







一.什么是ProtoBuf
特点:ProtoBuf是用于序列化和反序列化的一种方法,类似xml和json,但是效率更高,体积更小。ProtoBuf具有语⾔⽆关、平台⽆关,扩展性、兼容性好等特点。
ProtoBuf是需要依赖通过编译生成的头文件和源文件来使用的。也就是说他需要参与到编译链接的过程中。
使用方法简单来说,我们之需要写一个包含待处理数据的message,就可以通过protoc编译器编译.proto文件自动生成接口,在后续业务逻辑中我们直接使用这些接口即可。
二.形成proto文件
在protobuf里面定义的结构化对象叫message,在这个结构化对象中定义其对应的属性内容。在这里我们使用proto3语法,需要手动指定。同时指定包(类比命名空间)。
定义消息字段:字段类型+字段名=字段唯⼀编号。
这里的字段类型和c++一致(在类型后面带上位数)。字段唯⼀编号是⽤来标识字段,⼀旦开始使⽤就不能够再改变。但注意,这里有可能存在变长编码,变⻓编码是指:经过protobuf编码后,原本4字节或8字节的数可能会被变为其他字节数。
通过以上知识就能得到如下用例。
syntax = "proto3"; //指定语法
package contacts; //命名空间
message StudentInfo
{
string name = 1; // 姓名
int age = 2; // 年龄
}字段唯⼀编号的范围:1~536,870,911(2^29-1),其中19000~19999不可⽤。范围为1~15的字段编号需要⼀个字节进⾏编码,16~2047内的数字需要两个字节进⾏编码。编码后的字节不仅只包含了编号,还包含了字段类型。1~15要⽤来标记出现⾮常频繁的字段。
接下来编译生成C++文件
编译命令格式:protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.proto
【】内可以省略
在这里就可以是protoc --cpp_out=. contacts.proto
编译后⽣成了两个⽂件: contacts.pb.h contacts.pb.cc,
对于编译⽣成的C++代码,包含了以下内容:
- 对于每个message,都会⽣成⼀个对应的消息类。
- 在消息类中,编译器为每个字段提供了获取和设置⽅法
- 编辑器会针对于每个.proto ⽂件⽣成 .h 和 .cc ⽂件,分别⽤来存放类的声明与类的实现
这样就能得到基本的操作接口,类似这种
接下来就可以使用序列化和反序列化了在消息类的⽗类中能找到MessageLite,这里提供了序列化反序列化的接口。
//序列化:
bool SerializeToOstream(ostream* output) const; // 将序列化后数据写⼊⽂件
流
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input); // 从流中读取数据,再进⾏反序列化
动作
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);这样就能把数据结构转换为二进制结构。详情可参考protobuf官网。这样就能实现从序列化到反序列的整体逻辑,注意在编译的时候要告知编译器所使用的库名称。
三.详细语法
一.字段规则
- singular:消息中可以包含该字段零次或⼀次(不超过⼀次)。proto3语法中,字段默认使⽤该规则
- repeated:消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理解为定义了⼀个数组
syntax = "proto3"; package contacts; message StudentInfo { string name = 1; int32 age = 2; repeated string phone_numbers = 3; //能有多个电话 }
二.使用消息字段
proto里的消息体是可以重复嵌套的。
同时消息类型是可以充当字段来使用的。
syntax = "proto3";
package contacts;
message StudentInfo
{
string name = 1;
int32 age = 2;
message Phone
{
