






1. 实现ResNet34网络,在CIFAR100数据集上给出测试结果:
(1)搭建ResNet34网络:
定义ResNet的残差块,包含两个3x3卷积层,每层卷积后进行批量归一化(BN)并设置shortcut连接;定义ResNet结构,包括一个卷积层、一个批归一化层、四个残差层(多个残差块堆叠)和一个全连接层;定义ResNet34,传入参数[3, 4, 6, 3],表示每个残差层中堆叠残差块的个数。
相关代码如下:
1. # 定义基本残差块
2. class BasicBlock(nn.Module):
3. expansion = 1
4.
5. def __init__(self, in_planes, planes, stride=1):
6. super(BasicBlock, self).__init__()
7. self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
8. self.bn1 = nn.BatchNorm2d(planes)
9. self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
10. self.bn2 = nn.BatchNorm2d(planes)
11.
12. # shortcut连接
13. self.shortcut = nn.Sequential()
14. if stride != 1 or in_planes != self.expansion*planes:
15. self.shortcut = nn.Sequential(
16. nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
17. nn.BatchNorm2d(self.expansion*planes)
18. )
19.
20. def forward(self, x):
21. out = torch.relu(self.bn1(self.conv1(x)))
22. out = self.bn2(self.conv2(out))
23. out += self.shortcut(x)
24. out = torch.relu(out)
25. return out
26.
27. # 定义ResNet主体结构
28. class ResNet(nn.Module):
29. def __init__(self, block, num_blocks, num_classes=100):
30. super(ResNet, self).__init__()
31. self.in_planes = 64
32.
33. self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
34. self.bn1 = nn.BatchNorm2d(64)
35. self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
36. self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
37. self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
38. self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
39. self.linear = nn.Linear(512*block.expansion, num_classes)
40.
41. def _make_layer(self, block, planes, num_blocks, stride):
42. strides = [stride] + [1]*(num_blocks-1)
43. layers = []
44. for stride in strides:
45. layers.append(block(self.in_planes, planes, stride))
46. self.in_planes = planes * block.expansion
47. return nn.Sequential(*layers)
48.
49. def forward(self, x):
50. out = torch.relu(self.bn1(self.conv1(x)))
51. out = self.layer1(out)
52. out = self.layer2(out)
53. out = self.layer3(out)
54. out = self.layer4(out)
55. out = torch.nn.functional.avg_pool2d(out, 4)
56. out = out.view(out.size(0), -1)
57. out = self.linear(out)
58. return out
59.
60. # 构建ResNet34模型
61. def ResNet34():
62. return ResNet(BasicBlock, [3, 4, 6, 3])
(2)数据处理:
使用torchvision.datasets.CIFAR100和torch.utils.data.DataLoader进行数据集的加载。在加载时根据cifar-100数据集的均值和方差,对训练数据和测试数据做不同的transform。
相关代码如下:
1. # CIFAR-100数据集图像的均值和方差
2. CIFAR100_TRAIN_MEAN = (
3. 0.5070751592371323,
4. 0.48654887331495095,
5. 0.4409178433670343
6. )
7. CIFAR100_TRAIN_STD = (
8. 0.2673342858792401,
9. 0.2564384629170833,
10. 0.27615047132568404
11. )
12.
13. # CIFAR100数据预处理
14. transform_train = transforms.Compose([
15. transforms.RandomCrop(32, padding=4),
16. transforms.RandomHorizontalFlip(),
17. transforms.RandomRotation(15),
18. transforms.ToTensor(),
19. transforms.Normalize(CIFAR100_TRAIN_MEAN, CIFAR100_TRAIN_STD)
20. ])
21.
22. transform_test = transforms.Compose([
23. transforms.ToTensor(),
24. transforms.Normalize(CIFAR100_TRAIN_MEAN, CIFAR100_TRAIN_STD)
25. ])
26.
27. # 加载数据集
28. trainset = torchvision.datasets.CIFAR100(root='./data', train=True, download=False, transform=transform_train)
29. trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
30.
