







提示:可能会有错误,欢迎指出
文章目录
前言
第三次打数学建模比赛。
这次的APMCM的A题的题目是水果采摘机器人的图像识别,之前在妈妈杯也碰到了计算机视觉的题目,但是出于畏惧选了另一个更难的。于是这次不逃避了,直接冲。
项目地址

提示:以下是本篇文章正文内容,下面案例可供参考
一、环境搭建
注意:先去官网根据自己的系统安装pytorch,再安装ultralytics。
certifi==2022.12.7
charset-normalizer==2.1.1
colorama==0.4.6
coloredlogs==15.0.1
contourpy==1.2.0
cycler==0.12.1
filelock==3.9.0
flatbuffers==23.5.26
fonttools==4.45.0
fsspec==2023.4.0
humanfriendly==10.0
idna==3.4
Jinja2==3.1.2
kiwisolver==1.4.5
MarkupSafe==2.1.3
matplotlib==3.8.2
mpmath==1.3.0
networkx==3.0
numpy==1.24.1
onnx==1.15.0
onnxruntime==1.16.3
opencv-python==4.8.1.78
packaging==23.2
pandas==2.1.3
Pillow==9.3.0
protobuf==4.25.1
psutil==5.9.6
py-cpuinfo==9.0.0
pycocotools==2.0.7
pyparsing==3.1.1
pyreadline3==3.4.1
python-dateutil==2.8.2
pytz==2023.3.post1
PyYAML==6.0.1
requests==2.28.1
scipy==1.11.4
seaborn==0.13.0
six==1.16.0
sympy==1.12
thop==0.1.1.post2209072238
torch==2.1.1+cu121
torchaudio==2.1.1+cu121
torchvision==0.16.1+cu121
tqdm==4.66.1
typing_extensions==4.4.0
tzdata==2023.3
ultralytics==8.0.216
urllib3==1.26.13
二、问题1 和 问题二:数苹果 和 苹果位置
基于附件1中提供的可收获苹果图像数据集,提取图像特征,建立数学模型,统计 每张图像中的苹果数量,并绘制附件1中所有苹果分布的直方图。
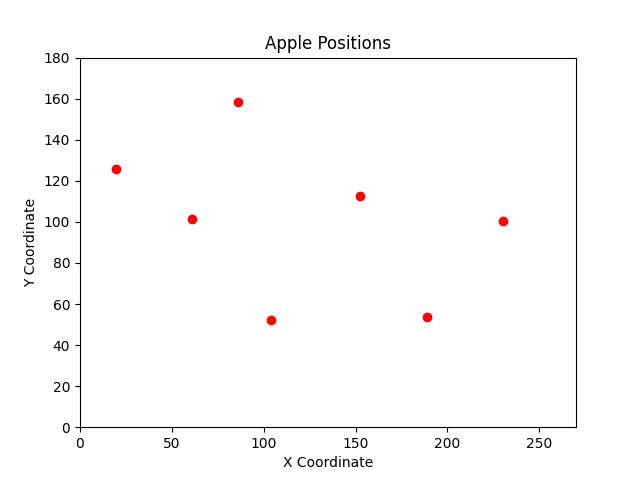
基于附件1中提供的可采摘苹果图像数据集,以图像左下角为坐标原点,识别每个图像中苹果的位置,绘制附件1中所有苹果几何坐标的二维散点图。
训练模型
我用的数据集是roboflow上的农业苹果数据集
训练代码如下
from ultralytics import YOLO
import multiprocessing
def main():
# 加载模型
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
# 训练模型
model.train(data='./final/question1/Apple Vision.v9-applevision-larger-set-80-20-10-split.yolov8/data.yaml', epochs=10, imgsz=640 ,resume=False)
# 保存训练后的模型为'apple.pt'
model.export(format='onnx')
if __name__ == '__main__':
multiprocessing.freeze_support()
main()
训练后将会在./runs/detect/train/weights目录下出现训练的模型best.oxxn
使用模型
from ultralytics import YOLO
import multiprocessing
from PIL import Image
import os
import csv
import matplotlib.pyplot as plt
def plot_apple_positions(apple_positions, image_name, output_folder='./pic/scatter/'):
# 将坐标拆分成两个列表,分别存储 x 和 y 坐标
x_coordinates = [box[0] for box in apple_positions]
