






 本文分享了字节跳动后端开发面试的详细过程,涵盖了HashMap扩容、Linux共享内存、TCP连接、Java GC机制、并发容器等核心技术问题,以及Redis数据结构和MySQL事务原理等。通过三轮面试,讨论了Java基础、并发编程、数据库和缓存等多个方面。
本文分享了字节跳动后端开发面试的详细过程,涵盖了HashMap扩容、Linux共享内存、TCP连接、Java GC机制、并发容器等核心技术问题,以及Redis数据结构和MySQL事务原理等。通过三轮面试,讨论了Java基础、并发编程、数据库和缓存等多个方面。

5G的到来证明了互联网行业发展一如既往的快,作为一名开发人员(Java岗)梦想自然是互联网行业的大厂,这次有幸获得面试字节跳动的机会,为此我也做出了准备在面试前一个月就开始做准备了,也很荣幸的拿到了字节跳动的offer,这里分享一份字节跳动三面过程!
字节一面:
- hashmap,怎么扩容,怎么处理数据冲突?怎么高效率的实现数据迁移?
- Linux的共享内存如何实现,大概说了一下。
- socket网络编程,说一下TCP的三次握手和四次挥手
- 同步IO和异步IO的区别?
- Java GC机制?GC Roots有哪些?
- 红黑树讲一下,五个特性,插入删除操作,时间复杂度?
- 快排的时间复杂度,最坏情况呢,最好情况呢,堆排序的时间复杂度呢,建堆的复杂度是多少
字节二面
- 自我介绍,主要讲讲做了什么和擅长什么
- 设计模式了解哪些?
- AtomicInteger怎么实现原子修改的?
- ConcurrentHashMap 在Java7和Java8中的区别?为什么Java8并发效率更好?什么情况下用HashMap,什么情况用ConcurrentHashMap?
- redis数据结构?
- redis数据淘汰机制?
字节三面
- mysql实现事务的原理(MVCC)
- MySQL数据主从同步是如何实现的?
- MySQL索引的实现,innodb的索引,b+树索引是怎么实现的,为什么用b+树做索引节点,一个节点存了多少数据,怎么规定大小,与磁盘页对应。
- 如果Redis有1亿个key,使用keys命令是否会影响线上服务?
- Redis的持久化方式,aod和rdb,具体怎么实现,追加日志和备份文件,底层实现原理的话知道么?
- 遇到最大困难是什么?怎么克服?
- 未来的规划是什么?
- 你想问我什么?
以上就字节跳动后端研发面试题,以下该面试题的部分参考答案。
金三银四跳槽季,小弟为各位大哥准备了几份面试宝典:
- 一份是技术干货《Java核心知识点整理》
- 一份是面试真题《1000道互联网Java工程师面试题》
- 面试宝典《互联网Java工程师面试题大全》
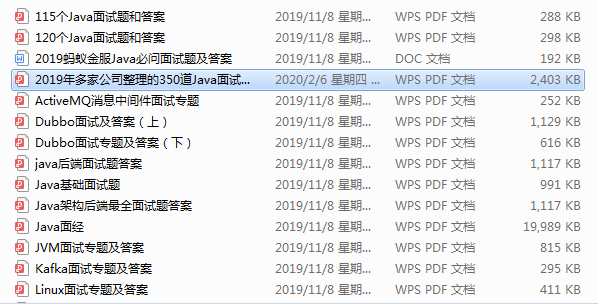
Java核心知识点整理
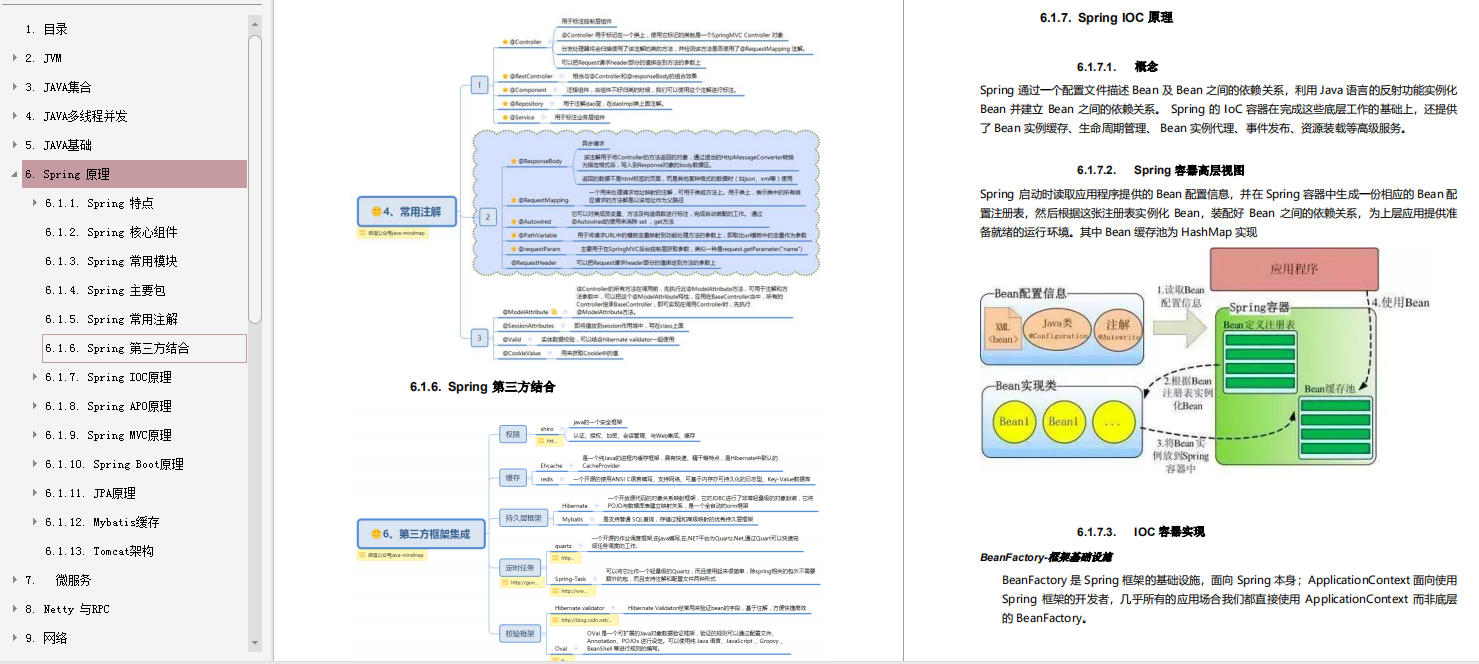
1000道互联网Java工程师面试题
互联网大厂面试宝典


















 4388
4388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