31. testset = torchvision.datasets.CIFAR100(root='./data', train=False, download=False, transform=transform_test)
32. testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=2)
(3)模型训练:
设置batch_size为128,损失函数为交叉熵损失函数,优化器为SGD并设置lr=0.1, momentum=0.9, weight_decay=5e-4。训练15轮,画出训练集和测试集上的loss和acc变化,结果如下图所示:
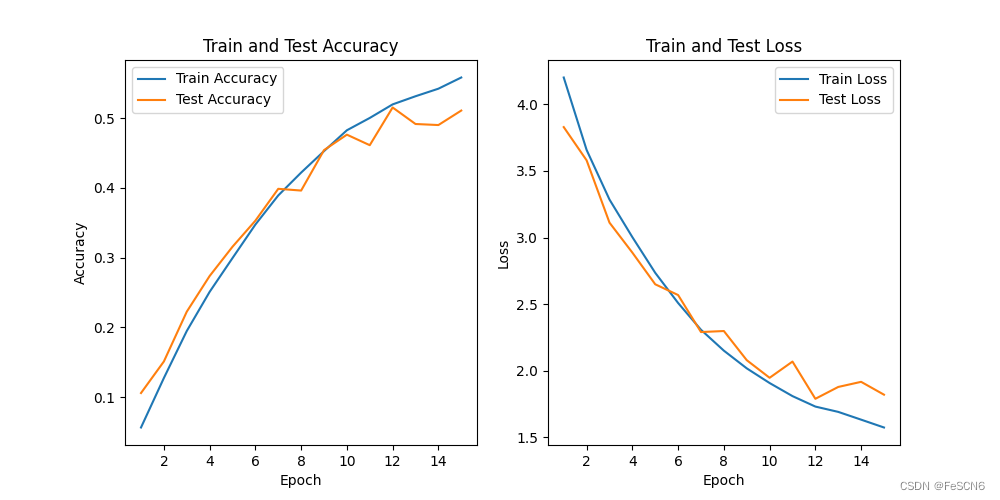
图一:ResNet34 训练集/测试集上的acc/loss(epoch=15)
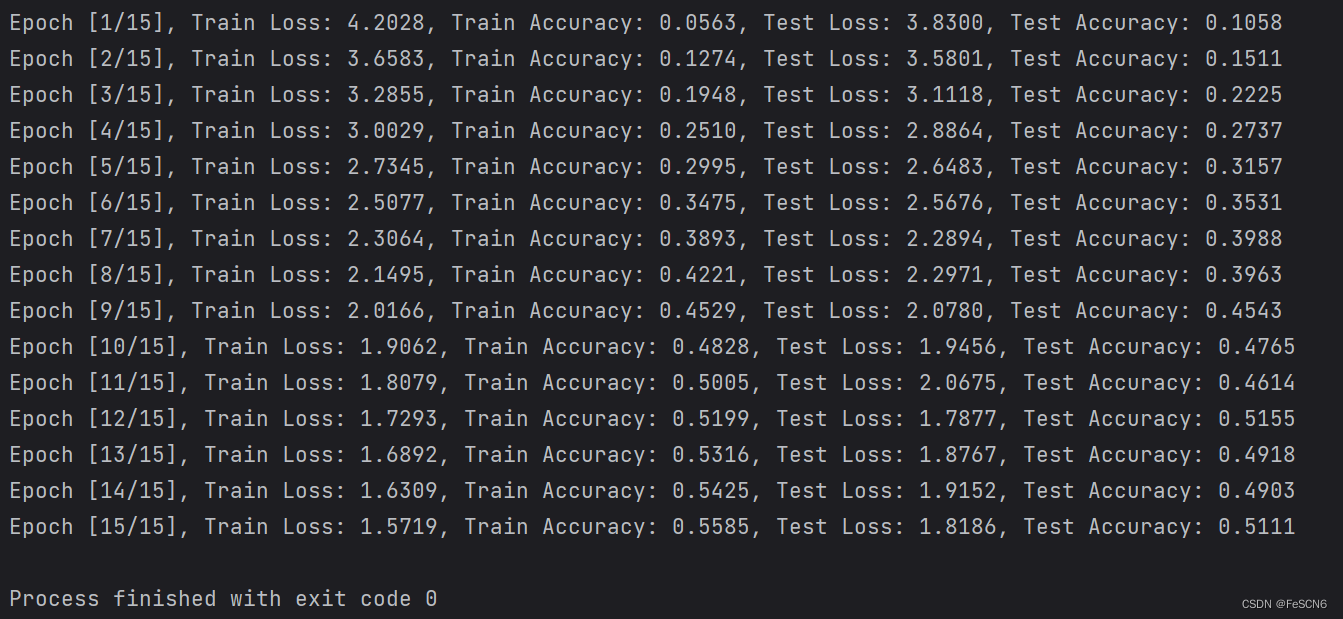
图二:ResNet34训练结果(epoch=15)
从结果来看,测试集上准确率最高达到51%,最后loss为1.8。
2. 在ResNet34网络上,删除部分层,测试网络层数对网络参数以及分类误差的影响:
在定义ResNet网络时,传入参数更改为[3, 4, 6, 2],[2, 3, 4, 2],[2, 2, 2, 2],即每次删除部分残差块获得ResNet32, ResNet26, ResNet18,训练模型并进行测试,结果分别如下:
