







一 事务的概念
为什么要有事务,我们先前没学事务,也能写sql语句,事务的意义是什么? 由来: 是为了服务应用层开发,降低开发难度。假如没有事务,那我们身为开发人员,要处理转账需求,此时一定是有多条sql语句对两个账号进行操作,mysqld就是一个网络服务,支持多个客户端对服务端的数据做curd,mysqld则是多线程处理这些请求,多线程一条一条执行sql语句,那这两句sql就是割裂开来的,我们怎么知道要让这两个线程先执行,这就很难设计。一个线程执行了扣除我账户的钱,此时另一个线程还没执行将我的钱加到你的账户中,此时其它线程读取我们的账户信息,得到的存款都是错误的。
所以我们就要在mysqld上再实现一层,能够将多条sql语句合并成一个需求,保证在这个需求处理完之前别人不能来访问,如何保证别人不来访问数据,也就是分配一个锁给这个需求,如果是以一句sql语句为单位分配锁,就无法解决上述场景,这个是事务串行化隔离的雏形,所以为了使用方便,免得每个使用者都手动实现sql语句的合并,mysqld就提供了事务。这里还简单引入了隔离性,因为sql语句合并成事务后,还是会有并发访问的问题,这个时候要用隔离性来解决。
二 事务演示
1 准备工作
mysqld本质是一个网络服务,为了研究事务,我们将隔离级别设置为读未提交,这是最低的,设置后要重启客户端,之后的客户端启动后都是这个隔离级别,意义: 为了方便研究事务。

创建测试表
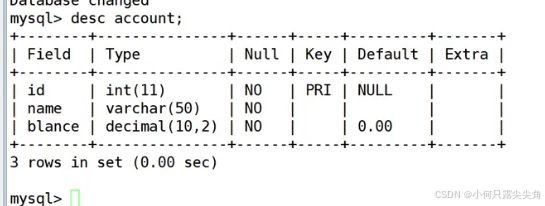
2 事务的基本操作
然后提交方式为On,表示打开自动提交。
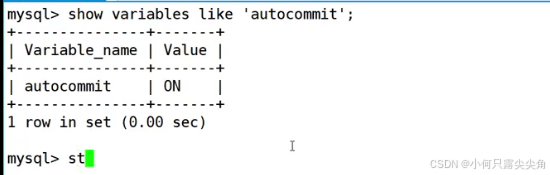
启动事务,往后所有的sql语句都是一个事务,
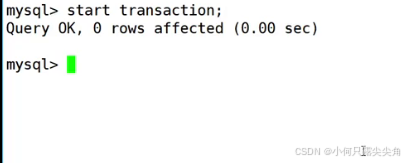
begin(begin 等价 start启动事务)让另一个客户端2也启动一个事务,此时有两个客户端都启动了事务
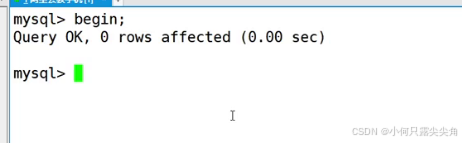
客户端1 设置保存点s1

然后客户端1开始插入数据,
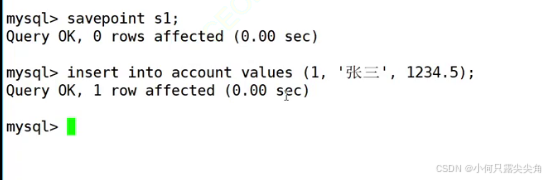
客户端2也能看到,这个和隔离级别设置最低有关系,这个隔离级别下两个并发的事务可以看到互相的修改结果。
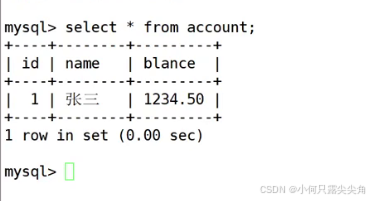
客户端1 多次设置保存点,可以支持后续回滚。
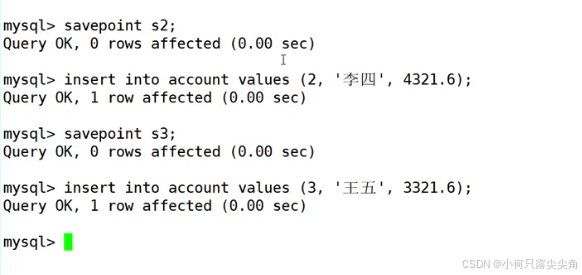
客户端2都能看到。

