







优先队列 是一种抽象的数据类型,而 堆 是一种数据结构。
堆 是实现 优先队列 的一种方式。
实现 优先队列 的方式有很多种,比如数组和链表。
但是,这些实现方式只能保证插入操作和删除操作中的一种操作可以在 O(1)的时间复杂度内完成,而另外一个操作则需要在 O(N) 的时间复杂度内完成。
而 堆 能够使 优先队列 的插入操作在 O(logN) 的时间复杂度内完成,删除操作在 O(logN)的时间复杂度内完成。
堆 是一种特别的二叉树,满足以下条件的二叉树,可以称之为 堆:
1.完全二叉树;
2. 每一个节点的值都必须 >=或者<= 其孩子节点的值。
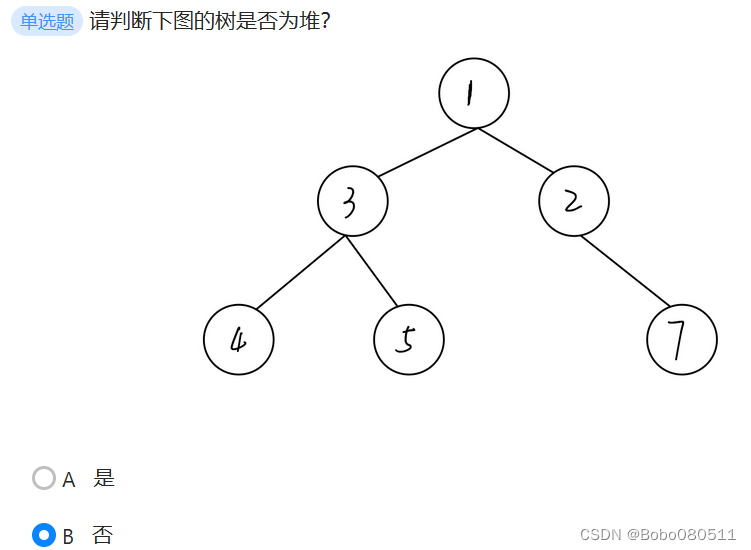
虽然所有节点都比孩子节点的值小,但它不是一个完全二叉树。
堆 具有以下的特点:
1.可以在 O(logN)的时间复杂度内向 堆 中插入元素;
2.可以在 O(logN)的时间复杂度内向 堆 中删除元素;
3.可以在 O(1)的时间复杂度内获取 堆 中的最大值或最小值。
堆 有两种类型:大根堆 和 小根堆。
大根堆:堆中每一个节点的值 都大于等于 其孩子节点的值。堆顶元素(根节点)是堆中的最大值。
小根堆:堆中每一个节点的值 都小于等于 其孩子节点的值。堆顶元素(根节点)是堆中的最小值。
插入操作 是指向 堆 中插入一个元素。元素插入之后,堆 依旧需要维持它的特性。
删除操作 是指在 堆 中删除堆顶元素。元素删除之后,堆 依旧需要维持它的特性。
在堆的数据结构中,常用堆的插入、删除、获取堆顶元素的操作。
可以用数组实现堆,将堆中的元素以二叉树的形式存入在数组中。
堆 在大部分编程语言中,都已经有内置方法实现它。在实际解题或者工作中,一般很少需要自己去实现堆。
堆的常用方法:
创建 堆 指的是初始化一个堆实例。所有堆方法的前提必须是在堆实例上进行操作。
堆化 就是将一组数据变成 堆 的过程。
C++的STL提供了make_heap()、push_heap、pop_heap、sort_heap等算法,它们用来将一个随机存储的数组或者容器等转换为一个heap。
构造:make_heap 的功能是将一段现有的数据转化成一个堆,默认情况下生成的是一个大堆。想实现小堆转化时,首先要#include <functional>,然后参数中使用great<int>()。需要注意的是当make_heap中使用了greater()后,后面pop_heap、push_heap和sort_heap都需要加上greater()。
插入:push_heap 的功能是往堆中插入一个数据。STL库提供的push_heap算法没有插入元素,仅仅是完成插入元素后的调整工作,将插入元素后的区间恢复成堆结构。需要注意,当一次性插入多个数据然后再调用push_heap进行调整的时候,除最后插入的数据之外的其他前面插入的数据必须保证和已有数据依然能够构成堆结构,因为push_heap只是对左闭右开区间的最后一个数据进行调整,并且认为前面的数据已经满足堆结构,所以如何前面插入的数据不能保证堆结构的话就会报错。
删除:pop_heap 的功能也是实现调整工作,但是是删除前的调整。pop_head会将堆顶的元素与最后一个元素(注意最后一个元素是last的上一个元素)交换,然后再调整,将除了最后一个元素的剩余其他元素重新恢复成堆结构。需要注意的是每次pop一个元素后,下一次pop时就需要将区间缩小1(last减1)。
排序:sort_heap 的功能就相当于多次调用pop_heap,每次调用pop_heap都将堆顶元素与最后元素进行交换(将堆中最大元素与堆中最后一个元素交换),然后last减1,重复调用heap_pop一直到只剩下1个元素,就实现了将元素排序。
//构造一个堆(最大堆)
int myints[] = {10,20,30,5,15};
std::vector<int> v(myints,myints+5);
//获取堆顶元素
std::make_heap (v.begin(),v.end());
std::cout << "initial max heap : " << v.front() << '\n';
