的数。输出:6
实验三 numpy的广播机制和常用函数
【实验内容】
掌握Numpy中的数组创建、切片索引、广播机制、基本运算、函数使用。
【实验目的】
1、掌握jupyter notebook的基本使用。
2、掌握numpy相关知识。
【实验步骤】
步骤5:掌握numpy广播机制。
步骤6:掌握numpy常用函数。
步骤5:掌握numpy广播机制。
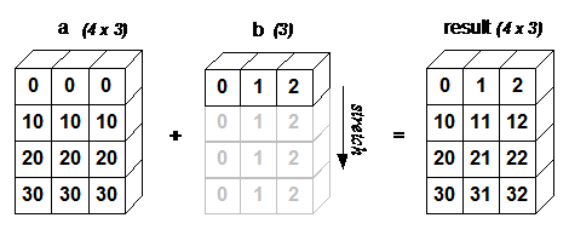
广播(Broadcast)是numpy对不同形状(shape)的数组进行数值计算的方式,对数组的算术运算通常在相应的元素上进行。如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长。
#同纬度的a和b相加。
a = np.array([[ 0, 0, 0],
[10,10,10],
[20,20,20],
[30,30,30]])
b = np.array([[0,1,2],
[0,1,2],
[0,1,2],
[0,1,2]])
print(a + b)输出:[[ 0 1 2]
[10 11 12]
[20 21 22]
[30 31 32]]
#不同维度的a和b相加。
a = np.array([[ 0, 0, 0],
[10,10,10],
[20,20,20],
[30,30,30]])
b = np.array([0,1,2])
print(a + b)输出:[[ 0 1 2]
[10 11 12]
[20 21 22]
[30 31 32]]
其计算过程如下:
步骤6:掌握numpy常用函数。
#大小写转换函数。
print(np.char.title('wei zhong')) #字符串的第一个单词大写。
print(np.char.lower('WEI ZHONG')) #每个元素都转换为小写。
print(np.char.upper('wei zhong')) #每个元素都转换为大写。输出:Wei Zhong
weizhong
WEI ZHONG
#正弦、余弦、正切运算(sin()、cos()、tan())。
a = np.array([0,30,45,60,90])
print ('各角度的正弦值:', np.sin(a*np.pi/180)) #np.pi/180 是转化为弧度。
print ('各角度的余弦值:', np.cos(a*np.pi/180))
print ('各角度的正切值:', np.tan(a*np.pi/180))输出:各角度的正弦值: [0. 0.5 0.70710678 0.8660254 1. ]
各角度的余弦值: [1.00000000e+00 8.66025404e-01 7.07106781e-01 5.00000000e-01
6.12323400e-17]
各角度的正切值: [0.00000000e+00 5.77350269e-01 1.00000000e+00 1.73205081e+00
1.63312394e+16]
#数组间的加减乘除。
a = np.arange(4).reshape(2,2) #定义一个3*3的数组 。
print ('第一个数组:n', a)
b = np.array([1, 2])
print ('第二个数组:n', b)
print ('两个数组相加:n', np.add(a,b))
print ('两个数组相减:n', np.subtract(a,b))
print ('两个数组相乘:n', np.multiply(a,b))
print ('两个数组相除:n', np.divide(a,b))输出:第一个数组:
[[0 1]
[2 3]]
第二个数组:
[1 2]
两个数组相加:
[[1 3]
[3 5]]
两个数组相减:
[[-1 -1]
[ 1 1]]
两个数组相乘:
[[0 2]