回滚操作,此时就回到s3节点,
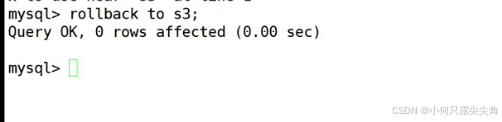
那数据应该会少一条王五的,确实如此。
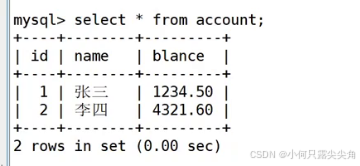
此时就是提交事务了,start和提交之间的sql语句都在一个事务内。

rollback默认回滚,是直接回滚到初始情况。
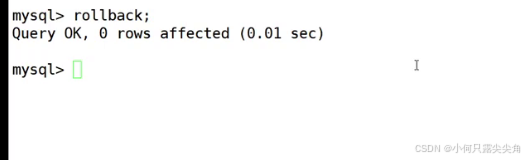
注意,回滚只能在事务间执行,提交后就不能回滚,虽然下面显示回滚成功,但是通过查询数据来看,回滚并未生效。
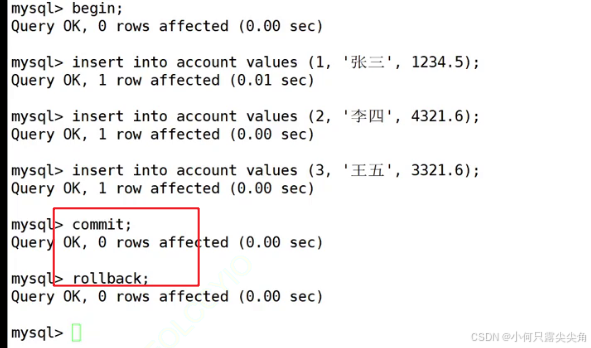
3 异常情况处理
当我们在事务中使用ctrl + \使得客户端崩溃
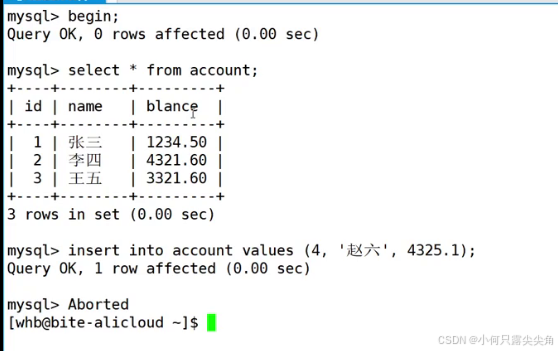
再次登录查询,发现自动回滚了。
但是只要提交了后,客户端崩溃也不会导致回滚影响先前的结果,这就是事务的持久性。可是我们一直是打开自动提交的,为什么先前崩溃没有自动提交呢,这是因为我们的事务都是手动begin开启的,此时这个提交方式不起作用,终止进程也不会自动提交,不提交那回滚就会恢复数据了。