//插入元素
v.push_back(99); std::push_heap (v.begin(),v.end());
std::cout << "max heap after push: " << v.front() << '\n';
//删除元素
std::pop_heap (v.begin(),v.end()); v.pop_back();
std::cout << "max heap after pop : " << v.front() << '\n';
//获取堆的长度
v.size();堆的应用:
1.优先队列:
首先要包含头文件 #include<queue>, 他和queue不同的就在于可以自定义其中数据的优先级, 让优先级高的排在队列前面,优先出队。
优先队列具有队列的所有特性,包括队列的基本操作(
- top 访问队头元素 队列取队首元素用的是front函数,而优先队列用的是top函数.
- empty 队列是否为空
- size 返回队列内元素个数
- push 插入元素到队尾 (并排序)
- emplace 原地构造一个元素并插入队列
- pop 弹出队头元素
- swap 交换内容
),只是在这基础上添加了内部的一个排序,它本质是一个堆实现的。
priority_queue<Type(数据类型), Container(数组实现的容器), Functional(比较函数)>;
//greater和less是std实现的两个仿函数 (就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了)
priority_queue<int, vector<int>, greater<int>(小顶堆)>q;
priority_queue<int, vector<int>, less<int>(大顶堆)>q;
priority_queue<int>a;默认大顶堆
priority_queue<pair<int,int>>a;
2.堆排序:利用堆的数据结构对一组无序元素进行排序。
小根堆 排序算法步骤如下:
- 将所有元素堆化成一个 小根堆 ;
- 取出并删除堆顶元素,并将该堆顶元素放置在存储有序元素的数据集 T 中;
- 此时,堆 会调整成新的 最小堆;
- 重复 3 和 4 步骤,直到 堆 中没有元素;
- 此时得到一个新的数据集 T,其中的元素按照 从小到大 的顺序排列。
最大堆 排序算法步骤如下:
- 将所有元素堆化成一个 最大堆;
- 取出并删除堆顶元素,并将该堆顶元素放置在存储有序元素的数据集 T 中;
- 此时,堆 会调整成新的 最大堆;
- 重复 3 和 4 步骤,直到 堆 中没有元素;
- 此时得到一个新的数据集 T,其中的元素按照从大到小的顺序排列。
时间复杂度:O(NlogN)。N是 堆 中的元素个数。
空间复杂度:O(N)。N是 堆 中的元素个数。
用堆解题:
1.Top K 大/小的元素:
解法1:
- 创建一个「大/小根堆」;
- 将所有元素都加到「大/小根堆」中;
- 通过 「边删除边遍历」 方法,将堆顶元素删除,并将它保存到结果集 T 中;
- 重复 3 步骤 K 次,直到取出前 K 个最大/小的元素;
时间复杂度: O(KlogN)
空间复杂度:O(N)
解法二:
- 创建一个大小为 K 的「小/大根堆」;
- 依次将元素添加到「小/大堆」中;
- 当「小/大堆」的元素个数达到 K 时,将当前元素与堆顶元素进行对比:如果当前元素小于/大于堆顶元素,则放弃当前元素,继续进行下一个元素;如果当前元素大于/小于堆顶元素,则删除堆顶元素,将当前元素加入到「小/大根堆」中。
- 重复步骤 2 和步骤 3,直到所有元素遍历完毕。
- 此时「小/大堆」中的 K 个元素就是前 K 个最大/小的元素。
时间复杂度: O(NlogK)
空间复杂度:O(K)
2.The Kth 大/小元素。(同上,最后记录即可)

















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