y_coordinates = [180 - box[1] for box in apple_positions] # 调整坐标系
# 绘制散点图
plt.scatter(x_coordinates, y_coordinates, marker='o', color='red')
plt.title('Apple Positions')
plt.xlabel('X Coordinate')
plt.ylabel('Y Coordinate')
# 设置坐标轴的范围
plt.xlim(0, 270) # 横坐标范围
plt.ylim(0, 180) # 纵坐标范围
# 保存散点图
scatter_file_path = os.path.join(output_folder, f'{image_name}.png')
plt.savefig(scatter_file_path)
plt.show()
def main():
# 加载模型
model = YOLO('./runs/detect/train5/weights/best.onnx') # 加载官方模型
# 图片文件夹路径
image_folder = './Attachment 1/'
# 检测结果保存文件夹路径
output_folder = './runs/predict/'
os.makedirs(output_folder, exist_ok=True)
# 获取图片文件列表
image_files = [f for f in os.listdir(image_folder) if f.endswith(('.jpg', '.jpeg', '.png'))]
# 用于保存结果的 CSV 文件
csv_file_path = os.path.join(output_folder, 'count.csv')
with open(csv_file_path, 'w', newline='') as csvfile:
# 定义 CSV 写入对象
csv_writer = csv.writer(csvfile)
# 写入 CSV 头部
csv_writer.writerow(['图片序号', '苹果个数'])
# 循环处理每张图片
for i, image_file in enumerate(image_files):
image_path = os.path.join(image_folder, image_file)
image_name = os.path.splitext(image_file)[0]
# 使用模型进行预测
results = model.predict(image_path, save=True)
# 查看 Results 对象的属性
# 打印所有属性
# 获取检测到的苹果个数
print("苹果个数:", len(results[0].boxes))
# 保存绘制的图
# 将图片序号和目标个数写入 CSV
csv_writer.writerow([image_name, len(results[0].boxes)])
# 提取苹果位置
apple_positions = [(box[0], box[1]) for box in results[0].boxes.xywh]
# 绘制二维散点图
plot_apple_positions(apple_positions, image_name)
if __name__ == '__main__':
multiprocessing.freeze_support()
main()
原始图

将会得到每张图片的框线图、苹果位置散点图和记录苹果数量的csv

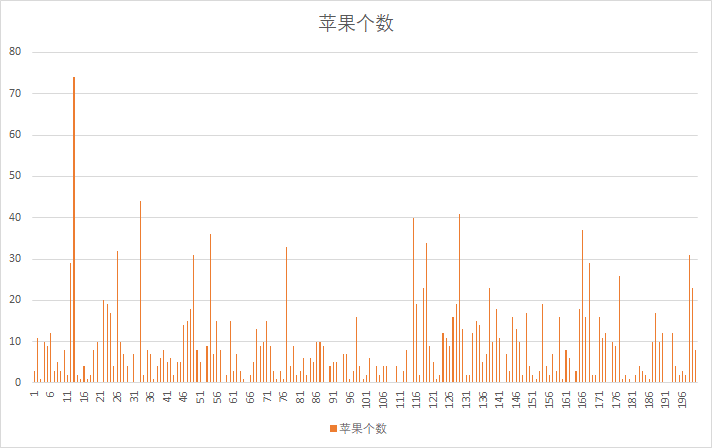
将苹果数量可视化
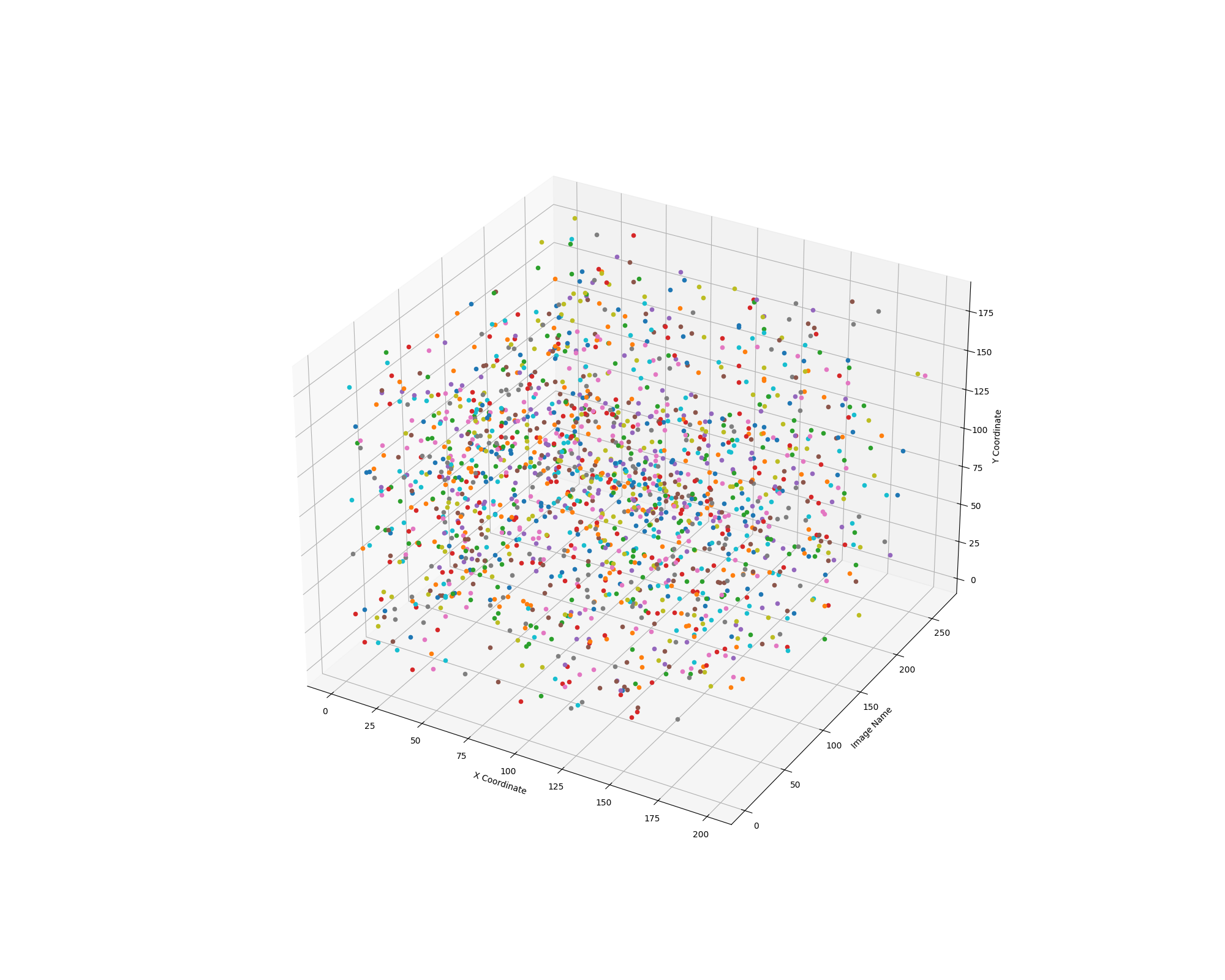
当然,位置图片也可以通过如下代码,绘制三维分布图
import pandas as pd
from ultralytics import YOLO
import multiprocessing
from PIL import Image
import os
import csv
import matplotlib.pyplot as plt
import os
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def main():
# 加载模型
model = YOLO('E:\code\python\APMCM\\1(1)\\train5\weights\\best.onnx') # 加载官方模型