此时我们不手动启动事务,而是一句句sql指令来测试,此时每句sql指令就是一个事务,这个自动提交是否打开,在客户端崩溃就会有不同的表现。关闭自动提交。

删除数据
然后程序崩溃,会自动回滚,因为该事务没有被提交,属于未完成出错,mysql选择回滚。

但如果自动提交开了
再模拟客户端崩溃
数据就真的被删除了,崩溃后不会回滚,就是因为崩溃后,自动提交了,显然这个自动提交只适用于自动启动的事务。
4 事务的隔离性和原子性
先前了解事务时我们提到事务的由来,是为了合并sql语句,同时保证:事务所有操作要么全部成功,要么失败,回滚,不会只完成一半,从用户层的角度来看,就是事务执行返回的结果要么是执行前,要么是执行后,不是指另一起一个事务来看,而是我们使用者查看事务的执行结果只会有两种状态,这就是事务的原子性。
虽然事务是原子的,但不是意味着他们之间是不会互相影响的,先前说那mysqld一定会并发处理多个事务,那就一定会出现事务并发访问的问题,我们要让事务执行时不被干扰,这个不被干扰就是隔离性,这个不被干扰我们很容易理解成完全不受干扰,数据库实际上允许事务收到不同程度的干扰,这就是和隔离级别相关了,完全不被干扰实际上是最高隔离级别。
问题1 事务并发到来,一个事务要对数据更新,另一个要查询,谁先执行?
串行化下应该谁先来谁先执行,在非串行化下是并发执行的。至于事务应不应该看到并发事务的更新结果,这个得看隔离级别,如果能看到,这说明事务之间能互相影响,干扰,毫无隔离性,如果看不到,查询结果确实不是数据库中最新的数据,这种数据不一致符合预期吗,这个下面再解释。
问题2 为什么要有四个隔离级别
数据库早期研发时考虑到多个事务并发访问数据的问题,例如脏读,不可重复读,幻读,需要我们解决各个问题,从读未提交到,读提交,可重复读到串行化,隔离级别越来越高,并发访问问题越来越少,数据一致性越来越高,并发越小,性能越差。
不同的隔离级别对不同的事务进行隔离,有些对并行的隔离,有些对未来的事务进行隔离,全都隔离就是串行化执行了,此时就不会出现查询结果不是最新的了,保持了高度的数据一致,出现数据不一致问题也并非是出错,要结合场景要求,如上所说,有时候需要减少一致性为并发让步,一个事务在读的时候允许其它事务并发来跑,这些事务修改了数据就有了数据一致性问题,所以问1结尾说数据不一致结合某些并发高的场景来看是符合预期的。
那串行化执行一定是符合的吗,有没有场景要考虑往后的事务影响呢? 我想应该是有的,如果真有了,可以用建立事务间的依赖关系使得事务执行时考虑后面的事务。注: 是运行中的事务相互隔离,对未来的,已经提交的事务不需要讨论隔离性,因为都影响不到自己。
三 隔离级别
1 隔离级别的查看

第二种和第三种是一样的

每次登录就是创建一个会话,会用全局的隔离级别初始化当前会话隔离级别,全局应该是保存在mysqld服务端。会话的概念: 客户端登录,就是创建了一个会话,生命周期是从登陆到断开。
级别设置:对谁设置(session/ global),设置级别是什么

注意,设置全局的,不会对已经有的会话隔离级别进行修改,要重新登录,服务端重新创建会话的管理信息,我们的隔离级别才会被初始化。
2 隔离级别的演示
读未提交
启动两个客户端,分别启动一个事务,显然这两个事务是并行的

