






1.SVM的定义
支持向量机(Support Vector Machine,简称SVM)是一种监督学习算法,用于数据分类和回归分析。其目标是找到一个最优的超平面,将数据集划分成不同的类别。在这个过程中,SVM关注的是距离超平面最近的一些数据点,这些数据点被称为支持向量。
2.SVM的主要特点
SVM具有以下主要特点:
-
最大间隔分类器(Maximum Margin Classifier): SVM致力于找到一个能够划分不同类别的超平面,并确保该超平面到最近的数据点(支持向量)的距离最大。这种最大间隔的思想使得SVM对噪声和泛化能力有较好的鲁棒性。
-
核技巧的应用: SVM通过引入核函数,使其在处理非线性可分的数据时也能取得良好的效果。核函数允许将数据映射到高维空间,从而在高维空间中找到一个能够线性分隔的超平面。
3.SVM的工作原理
3.1线性和非线性问题
-
线性分类: 在线性可分的情况下,SVM通过找到一个最大间隔超平面,实现了对线性问题的精准分类。
-
非线性分类: 通过核技巧,SVM能够处理非线性可分的数据,将其映射到高维空间进行线性划分,从而扩展了SVM在更复杂问题上的适用性。
3.2最大间隔分类器
最大间隔分类器是SVM的核心概念之一,其目标是找到一个超平面,使得不同类别的数据点到这个超平面的距离最大。这个距离被称为间隔(margin)。通过最大化这个间隔,SVM能够提高模型的鲁棒性,使其对新数据的泛化能力更强。
在数学上,最大间隔分类器的目标可以通过优化问题来表述,包括最小化权重向量的范数以及对误分类点的惩罚。
间隔(Margin)的定义:
给定一个超平面 ω⋅x+b=0,其中 ω 是法向量,x 是数据点的特征向量,b 是偏置,对于任意数据点 xi 到超平面的距离可以用以下公式表示:
距离=∥ω∥1∣ω⋅+b∣
其中,∥ω∥ 表示ω的范数。如果我们的数据是线性可分的,那么我们的目标是找到一个 ω 和 b,使得对于所有的 i,满足以下条件:
(ω⋅
+b)≥1
这里 yi 是数据点 xi 的类别标签(1 或 -1)。而对于支持向量(即满足 yi(ω⋅+b)=1 的点),其到超平面的距离是最小的。
3.3核技巧的应用
SVM通过核技巧处理非线性可分的数据。核函数允许在低维空间中无法线性分割的数据通过映射到高维空间来实现线性分割。常用的核函数包括:
-
线性核函数: 用于处理线性可分的数据。
-
多项式核函数: 通过多项式映射将数据映射到更高维的空间。
-
径向基函数(RBF)核函数: 常用于处理非线性可分数据,将数据映射到无穷维的空间。
核技巧的应用使得SVM在处理复杂数据集时具备了更强的表达能力,从而提高了模型的适用性。
4.SVM的数学原理
4.1解释数据可分离的概念
在线性可分的情况下,我们希望找到一个超平面,表示为:
ω⋅x+b=0
其中,w 是法向量(决定超平面方向的权重),x 是数据点的特征向量,b 是偏置。
对于一个给定的数据点 ,其类别标签为
(
∈{−1,1}),我们希望满足以下条件:
(ω⋅
+b)≥1
若数据是线性可分的,所有数据点都满足这个条件。
4.2对偶问题的转化
对偶问题是通过构建拉格朗日函数来引入拉格朗日乘子 ,进而将原始问题转化为极大极小问题。拉格朗日函数为:
![]()
其中, 是拉格朗日乘子。
通过对 ω 和 ξ 分别求偏导并令其为零,可得到对偶问题:
![]()
满足以下条件:
0≤≤C
4.3拉格朗日乘子法的应用
通过求解对偶问题,可以得到最优的拉格朗日乘子 αi。最终的分类决策函数为:
![]()
其中, 大于零的点对模型产生影响,它们被称为支持向量。最优超平面由支持向量完全决定。
5垃圾邮件分类代码实现
导入库:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
import re
import numpy as np加载数据集:
loadDataSet函数负责加载数据集。textParse函数用于解析文本并返回一个单词列表。- 对于每个文件,将其加载到
docList中,并将其对应的类别(垃圾邮件为1,非垃圾邮件为0)加载到classList中。
def loadDataSet():
docList = []
classList = []
for i in range(1, 26): # 遍历25个文件