[2 6]]
两个数组相除:
[[0. 0.5]
[2. 1.5]]
#计算数组的均值、最大值、最小值、标准差。
a = np.arange(9).reshape(3,3)
print(a)
print('数组的均值为',a.mean())
print('数组的最大值为', a.max())
print('数组的最小值为', a.min())
print('数组的标准差为', a.std())输出:
[[0 1 2]
[3 4 5]
[6 7 8]]
数组的均值为 4.0
数组的最大值为 8
数组的最小值为 0
数组的标准差为 2.581988897471611
实验四 matplotlib正弦曲线绘制
一、实验目的
1. 了解matplotlib库的基本功能
2. 掌握matplotlib库的使用方法
二、实验工具:
1. Anaconda
2. Numpy,matplotlib
三、Matplotlib简介
Matplotlib 包含了几十个不同的模块, 如 matlab、mathtext、finance、dates 等,而 pylot 则是我们最常用的绘图模块
四、实验内容
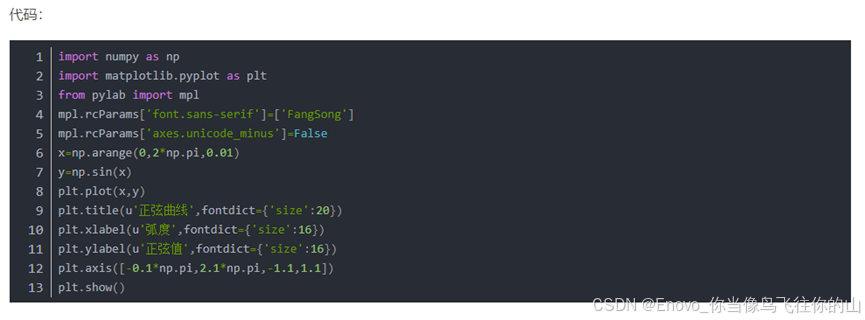
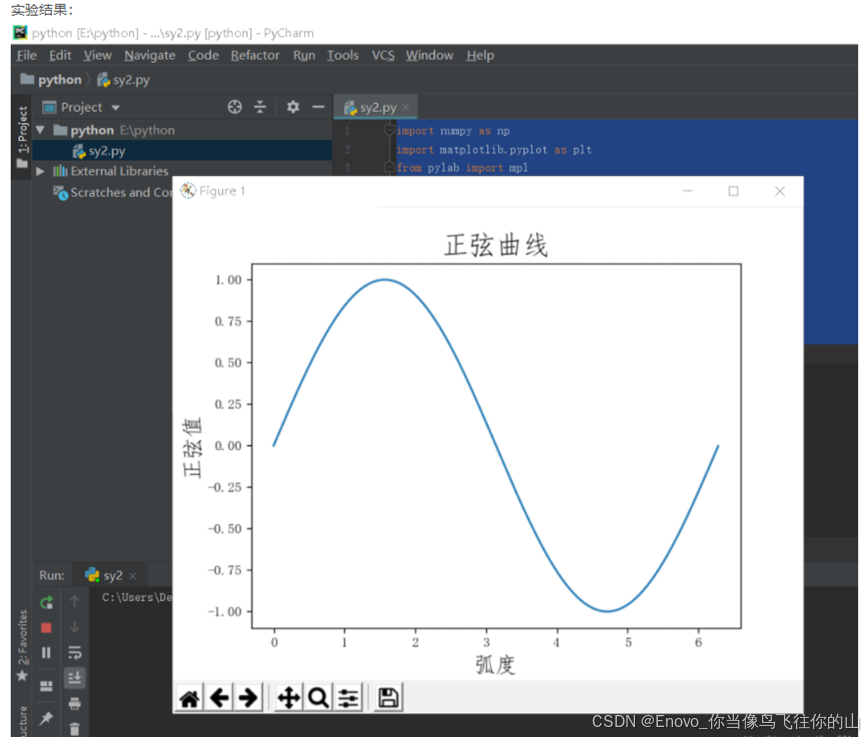
1.绘制正弦曲线,并设置标题、坐标轴名称、坐标轴范围
实验五 matplotlib曲线绘图
一、实验目的
1. 了解matplotlib库的基本功能
2. 掌握matplotlib库的使用方法
二、实验工具:
1. Anaconda
2. Numpy,matplotlib
三 实验内容
同一坐标系中绘制多种曲线并通过样式、宽度、颜色加以区分
代码:
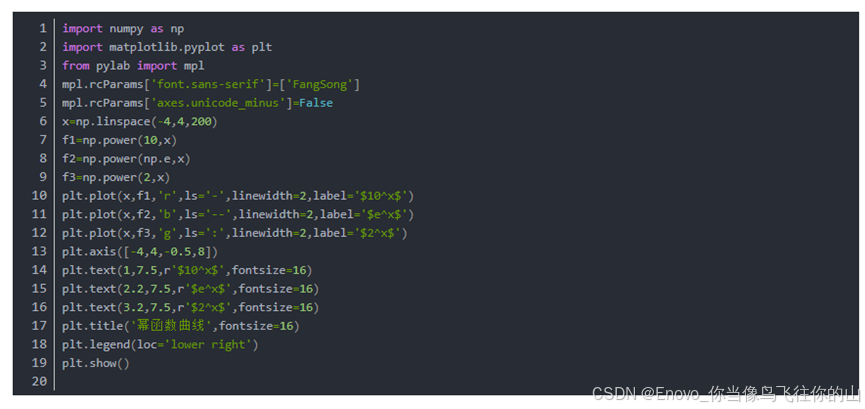
结果
实验六 pandas缺失值分析和异常值处理
缺失值分析
实验内容
- 生成含有缺失值的数据
- 对数据集进行缺失值分析
- 使用删除缺失值的方法处理数据集
代码:
import pandas as pd
import numpy as np
# 生成一个含有缺失值数据的数据集
data = pd.DataFrame({
'name': ['张三', '李四', '王五', 'Bob', np.nan], # 修正np,nan为np.nan
'age': [np.nan, 18, 30, 20, 25],
'id': [1401, 1402, 1403, np.nan, 1405]
})
print("原始数据集:")
print(data)
print("\n" + "-"*50 + "\n")
# 使用isnull()方法查看缺失值
print("缺失值检查(True表示缺失):")
print(data.isnull())
print("\n" + "-"*50 + "\n")
# 使用any()方法查看含有缺失值的列
print("各列是否含有缺失值:")
print(data.isnull().any())
print("\n" + "-"*50 + "\n")
# 使用all()方法查看全部都是缺失值的列
print("各列是否全部为缺失值:")
print(data.isnull().all())
print("\n" + "-"*50 + "\n")
# 处理缺失值 - 删除含有缺失值的行
print("删除缺失值后的数据集:")
print(data.dropna())
异常值处理
实验内容
- 生成含有异常值得数据集
- 对数据进行标准化
- 对数据进行异常值分析
代码:
import pandas as pd
# 生成一个含有异常值的数据集
data = pd.DataFrame({
'name': ['a', 'b', 'c', 'd', 'e', 'f', 'g'],