一个客户端一改,事务还没结束,另一个客户端能看到该客户端的操作结果
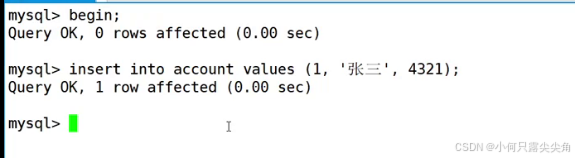
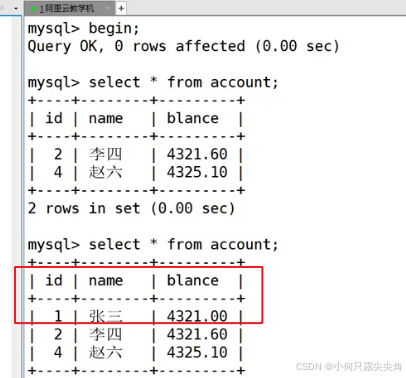
在更新的时候,两个事务是会申请独占锁,这个锁是行级的,所以当两个,事务对同一行做update修改就会触发锁冲突,导致阻塞。注意,有时候只有一个事务在更新时,此时根据资料显示,事务应该持有独占锁,实际上我们查看这个事务却并没有持有锁,但是一旦有别的事务也来更新,我们原来的事务会立刻分配到锁,使得后续事务无法得到锁而休眠,这就是锁的延迟分配。因为只有一个事务的时候没必要加锁,当真正用的时候再分配,减少锁的管理,是对性能的优化。
这就是读未提交,读到了别人还未提交的状态。原理:所有事务都是看最新的缓存数据,此时undo log中还会保留历史数据用于回滚,不用于版本控制。
读提交
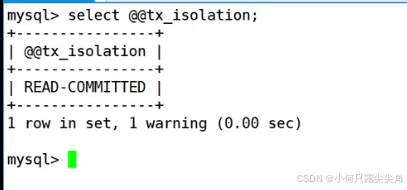
让两个客户端隔离级别为读提交,然后各起一个事务。
,
客户端2先查看初始的数据
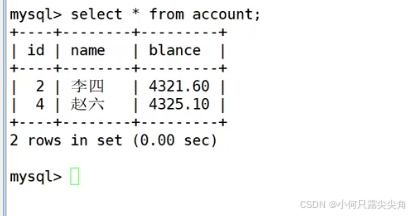
客户端1插入
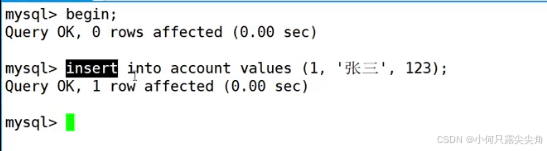
此时另一个客户端2看不到这个变化,自己却看得到,如何实现各个客户端看得不一样? 版本控制,后面隔离性原理会慢慢提及。
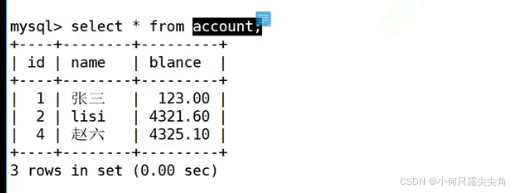
只有当这个curd的事务提交了,其它的并行事务才能看到结果。
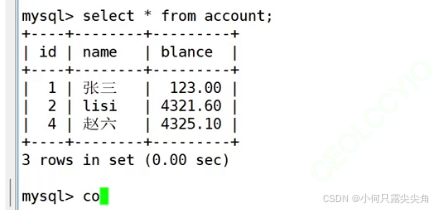
没有看到最新的数据,屏蔽了并行事务对数据的修改,只会看到已经提交的事务,这就解决了脏读问题。却导致在一个事务内多次调用select,结果可能不一样,这就是不可重复读问题。不可重复读是问题吗? 会造成什么问题? 样例如下,当下面两个事务在并发运行时,

小张先执行了三行select,此时tom已经被搜索出来了,然后小王改了立马提交,此时小张又会查出第二个tom,这种重复读取的场景下就出问题了。
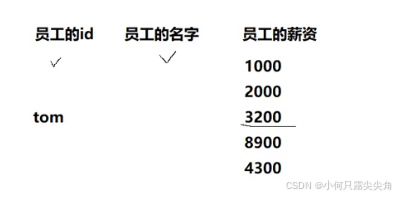
但是并不意味这个隔离等级无意义,因为这个解决了脏读问题,牺牲了一些性能用于版本控制。
可重复读
两个并行的事务无法互相看到结果,只有在事务结束,然后启动的事务才能看到。rc和rr由于版本控制,在读取时不加锁,但是更新时会申请独占锁。
同时启动两个事务,事务1做如下更新
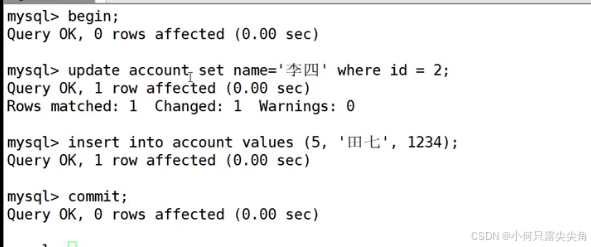
事务2就算等事务1提交了也看不见,重复读结果不变,这就是可重复读。
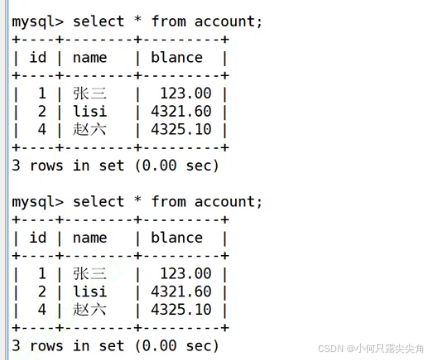
只有在事务1提交后启动的事务才看得到,这个等我们了解版本控制就理解了。
可重复读由于版本控制,1 不是能够自行消除幻读影响吗,当我的事务在运行时,已经形成了快照,别的事务做的修改和插入都会对数据打上事务id,我一比较就发现该事务是未来的或者并行的,就看不到该数据。快照读下mvcc确实能解决幻读问题,但是在当前读下还是会有幻读问题,解决: next-key和gap行锁解决的。
现象1 事务2如果先不select,等事务1执行完修改事务提交后再select,此时就能看到新的数据,如果是先select一次,等事务1执行完修改事务提交再次select查看,此时就看不到最新的数据。这个也是和版本控制相关,也是rr和rc的差别。
串行化