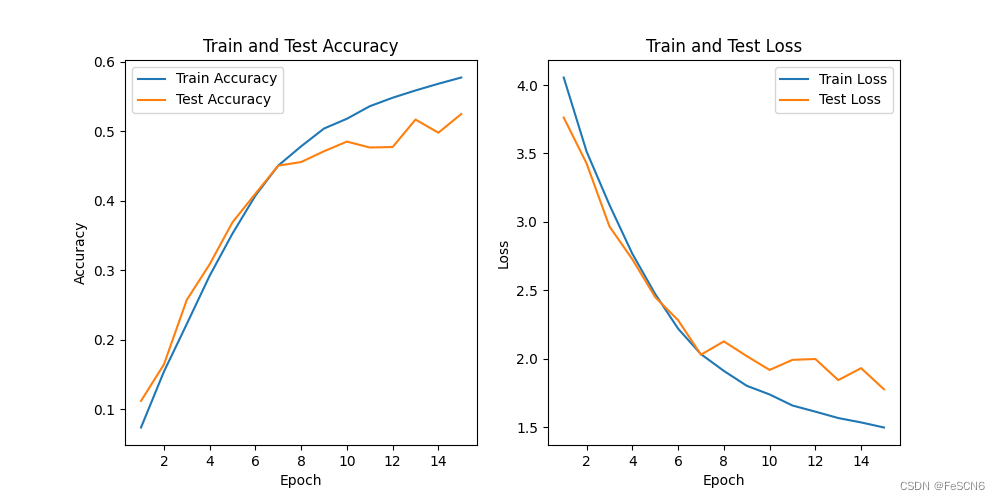
图三:ResNet32训练结果
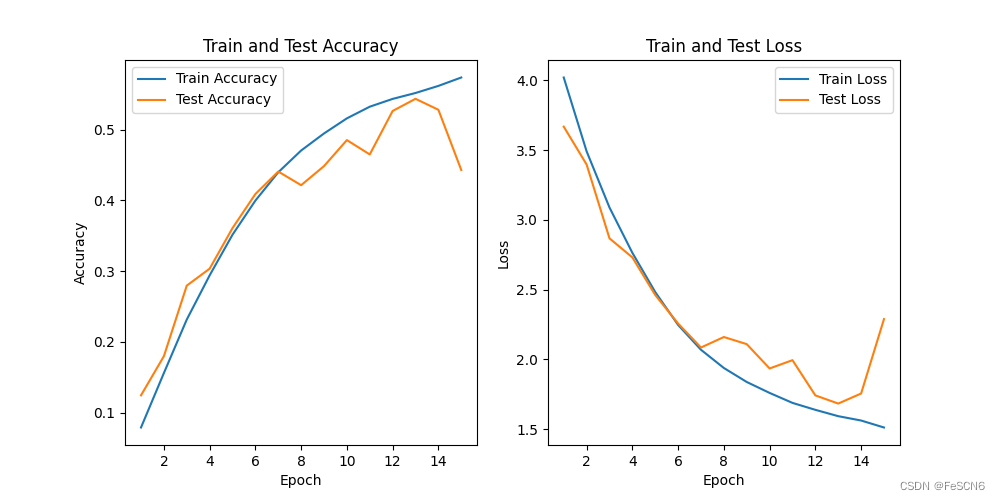
图四:ResNet26训练结果
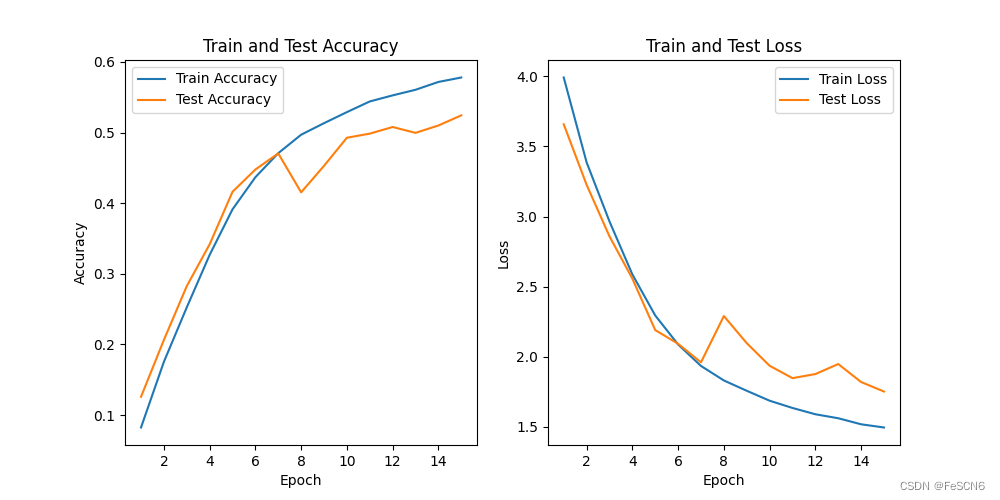
图五:ResNet18训练结果
从结果来看,随着残差块的减少,模型性能明显下降,表现为测试集上收敛效果差且准确度不高。
3. 实现SENet101网络,在CIFAR100数据集上给出测试结果:
(1)搭建SENet101网络:
SENet101网络实际上是把SE模块(全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid)插入到ResNet101中。与ResNet18和ResNet34不同,ResNet101由Bottleneck组成,相比前两种组成中分的Basicblock多了一个卷积层,最后由[3, 4, 23, 3]个Bottleneck组成。
将SE模块加入ResNet101中,选择加在Bottleneck中BatchNorm之后、shortcut之前。其余SENet101网络结构搭建和ResNet101相同。
相关代码如下:
1. # SE模块
2. # 全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
3. class SE_Block(nn.Module):
4. def __init__(self, inchannel, ratio=16):
5. super(SE_Block, self).__init__()
6. # 全局平均池化(Fsq操作)
7. self.gap = nn.AdaptiveAvgPool2d((1, 1))
8. # 两个全连接层(Fex操作)
9. self.fc = nn.Sequential(
10. nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/r
11. nn.ReLU(),
12. nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> c
13. nn.Sigmoid()
14. )
15.
16. def forward(self, x):
17. b, c, h, w = x.size()
18. # Fsq操作:经池化后输出b*c的矩阵
19. y = self.gap(x).view(b, c)
20. # Fex操作:经全连接层输出(b,c,1,1)矩阵
21. y = self.fc(y).view(b, c, 1, 1)
22. # Fscale操作:将得到的权重乘以原来的特征图x
23. return x * y.expand_as(x)
24.
25. # Bottleneck模块
26. class Bottleneck(nn.Module):
27. expansion = 4
28.
