







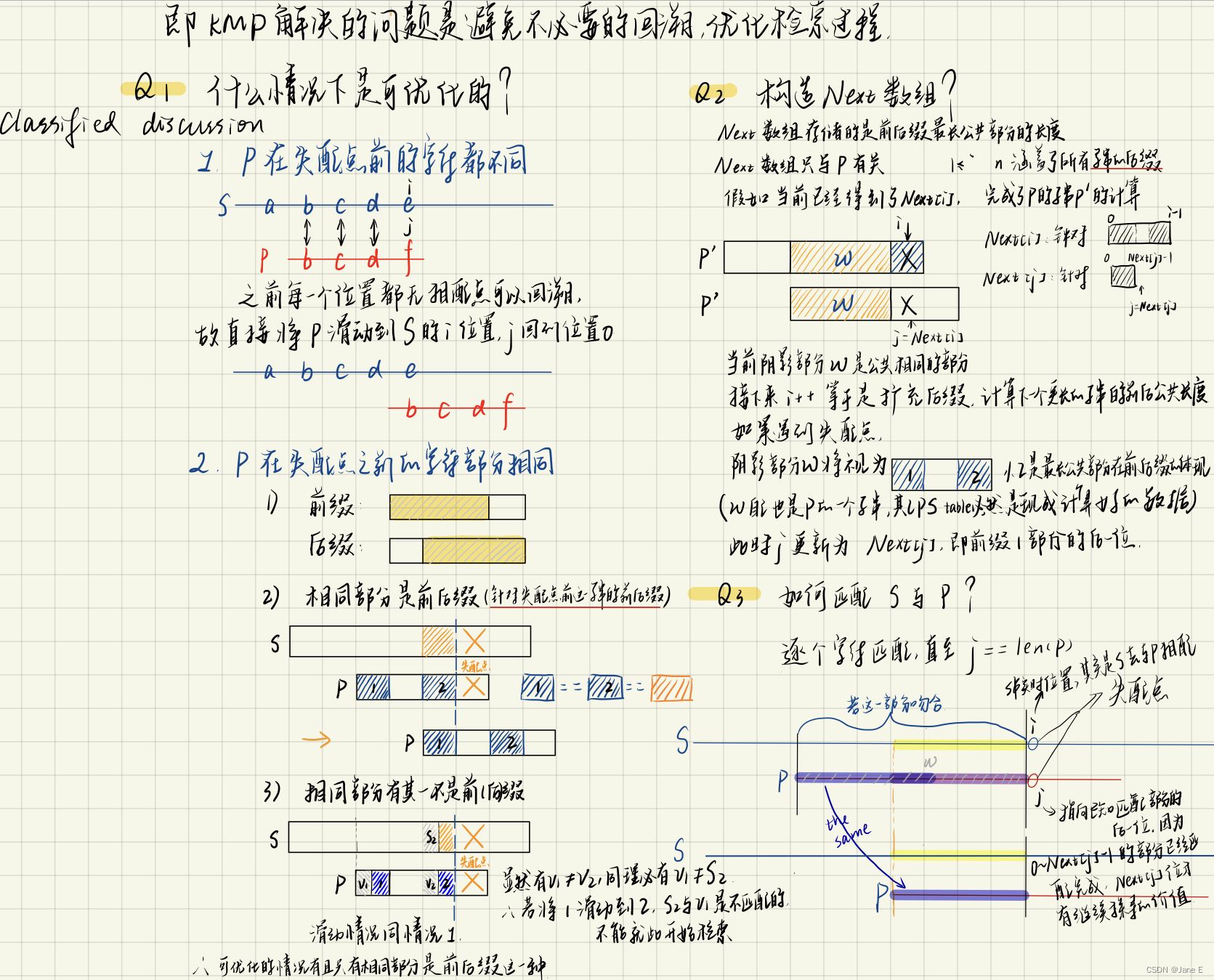
对于S串每一个特定的下标i,在满足s[i-j+1,i]=p[0,j]的前提下,我们需要找出j的最大值 唯一不同的在于,求next数组时,我们关心对于每个不同的下标i,j能走多远;匹配时,仍然是对于每个不同的i,j能走多远的问题,但我们只关心j是否走到末尾
j指向后一位方便了next的调用
匹配时,若j==n,那么此时i指向的是S中相匹配的最后一位,要得到初始位置需要有i-n+1
#include<cstdio>
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
const int N=100005,M=1000005;
/*给定一个字符串 S,以及一个模式串 P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模式串 P 在字符串 S 中多次作为子串出现。
求出模式串 P 在字符串 S 中所有出现的位置的起始下标。
输入格式
第一行输入整数 N,表示字符串 P 的长度。
第二行输入字符串 P。
第三行输入整数 M,表示字符串 S 的长度。
第四行输入字符串 S。*/
//next数组,next[j]等于P[0]~P[j-1]这部分子串的前缀集合和后缀集合的最长交集长度,即最长公共前后缀
int n,m;
char s[M],p[N];
int Next[N];
int main()
{
cin>>n>>p>>m>>s;
//构造Next
Next[0]=0;
Next[1]=0;
for(int i=1;i<n;i++)
{
int j=Next[i];//针对P[0...i-1]的LPS table
while(j&&p[i]!=p[j]) j=Next[j];
if(p[i]==p[j]) Next[i+1]=j+1;//针对P[0...i]的LPS table,j就是一个公共长度
else Next[i+1]=0;//前缀部分无法找到与新加入后缀匹配的位置,考虑到所求公共前缀里一定包括最后一位的“克隆”,也就是新加入的后缀,所以公共部分不存在
}
//KMP匹配
//S[0...i]这一段中能否有P
for(int i=0,j=0;i<m;i++)
{
while(j&&s[i]!=p[j]) j=Next[j];
if(s[i]==p[j]) j++;
if(j==n)
{
printf("%d ",i-n+1);
}
}
return 0;
}
















 2046
2046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