string number = 1;
}
repeated Phone phone = 3;
}
我们也可以在一个proto内部导入其他proto的消息类型
//使用 import 导入其他类型的proto文件
import "phone.proto";
// 引⼊的⽂件声明了package,使⽤消息时,需要⽤ ‘命名空间.消息类型’ 格式
message test
{
phone.Phone phone = 1;
}注意在使用api对消息类型进行赋值的时候有两个接口,mutable_⽅法,返回值为消息类型的指针,这类方法会为我们开辟好空间,可以直接对这块空间的内容进⾏修改。或用 set_allocated_这个函数需要手动传入一个你自己开辟好的空间。
三.enum 类型
要注意枚举类型的定义有以下几种规则:
1. 0值常量必须存在,且要作为第⼀个元素。这是为了与proto2的语义兼容:第⼀个元素作为默认
值,且值为0。
2. 枚举类型可以在消息外定义,也可以在消息体内定义(嵌套)。
3. 枚举的常量值在32位整数的范围内。但因负值⽆效因⽽不建议使⽤(与编码规则有关)
同时具有相同枚举值名称不能出现在同一级别下。同级(同层)的枚举类型,各个枚举类型中的常量不能重名。
• 单个.proto⽂件下,最外层枚举类型和嵌套枚举类型,不算同级。
• 多个.proto⽂件下,若⼀个⽂件引⼊了其他⽂件,且每个⽂件都未声明package,每个proto⽂
件中的枚举类型都在最外层,算同级。
• 多个.proto⽂件下,若⼀个⽂件引⼊了其他⽂件,且每个⽂件都声明了package,不算同级。
在使用枚举类型的时候使用诸如set_,或者type,用来设置和获取枚举类型
四.Any类型
Any类型可以看成c++的auto泛型类型,使⽤时可以在Any中存储任意消息类型,Any类
型的字段也⽤repeated来修饰。注意在使用的时候引入any.proto
import "google/protobuf/any.proto";
message test
{
google.protobuf.Any data = 1;
}对于any类型来说,设置方法可以用mutable方法修改。
any类型可以和普通类型之间可以互相转换,使用PackFrom() 方法可以将任意消息类型转为 Any 类型。使⽤ UnpackTo() ⽅法可以将 Any 类型转回之前设置的任意消息类型。使用 Is() 方法可以⽤来判断存放的消息类型是否为 typename T。
五.oneof类型
表示这其中的字段同时只有一个字段会被设置。同时oneof里不能设置repeated,若是在oneof里多次设置,则会保留最后一次设置字段属性,可以用诸如_case方法获取设置了哪一个字段
六.map类型
可以类比c++中的map类型
map<key_type, value_type> map_field = N;注意key值不能是float或者double.使用map方法也用mutable方法进行设置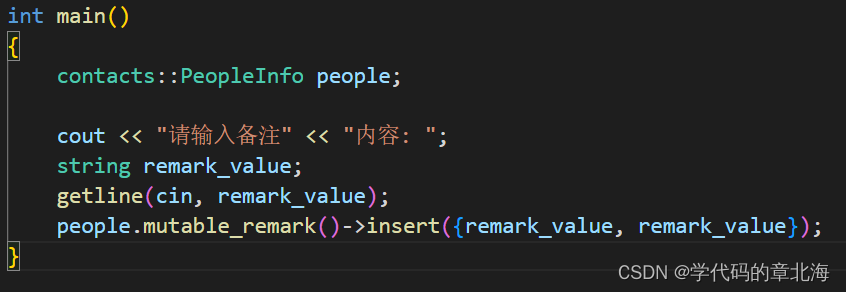
四.语法的细节处理
- 对于字符串,默认值为空字符串。
- 对于字节,默认值为空字节。
- 对于布尔值,默认值为false。
- 对于数值类型,默认值为0。、
- 对于枚举,默认值是第⼀个定义的枚举值,必须为0。
- 于设置了repeated的字段的默认值是空的(通常是相应语⾔的⼀个空列表)
- 对于 消息字段 、 oneof字段 和 any字段 ,C++和Java语⾔中都有has_⽅法来检测当前字段
是否被设置
更新消息字段:
- 禁⽌修改任何已有字段的字段编号。
- 若是移除⽼字段,要保证不再使⽤移除字段的字段编号。正确的做法是保留字段编号(reserved),以确保该编号将不能被重复使⽤。不建议直接删除或注释掉字段。
- int32,uint32,int64,uint64和bool是完全兼容的。可以从这些类型中的⼀个改为另⼀个,⽽不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,会采⽤与C++⼀致的处理⽅案(例如,若将64位整数当做32位进⾏读取,它将被截断为32位)。
- sint32和sint64相互兼容但不与其他的整型兼容。
- string和bytes在合法UTF-8字节前提下也是兼容的。