上面隔离等级是解决读写并发的问题,写写并发只能用串行化解决,是依赖锁解决的。此时还是同时启动两个客户端,分别启动事务ab,各自select查询,此时事务不会阻塞,我们可以通过select * from information_schema.innodb_locks查看锁的信息,其实此时是加了共享锁的,只是还没有真正分配,所以查不出来。当事务a要修改,此时就被卡住了,因为事务b会瞬间将应该分配的共享锁分配下来,事务a不会分配共享锁(原因后面提),而此时事务a要申请独占锁对该资源进行加锁,会被事务b的共享锁阻塞,这两个锁从定义上就知道,两个锁是互斥的,不能两个事务分别持有对同一个资源进行加锁。
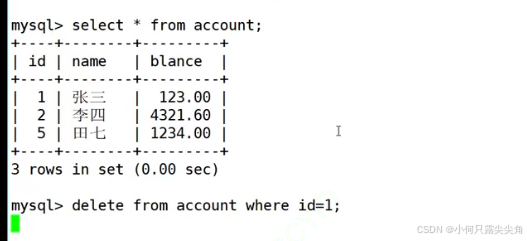
那为什么事务a没有分配共享锁呢,因为它已经在申请独占锁了,就不会再分配共享锁,免得到时候还要释放。一个事务对于一个资源只会加一把锁,不能同时加共享和独占锁。
3 版本控制
后面要解释版本控制(mvcc)的原理,解释完这个版本控制,有助于我们理解rr和rc隔离级别的实现。
先来两个前置知识。
1 事务要分先后,用什么来区分,事务到来时会被分配一个事务id,id越小,事务越先来。我们在rc和rr中曾多次提及事务先后的概念,就是通过事务id来区分的。
2 mysqld会同时处理多个事务的情况,这些事务要被执行,挂起,销毁,也就是mysqld会对事务进行管理,也就是调度处理,处理完就要删除该事务。管理: 对事务用结构体进行描述,然后将这些结构体对象组织起来,这个就是事务的具体化。
接下来再认识三个隐藏字段,还有undo log和read view,它们组成了mvcc。mysql会在建表的时候给表多建几列,这几列用来保存隐藏字段。
字段1 事务id

当事务a修改了表的某行后,会先保存修改该行数据到undo log中,然后再去修改表的数据,这样就知道历史数据是什么,可以回滚,而且记录该行修改事务id也会被更新成事务a的。
字段2 回滚指针

我们先前说了某行数据被修改前,数据会先复制一份在undo log中,然后直接对该行进行操作,该行会有一个指针,指向历史版本,方便找到历史版本进行读取。
字段3 默认的主键索引

