







提示:本文介绍时间序列预测Transformer模型的计算过程和代码实现
文章目录
以下将按照代码的执行顺序拆解模型:
一、总的处理顺序
def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
# Embedding
enc_out = self.enc_embedding(x_enc, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
dec_out = self.dec_embedding(x_dec, x_mark_dec)
dec_out = self.decoder(dec_out, enc_out, x_mask=None, cross_mask=None)
return dec_out
以ETT数据集为例,输入及其含义:
- x_enc
{Tensor:(32,96,7)}:batch_size,seq_len, enc_in - x_dec
{Tensor:(32,144,7)}:batch_size,seq_len + label_len, dec_in - x_mark_enc
{Tensor:(32,96,4)}
x_mark_enc 是与编码输入数据 x_enc 相关的时间特征标记。它的主要作用是提供有关时间序列数据的时间信息,包括月份(month)、日期(day)、星期(weekday)、小时(hour)四个维度的信息。 - x_mark_dec
{Tensor:(32,144,4)}
x_mark_enc 是与编码输入数据 x_dec 相关的时间特征标记,同样包括月份(month)、日期(day)、星期(weekday)、小时(hour)四个维度的信息。
二、embedding
代码实现
# 在“Trasformer”文件中的定义
self.enc_embedding = DataEmbedding(configs.enc_in, configs.d_model, configs.embed, configs.freq,
configs.dropout)
self.dec_embedding = DataEmbedding(configs.dec_in, configs.d_model, configs.embed, configs.freq,
configs.dropout)
# configs.d_model: 输出的维度
# configs.embed: embed的方式,包括 timeF, fixed, learned 三种
# 在“Embed”文件中的定义
class DataEmbedding(nn.Module):
def __init__(self, c_in, d_model, embed_type='fixed', freq='h', dropout=0.1):
super(DataEmbedding, self).__init__()
self.value_embedding = TokenEmbedding(c_in=c_in, d_model=d_model)
self.position_embedding = PositionalEmbedding(d_model=d_model)
self.temporal_embedding = TemporalEmbedding(d_model=d_model, embed_type=embed_type,
freq=freq) if embed_type != 'timeF' else TimeFeatureEmbedding(
d_model=d_model, embed_type=embed_type, freq=freq)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, x_mark):
if x_mark is None:
x = self.value_embedding(x) + self.position_embedding(x)
else:
x = self.value_embedding(
x) + self.temporal_embedding(x_mark) + self.position_embedding(x)
return self.dropout(x)
在时间序列预测中,value_embedding、position_embedding和temporal_embedding是三种重要的嵌入技术,它们分别用于编码序列数据中的数值、位置和时间信息
1.Value Embedding(数值嵌入)
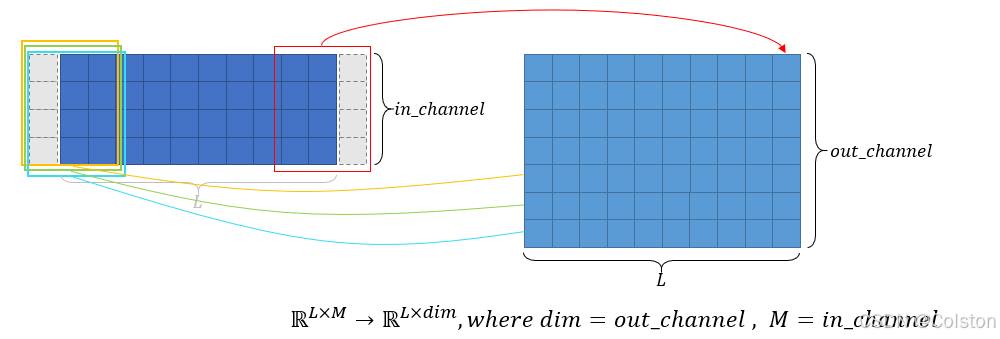
将序列数据中的每个元素映射到一个低维度的连续向量表示。这种向量表示被称为嵌入向量(embedding vector)。value_embedding通过一维卷积实现,扩充输入的维度。
下图是将输入特征M维➡dim维的示意图
代码实现
# value_embedding
class TokenEmbedding(nn.Module):
def __init__(self, c_in, d_model):
super(TokenEmbedding, self).__init__()
padding = 1 if torch.__version__ >= '1.5.0' else 2
self.tokenConv = nn.Conv1d(in_channels=c_in, out_channels=d_model,
kernel_size=3, padding=padding, padding_mode='circular', bias=False)
for m in self.modules():
if isinstance(m, nn.Conv1d):
nn.init.kaiming_normal_(
m.weight, mode='fan_in', nonlinearity='leaky_relu')
def forward(self, x):
x = self.tokenConv(x.permute(0, 2, 1)).transpose(1, 2)
return x
2.Position Embedding(位置嵌入)
用于将序列中的每个位置信息编码为一个向量表示。具体来说,对于每个位置 ( pos ) 和每个维度 ( i ),位置编码向量 P E ( p o s , 2 i ) PE(pos, 2i) PE(pos,2i) 和 P E ( p o s , 2 i + 1 ) PE(pos, 2i+1) PE(pos,2i+1) 分别由以下公式计算
-
位置索引:
p o s i t i o n = [ 0 , 1 , 2 , … , m a x _ l e n − 1 ] position =[0,1,2, \ldots , max\_len - 1 ] position=[0,1,2,…,max_len−1]
这个序列表示序列中每个位置的索引,其中 m a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