'cost': [2, 127, 4, 6, 3, 13, 14], # 127是明显的异常值
'sales': [13, 18, 32, 54, 23, 33, 44]
})
print("原始数据集:")
print(data)
print("\n" + "-"*50 + "\n")
# 复制数据以避免修改源数据
data_standardized = data.copy()
# 对cost和sales列进行标准化(Z-score标准化)
for col in ['cost', 'sales']:
mean = data_standardized[col].mean()
std = data_standardized[col].std()
data_standardized[col] = (data_standardized[col] - mean) / std
print("标准化后的数据集(Z-score):")
print(data_standardized)
print("\n" + "-"*50 + "\n")
# 设置阈值(通常使用2或3个标准差),筛选出异常值
threshold = 2
outliers = data[abs(data_standardized['cost']) > threshold]
print(f"cost列中Z-score绝对值大于{threshold}的异常值:")
print(outliers)
print("\n" + "-"*50 + "\n")
# 查看异常值在原始数据中的位置
print("异常值在原始数据中的索引位置:")
print(outliers.index.tolist())
实验七 pandas一致性分析和值分析
一致性分析
实验内容
- 准备三个数据文件,要求有两个文件的内容是完全相同的,第三个是不同的
- 使用第一个文件分别于第二个和第三个文件进行一致性比较
代码:
import hashlib
import os
def calculate_md5(file_path):
"""
计算文件的MD5哈希值
参数:
file_path: 文件的路径
返回:
字符串: 文件的MD5哈希值,如果文件不存在或出错则返回None
"""
# 检查文件是否存在
if not os.path.exists(file_path):
print(f"错误: 文件 '{file_path}' 不存在")
return None
# 检查是否是文件(不是目录)
if not os.path.isfile(file_path):
print(f"错误: '{file_path}' 不是一个文件")
return None
md5 = hashlib.md5()
# 大文件处理:分块读取,避免内存占用过高
with open(file_path, 'rb') as f:
while True:
chunk = f.read(4096) # 每次读取4KB
if not chunk:
break
md5.update(chunk)
return md5.hexdigest()
# 示例用法
if __name__ == "__main__":
test_file = "example.txt"
md5_value = calculate_md5(test_file)
if md5_value:
print(f"文件 '{test_file}' 的MD5值为: {md5_value}")
实验八 值分析
实验内容:
- 生成或打开一个含有重复值,空值,零值得数据集
- 统计重复值,空值,正负值,零值得数量
代码:
import pandas as pd
import matplotlib.pyplot as plt
# 读取训练数据
# 注意:确保train.csv文件在正确的路径下
data = pd.read_csv('train.csv')