我们先前没建立索引select慢,就是因为没用上这个主键索引,根据一个普通列进行select只能暴力遍历。
字段4 flag隐藏字段
表示数据是否被删除,意义: 这些数据是存在叶子节点里的page页,是在内存的,我们不需要清空内存的数据,直接删除会导致我们要调整page内的数据存储位置,我们只需要标记这个数据是无效的,之后刷新的时候不将其持久化即可。
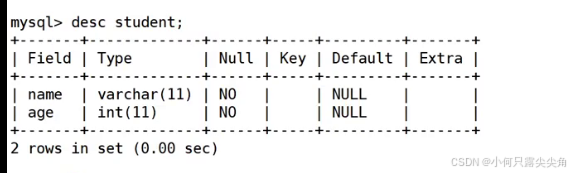
创建一个测试表,插入一条数据。

很久前曾提及,一句sql指令默认为一个事务,所以此时上面插入的这行数据记录的修改事务id就是先前insert事务id,id就随便用个数字,完整行如下:

5 undo日志
就是一块缓冲区,专门用来保存版本数据。开始模拟mvcc。现在有一个事务(id为10),对student表进行修改,将name改成李四。修改前先保存一份在undo log中,然后返回保存地址。
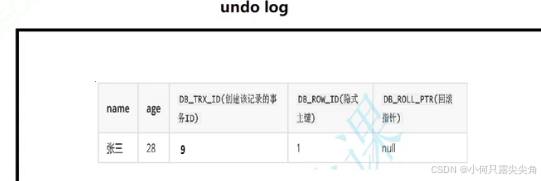
执行完后如下,mysql存了两份记录,一份是原本用于修改,一份是副本用于其它事务读取。

如果之后又来了个事务11,要对刚刚那个数据进行修改,将年龄改成38,此时不是对历史数据进行修改,还是复制一份到undo log中,然后对原本进行修改。
undo log只会保存事务运行期间的历史版本,事务运行期间可以多次修改,就会有多个版本,但是提交完后不一定会释放(因为它们的历史版本会被其它事务读取,不能立刻释放),这个释放可以理解成free释放。上面undo log中的版本链是用于版本控制的,而回滚操作不是将这里面的数据覆盖式回滚,而是在undo log中记录相反的sql。
补充1 delete和insert如何保存历史版本?
delete就是直接保存一份数据到undo log中。
insert没有历史版本,undo log不会形成版本链,但是还要存放一些信息用于回滚操作,也就是一句相反的sql语句。
补充2 select是查看历史数据还是最新的数据?
如果读历史版本,这就说明了事务结束,版本不一定能删除,要等select读完,所以上面说版本不一定在事务提交后立刻释放。当前读:就是读最新的数据,增删改都叫当前读,因为增删改只能对当前数据进行操作,不能修改历史版本信息,下面就是select当前读,正常的select都是读历史版本,又叫快照读。

快照读就是查看历史版本。所以为什么rc,rr读写能并发,就是因为读是读历史数据,而写是修改最新的,读写是不同位置,当然可以不加锁并发执行。
补充3 那select什么时候当前读,什么时候快照读呢? 快照读又应该读哪个历史版本?
我们先前说隔离性是防止事务被干扰,而在多版本控制下,防止被干扰就是让它们看到不同的版本信息,事务已经有先后的概念了,那一个事务来了,肯定可以看到undo log先前事务修改的版本数据(因为我们的事务执行是要时间的,那就一定会有新的事务来,它可能也会对数据做修改,然后在undo log中产生历史版本),并行的和未来的事务产生的版本我们认为看不到,这样我们的事务运行就看不到后续事务产生的版本,也就不会被干扰,这就是隔离性。显然select默认就是快照读,因为快照读具有隔离性。
但是如何让不同的事务看到不同的内容,应该看到哪个版本,由read view决定。
4 read view
read view就是一个类,mysqld处理事务时,往往会在服务端创建这个快照类对象。 undo log里面有不同的版本数据,所有事务对这些版本都有自己的可见性,不是所有版本的数据都能看见,而read view就是用来描述事务的可见性的, 这个可见性为隔离性服务的,当事务看到的是不同版本的数据,本质就实现了一种隔离。
当我们的事务执行快照读的时候就会创建read view 结构体(不是事务一来就创建),就会初始化这个结构体。接下来介绍read view的成员,最重要的就下面四个字段。