# 图片文件夹路径
image_folder = './pic/q1/'
# 检测结果保存文件夹路径
output_folder = './runs/predict/'
os.makedirs(output_folder, exist_ok=True)
# 获取图片文件列表
image_files = [f for f in os.listdir(image_folder) if f.endswith(('.jpg', '.jpeg', '.png'))]
# 初始化数据列表
all_data = {'Image Name': [], 'Box Number': [], 'X Coordinate': [], 'Y Coordinate': []}
# 循环处理每张图片
for i, image_file in enumerate(image_files):
image_path = os.path.join(image_folder, image_file)
image_name = os.path.splitext(image_file)[0]
# 使用模型进行预测
results = model.predict(image_path, save=False)
# 提取苹果位置
apple_positions = [(box[0], box[1]) for box in results[0].boxes.xywh]
# 添加数据到列表
all_data['Image Name'].extend([image_name] * len(apple_positions))
all_data['Box Number'].extend(list(range(1, len(apple_positions) + 1)))
all_data['X Coordinate'].extend([box[0] for box in apple_positions])
all_data['Y Coordinate'].extend([box[1] for box in apple_positions])
# 保存相关信息至CSV文件
csv_file_path = os.path.join(output_folder, 'apple_positions.csv')
df = pd.DataFrame(all_data)
df.to_csv(csv_file_path, index=False)
if __name__ == '__main__':
multiprocessing.freeze_support()
main()
此代码将所有图片中苹果位置信息,保存至一个csv
使用如下代码可视化
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import ast
import re
# 读取CSV文件
df = pd.read_csv('./runs/predict/apple_positions.csv')
# 自定义函数,用于提取张量值
def extract_tensor_value(tensor_str):
match = re.search(r'tensor\((.*?)\)', tensor_str)
if match:
return float(match.group(1))
else:
return None
# 应用自定义函数以提取张量值
df['X Coordinate'] = df['X Coordinate'].apply(extract_tensor_value)
df['Y Coordinate'] = df['Y Coordinate'].apply(extract_tensor_value)
# 创建3D散点图
# 创建3D散点图,调整图形大小为10x8
fig = plt.figure(figsize=(20, 16))
ax = fig.add_subplot(111, projection='3d')
# 绘制散点图
for index, row in df.iterrows():
x = int(row['Image Name'])
y = row['X Coordinate']
z = row['Y Coordinate']
ax.scatter(x, y, z)
# 设置坐标轴标签
ax.set_ylabel('Image Name')
ax.set_xlabel('X Coordinate')
ax.set_zlabel('Y Coordinate')
# 显示图形
plt.show()