def analyze_duplicates(col_name):
"""统计指定列的重复值及其出现次数"""
print(f'\n{col_name}列的重复值以及重复的次数:')
# 使用value_counts()统计值出现的次数
counts = data[col_name].value_counts()
# 筛选出重复出现的值(出现次数>1)
duplicates = counts[counts > 1]
if duplicates.empty:
print(f"{col_name}列没有重复值")
else:
print(duplicates)
def analyze_null_values(col_name):
"""统计指定列的空值个数及占比"""
# 使用isna()和sum()更高效地计算空值
null_count = data[col_name].isna().sum()
total_count = len(data)
null_ratio = null_count / total_count * 100 # 百分比
print(f'\n{col_name}列数据为空的个数: {null_count}')
print(f'{col_name}列空值占比: {null_ratio:.2f}%')
def analyze_number_distribution(col_name):
"""分析数值列的正负值、负值和零值分布"""
# 确保列是数值类型
if not pd.api.types.is_numeric_dtype(data[col_name]):
print(f'\n{col_name}列不是数值类型,无法进行正负值分析')
return
positive = (data[col_name] > 0).sum()
negative = (data[col_name] < 0).sum()
zero = (data[col_name] == 0).sum()
print(f'\n{col_name}列数值分布:')
print(f'正数的个数: {positive}')
print(f'负数的个数: {negative}')
print(f'零值的个数: {zero}')
def analyze_empty_strings(col_name):
"""分析字符串列的空字符串数量"""
# 确保列是字符串类型
if not pd.api.types.is_string_dtype(data[col_name]):
print(f'\n{col_name}列不是字符串类型,无法进行空字符串分析')
return
# 统计空字符串(排除NaN)
empty_str_count = (data[col_name].fillna('') == '').sum()
print(f'\n{col_name}列空字符串个数: {empty_str_count}')
# 示例用法
if __name__ == "__main__":
# 假设数据集中包含以下列,可以根据实际情况修改
numeric_cols = ['Age', 'Fare'] # 示例数值列
string_cols = ['Name', 'Sex', 'Embarked'] # 示例字符串列
# 分析数值列
for col in numeric_cols:
analyze_duplicates(col)
analyze_null_values(col)
analyze_number_distribution(col)
# 分析字符串列
for col in string_cols:
analyze_duplicates(col)
analyze_null_values(col)
analyze_empty_strings(col)
实验九 pandas直方图与频次图、统计分析