29. def __init__(self, inchannel, outchannel, stride=1):
30. super(Bottleneck, self).__init__()
31. self.conv1 = nn.Conv2d(inchannel, outchannel, kernel_size=1, bias=False)
32. self.bn1 = nn.BatchNorm2d(outchannel)
33. self.conv2 = nn.Conv2d(outchannel, outchannel, kernel_size=3,
34. stride=stride, padding=1, bias=False)
35. self.bn2 = nn.BatchNorm2d(outchannel)
36. self.conv3 = nn.Conv2d(outchannel, self.expansion * outchannel,
37. kernel_size=1, bias=False)
38. self.bn3 = nn.BatchNorm2d(self.expansion * outchannel)
39. # SE_Block放在BN之后,shortcut之前
40. self.SE = SE_Block(self.expansion * outchannel)
41.
42. self.shortcut = nn.Sequential()
43. if stride != 1 or inchannel != self.expansion * outchannel:
44. self.shortcut = nn.Sequential(
45. nn.Conv2d(inchannel, self.expansion * outchannel,
46. kernel_size=1, stride=stride, bias=False),
47. nn.BatchNorm2d(self.expansion * outchannel)
48. )
49.
50. def forward(self, x):
51. out = F.relu(self.bn1(self.conv1(x)))
52. out = F.relu(self.bn2(self.conv2(out)))
53. out = self.bn3(self.conv3(out))
54. out = self.SE(out)
55. out += self.shortcut(x)
56. out = F.relu(out)