- fixed32与sfixed32兼容,fixed64与sfixed64兼容。
- oneof:
◦ 将⼀个单独的值更改为新oneof类型成员之⼀是安全和⼆进制兼容的。
◦ 若确定没有代码⼀次性设置多个值那么将多个字段移⼊⼀个新oneof类型也是可⾏的。
◦ 将任何字段移⼊已存在的oneof类型是不安全的。
如果删除一个字段后用新的字段占据了这个编号,在反序列化的时候就会解析出错误的信息。
若是新设置了字段,但却仍然使用就的方法序列化的话,新增的字段在旧程序中其实并没有丢失,⽽是会作为旧程序的未知字段。
未知字段:
在了解未知字段之前先需要知道一下protobuf之间不同类的关系。
MessageLite仅仅提供序列化、反序列化功能,跟message属于同一个层级,是message类的拓展。
Descriptor类是描述和管理message属性的类,是message类的下层。
Reflection主要提供了动态读写消息字段的接⼝,对消息对象的⾃动读写主要通过该类完成。提供⽅法来动态访问/修改message中的字段,对每种类型,Reflection都提供了⼀个单独的接⼝⽤于读写字段对应的值。类中还包含了访问/修改未知字段的⽅法。是message类的下层
UnknownFieldSet类
包含在分析消息时遇到但未由其类型定义的所有字段。是Reflection类的下层
UnknownField类
表⽰未知字段集中的⼀个字段,是UnknownFieldSet的下层。这里是未知字段的类型
enum Type {
TYPE_VARINT,
TYPE_FIXED32,
TYPE_FIXED64,
TYPE_LENGTH_DELIMITED,
TYPE_GROUP
};
当我们想拿到未知字段需要一层一层获取它的上层对象
//这里以people的字段为例
const Reflection* reflection = PeopleInfo::GetReflection();
const UnknownFieldSet& unknowSet = reflection->GetUnknownFields(people);
for (int j = 0; j < unknowSet.field_count(); j++)
{
const UnknownField& unknow_field = unknowSet.field(j);
}五.选项option
.proto⽂件中可以声明许多选项,使⽤option 标注。选项能影响proto编译器的某些处理⽅式。
常用选项列举
optimize_for:
该选项为文件选项,可以设置protoc编译器的优化级别,分别为SPEED 、
CODE_SIZE 、 LITE_RUNTIME 。受该选项影响,设置不同的优化级别,编译.proto⽂件后⽣
成的代码内容不同
SPEED :protoc编译器将⽣成的代码是⾼度优化的,代码运⾏效率⾼,但是由此⽣成的代码编译后会占⽤更多的空间。 SPEED 是默认选项
CODE_SIZE :proto编译器将⽣成最少的类,会占⽤更少的空间,是依赖基于反射的代码来
实现序列化、反序列化和各种其他操作。但和 SPEED 恰恰相反,它的代码运⾏效率较低。这
种⽅式适合⽤在包含⼤量的.proto⽂件,但并不盲⽬追求速度的应⽤中。
LITE_RUNTIME :⽣成的代码执⾏效率⾼,同时⽣成代码编译后的所占⽤的空间也是⾮常
少。这是以牺牲ProtocolBuffer提供的反射功能为代价的,仅仅提供encoding+序列化功能,
所以我们在链接库时仅需链接libprotobuf-lite,⽽⾮libprotobuf。这种模式通常⽤于资源
有限的平台,例如移动⼿机平台中
option optimize_for = SPEED;
allow_alias:
允许将相同的常量值分配给不同的枚举常量,⽤来定义别名。该选项为枚举选项。
enum TestType
{
option allow_alias = true;
test1 = 0;
test2= 1;
test3 = 1; // 若不加 option allow_alias = true; 这⼀⾏会编译报错
}

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