1 m_ids
当事务快照读的时候,此时会用该对象保存并行事务的id。
2 low_limit_id
记录还未分配的下一个事务id,当大于等于这个id值,都能说明这些事务对于当前事务来说是未来的事务。
3 up_limit_id
这个是m_ids列表中的最小值,我们可以用这个值表明提交事务的id,小于这个id值的事务一定是已经提交了的,因为事务是先后到来的,如果一个事务的id比m_ids中的最小值还小,这说明它比这些并行事务还早来,那么就一定处于并行或者提交状态,不在列表里就只能是提交了。
为什么low_limit_id不是m_mids中的最大值,这并不能表示未来的事务,例如当前事务id是4,m_mids记录了2,3,后来的5,6事务提前跑完了,此时我们发现low记录成4就有问题。
我们知道版本链条中每个版本都记录了事务id,表明是被某个事务修改的,而根据上面分析我们知道哪些事务id对我来说是未来的事务,哪些是并行的,哪些是已经提交的,那我们遍历版本链,我们就能找到一个最新的而且是已提交事务产生的版本,这就是解决了脏读问题。这个版本就代替了最新的数据被事务看到,我们的事务就看不到最新的数据,就不会被干扰。
可见性判断样例:
假设来了11,12,13,14,15五个事务,然后12,14事务提交了,此时我们启动事务进行快照读,11,13,15就是并行的事务,用m_ids记录。up_limit_id记录的就是11,只有提交了的才能看到(因为隔离性,看到未提交的,或者是后续的事务的数据,这就说明事务被干扰了),我们由上面推理得出11之前的都提交了,所以遇到版本是由小于11的事务或者事务id小于up_limit_id,大于up_limit_id,然后又不在m_mids列表中的都是已经提交的事务,这些事务产生的版本都可读取,如果是由自己修改的,那也可以读取,这就是rc和rr为什么只能看到提交后的事务的原因。
5 read view 实验
假设有如下记录,然后有四个事务在运行。
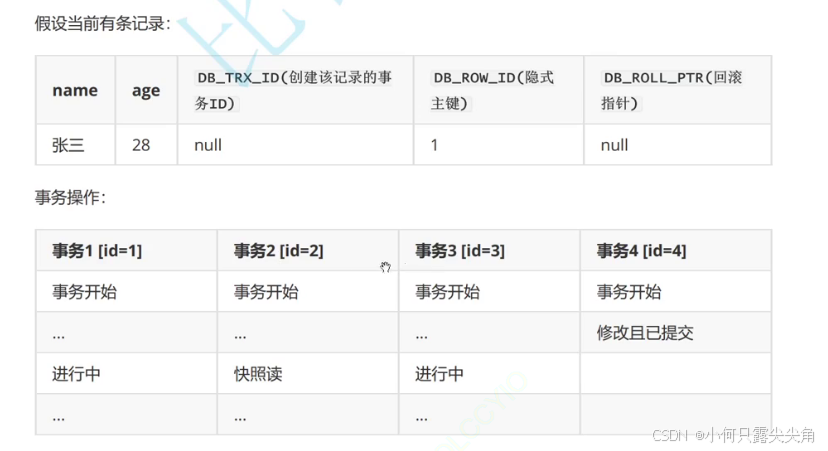
事务2开始快照读,也就是创建read view结构体,事务4将name张三改成李四,且已经提交了,而事务1,3还在并行。
生成的read view应该如下图。

m_ids记录了并行事务id,up_limit_id也就是1了,而low_limit_id就认为是5,因为此时我们就认为四是最后一个事务,所以5是尚未分配的下一个事务id。
版本如下,name为李四的是最新的行,指向历史版本,接下来看看事务2应该看到哪个版本。