得到苹果位置三维分布图
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
问题三 和 问题四 :估计苹果的成熟状态 和 估计苹果的质量
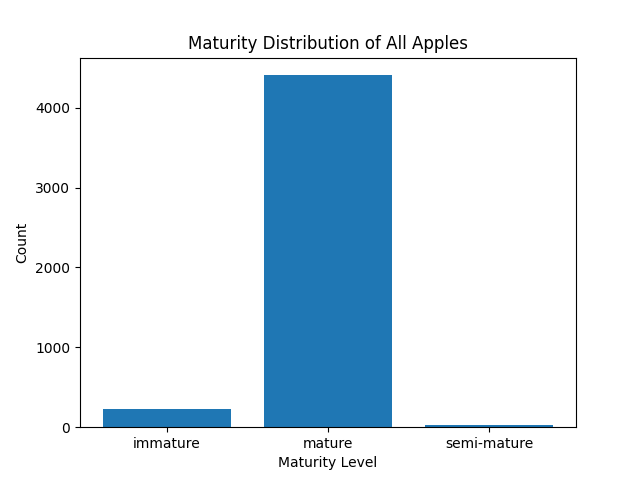
基于附件1中提供的可采摘苹果图像数据集,建立数学模型,计算 每张图像中苹果的成熟度,并绘制附件1中所有苹果成熟度分布的直方图。
基于附件1中提供的可收获苹果图像数据集,以图像左下角为坐标原点,计算每幅图像中苹果的二维面积,估计苹果的质量,并绘制附件1中所有苹果的质量分布直方图。
训练模型
分别使用了苹果成熟度和苹果花朵成熟度两个数据集,分别训练,得到成熟度和花朵两个检测模型
from ultralytics import YOLO
import multiprocessing
def main():
# 加载模型
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
# 训练模型(训练哪个用哪行)
model.train(data='./final/question3/apple flowers.v2i.yolov8/data.yaml', epochs=10, imgsz=640 ,resume=False)
model.train(data='./final /question3/Apple_maturity.v1i.yolov8/data.yaml/data.yaml', epochs=10, imgsz=640, resume=False)
# 保存训练后的模型为'apple.pt'
model.export(format='onnx')
if __name__ == '__main__':
multiprocessing.freeze_support()
main()
检测成熟度
检测苹果颜色成熟度
检测
from ultralytics import YOLO
import multiprocessing
from PIL import Image
import os
import csv
import matplotlib.pyplot as plt
def plot_apple_positions(apple_positions, image_name, output_folder='./pic/scatter/'):
# 将坐标拆分成两个列表,分别存储 x 和 y 坐标
x_coordinates = [box[0] for box in apple_positions]
y_coordinates = [180 - box[1] for box in apple_positions] # 调整坐标系
# 绘制散点图
plt.scatter(x_coordinates, y_coordinates, marker='o', color='red')
plt.title('Apple Positions')
plt.xlabel('X Coordinate')
plt.ylabel('Y Coordinate')
# 设置坐标轴的范围
plt.xlim(0, 270) # 横坐标范围
plt.ylim(0, 180) # 纵坐标范围
# 保存散点图
scatter_file_path = os.path.join(output_folder, f'{image_name}.png')
plt.savefig(scatter_file_path)
plt.show()
def main():
# 加载模型(使用苹果颜色模型)
model = YOLO('./runs/detect/train3/weights/best.onnx') # 加载官方模型
# 图片文件夹路径
image_folder = './Attachment 1/'
# 获取图片文件列表
image_files = [f for f in os.listdir(image_folder) if f.endswith(('.jpg', '.jpeg', '.png'))]
# 循环处理每张图片
for i, image_file in enumerate(image_files):
image_path = os.path.join(image_folder, image_file)
image_name = os.path.splitext(image_file)[0]
# 使用模型进行预测
results = model.predict(image_path, save=False)