57. return out
58.
59.
60. # 搭建SE_ResNet结构
61. class SE_ResNet(nn.Module):
62. def __init__(self, block, num_blocks, num_classes=100):
63. super(SE_ResNet, self).__init__()
64. self.in_planes = 64
65.
66. self.conv1 = nn.Conv2d(3, 64, kernel_size=3,
67. stride=1, padding=1, bias=False) # conv1
68. self.bn1 = nn.BatchNorm2d(64)
69. self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) # conv2_x
70. self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) # conv3_x
71. self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) # conv4_x
72. self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) # conv5_x
73. self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
74. self.linear = nn.Linear(512 * block.expansion, num_classes)
75.
76. def _make_layer(self, block, planes, num_blocks, stride):
77. strides = [stride] + [1] * (num_blocks - 1)
78. layers = []
79. for stride in strides:
80. layers.append(block(self.in_planes, planes, stride))
81. self.in_planes = planes * block.expansion
82. return nn.Sequential(*layers)
83.
84. def forward(self, x):
85. x = F.relu(self.bn1(self.conv1(x)))
86. x = self.layer1(x)
87. x = self.layer2(x)
88. x = self.layer3(x)
89. x = self.layer4(x)
90. x = self.avgpool(x)
91. x = torch.flatten(x, 1)
92. out = self.linear(x)
93. return out
94.
95. # 定义SENet101
96. def SEResNet101():
97. return SE_ResNet(Bottleneck, [3, 4, 23, 3])
(2)数据处理:
数据处理方式和流程与任务一相同,故不重述。
(3)模型训练:
损失函数和优化器的设置也与任务一相同。由于SENet101模型深度较大、参数量较多,自己笔记本电脑显存有限,设置batch_size=32,epoch=10。因此模型训练速度较慢,平均一轮耗时10min左右。
画出训练集和测试集上的loss和acc变化,结果如下图所示:
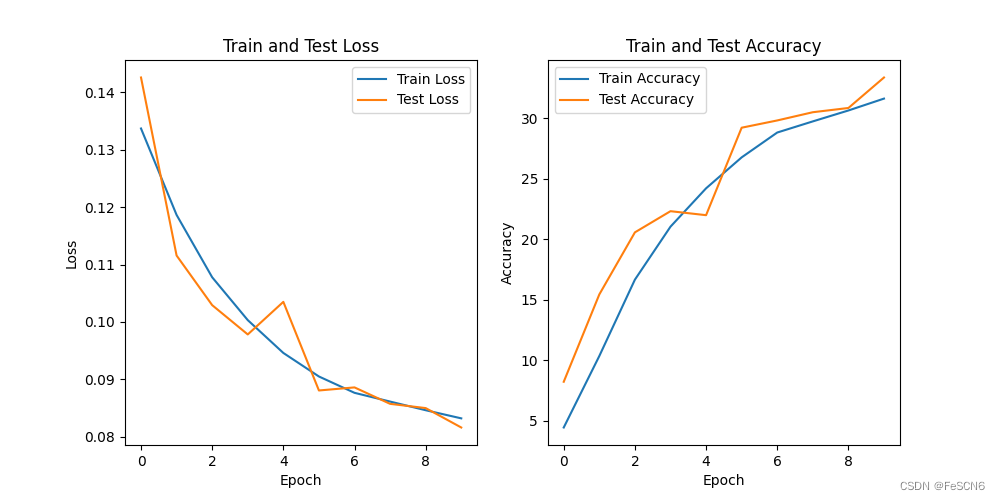
图六:SENet101 训练集/测试集上的acc/loss(epoch=10)
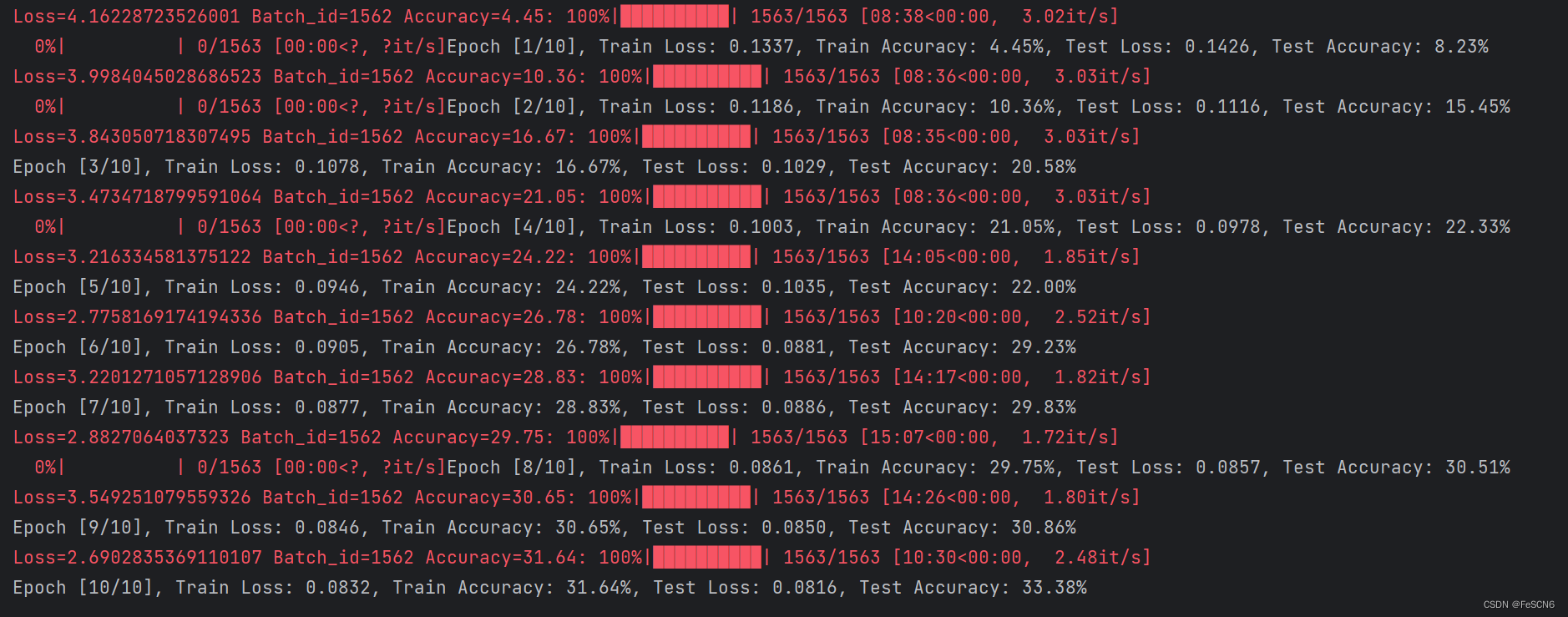
图七:SENet101训练结果
由于显存、训练时间等限制,只跑了10轮的情况,如果像论文中跑100轮可能准确度会提高很多。目前训练十轮,测试集上准确度能达到33%,并且根据1-10轮loss和acc的变化推测继续训练loss会进一步降低、acc会进一步上升。
4. 在SENet101网络上,验证通道注意力机制对模型性能的影响:
SE_Block的定义体现了注意力机制:Squeeze步骤使用全局平均池化,将每个通道的特征图汇总成一个标量,实现了压缩;Excitation步骤通过两个全连接层,将压缩后的特征向量转换为一个激活权重向量,用于表示每个通道的重要性;最后将 Excitation步骤得到的通道注意力权重乘以原始的特征图,从而得到加权后的特征表示。
为了验证通道注意力机制对模型性能的影响,删去SE模块,将SENet101和ResNet101进行对比。对上面搭建SENet101的代码仅删去调用SE_Block的部分,修改batch_size为64(这里设成64显存够用,上面SENet101只能设成32不然显存不够),其他不变。ResNet101在cifar-100数据集上训练结果如下:
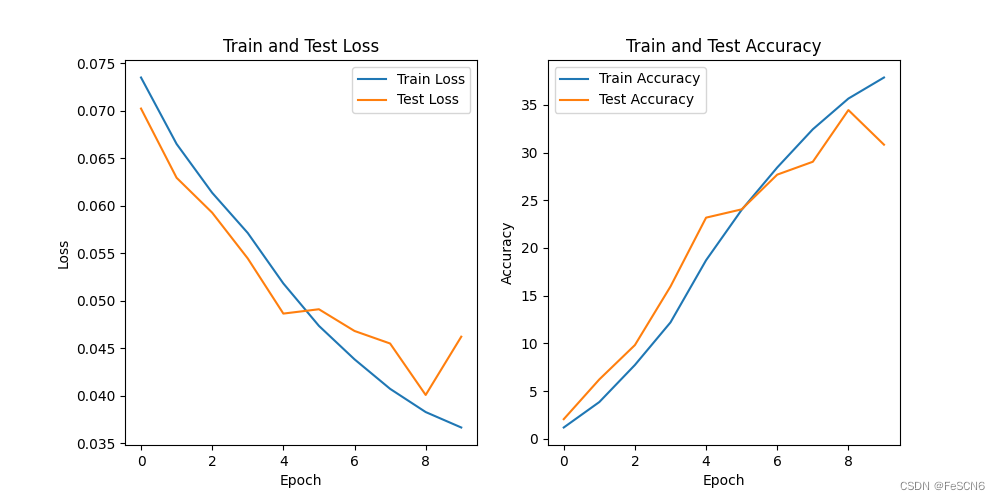
图八:ResNet101 训练集/测试集上的acc/loss(epoch=10)