直方图与频次图分析
实验内容
- 生成需要的统计数据
- 根据数据源绘制直方图
代码:
import matplotlib.pyplot as plt
import numpy as np
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False # 正确显示负号
# 工资数据
wages = [3000, 2700, 2800, 2100, 5600, 6700, 4200, 3100, 3500,
4100, 5100, 6100, 7600, 7800, 8700, 9800, 10000, 6500, 6000]
# 排序数据
wages.sort()
print("排序后的工资数据:", wages)
# 绘制直方图
plt.figure(figsize=(10, 6)) # 设置图表大小
# 绘制直方图,自动计算合适的分箱数
n, bins, patches = plt.hist(
wages,
bins=8, # 更合理的分箱数
range=(2000, 10000),
histtype='bar',
rwidth=0.9,
color='skyblue',
edgecolor='black'
)
# 添加标题和坐标轴标签
plt.xlabel('工资水平', fontsize=12)
plt.ylabel('人数', fontsize=12)
plt.title('员工工资分布直方图', fontsize=14, pad=20)
# 添加网格线使数据更易读
plt.grid(axis='y', linestyle='--', alpha=0.7)
# 调整布局
plt.tight_layout()
# 显示图形
plt.show()
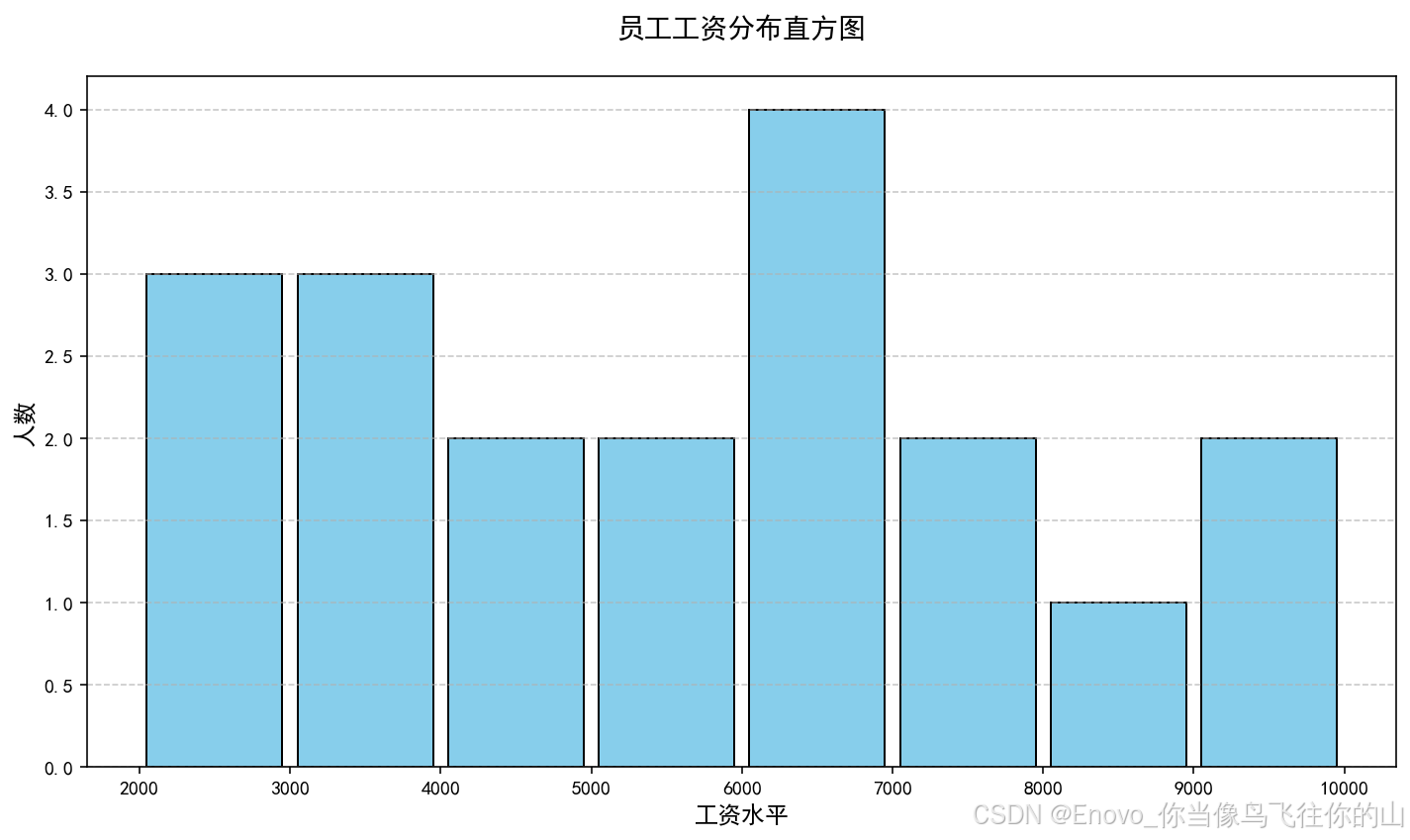
统计分析
实验内容
- 生成三组数据
- 使用计算统计量的多种方法计算出每组数据的各种统计量
代码:
import pandas as pd
importnumpyas np
np.random.seed(1234)
d1 = pd.Series(2 * np.random.normal(size=100) + 3)
d2 = np.random.f(2, 4, size = 100)
d3 = np.random.randint(1, 100, size=100)
#创建一个方法,生成一个统计量名称和统计量对应的值得二维表
defstatus(x):
returnpd.Series([x.count[], x.min(), x.idxmin(), x.quantile(.25), x.median(), x.quantile(.75), x.mean(), x,max(), x.idxmax(), x.mad(), x.var(), x.std(), x.skew(), x.kurt()], index = ['总数', '最小值', '最小值位置', '25%分位数', '75%分位数', '均值', '最大值', '最大值位数', '平均值绝对偏差', '方差', '标准差', '偏度', '峰度'])
#将三组数据都进行统计量的计算并打印出一一对应的二维表
df = pd.DataFrame(np.array[d1, d2, d3].T, columns = ['x1', 'x2', 'x3'])
df.head()
print(df.apply(status)) #使用三组数据计算出结果并打印上述内容就是我们,大数据分析与应用实验—Numpy、Pandas 的全部内容了,希望可以得到大家的支持!
如果各位有疑问的话,欢迎私信,发现错误,也希望可以指出,共同改进学习,加油💪!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}