wordList = textParse(open('C:/Users/Brenty/Desktop/email/spam/%d.txt' % i, 'r', encoding='latin1').read())
docList.append(" ".join(wordList))
classList.append(1) # 垃圾邮件标记为1
wordList = textParse(open('C:/Users/Brenty/Desktop/email/ham/%d.txt' % i, 'r', encoding='latin1').read())
docList.append(" ".join(wordList))
classList.append(0) # 垃圾邮件标记为0
return docList, classList文本解析:
textParse函数接收一个大字符串,使用正则表达式将其分割成单词,并返回一个小写的单词列表。
def textParse(bigString):
listOfTokens = re.split(r'\W+', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 0]SVM训练和测试:
svmTrainAndTest函数负责训练和测试SVM模型。- 使用TF-IDF向量化文本数据。
- 划分数据集为训练集和测试集。
- 使用线性核的SVM模型进行训练。
- 预测测试集并评估模型性能。
def svmTrainAndTest():
docList, classList = loadDataSet()
# 使用TF-IDF进行文本特征提取
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(docList)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, classList, test_size=0.2, random_state=42)
# 训练SVM模型
svm_model = SVC(kernel='linear') # 使用线性核
svm_model.fit(X_train, y_train)
# 预测
y_pred = svm_model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Classification Report:\n', report)
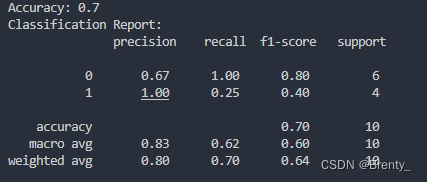
svmTrainAndTest()结果:
6.总结
优点:
-
高维空间的高效处理: SVM在高维空间中的表现优秀,适用于处理具有大量特征的数据,比如文本分类问题。
-
最大间隔分类: SVM通过寻找最大间隔超平面,使得模型更具泛化性,对新样本的分类效果较好,具有较高的鲁棒性。
-
核技巧的应用: SVM利用核技巧可以处理非线性问题,将低维的非线性可分问题映射到高维的线性可分问题,从而更好地解决各类复杂问题。
-
小样本数据的处理: SVM在小样本数据集上的表现相对较好,对于数据量较小的情况也能产生较好的分类效果。
-
适用于不同类型的数据: 由于核函数的存在,SVM适用于处理不同类型的数据,包括数值型和非数值型数据。
缺点:
-
计算复杂度高: 在大规模数据集上训练SVM模型的计算复杂度较高,尤其是在非线性问题中,需要大量的计算资源。
-
选择核函数的主观性: 核函数的选择对模型性能有很大的影响,但没有一种核函数能够适用于所有情况,选择核函数具有一定的主观性。
-
对噪声和缺失数据敏感: SVM对噪声和缺失数据比较敏感,可能会导致模型性能下降。
-
参数调优困难: SVM有一些需要调优的参数,如正则化参数C和核函数的参数,需要经过反复试验和调整才能找到最佳组合。
-
仅适用于二分类问题: 原始的SVM算法主要适用于二分类问题,对于多分类问题需要进行扩展或者使用其他方法。
综上所述,支持向量机是一种具有在各种应用场景中取得优越性能的潜力的机器学习算法。通过灵活选择核函数和调整参数,SVM能够适应不同类型的数据,为实际问题的解决提供了有力支持。

















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