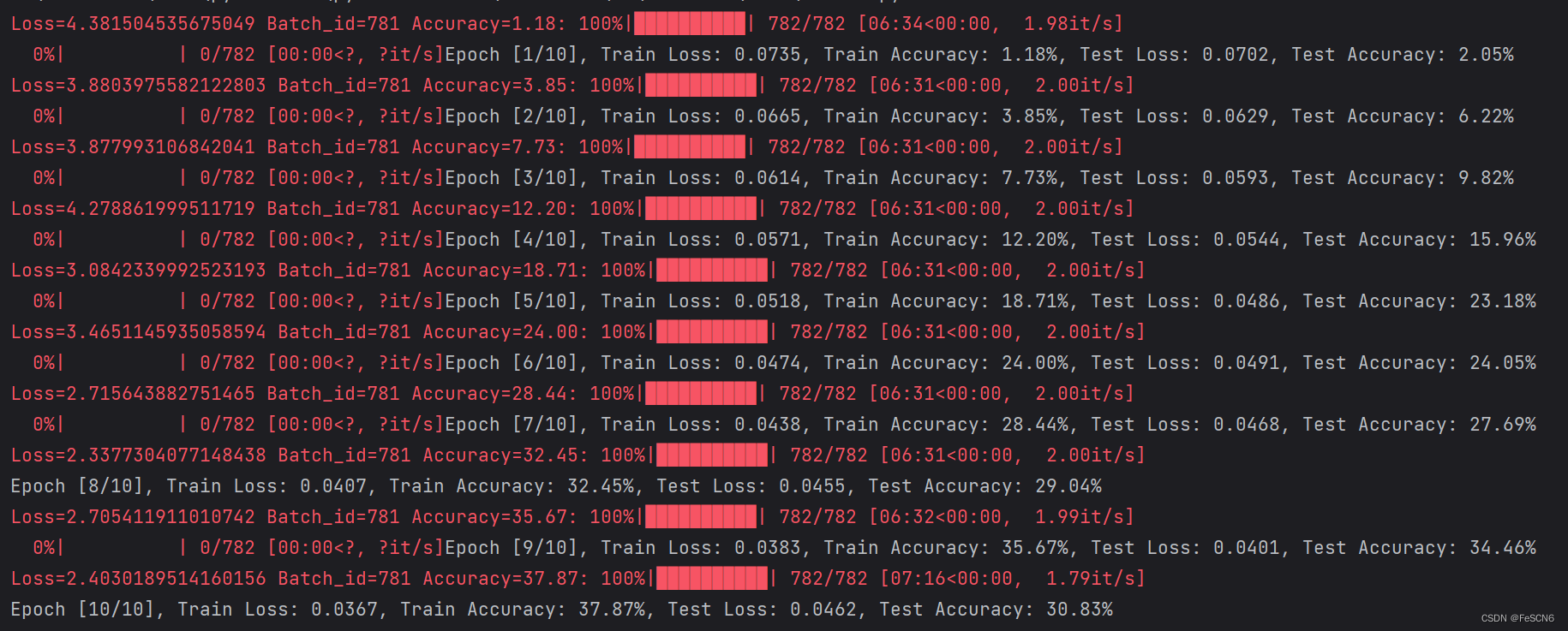
图九:ResNet101训练结果
对比发现ResNet101收敛速度快于SENet101,但在测试集上准确率不如SENet101。对比实验效果不明显,认为是训练轮数过少,如果训练达到100甚至200轮可能对比效果会更明显。理论上来说,注意力机制可以帮助模型自适应地学习并关注输入数据中的重要部分或特征,从而提高了特征的表征能力。通过对输入数据进行加权,模型可以更有效地提取和利用重要的特征信息,从而提高了模型的性能和泛化能力。但受限于设备和时间,此次实验只训练了10轮,对比效果不明显。
总结与结论:
1. 搭建ResNet34网络,每个残差层残差块个数[3,4,6,3],最终34=(3+4+6+3)*2+1+1。在搭建好的网络上进行训练,测试集上准确率最高达到51%,最后loss为1.8。
2. 试着减少残差层,分别构建了ResNet32,ResNet26,ResNet18网络([3, 4, 6, 2],[2, 3, 4, 2],[2, 2, 2, 2]),进行训练,发现随着残差块的减少,模型性能明显下降,表现为测试集上收敛效果差且准确度不高。
3. 搭建SENet101网络,实际上是把SE模块(全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid)插入到ResNet101中。由于SENet101模型深度较大、参数量较多,笔记本电脑显存有限,进行10轮的训练,发现模型效果不够好,十轮下来测试集上准确度只有33%。但根据1-10轮loss和acc的变化推测,继续训练loss会进一步降低、acc会进一步上升,如果像论文中跑100轮可能模型性能会提高很多。
4. SE_Block的定义体现了注意力机制。于是对比没有SE模块的ResNet101验证注意力机制在SENet101网络上的作用。理论上来说,注意力机制可以帮助模型自适应地学习并关注输入数据中的重要部分或特征,从而提高了特征的表征能力。通过对输入数据进行加权,模型可以更有效地提取和利用重要的特征信息,从而提高了模型的性能和泛化能力。实验对比发现ResNet101收敛速度快于SENet101,但在测试集上准确率不如SENet101。对比实验效果不明显,认为是训练轮数过少,如果训练达到100甚至200轮可能对比效果会更明显。

















 3245
3245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