开始遍历版本链,先遍历最新的数据,发现对该数据修改的事务是4,4 > up_limit_id,这个条件不满足还不能说明事务还未提交,然后和low_limit_id比较,小于5,说明这个版本不是未来事务形成的,但是还要看看事务是否已经提交,就是看在不在m_ids表中,在就说明是活跃的事务,不在就说明已经提交了,可以看到就返回了,如果不能看到就要继续去undo log找下一条数据进行判断,显然是返回最先遇到的且可看到的数据。
不过为什么是最先遇到的呢,因为有多个事务可以对该行形成版本,这个版本也有新旧顺序,可见性判断中我们的事务可以看到多个版本,当然应该返回事务能看到的所有版本中最新的,如果返回老的,那就加重数据不一致了。
前面提及过read view并非是创建事务形成的,而是select快照读才创建的,而这个read view的更新在下面两种隔离级别表现不一样。
6 rc和rr区别
一般select 都是快照读,但是显然这个快照读在各个隔离级别上表现不一样?,本质是read view的更新次数不一样。
![]()
级别设为可重复读,这个设置可以看前面,设置全局,然后重启会话,初始化会话的隔离级别,表现是: 多次select结果不变,哪怕用另一个事务在修改,提交后,也不会影响我当前事务的select读取结果。

表设计如下。
表中原始数据如下。
事务a,b开启快照读,此时read view结构体就被创建了。
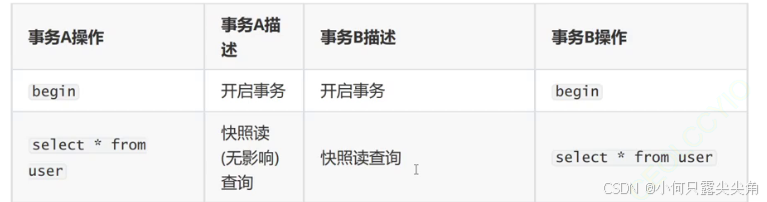
因为事务a改了数据,就一定会在undo log形成版本链。

当我们不是快照读的时候,就能读到最新数据,显然可重复读结果不变,说得是重复快照读,而不是重复当前读保持不变。
而为什么事务b快照读看不到也很正常,新的版本是并行事务产生的,自己在创建read view时将事务a列入了并行事务,所以看不到修改。
案例2
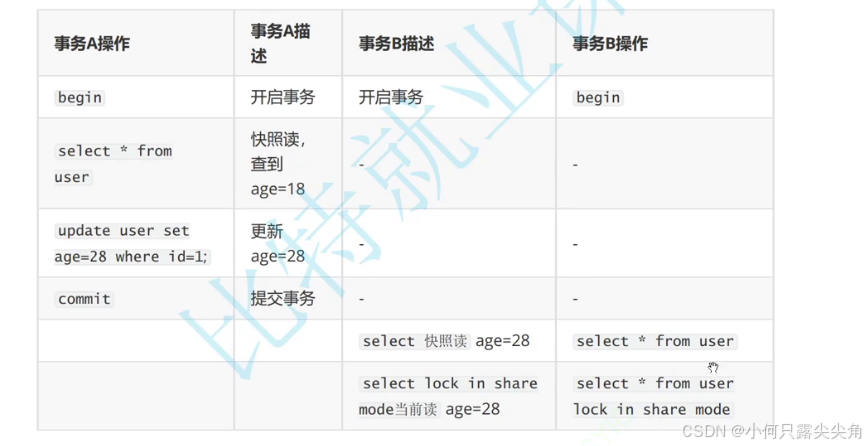
事务b在事务a修改时并没有调用select,此时它就还没生成版本快照,当事务a提交后,再调用select生成版本快照,此时事务a在read view中就会被认定为是已经提交的事务,可以读取,所以我们发现在rr级别下read view创建的时机会导致显示的不同,这也回答了隔离级别演示时提到的问题。
rc级别下:
rr级别只有一个read view,而且不更新,一直用第一次select创建的read view,所以事务a只要被列入并行事务,那事务b就一直认为事务a是并行的,rc级别也只有一个read view,但是每次select就更新。
所以读提交(rc)可以一直看到别人提交后更新的数据,就是因为我们一直在更新read view,可以一直将提交的事务纳入到可读取的事务列之中,导致我们能一直看到别人提交后的结果。所以rc是不可重复读的,因为每次结果会不同。这个多版本控制(mvcc): 使得读写可以不加锁并发,因为访问的是不同的位置,不同的版本数据。


















 946
946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