#results[0].save_txt('./q3/image_name_flower.txt')
results[0].save_txt('./q3/image_name.txt')
# 查看 Results 对象的属性
# 打印所有属性
# 获取检测到的苹果个数
print("苹果个数:", len(results[0].boxes))
# 保存绘制的图
# 提取苹果位置
apple_positions = [(box[0], box[1]) for box in results[0].boxes.xywh]
# 绘制二维散点图
plot_apple_positions(apple_positions, image_name)
if __name__ == '__main__':
multiprocessing.freeze_support()
main()
绘图
import os
import matplotlib.pyplot as plt
def get_maturity_counts(dir_path):
maturity_counts = {0: 0, 1: 0 ,2: 0}
file_list = os.listdir(dir_path)
for file_name in file_list:
if file_name.endswith(".txt"):
file_path = os.path.join(dir_path, file_name)
with open(file_path, 'r') as file:
lines = file.readlines()
for line in lines:
maturity = int(line.strip().split()[0])
if maturity in maturity_counts:
maturity_counts[maturity] += 1
return maturity_counts
def plot_maturity_counts(maturity_counts):
maturity_levels = [ 'immature','mature','semi-mature']
counts = [maturity_counts[0], maturity_counts[2],maturity_counts[1]]
plt.bar(maturity_levels, counts)
plt.xlabel('Maturity Level')
plt.ylabel('Count')
plt.title('Maturity Distribution of All Apples')
plt.show()
dir_path = r"./apple" # 更改为你的txt文件路径
maturity_counts = get_maturity_counts(dir_path)
plot_maturity_counts(maturity_counts)
检测苹果花朵成熟度
检测
from ultralytics import YOLO
import multiprocessing
from PIL import Image
import os
import csv
import matplotlib.pyplot as plt
def plot_apple_positions(apple_positions, image_name, output_folder='./pic/scatter/'):
# 将坐标拆分成两个列表,分别存储 x 和 y 坐标
x_coordinates = [box[0] for box in apple_positions]
y_coordinates = [180 - box[1] for box in apple_positions] # 调整坐标系
# 绘制散点图
plt.scatter(x_coordinates, y_coordinates, marker='o', color='red')
plt.title('Apple Positions')
plt.xlabel('X Coordinate')
plt.ylabel('Y Coordinate')
# 设置坐标轴的范围
plt.xlim(0, 270) # 横坐标范围
plt.ylim(0, 180) # 纵坐标范围
# 保存散点图
scatter_file_path = os.path.join(output_folder, f'{image_name}.png')
plt.savefig(scatter_file_path)
plt.show()
def main():
# 加载模型(使用花的模型)
model = YOLO('./runs/detect/train3/weights/best.onnx') # 加载官方模型
# 图片文件夹路径
image_folder = './Attachment 1/'
# 获取图片文件列表
image_files = [f for f in os.listdir(image_folder) if f.endswith(('.jpg', '.jpeg', '.png'))]
# 循环处理每张图片
for i, image_file in enumerate(image_files):
image_path = os.path.join(image_folder, image_file)
image_name = os.path.splitext(image_file)[0]
# 使用模型进行预测
results = model.predict(image_path, save=False)
results[0].save_txt('./q3/image_name_flower.txt')
#results[0].save_txt('./q3/image_name.txt')
# 查看 Results 对象的属性
# 打印所有属性
# 获取检测到的苹果个数
print("苹果个数:", len(results[0].boxes))
# 保存绘制的图
# 提取苹果位置
apple_positions = [(box[0], box[1]) for box in results[0].boxes.xywh]
# 绘制二维散点图
plot_apple_positions(apple_positions, image_name)
if __name__ == '__main__':
multiprocessing.freeze_support()
main()
绘图
import os
import matplotlib.pyplot as plt
def get_maturity_counts(dir_path):
maturity_counts = {0: 0, 1: 0}
file_list = os.listdir(dir_path)
for file_name in file_list:
if file_name.endswith(".txt"):
file_path = os.path.join(dir_path, file_name)
with open(file_path, 'r') as file:
lines = file.readlines()
for line in lines:
maturity = int(line.strip().split()[0])
if maturity in maturity_counts:
maturity_counts[maturity] += 1
return maturity_counts
def plot_maturity_counts(maturity_counts):
maturity_levels = [ 'unflowering','flowering']
counts = [maturity_counts[0], maturity_counts[1]]
plt.bar(maturity_levels, counts)
plt.xlabel('Maturity Level')
plt.ylabel('Count')
plt.title('Maturity Distribution of All Apples')
plt.show()
dir_path = r"./flower" # 更改为你的txt文件路径
maturity_counts = get_maturity_counts(dir_path)
plot_maturity_counts(maturity_counts)
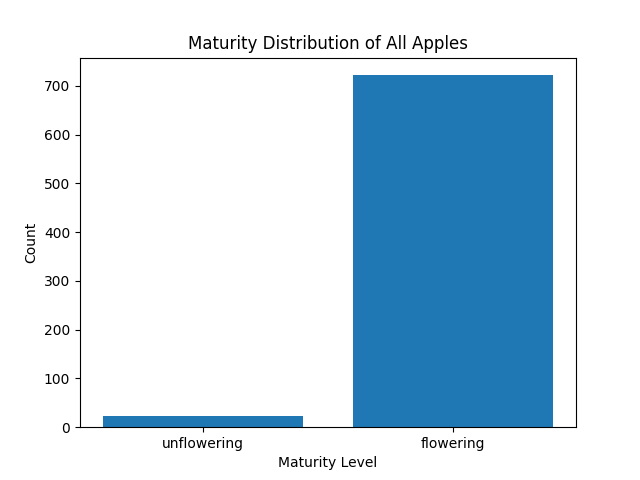
检测评估数量
主要靠评估面积进行估算
import os
import matplotlib.pyplot as plt
def calculate_masses(folder_path, k, img_width, img_height):
masses = []
for file_name in os.listdir(folder_path):
if file_name.endswith('.txt'): # 假设标签文件是txt格式
total_area_per_image = 0
with open(os.path.join(folder_path, file_name), 'r') as file:
lines = file.readlines()
for line in lines:
_, x_center, y_center, width, height = map(float, line.strip().split())
# 为了得到实际像素面积,��要用到原始图像的宽度和高度来进行反归一化
area = (width * img_width) * (height * img_height)
total_area_per_image += area
mass = total_area_per_image * k # 估算质量
masses.append(mass)
print(f'Total apple area in {file_name}: {total_area_per_image}')
print(f'Total apple area in all images: {sum(masses)}')
return masses
def plot_mass_distribution(masses):
plt.hist(masses, bins=20, color='gray', edgecolor='black')
plt.xlabel('Mass')
plt.ylabel('Count')
plt.title('Mass distribution of apples')
plt.show()
folder_path = r"./labels" # 由第一问得出的评估xywh数据来计算
img_width = 270 # 替换为你的图像宽度
img_height = 185 # 替换为你的图像高度
k = 2 # 设定比例系数,此值需根据实际情况调整
masses = calculate_masses(folder_path, k, img_width, img_height)
plot_mass_distribution(masses)
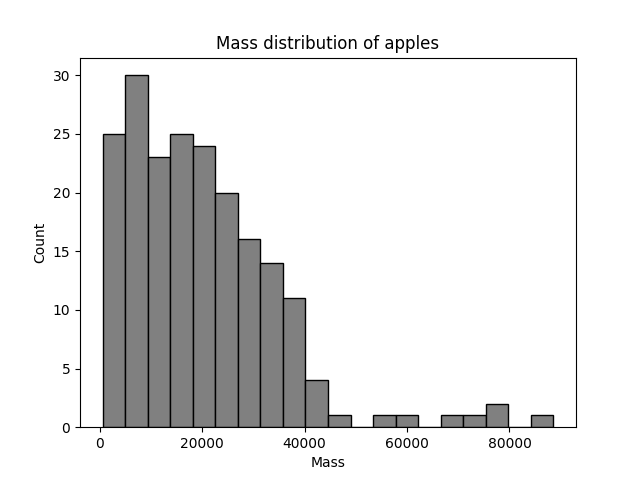
问题5:苹果的识别
基于附件2中提供的收获水果图像数据集,提取图像特征,训练苹果识别模型,识别附件3中的苹果,并绘制附件3中所有苹果图像ID号的分布直方图。
这一问就没有啥数据集可以用了,主要是要把苹果从李子、梨、西红柿、杨桃中区分开。
数据标注
我使用的官方教程中推荐的Roboflow
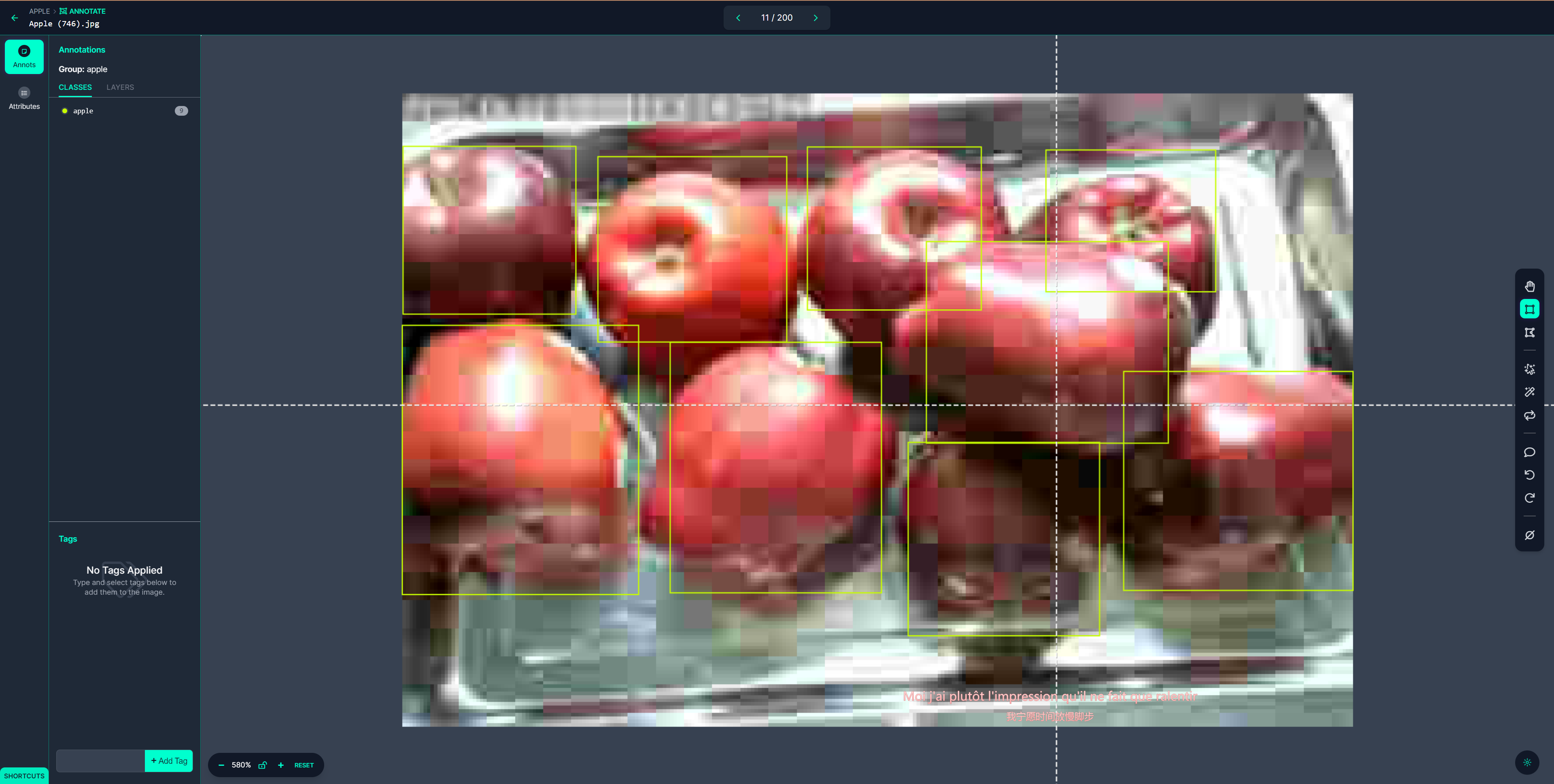
制作了自己的数据集
训练模型
from ultralytics import YOLO
import multiprocessing
def main():
# 加载模型
model = YOLO('yolov8n.pt') # 加载预训练模型(推荐用于训练)
# 训练模型
model.train(data='./apple.v1i.yolov8\data.yaml', epochs=10, imgsz=640 ,resume=False)
# 保存训练后的模型为'apple.pt'
model.export(format='onnx')
if __name__ == '__main__':
multiprocessing.freeze_support()
main()
检测苹果
from ultralytics import YOLO
import multiprocessing
import os
import csv
import matplotlib.pyplot as plt
import re
def extract_image_id(file_name):
# 从文件名中提取图片ID号
match = re.search(r'\((\d+)\)', file_name)
if match:
return match.group(1)
else:
return None
def main():
# 加载模型
model = YOLO('./runs/detect/train4/weights/best.onnx') # 加载官方模型
# 图片文件夹路径
image_folder = './Attachment 3/'
# 检测结果保存文件夹路径
output_folder = './runs/predict/'
os.makedirs(output_folder, exist_ok=True)
# 获取图片文件列表
image_files = [f for f in os.listdir(image_folder) if f.endswith(('.jpg', '.jpeg', '.png'))]
# 用于保存结果的 CSV 文件
csv_file_path = os.path.join(output_folder, 'count_fruits.csv')
with open(csv_file_path, 'w', newline='') as csvfile:
# 定义 CSV 写入对象
csv_writer = csv.writer(csvfile)
# 写入 CSV 头部
csv_writer.writerow(['图片ID号', '苹果个数'])
# 用于存储所有图片的苹果个数和ID号
apple_count_list = []
# 循环处理每张图片
for i, image_file in enumerate(image_files):
image_path = os.path.join(image_folder, image_file)
image_name = os.path.splitext(image_file)[0]
# 使用模型进行预测
results = model.predict(image_path, save=False)
# 获取图片ID号
image_id = extract_image_id(image_name)
if image_id is not None:
# 获取检测到的苹果个数
apple_count = len(results[0].boxes)
# 将图片ID号和苹果个数写入 CSV
csv_writer.writerow([image_id, apple_count])
# 存储苹果个数和ID号到列表中
apple_count_list.append((int(image_id), apple_count))
# 绘制苹果图像ID号的分布直方图
if apple_count_list:
image_ids, apple_counts = zip(*apple_count_list)
plt.bar(image_ids, apple_counts)
plt.xlabel('图片ID号')
plt.ylabel('苹果个数')
plt.title('苹果图像ID号的分布直方图')
plt.show()
if __name__ == '__main__':
multiprocessing.freeze_support()
main()
绘图
import pandas as pd
import matplotlib.pyplot as plt
# 读取 CSV 文件
csv_file_path = './runs/predict/count_fruits.csv'
df = pd.read_csv(csv_file_path,encoding='gbk')
# 提取数据
apples = df['苹果个数']
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 加入一行,解决中文不显示问题,对应字号选择如下图
plt.rcParams['axes.unicode_minus']=False # 解决负号不显示问题
# 绘制分布柱状图
plt.bar(df['图片ID号'], df['苹果个数'])
plt.xlabel('Fruit ID')
plt.ylabel('Apple Count')
plt.title('Histogram of the distribution of Fruit ID numbers')
plt.show()
#绘制分布直方图
plt.hist(apples,bins=20,alpha=0.5)
plt.xlabel('Fruit ID')
plt.ylabel('Apple Count')
plt.title('Histogram of the distribution of Fruit ID numbers')
plt.show()
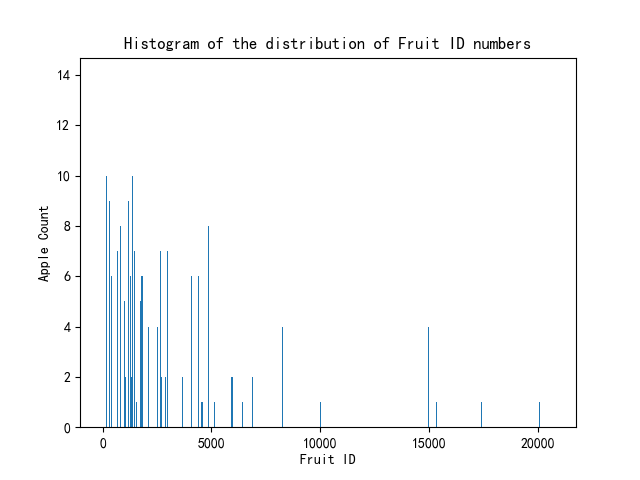
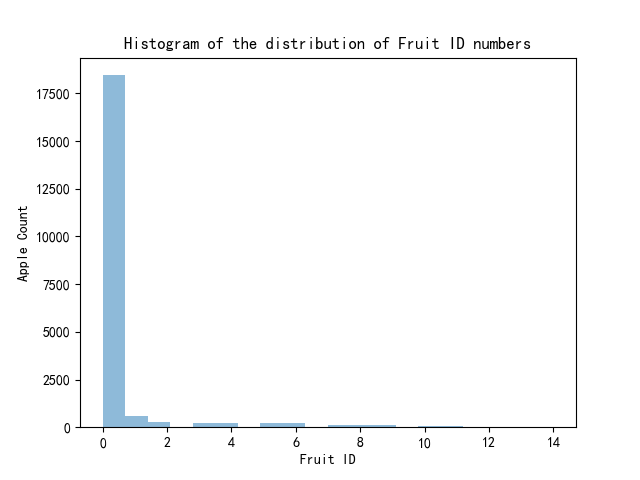
可以看出,已经避开了其它水果的干扰,不是苹果的图片检测结果就是0。
结尾
这次比赛过程并不顺利,最开始是python环境一直有问题,后来是数据集找不到合适的,好在最终都解决了。
yolov8的实际体验,效果还是不错的。
以后要是还有计算机视觉的可以直接用了。


















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











